RCNN、Fast RCNN、 Faster RCNN 学习与对比
R-CNN算法
RCNN算法可以分为4个步骤
- 一张图像生成1K~2K个候选框(通过Selection Search算法选取候选框)
- 对每个候选区域,使用深度网络提取特征(生成2000x4096的特征矩阵, VGG16)
- 特征送入每一类的SVM分类,判断是否属于该类(生成2000x20的特征矩阵,每一行代表一个候选框对不同类别的预测概率,每一列表示同一类别在不同候选框中的类别预测概率,同时,使用NMS非极大值抑制算法,删除掉一些候选框)
- 使用回归器精细修正候选框(将剩余的候选框与Ground True对比,小于给定阈值的候选框进行删除,剩余的候选框进行位置修正)
| Region proposal(Selective Search) |
|---|
| Feature extraction(CNN) |
| Classification(SVM)-----------------------Bounding-box regression(regression) |
R-CNN存在问题:
- 测试速度慢:
测试一张图片约53s(CPU)。用Selective Search算法提取候选框用时2s,一张图像内候选框大量重叠,提取特征操作冗余。 - 训练速度慢:
过程及其繁琐 - 训练所需空间大:
对于SVM和bbox回归训练,需要从每个图像中的每个目标候选框提取特征,并写入磁盘。对于非常深的网络,如VGG16,从VOC07训练集上的5k图像上提取的特征需要数百GB的存储空间。

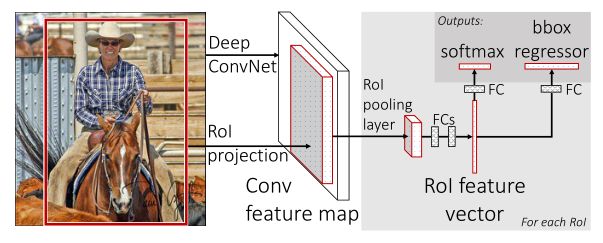
Fast RCNN
Fast RCNN算法流程可分为3个步骤:
- 一张图像生成1k~2k个候选区域(使用Selective Search算法)
- 将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上后的相应的特征矩阵(VGG16: 512d)
- 将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
训练数据的采样(正样本,负样本)
ROI pooling保证了不同输入特征矩阵的输出一致性具体操作:ROI Pooling
N个类别+1个背景
classes_outputs: 1x(20+1)
bbox regressor_outputs: 4x(n+1)
G x = P w d x ( P ) + P x G_x = P_wd_x(P) + P_x Gx=Pwdx(P)+Px G y = P w d y ( P ) + P y G_y = P_wd_y(P) + P_y Gy=Pwdy(P)+Py G w = P w e d w ( P ) G_w = P_we^{d_w(P)} Gw=Pwedw(P) G h = P h e d h ( P ) G_h = P_he^{d_h(P)} Gh=Phedh(P)
P x , P y , P w , P h P_x,P_y, P_w, P_h Px,Py,Pw,Ph分别为候选框的中心x, y坐标,以及宽高
G x , G y , G w , G h G_x, G_y, G_w, G_h Gx,Gy,Gw,Gh分别为最终预测的边界框中心x, y坐标,以及宽高
其中, d x , d y , d w , d h d_x,d_y,d_w,d_h dx,dy,dw,dh为训练参数
Multi-task loss
L ( p , u , t u , v ) = L c l s ( p , u ) + λ [ u ≥ 1 ] L l o c ( t u , v ) L(p, u, t^u, v)=L_{cls}(p, u) + \lambda[u≥1]L_{loc}(t^u,v) L(p,u,tu,v)=Lcls(p,u)+λ[u≥1]Lloc(tu,v)
其中, L c l s ( p , u ) L_{cls}(p, u) Lcls(p,u)为分类损失, λ [ u ≥ 1 ] L l o c ( t u , v ) \lambda[u≥1]L_{loc}(t^u,v) λ[u≥1]Lloc(tu,v)为边界框回归损失
p p p是分类器预测的softmax概率分布 p = ( p 0 , . . . , p k ) p=(p_0, ..., p_k) p=(p0,...,pk)
u u u是对应目标真实类别标签
t u t^u tu对应边界框回归预测的对应类别u的回归参数( t x u , t y u , t w u , t h u t^u_x, t^u_y,t^u_w,t^u_h txu,tyu,twu,thu)
v v v对应真实目标的边界框回归参数 ( v x , v y , v w , v h ) (v_x, v_y, v_w,v_h) (vx,vy,vw,vh)->对应 d x . . . d_x... dx...
