文本信息事件信息抽取的方法
事件抽取(EE)是信息抽取研究中的一个重要而富有挑战性的课题。事件作为一种特殊的信息形式,是指在特定时间、特定地点发生的涉及一个或多个参与者的特定事件,通常可以描述为状态的变化。事件提取任务旨在将此类事件信息从非结构化的纯文本中提取为结构化的形式,主要描述现实世界中事件发生的“谁、何时、何地、什么、为什么”和“如何”。在应用方面,该任务便于人们检索事件信息,分析人们的行为,促进信息检索、智能问答、知识图谱构建等实际应用。
事件提取可分为两个层次:基于模式的事件提取和基于开放域的事件提取。在基于模式的事件抽取任务中,事件被认为是特定的人和对象在特定的时间和地点进行交互的客观事实。基于模式的事件提取是寻找属于特定事件模式的单词,即发生的动作或状态变化,其提取目标包括时间、地点、人、动作等。在开放域事件提取任务中,事件被认为是一组主题的相关描述,可以通过分类或聚类形成。基于开放领域的事件提取是指获取与特定主题相关的一系列事件,通常由多个事件组成。无论是基于模式还是开放域事件提取任务,事件提取的目的是从大量文本中捕获我们感兴趣的事件类型,并以结构化的形式显示事件的基本元素。
事件提取具有大量的工作价值,是一种相对成熟的研究分类法。它从文本中发现事件提及,并提取包含事件触发器和事件参数的事件。事件提及是指包含一个或多个触发器和参数的句子。事件提取需要识别事件、对事件类型进行分类、识别元素以及判断元素角色。触发器识别和触发器分类可分为事件检测任务。参数标识和参数角色分类可以定义为一个参数提取任务。触发器分类是一个多标签分类]任务,用来对每个事件的类型进行分类。角色分类任务是一种基于单词对的多类分类任务,确定句子中任意一对触发器和实体之间的角色关系。因此,事件提取可以依赖于一些NLP任务的结果,如命名实体识别(NER)、语义解析和关系提取。

上图是事件抽取的流程图。事件提取是找到焦点事件类型,并用它的角色提取其元素。对于pipeline范例事件提取,有必要区分给定文本的文本中的事件类型,称为触发器分类。针对不同的事件类型,设计了不同的事件模式。然后,根据模式提取事件元素,包括元素识别和元素角色分类子任务。在早期阶段,论点提取被视为一个词分类任务,并对文本中的每个词进行分类。此外,还有序列标记、机器阅读理解(MRC)和序列到结构生成方法。对于联合范例事件提取,该模型同时对事件类型和元素角色进行分类,以避免触发分类子任务带来的错误。
近年来,深度学习方法在很多领域得到了应用,深度学习模型能够自动有效地提取句子中的重要特征。与传统的特征提取方法相比,深度学习方法可以自动提取特征。它可以对语义信息进行建模,并在更高的层次上自动组合和匹配触发特征。这些方法的有效性在自然语言处理中得到了验证,并取得了许多突破。在事件提取任务中使用深度学习可以使许多研究人员消除特征提取工作。
大多数基于深度学习的事件提取方法通常采用监督学习,这意味着需要高质量的大数据集。依赖人工标注语料库数据耗时耗力,导致现有事件语料库数据规模小、类型少、分布不均匀。事件提取任务可能非常复杂。一个句子中可能有多个事件类型,不同的事件类型将共享一个事件元素。同样的论点在不同事件中的作用也是不同的。根据抽取范式,基于模式的抽取方法可分为基于流水线(pipeline)的抽取方法和基于联合的抽取方法。对基于流水线(pipeline)的模型学习事件检测模型,然后学习元素抽取模型。联合事件提取方法避免了触发器识别错误对元素提取的影响,但不能充分利用事件触发器的信息。到目前为止,最好的事件提取方法是基于联合的事件提取范例。
3.3.1基于流水线(pipeline)的事件信息抽取方法
采用基于流水线(pipeline)的方法,它首先检测触发器,并根据触发器判断事件类型。元素提取模型根据事件类型和2触发器的预测结果提取元素并对元素角色进行分类。
