面经合集(包含python、mysql、linux、测试等内容)
mysql
1. 怎么排序?
order by。
2. 聚合函数
sum,count,min,max...
3. 介绍一下mysql
关系型数据库。由于体积小、速度快、成本低、开源,MySQL被广泛的应用在Internet上的大中小型网站中。
4. 增删改查
select、delete、update、insert into
5. 连表查询
连接查询包括合并、内连接、外连接和交叉连接.
1. union
SELECT ID,Name FROM Students UNION SELECT ID,Name FROM Teachers
2. INNER JOIN(内连接)
INNER JOIN(内连接),也成为自然连接
作用:根据两个或多个表中的列之间的关系,从这些表中查询数据。
注意: 内连接是从结果中删除其他被连接表中没有匹配行的所有行,所以内连接可能会丢失信息。
重点:内连接,只查匹配行。
语法:(INNER可省略)
SELECT fieldlist
FROM table1 [INNER] join table2
ON table1.column=table2.column
3、外连接
与内连接相比,即使没有匹配行,也会返回一个表的全集。
外连接分为三种:左外连接,右外连接,全外连接。对应SQL:LEFT/RIGHT/FULL OUTER JOIN。通常我们省略outer 这个关键字。写成:LEFT/RIGHT/FULL JOIN。
重点:至少有一方保留全集,没有匹配行用NULL代替。
1)LEFT OUTER JOIN,简称LEFT JOIN,左外连接(左连接)
结果集保留左表的所有行,但只包含第二个表与第一表匹配的行。第二个表相应的空行被放入NULL值。
依然沿用内链接的例子
SELECT Students.ID,Students.Name,Majors.Name AS MajorName
FROM Students LEFT JOIN Majors
ON Students.MajorID = Majors.ID
2)RIGHT JOIN(right outer join)右外连接(右连接)
右外连接保留了第二个表的所有行,但只包含第一个表与第二个表匹配的行。第一个表相应空行被入NULL值。
右连接与左连接思想类似。只是第二张保留全集,如果第一张表中没有匹配项,用NULL代替
依然沿用内链接的例子,只是改为右连接
SELECT Students.ID,Students.Name,Majors.Name AS MajorName
FROM Students RIGHT JOIN Majors
ON Students.MajorID = Majors.ID
3)FULL JOIN (FULL OUTER JOIN,全外连接)
全外连接,简称:全连接。会把两个表所有的行都显示在结果表中
SELECT Students.ID,Students.Name,Majors.Name AS MajorName
FROM Students FULL JOIN Majors
ON Students.MajorID = Majors.ID
6. 索引。结构,优缺点,使用,失效条件
1. 概念
索引是对数据库表的一列或者多列的值进行排序一种结构,使用索引可以快速访问数据表中的特定信息。
2. 优缺点
优点:
- 大大加快数据检索的速度。
- 将随机I/O变成顺序I/O(因为B+树的叶子节点是连接在一起的)
- 加速表与表之间的连接
缺点:
- 从空间角度考虑,建立索引需要占用物理空间
- 从时间角度 考虑,创建和维护索引都需要花费时间,例如对数据进行增删改的时候都需要维护索引。
3. 数据结构
索引的数据结构主要有B+树和哈希表,对应的索引分别为B+树索引和哈希索引。InnoDB引擎的索引类型有B+树索引和哈希索引,默认的索引类型为B+树索引。
4. 使用场景
- 对于中大型表建立索引非常有效,对于非常小的表,一般全部表扫描速度更快些。
- 对于超大型的表,建立和维护索引的代价也会变高,这时可以考虑分区技术。
- 如何表的增删改非常多,而查询需求非常少的话,那就没有必要建立索引了,因为维护索引也是需要代价的。
- 一般不会出现在where条件中的字段就没有必要建立索引了。
