python爬虫实例(一) b站篇
python爬虫实例(一) b站篇
- 一、代码
- 二、注意事项
-
- 1. 视频格式:m4s,flv,mp4
-
- 1. m4s:
- 2. flv:
- 3. mp4
- 4. 概述
- 2. blob
- 三、思路
- 总结
一、代码
import requests
import os, sys
from lxml import etree
from multiprocessing.dummy import Pool
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
def get_cid(video):
# 获取cid
video_json = requests.get(url=video["cid_url"].format(video["bvid"]), headers=video["cid_header"]).json()
detail = video_json['data'][0]
video["cid"] = detail['cid']
video["name"] = detail['part'].replace(' ', '_') + '.mp4'
video["duration"] = detail["duration"]
def get_videourl(video):
# 获取视频的url(mp4格式)
video["video_header"]["host"] = video["video_url"].split('/')[2]
video_json = requests.get(url=video["video_url"].format(video["bvid"], video["cid"]),
headers=video["video_header"]).json()
durl = video_json['data']['durl'][0]
video["size"] = durl['size']
video["video_url"] = durl['url']
video["length"] = durl['length']
def get_download(video):
size = 0
video["video_header"]["host"] = video["video_url"].split('/')[2]
response = requests.get(url=video["video_url"], headers=video["video_header"], stream=True, verify=False)
chunk_size = 1024
content_size = int(response.headers['content-length'])
if response.status_code == 200:
sys.stdout.write(video["name"] + ' [文件大小]:%0.2f MB\n' % (content_size / chunk_size / 1024))
with open("D:\\python_file\\" + video["name"], 'wb') as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
size += len(data)
file.flush()
sys.stdout.write(video["name"] + ' [下载进度]:%.2f%%' % float(size / content_size * 100) + '\r')
if size / content_size == 1:
print('\n')
else:
print('下载出错')
if __name__ == '__main__':
# 进程池开4个大小
pool = Pool(4)
# bvid列表
bvid_list = ["BV17E411o7ye"]
videos = []
for bvid in bvid_list:
data = {
"cid": "",
"bvid": bvid,
"name": "",
"duration": "",
"length": "",
"size": "",
"cid_url": "https://api.bilibili.com/x/player/pagelist?bvid={}&jsonp=jsonp",
"video_url": "https://api.bilibili.com/x/player/playurl?bvid={}&cid={}&qn=80&type=&otype=json&fnval=1",
# 公共部分可以提到外面
"cid_header": {
"host": "api.bilibili.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4506.400"
},
"video_header": {
"host": "",
"Origin": "https://www.bilibili.com",
"Referer": "https://www.bilibili.com/video/" + bvid,
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4506.400"
}
}
videos.append(data)
pool.map(get_cid, videos)
pool.map(get_videourl, videos)
for i in videos:
print("name:{0} duration:{1}s 下载地址:D:\\python_file\\{2}".format(i["name"], i["duration"], i["name"]))
pool.map(get_download, videos)
二、注意事项
1. 视频格式:m4s,flv,mp4
1. m4s:
2. flv:

3. mp4
就是很正经的那个mp4了
4. 概述
也就是说现在网页播放视频大部分都是flv格式,然后又把flv切片成好多m4s?
2. blob
Blob URL只能由浏览器在内部生成。URL.createObjectURL()将创建一个特殊的Blob或File对象的引用,以后可以使用它来发布URL.revokeObjectURL()。这些URL只能在浏览器的单个实例中和同一个会话中(即页面/文档的生命周期)在本地使用。
Blob URL / Object URL是一种伪协议,允许Blob和File对象用作图像,下载二进制数据链接等的URL源。
最早是数据库直接用Blob来存储二进制数据对象,这样就不用关注存储数据的格式了。在web领域,Blob对象表示一个只读原始数据的类文件对象,虽然是二进制原始数据但是类似文件的对象,因此可以像操作文件对象一样操作Blob对象。
三、思路
先现在网页里找,看能不能找到视频下载地址