基于流水线(pipeline)的方法将所有子任务视为独立的分类问题(《Zero shot transfer learning for event extraction,》、《Pipelined query processing in coprocessor environments》、《R-node: New pipelined approach for an effective reconfifigurable wireless sensor node》)。流水线(pipeline)方法被广泛使用,因为它简化了整个事件提取任务。如图所示,基于流水线(pipeline)的事件提取方法将事件提取任务转化为多阶段分类问题。所需的分类器包括:
1) 触发器分类器用于确定术语是否为事件触发器和事件类型。
2) 元素分类器用于确定单词是否为事件的元素。
3) 元素角色分类器用于确定元素的类别。

经典的基于深度学习的事件提取模型DMCNN(《Event extraction via dynamic multi-pooling convolutional neural networks》)使用两个动态多池卷积神经网络进行触发分类和元素分类。触发器分类模型识别触发器。如果存在触发器,元素分类模型将用于识别元素及其角色。PLMEE(《Exploring pretrained language models for event extraction and generation》)还使用了两种模型,分别采用触发器提取和元素提取。元素提取器使用触发器提取的结果进行推理。通过引入BERT,它表现良好。
基于流水线(pipeline)的事件提取方法通过之前的子任务为后续子任务提供额外信息,并利用子任务之间的依赖关系。Du等人(《Event extraction by answering (almost) natural questions》)采用问答方法来实现事件提取。首先,该模型通过设计的触发器问题模板识别输入句子中的触发器。模型的输入包括输入句子和问题。然后,它根据已识别的触发器对事件类型进行分类。触发器可以为触发器分类提供额外信息,但错误的触发器识别结果也会影响触发器分类。最后,该模型识别事件元素,并根据事件类型对应的模式对元素角色进行分类。在论点提取中,该模型利用了上一轮历史内容的答案。这种方法最显著的缺陷是错误传播。直观地说,如果在第一步中触发器识别出现错误,那么元素识别的准确性就会降低。因此,在使用流水线(pipeline)提取事件时,会出现错误级联和任务拆分问题。流水线(pipeline)事件提取方法可以利用触发器的信息提取事件元素。然而,这需要高精度的触发器识别。错误的触发器将严重影响元素提取的准确率。因此,流水线(pipeline)事件提取方法将触发器视为事件的核心。
基于流水线(pipeline)的方法将将事件提取任务转化为多阶段分类问题。基于流水线(pipeline)的事件提取方法首先识别触发器和元素标识基于触发器识别的结果。它考虑了触发因素作为事件的核心。然而,这一阶段性战略将导致错误传播。触发器的识别错误将被传递到元素分类阶段将导致整体性能下降。此外,因为触发检测总是在前元素检测,元素将不被考虑同时检测触发器。因此,每个环节都是独立的缺乏互动,忽视了它们之间的影响。因此,整体依赖关系无法处理。典型的例子是DMCNN。
3.3.2 联合学习的事件信息抽取方法
为了克服由事件检测引起的错误信息传播,研究人员提出了一种基于联合的事件提取范式。它通过结合触发器识别和元素提取任务来减少错误信息的传播。
事件抽取在自然语言处理中具有重要的实用价值。在使用深度学习对事件提取任务建模之前,研究了事件提取中的联合学习方法。如下图所示,该方法在第一阶段根据候选触发器和实体识别触发器和元素。在第二阶段,为了避免事件类型错误信息的传播,同时实现了触发器分类和元素角色分类。将触发器“died”分为Die事件类型,元素“Baghdad”分为Place元素角色等。
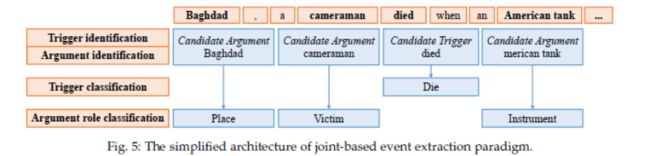