- 多个字段经常被查询的话可以考虑联合索引。
- 字段多且字段值没有重复的时候考虑唯一索引。
- 字段多且有重复的时候考虑普通索引。
5. 失效情况
- 条件中有or,例如select * from table_name where a = 1 or b = 3
- 在索引上进行计算会导致索引失效,例如select * from table_name where a + 1 = 2
- 在索引的类型上进行数据类型的隐形转换,会导致索引失效,例如字符串一定要加引号,假设 select * from table_name where a = '1'会使用到索引,如果写成select * from table_name where a = 1则会导致索引失效。
- 在索引中使用函数会导致索引失效,例如select * from table_name where abs(a) = 1
- 在使用like查询时以%开头会导致索引失效
- 索引上使用!=、<>进行判断时会导致索引失效,例如select * from table_name where a != 1
- 索引字段上使用 is null/is not null判断时会导致索引失效,例如select * from table_name where a is null
6. 索引类型
MySQL主要的索引类型主要有FULLTEXT,HASH,BTREE,RTREE。
- FULLTEXT
FULLTEXT即全文索引,MyISAM存储引擎和InnoDB存储引擎在MySQL5.6.4以上版本支持全文索引,一般用于查找文本中的关键字,而不是直接比较是否相等,多在CHAR,VARCHAR,TAXT等数据类型上创建全文索引。全文索引主要是用来解决WHERE name LIKE "%zhang%"等针对文本的模糊查询效率低的问题。
- HASH
HASH即哈希索引,哈希索引多用于等值查询,时间复杂夫为o(1),效率非常高,但不支持排序、范围查询及模糊查询等。
- BTREE
BTREE即B+树索引,INnoDB存储引擎默认的索引,支持排序、分组、范围查询、模糊查询等,并且性能稳定。
- RTREE
RTREE即空间数据索引,多用于地理数据的存储,相比于其他索引,空间数据索引的优势在于范围查找
7. 事务的四个特性,举例子
- 原子性:原子性是指包含事务的操作要么全部执行成功,要么全部失败回滚。
- 一致性:一致性指事务在执行前后状态是一致的。
- 隔离性:一个事务所进行的修改在最终提交之前,对其他事务是不可见的。
- 持久性:数据一旦提交,其所作的修改将永久地保存到数据库中。
8. 锁
什么是数据库的锁?
当数据库有并发事务的时候,保证数据访问顺序的机制称为锁机制。
数据库的锁与隔离级别的关系?
| 隔离级别 |
实现方式 |
| 未提交读 |
总是读取最新的数据,无需加锁 |
| 提交读 |
读取数据时加共享锁,读取数据后释放共享锁 |
| 可重复读 |
读取数据时加共享锁,事务结束后释放共享锁 |
| 串行化 |
锁定整个范围的键,一直持有锁直到事务结束 |
数据库锁的类型有哪些?
按照锁的粒度可以将MySQL锁分为三种:
| MySQL锁类别 |
资源开销 |
加锁速度 |
是否会出现死锁 |
锁的粒度 |
并发度 |
| 表级锁 |
小 |
快 |
不会 |
大 |
低 |
| 行级锁 |
大 |
慢 |
会 |
小 |
高 |
| 页面锁 |
一般 |
一般 |
不会 |
一般 |
一般 |
MyISAM默认采用表级锁,InnoDB默认采用行级锁。
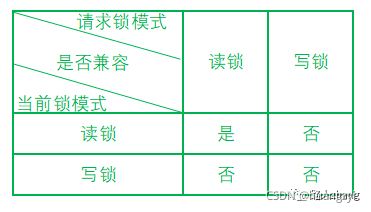
从锁的类别上区别可以分为共享锁和排他锁
- 共享锁:共享锁又称读锁,简写为S锁,一个事务对一个数据对象加了S锁,可以对这个数据对象进行读取操作,但不能进行更新操作。并且在加锁期间其他事务只能对这个数据对象加S锁,不能加X锁。
- 排他锁:排他锁又称为写锁,简写为X锁,一个事务对一个数据对象加了X锁,可以对这个对象进行读取和更新操作,加锁期间,其他事务不能对该数据对象进行加X锁或S锁。
它们的兼容情况如下(不太会用excel,图太丑了):
MySQL中InnoDB引擎的行锁模式及其是如何实现的?
