python抓取浏览器的cookie_Python抓取需要cookie的网页
在仿照《Python小练习:可视化人人好友关系》一文时,需要登录模拟登录人人网。然而自从CSDN事件之后,人人网开始使用加密方式处理登录名和密码,直接使用post方式已经无法登陆人人网。这时,从豆瓣讨论中找到了解决方法:
1. 首先使用浏览器登陆人人,然后找到浏览器中关于登陆的Cookie;
2. 将Cookie记录下来,在Python中使用cookie模块模拟浏览器的行为;
3. 取得并解析数据。
1. HTTP协议与Cookie
抓取网页的过程跟浏览器浏览网页的过程是一样的,了解浏览器的工作原理就进行网页抓取的第一步。
了解HTTP协议和Cookie的有一系列非常好的文章:
* HTTP协议详解
* HTTP协议 (二) 基本认证
* HTTP协议 (七) Cookie
2. urllib2与cookie使用分析
2.1. 最简单用法
1 import urllib2
2 page = urllib2.urlopen("http://www.baidu.com")
3 page_data = page.read()
4 print page_data
它直接模拟了登陆百度首页的方法,打印出来的话你可以看到page_data的内容和浏览器里查看到的网页源码是一样的。
2.2. 设置Request信息
有些网页不希望被抓取,这些网页所在的服务器可以通过Request的Header信息识别你使用的哪种浏览器访问的。比如大家在论坛常见的这样的图片就是这一种原理。
因此我们需要手修改Request的信息,urllib2提供了这一功能。
例:未更改Request
1 import urllib2
2 request = urllib2.Request("http://www.baidu.com")
3 opener = urllib2.build_opener(urllib2.HTTPHandler(debuglevel=1))#为了开启回显,需要手动构造一个HTTPHandler
4 feeddata = opener.open(request).read()
可以得到回显:

1 send:'GET / HTTP/1.1\r\nAccept-Encoding: identity\r\nHost: www.baidu.com\r\nConnection: close\r\nUser-Agent: Python-urllib/2.7\r\n\r\n'
2 reply:'HTTP/1.1 200 OK\r\n'
3 header:Date:Tue,25Mar201411:02:30 GMT
4 header:Content-Type: text/html
5 header:Transfer-Encoding: chunked
6 header:Connection:Close
7 header:Vary:Accept-Encoding
8 header:Set-Cookie: BAIDUID=A12BBEA0BBB616F70334E89B4BB19228:FG=1; expires=Thu,31-Dec-3723:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
9 header:Set-Cookie: BDSVRTM=0; path=/
10 header:Set-Cookie: H_PS_PSSID=5610_5631_1428_5224_5723_4261_5567_4759; path=/; domain=.baidu.com
11 header: P3P: CP=" OTI DSP COR IVA OUR IND COM "
12 header:Expires:Tue,25Mar201411:02:20 GMT
13 header:Cache-Control: private
14 header:Server: BWS/1.1
15 header: BDPAGETYPE:1
16 header: BDQID:0xcd6b513700008d44
17 header: BDUSERID:0
其中 send: 'GET / HTTP/1.1\r\nAccept-Encoding: identity\r\nHost: www.baidu.com\r\nConnection: close\r\nUser-Agent: Python-urllib/2.7\r\n\r\n 就是urllib2库发送的Request Header。服务器可以通过User-Agent分辨出是哪种浏览器浏览的网页。
例:手工设置Request Header:
1 import urllib2
2 request = urllib2.Request("http://www.baidu.com")
3 opener = urllib2.build_opener(urllib2.HTTPHandler(debuglevel=1))#为了开启回显,需要手动构造一个HTTPHandler
4 user_agent ="Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.43 BIDUBrowser/6.x Safari/537.31"
5 request.add_header("User-Agent", user_agent)
6 feeddata = opener.open(request).read()
得到的回显' send: 'GET / HTTP/1.1\r\nAccept-Encoding: identity\r\nHost: www.baidu.com\r\nConnection: close\r\nUser-Agent: Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.43 BIDUBrowser/6.x Safari/537.31\r\n\r\n 此时服务器会认为我们在使用其它的浏览器浏览网页。
2.3. 使用cookie
使用浏览器登陆一个以前已经登陆过的网页,往往不再需要输入用户名和密码再次登陆,这颗因为浏览器已经保存了网站发送来的cookie。下次登陆时,浏览器会自动发送相关cookie到服务器,确定目前登陆状态。因此如果能够取得一个网站的cookie,就可以不输入用户名和密码模拟登陆这个网站。
Python需要使用cookielib处理cookie。
在登陆一个网页之后,可以使用Firebug或Chrome的“开发人员工具”查看网页的cookie。
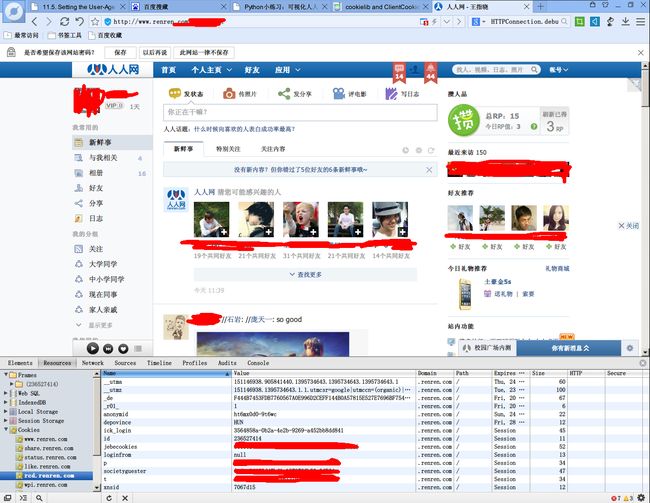
1 import urllib2
2 import cookielib
3 request = urllib2.Request("http://www.renren.com")
4 cookie = cookielib.CookieJar()
5 opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
6 opener.handle_open["http"][0].set_http_debuglevel(1)#设定开启回显
7 user_agent ="Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.43 BIDUBrowser/6.x Safari/537.31"
8 request.add_header("User-Agent", user_agent)
9 cookie ="t=*************************"#设定cookie的内容
10 request.add_header("Cookie", cookie)
11 feeddata = opener.open(request).read()