基于联合模型的深度学习事件提取方法主要利用深度学习和联合学习与特征学习进行交互,避免了学习时间过长和复杂的特征工程。Li等人(《Joint event extraction via structured prediction with global features》)在传统特征提取方法的基础上,研究了触发器提取和元素提取任务的联合学习,并通过结构化感知器模型获得最优结果。Zhu等人(《Bilingual event extraction: a case study on trigger type determination》)设计了高效的离散特征,包括特征词中包含的所有信息的局部特征,以及可以连接触发器和元素信息的全局特征。Nguyen等人(《Joint event extraction via recurrent neural networks》)通过深度学习和联合学习成功构建了本地特征和全球特征。它使用递归神经网络将事件识别和论点角色分类结合起来。构建的局部特征包括文本序列特征和局部窗口特征。输入文本由单词向量、实体向量和事件元素组成。然后将文本转换为递归神经网络模型,以获得深度学习的序列特征。本文还提出了一个带记忆的深度学习模型对其进行建模。它主要针对事件触发器之间、事件元素之间以及事件触发器与事件元素之间的全局特性,以同时提高任务的性能。
事件提取涉及实体识别等相关任务,这有助于改进事件提取。Liu等人(《Leveraging framenet to improve automatic event detection》)利用论点的局部特征来辅助角色分类。他们首次采用了实体联合学习任务,旨在降低任务的复杂性。前面的方法使用标记的特征输入数据集,并输出事件。Chen等人(《Automatically labeled data generation for large scale event extraction》)简化了过程,即纯文本输入和输出。在过程的中间,它是事件元素的联合学习。这种联合学习因素主要提供每个输入事件中不同事件的关系和实体信息。
上述联合学习方法可以实现触发器和元素的联合建模事件提取。然而,在实际工作过程中,触发器和元素的提取是连续进行的,而不是同时进行的,这是一个亟待讨论的问题。此外,如果在深度学习中加入端到端模式,特征选择工作量将显著减少,这也将在后面讨论。联合事件提取方法避免了触发器识别错误对事件元素提取的影响,考虑到触发器和元素同等重要,但不能利用触发器的信息。
为了克服流水线(pipeline)的方法的缺点,研究人员提出了联合方法。联合方法构造了一个联合学习模型来触发识别和元素识别,其中触发和元素可以相互促进提取效果。实验证明,联合学习方法的效果优于流水线(pipeline)学习方法。经典案例是JRNN(《Joint event extraction via recurrent neural networks》)。联合事件提取方法避免了事件元素提取中的触发器识别,但不能利用触发器信息。联合事件提取方法认为事件中的触发器和元素同等重要。然而,无论是基于流水线(pipeline)的事件提取还是基于联合的事件提取都无法避免事件类型预测错误对元素提取性能的影响。此外,这些方法不能在不同的事件类型之间共享信息,不能独立地学习每种类型,这不利于仅使用少量标记数据的事件提取。
3.3.3 基于深度学习的事件信息抽取模型
传统的事件提取方法对深度特征的学习具有挑战性,使得依赖于复杂语义关系的事件提取任务难以改进。最新的事件提取工作基于深度学习体系结构,如卷积神经网络(CNN)、循环神经网络(RNN)、图形神经网络(GNN)、Transformers或其他网络。深度学习方法可以捕获复杂的语义关系,显著改善多事件提取数据集。下面会介绍了几种典型的事件提取模型。
3.3.3.1基于CNN的模型
事件提取是信息提取中一个特别具有挑战性的问题。传统的事件提取方法主要依赖于设计良好的特征和复杂的NLP工具,这会消耗大量人力资源成本,并导致数据稀疏和错误传播等问题。为了在不使用复杂的自然语言处理工具的情况下自动提取词汇和句子级特征,Chen等人引入了一种称为DMCNN的单词表示模型。它捕捉单词有意义的语义规则,并采用基于CNN的框架来捕捉句子层面的线索。然而,CNN只能捕获句子中的基本信息,它使用动态多池层来存储基于事件触发器和元素的更关键的信息。事件提取是由具有自动学习特征的动态多池卷积神经网络实现的两阶段多类分类。第一阶段是触发器分类。DMCNN对句子中的每个单词进行分类,以确定触发因素。对于具有触发器的句子,此阶段应用类似的DMCNN为触发器分配元素,并对齐元素的角色。图6描述了元素分类的体系结构。词汇级特征表示和句子级特征提取用于捕捉词汇线索和学习句子的组成语义特征。