L l o c ( t u , v ) = ∑ i ∈ { x , y , w , h } s m o o t h L 1 ( t i u − v i ) L_{loc}(t^u, v)=\sum_{i∈\{x, y,w,h\}} smooth_{L1}(t^u_i-v_i) Lloc(tu,v)=i∈{x,y,w,h}∑smoothL1(tiu−vi)
s m o o t h L 1 ( x ) = { 0.5 x 2 i f ∣ x ∣ < 1 ∣ x ∣ − 0.5 o t h e r w i s e smooth_{L1}(x) = \left\{ \begin{array}{lr} 0.5x^2 & if |x| < 1\\ |x|-0.5 & otherwise \end{array} \right. smoothL1(x)={0.5x2∣x∣−0.5if∣x∣<1otherwise
[ u ≥ 1 ] = { 1 u ≥ 1 0 o t h e r w i s e [u ≥ 1] = \left\{ \begin{array}{lr} 1 & u ≥ 1\\ 0 & otherwise \end{array} \right. [u≥1]={10u≥1otherwise
| Region proposal(Selective Search) |
|---|
| Feature extraction----Classification----Bounding-box regression |
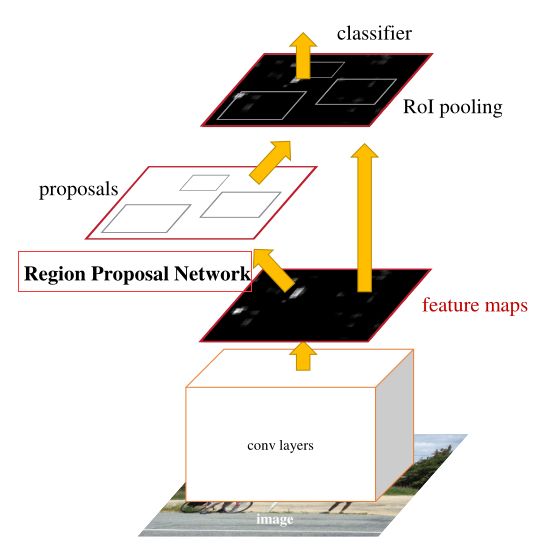
Faster RCNN(RPN+Fast RCNN)
Faster RCNN算法流程可分为3个步骤:
- 将图像输入网络得到相应的特征图
- 使用RPN结构生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵(ZFNet:256d)
- 将每个特征矩阵通过ROI poling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
anchor:
三种尺度(面积): { 12 8 2 , 25 6 2 , 51 2 2 128^2, 256^2, 512^2 1282,2562,5122}
三种比例: {1:1, 1:2, 2:1}
每个位置在原图上都对应有3x3=9个anchor
对于一张1000x600x3的图像,大约有60x40x9=20k个anchor,忽略跨跨越边界的anchor以后,剩下约6k个anchor。对于RPN生成的候选框之间存在大量重叠,基于候选框cls得分,采用非极大值抑制,IoU设为0.7,这样每张图片只剩2k个候选框。
注:候选框和anchor不同,anchor经过调整后形成候选框
RPN通过在feature maps利用3x3的卷积核,s=1, p=1,生成与feature maps 相同大小的feature maps,再利用1x1卷积,通道数分别设置为2*k和4*k, 也就是分类(非背景,背景)和回归个数(x, y, w, h)。
训练数据的采样(正样本和负样本)
从某张图像中,随机从所有的anchor中采样256个anchor,正负样本个数1:1,如果正样本的个数不足128,使用负样本填充。
正样本概念:
- anchor与Ground True拥有最大的IoU为正样本
- anchor与Ground True的IOU超过0.7即为正样本
负样本概念:
anchor与Ground True的IOU小于0.3即为负样本
RPN Multi-task loss
L ( { p i } , { t i } , t u , v ) = 1 N c l s L c l s ( p i , p i ∗ ) + λ 1 N r e g L r e g ( t i , t i ∗ ) L(\{p_i\}, \{t_i\}, t^u, v)=\frac{1}{N_{cls}} L_{cls}(p_i,p_i^* ) + \lambda \frac{1}{N_{reg}}L_{reg}(t_i,t_i^*) L({pi},{ti},tu,v)=Ncls1Lcls(pi,pi∗)+λNreg1Lreg(ti,ti∗)