行锁模式
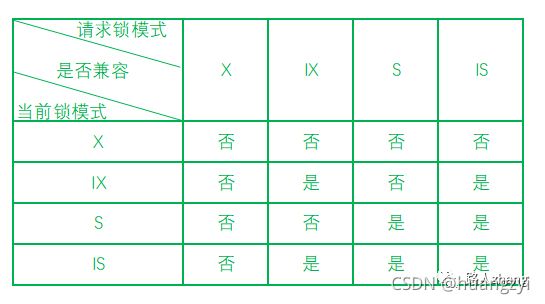
在存在行锁和表锁的情况下,一个事务想对某个表加X锁时,需要先检查是否有其他事务对这个表加了锁或对这个表的某一行加了锁,对表的每一行都进行检测一次这是非常低效率的,为了解决这种问题,实现多粒度锁机制,InnoDB还有两种内部使用的意向锁,两种意向锁都是表锁。
- 意向共享锁:简称IS锁,一个事务打算给数据行加共享锁前必须先获得该表的IS锁。
- 意向排他锁:简称IX锁,一个事务打算给数据行加排他锁前必须先获得该表的IX锁。
有了意向锁,一个事务想对某个表加X锁,只需要检查是否有其他事务对这个表加了X/IX/S/IS锁即可。
锁的兼容性如下:
行锁实现方式:INnoDB的行锁是通过给索引上的索引项加锁实现的,如果没有索引,InnoDB将通过隐藏的聚簇索引来对记录进行加锁。
InnoDB行锁主要分三种情况:
- Record lock:对索引项加锁
- Grap lock:对索引之间的“间隙”、第一条记录前的“间隙”或最后一条后的间隙加锁。
- Next-key lock:前两种放入组合,对记录及前面的间隙加锁。
InnoDB行锁的特性:如果不通过索引条件检索数据,那么InnoDB将对表中所有记录加锁,实际产生的效果和表锁是一样的。
MVCC不能解决幻读问题,在可重复读隔离级别下,使用MVCC+Next-Key Locks可以解决幻读问题。
9. 死锁
死锁是指两个或者两个以上进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象。在MySQL中,MyISAM是一次获得所需的全部锁,要么全部满足,要么等待,所以不会出现死锁。在InnoDB存储引擎中,除了单个SQL组成的事务外,锁都是逐步获得的,所以存在死锁问题。
下列方法有助于最大限度地降低死锁:
(1)按同一顺序访问对象。
(2)避免事务中的用户交互。
(3)保持事务简短并在一个批处理中。
(4)使用低隔离级别。
(5)使用绑定连接。
10. 乐观锁和悲观锁
1、悲观锁
悲观锁,它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度。因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制。也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统的数据访问层中实现了加锁机制,也无法保证外部系统不会修改数据。
2、乐观锁
乐观锁( Optimistic Locking ) 相对悲观锁而言,乐观锁假设认为数据一般情况下不会造成冲突,所以只会在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则返回用户错误的信息,让用户决定如何去做。
11. 查找重复记录中的一条,limit 1查找完一条就结束吗?