CNN归纳出句子中k-gram的基本结构。因此,一些研究人员还研究了基于卷积神经网络的事件提取技术。Nguyen等人[114]使用CNN来研究事件检测任务,与传统的基于特征的方法相比,它克服了复杂的特征工程和错误传播限制。但它广泛依赖其他受监督的模块和手动资源来获取特征。在跨域泛化性能方面,它明显优于基于特征的方法。此外,为了考虑非连续的K-G,Nguyen等人(111)引入了不连续的CNN。CNN模型通过具有丰富局部和全局特征的结构化预测应用于基于流水线(pipeline)和基于联合的范式,以自动学习隐藏的特征表示。与基于流水线(pipeline)的方法相比,基于联合的范式可以缓解错误传播问题,并利用事件触发器和元素角色之间的相互依赖性。
3.3.3.2基于RNN的模型
除了基于CNN的事件提取方法外,还对RNN进行了一些研究。RNN用于建模序列信息,以提取事件中的元素,如图7所示。JRNN提出了一种双向RNN,用于基于联合的范例中的事件提取。它有一个编码阶段和预测阶段。在编码阶段,它使用RNN来总结上下文信息。此外,它还预测了预测阶段的触发和论证。
以前的方法严重依赖于特定语言的知识和现有的NLP工具。一种更具前景的从数据中自动学习有用特征的方法。Feng等人(《A language independent neural network for event detection》)开发了一种混合神经网络,用于捕捉特定序列和信息片段的上下文,并将其用于训练多语言事件检测器。该模型使用双向LSTM获取需要识别的文档序列信息。然后利用卷积神经网络获取文档中的短语块信息,将这两种信息结合起来,最终识别出触发点。该方法可以使用多种语言(英语、汉语和西班牙语)进行稳健、高效和准确的检测。在跨语言泛化性能方面,复合模型优于传统的基于特征的方法。深度学习中的树结构和序列结构比序列结构具有更好的性能。为了避免过度依赖词汇和句法特征,依赖桥递归神经网络(DBRNN)(《Jointly extracting event triggers and arguments by dependency-bridge RNN and tensor based argument interaction》)基于双向RNN进行事件提取。DBRNN依靠衔接语法相关单词来增强。DBRNN是一个基于RNN的框架,它利用依赖关系图信息提取事件触发器和元素角色。
3.3.3.3基于注意力的模型
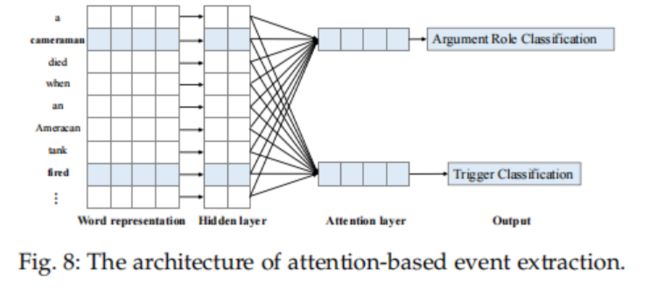
深度学习模型对事件特征的自动提取和外部资源对事件特征的增强主要集中在事件触发器的信息上,而对事件元素和词间相关性的信息关注较少。句子级顺序建模在捕获很长范围的依赖关系时效率很低。此外,基于RNN和基于CNN的模型不能完全模拟事件之间的关联。注意机制中结构信息的建模逐渐引起了研究者的关注。随着研究方法的不断提出,增加注意机制的模型逐渐出现,如图所示。注意机制的特点决定了它可以在不考虑位置信息的情况下,利用全局信息对局部环境进行建模。在更新词语的语义表示时有很好的应用效果。
注意机制通过控制句子各部分的不同权重信息,使模型在关注句子重要特征信息的同时忽略其他不重要的特征信息,并合理分配资源以提取更准确的结果。同时,注意机制本身可以作为一种对齐,解释端到端模型中输入和输出之间的对齐,使模型更具解释性。
一些研究人员还使用分层注意机制来进行信息的全局聚合。四个模块:单词表示、句法图卷积网络、自我注意触发分类和论点分类模块。通过引入语法快捷弧,信息流得到了增强。利用基于注意的图卷积网络对图信息进行联合建模,提取多个事件触发器和元素。此外,当联合提取事件触发器和元素以解决数据集不平衡时,它优化了有偏损失函数。