之后就发现了这么一串东西,然后去搜blob发现这是个新的知识点,然后后面的网址也用不了
于是我选择去抓包了
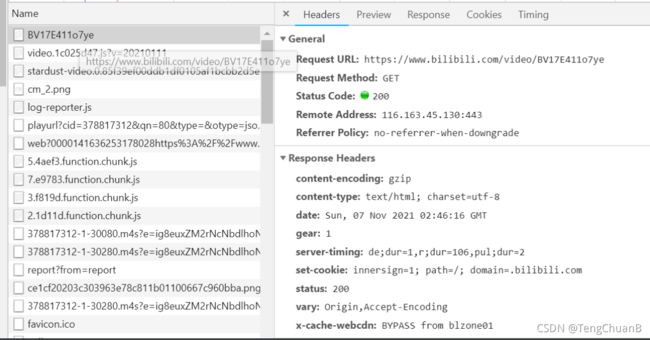
我先去找第一个包,发现他的响应就是一个页面而已,没有参考价值,于是继续寻找有用的信息
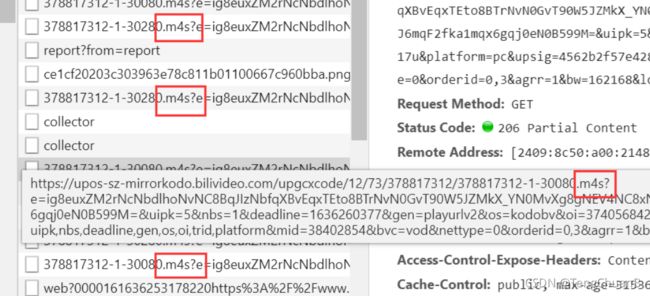
之后我发现了这种m4s格式的请求,然后去搜一下,发现这是视频格式,大胆猜测,这就是我要找的视频,但是这些请求太分散了,我根本抓不住,只能继续找其他的包
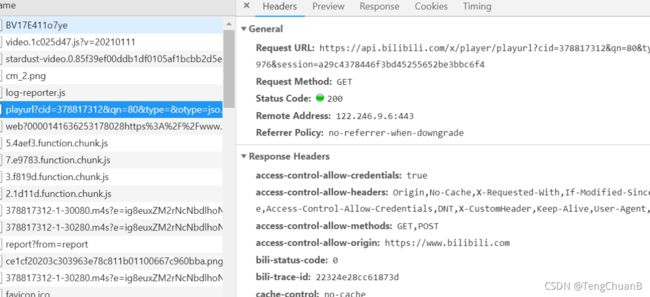
然后我就找到了这个,他的响应是json,里面放了很多m4s文件的url

其实这个时候即可以大胆猜测了,这就是我之前发现的那些m4s格式请求的url
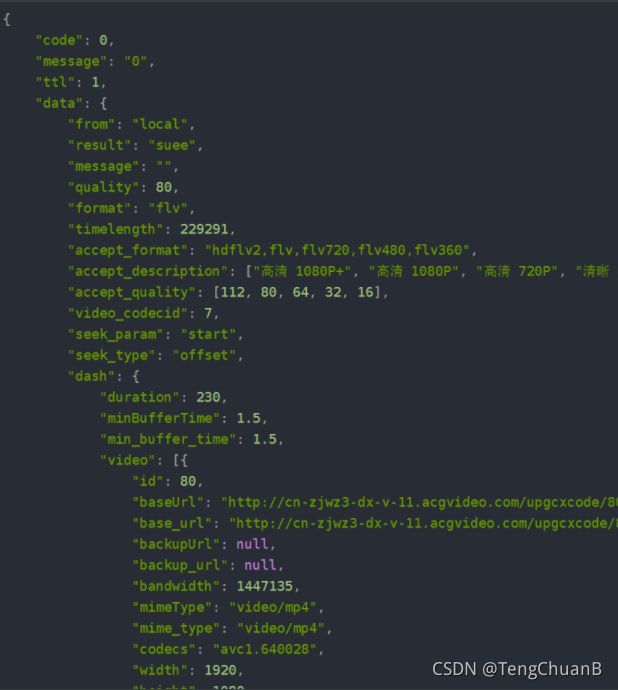
用json转换工具破解一下,就是这样了

所以现在的问题就变成了,如何获取这请求头的url
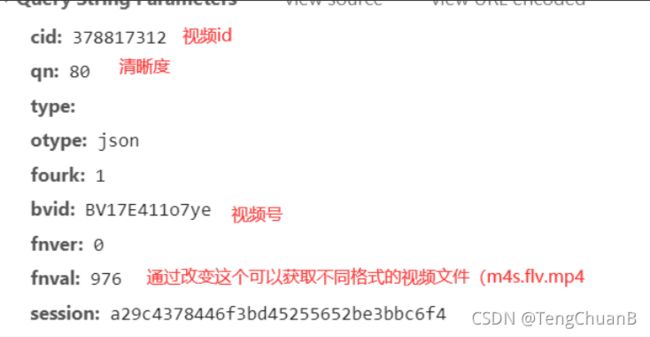
经过寻找资料和以往知识,我大概知道了这些参数都是什么意思
接下来的问题就是寻找cid了,所以继续往下找
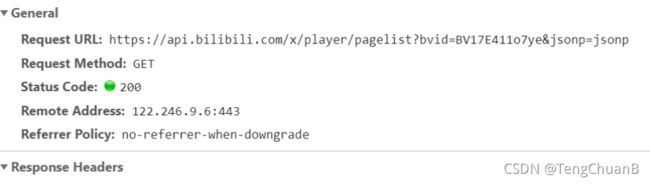
经过不懈努力,终于找到了这个,他的返回是json,其中就有cid

也就是,我可以通过bvid找到cid,然后再构造参数,获取视频url
然后就有下一个问题了,我确实获得了视频m4s文件的url,不过这么多m4s文件,我也不会分析(太菜了
于是继续百度,发现可以通过fnval这个参数,改变返回的视频格式类型,所以在构造参数的时候,我让fnval=1,就可以直接获取mp4格式的视频了
之后就是下载操作了