深度学习入门之批处理
深度学习入门之批处理
参考书籍:深度学习入门——基于pyhthon的理论与实现
文章目录
- 深度学习入门之批处理
- 前言
- 一、批处理作用
- 二、python实现批处理
-
- 1.批处理
- 2.代码解读
- 总结
前言
处理MNIST数据集的神经网络的实现,关注输入数据和权重参数的“形状”。
使用python解析器,输出神经网络的各层的权重的形状。
代码如下(示例):
x,_ = get_data()
network = init_network()
w1,w2,w3 = network['w1'],network['w2'],network['w3']
x.shape
(10000,784)
x[0].shape
(784,)
w1.shape
(784,50)
w2.shape
(50,100)
w3.shape
(100,10)
通过上述结果来确认一下多维数组的对应维数的元素个数是否一致(省略偏置)。图来表示的话,可以发现多维数组的对应维度的元素个数确定是一致的。此外,我们还可以确认最终的结果是输出了元素个数为10的一维数组。
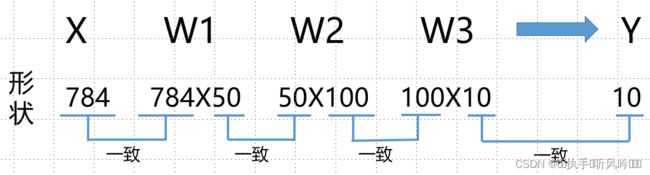
从整体的处理流程来看,输入一个784个元素(原本是一个2828的二维数组)构成的一维数组后,输出一个有10个元素的一维数组。这个只是输入一张图片数据时的处理流程。
考虑打包处理输入多张图像,一次性处理打包100张图片。为此,将x的尺寸变为100784,将100张图像打包作为输入数据。用图表示的话,如下图。

输入数据为100784,输出数据为10010.这表示输入的100张图像的结果被一次性输出了。比如下X[0]和Y[0]中保存了第0张图像以及其推理结果,X[1]和Y[1]表示保存了第1张图像以及其推理结果。
这种打包式的输入数据成为批(batch)。
一、批处理作用
批处理对计算机的运算大有利处,可以大幅度缩短每张图片的处理时间。
那么为什么批处理可以缩短处理时间呢?
这是因为大多数处理数值计算的库都进行了能够高效处理大型数组运算的最优化。并且,在神经网络的运算中,当数据传送成为瓶颈时,批处理可以减轻数据总线的负荷(严格的讲,相对于数据读取,可以将更多的时间用在计算上)。也就是说,批处理一次性计算大型数组要比分开逐步计算各个小型数组速度要更快。
二、python实现批处理
1.批处理
下面进行基于批处理的代码实现
代码如下(示例):
x,t = get_data()
network = init_network()
batch_size = 100 #批数量
accurary_cnt = 0
for i in range(0,len(x),batch_size):
x_batch = x[i:i+batch_size]
y_batch = predict(network,x_batch)
p = np.argmax(y_batch,axis=1)
accurary_cnt += np.sum(p==t[i:i+batch_size])
print('Accurary:' + str(float(accurary_cnt)/len(x)))
2.代码解读
首先range函数,range()函数若指定为range(start,end),则会生成一个由start到end-1之间的整数构成列表。若像range(start,end,step)这样三个参数,则生成的列表中的下一个元素会增加step指定的值。
代码如下(示例):
>>list(range(0,10))
>[0,1,2,3,4,5,6,7,8,9]
>>list(range(0,10,3))
>[0,3,6,9]
在range函数生成的列表的基础上,通过x[i:i+batch_size]从输入数据中抽出批数据。x[i:i+batch_n]会取出从第i个到第i+batch_n个之间的数据。
通过argmax函数获取值最大的元素的索引。不过这里需要注意的是,我们给定了参数axis=1.这是指定了在100*10的数组中,沿着第一维度方向找到最大值的元素索引(第0维对应第一个维度)
>>x=np.array([0.1,0.8,0.1],[0.3,0.1,0.6],[0.2,0.5,0.3],[0.8,0.1,0.1])
>>y=np.argmax(x,axis=1)
>[1,2,1,0]
总结
输入数据的集合称为批(batch)。通过批处理进行,以批为单位进行推理处理,能够实现高速的运算。