3.3.3.4基于GCN的模型
句法表征为句子中的事件检测提供了一种将单词直接链接到其信息上下文的有效方法。Nguyen等人(《Graph convolutional networks with argument-aware pooling for event detection》)研究了一种基于依赖树的卷积神经网络来执行事件检测,他们是第一个将语法集成到神经事件检测中的人。他们提出了一种新的池化方法,该方法依赖于实体提及来聚合卷积向量。该模型对当前单词和句子中提到的实体的基于图形的卷积向量进行合并。该模型聚合卷积向量以生成用于事件类型预测的单个向量表示。该模型将对实体提及的信息进行显式建模,以提高事件检测的性能。
在(《Event time extraction and propagation via graph attention networks》)中,TAC-KBP时隙用于填充任务中提出的四元时间表示,该模型预测事件的最早和最晚开始和结束时间,从而表示事件的模糊时间跨度。该模型基于共享元素和时间关系为每个输入文档构建文档级事件图,并使用基于图的注意网络方法在图上传播时间信息,如图所示,其中实体加下划线,事件用粗体显示。Wen等人基于输入文档的事件关系构建文档级事件图方法。将提取文档中的事件元素。然后,根据关键字(如前后)和事件发生的时间逻辑,按时间顺序排列事件。实体元素在不同事件之间共享。模型实现将事件合并到更准确的时间线中。
3.3.3.5基于transformer的模型
利用一个在不同事件中扮演不同角色的元素来改进事件提取是一个挑战。杨在论证角色方面的预测有助于克服角色重叠问题。此外,由于训练数据不足,该方法通过编辑原型并通过对质量进行排序来筛选开发的样本,从而自动生成标记数据。他们提出了一个框架,即基于预训练语言模型的事件提取器(PLMEE)[37],如图10所示。PLMEE通过结合使用提取模型和基于预先训练的语言模型的生成方法来促进事件提取。它是一个两阶段的任务,包括触发器提取和元素提取,由触发器提取程序和元素提取程序组成,这两个程序都依赖于伯特的特征表示。然后,它利用角色的重要性来重新权衡损失函数。
GAIL(《Joint entity and event extraction with generative adversarial imitation learning》)是一个基于ELMo的模型,利用生成性对抗网络帮助模型关注更难检测的事件。他们提出了一个基于生成对抗式模仿学习的实体和事件提取框架。这是一种采用生成对抗网络(GAN)的反向强化学习(IRL)方法。该模型通过使用IRL的动态机制,直接评估实体和事件提取中实例的正确和错误标记。
DYGIE++(《Entity, relation, and event extraction with contextualized span representations》)是一个基于BERT的框架,它对句子和跨句子上下文中的文本跨度和捕获进行建模。许多信息提取任务,如命名实体识别、关系提取、事件提取和共同引用解析,都可以受益于跨句子的全局上下文或不依赖于局部的短语。它们将事件提取作为附加任务,并在事件触发器及其元素的关系图中进行跨度更新。广度表示是在多语句BERT编码的基础上构造的。
事件抽取是信息抽取的一个重要研究方向,在信息收集、信息检索、舆论分析等方面发挥着重要作用,具有应用价值。传统的事件提取方法大多采用人工构造的方法进行特征表示,并使用分类模型对触发器进行分类,识别元素的作用。近年来,深度学习在图像处理、语音识别、自然语言处理等方面取得了显著的效果。为了解决传统方法的不足,系统地讨论了基于深度学习的事件提取。在伯特模型出现之前,主流的方法是从文本中找到触发点,并根据触发点判断文本的事件类型。近年来,随着BERT事件提取模型的引入,基于全文的事件类型识别方法已成为主流。这是因为BERT具有出色的上下文表示能力,在文本分类任务中表现良好,尤其是在数据量较小的情况下。