其中, N c l s L c l s ( p i , p i ∗ ) {N_{cls}} L_{cls}(p_i,p_i^* ) NclsLcls(pi,pi∗)为分类损失, L r e g ( t i , t i ∗ ) L_{reg}(t_i,t_i^*) Lreg(ti,ti∗)为边界框回归损失,与Fast RCNN 一样
p i p_i pi表示第i个anchor预测为真实标签的概率
p i ∗ p_i^* pi∗当为正样本时为1, 当为负样本时为0
t i t_i ti表示预测第i个anchor的边界框回归参数
t i ∗ t^*_i ti∗表示第i个anchor对应的GTBox
N c l s N_{cls} Ncls表示一个mini-batch中的所有样本数量256
N r e g N_{reg} Nreg表示anchor位置的个数(不是anchor个数)约2400
t i t_i ti对应边界框回归预测的对应类别u的回归参数( t x , t y , t w , t h t_x, t_y,t_w,t_h tx,ty,tw,th)
L l o c ( t i , t i ∗ ) = ∑ i ∈ { x , y , w , h } s m o o t h L 1 ( t i − t i ∗ ) L_{loc}(t_i, t^*_i)=\sum_{i∈\{x, y,w,h\}} smooth_{L1}(t_i-t^*_i) Lloc(ti,ti∗)=i∈{x,y,w,h}∑smoothL1(ti−ti∗)
s m o o t h L 1 ( x ) = { 0.5 x 2 i f ∣ x ∣ < 1 ∣ x ∣ − 0.5 o t h e r w i s e smooth_{L1}(x) = \left\{ \begin{array}{lr} 0.5x^2 & if |x| < 1\\ |x|-0.5 & otherwise \end{array} \right. smoothL1(x)={0.5x2∣x∣−0.5if∣x∣<1otherwise
t x = ( x − x a ) / w a t_x = (x-x_a)/w_a tx=(x−xa)/wa, t y = ( y − y a ) / h a t_y = (y-y_a)/h_a ty=(y−ya)/ha, t w = l o g ( w / w a ) t_w = log(w/w_a) tw=log(w/wa), t h = l o g ( h / h a ) t_h = log(h/h_a) th=log(h/ha)
t x ∗ = ( x ∗ − x a ) / w a t_x^* = (x^*-x_a)/w_a tx∗=(x∗−xa)/wa, t y ∗ = ( y ∗ − y a ) / h a t_y^* = (y^*-y_a)/h_a ty∗=(y∗−ya)/ha, t w ∗ = l o g ( w ∗ / w a ) t_w^* = log(w^*/w_a) tw∗=log(w∗/wa), t h ∗ = l o g ( h ∗ / h a ) t_h^* = log(h^*/h_a) th∗=log(h∗/ha)
Fast RCNN Multi-task loss
与上部分相同
Faster RCNN 训练
现在使用方法:
直接采用RPN Loss + Fast RCNN Loss的联合训练方法
原论文中采用分别训练RPN以及Fast RCNN的方法
(1)利用ImageNet预训练分类模型初始化前置卷积网络层参数,并开始单独训练RPN网络
(2)固定RPN网络独有的卷积层以及全连接层参数,再利用ImageNet预训练分类模型初始化前置卷积网络参数,并利用RPN网络生成的目标建议框去训练Fast RCNN网络参数
(3)固定利用Fast RCNN训练好的前置卷积网络层参数,去微调RPN网络独有的卷积层和全连接层
(4)同样保持固定前置卷积网络层参数,去微调Fast RCNN网络的全连接层参数。最后RPN网络与Fast RCNN网络共享前置卷积网络层参数,构成一个统一网络。
简述过程:先训练Backbound->训练RPN->FastRCNN->微调RPN->微调FastRCNN
| Region proposal – Feature extraction --Classfication – Bounding-box regression |
|---|