是
12. 左连接右连接区别,内连接外连接区别
13. 唯一性索引和主键索引的差别
(1)主键是一种约束,唯一索引是一种索引,两者在本质上是不同的。
(2)主键创建后一定包含一个唯一性索引,唯一性索引并不一定就是主键。
(3)唯一性索引列允许空值,而主键列不允许为空值。
(4)主键可以被其他表引用为外键,而唯一索引不能。
(5)一个表最多只能创建一个主键,但可以创建多个唯一索引。
(6)主键更适合那些不容易更改的唯一标识,如自动递增列、身份证号等。
(7)在RBO模式下,主键的执行计划优先级要高于唯一索引。 两者可以提高查询的速度。
14. 数据量大查询慢怎么加速
15. 怎么保证原子性
16. varchar和char的区别,搜索速度
- varchar表示变长,char表示长度固定。当所插入的字符超过他们的长度时,在严格模式下,会拒绝插入并提示错误信息,在一般模式下,会截取后插入。如char(5),无论插入的字符长度是多少,长度都是5,插入字符长度小于5,则用空格补充。对于varchar(5),如果插入的字符长度小于5,则存储的字符长度就是插入字符的长度,不会填充。
- 存储容量不同,对于char来说,最多能存放的字符个数为255。对于varchar,最多能存放的字符个数是65532。
- 存储速度不同,char长度固定,存储速度会比varchar快一些,但在空间上会占用额外的空间,属于一种空间换时间的策略。而varchar空间利用率会高些,但存储速度慢,属于一种时间换空间的策略。
- 在检索上,就算不考虑索引,char是定长的,移动到下一条记录,只需要做固定长度的指针偏移即可。varchar则必须根据当前记录的长度算出下一个数据指针的偏移。
c
1. static
静态函数与普通函数的区别在于:静态函数不可以被同一源文件以外的函数调用。
1)隐藏
变量和函数如果加了 static,就会对其它源文件隐藏
2)保持变量内容的持久
存储在静态数据区的变量会在程序刚开始运行时就完成初始化,也是唯一的一次初始化。
3)默认初始化为 0
shell
1. 常用shell做什么?
2. 怎么使用shell
linux
1. 查看文件详细信息(有多少行)
使用wc命令 具体通过wc --help 可以查看。
如:wc -l filename 就是查看文件里有多少行
wc -w filename 看文件里有多少个word。
wc -L filename 文件里最长的那一行是多少个字。wc命令
wc命令的功能为统计指定文件中的字节数、字数、行数, 并将统计结果显示输出。
2. 怎么进行存储管理
//查看当前系统磁盘使用空间
df -h
//查看当前目录文件占用空间大小
du -sh *
3. 常用命令
1、ls命令
就是 list 的缩写,通过 ls 命令不仅可以查看 linux 文件夹包含的文件,而且可以查看文件权限(包括目录、文件夹、文件权限)查看目录信息等等。
2、cd 命令
切换当前目录至 dirName
3、pwd 命令
pwd 命令用于查看当前工作目录路径。
4、mkdir 命令
mkdir 命令用于创建文件夹。
5、rm 命令
删除一个目录中的一个或多个文件或目录,如果没有使用 -r 选项,则 rm 不会删除目录。如果使用 rm 来删除文件,通常仍可以将该文件恢复原状
6、rmdir 命令
从一个目录中删除一个或多个子目录项,删除某目录时也必须具有对其父目录的写权限。
7、mv 命令
移动文件或修改文件名,根据第二参数类型(如目录,则移动文件;如为文件则重命令该文件)。
8、cp 命令
将源文件复制至目标文件,或将多个源文件复制至目标目录。
9、cat 命令
cat 主要有三大功能:
1.一次显示整个文件:
cat filename
2.从键盘创建一个文件:
cat > filename
只能创建新文件,不能编辑已有文件。
3.将几个文件合并为一个文件:
cat file1 file2 > file
10、more 命令
功能类似于 cat, more 会以一页一页的显示方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示,按 b 键就会往回(back)一页显示。
11、less 命令
less 与 more 类似,但使用 less 可以随意浏览文件,而 more 仅能向前移动,却不能向后移动,而且 less 在查看之前不会加载整个文件。
12、head 命令
head 用来显示档案的开头至标准输出中,默认 head 命令打印其相应文件的开头 10 行。
13、tail 命令
用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理。常用查看日志文件。
-n 显示文件的尾部 n 行内容
14、which 命令
在 linux 要查找某个文件,但不知道放在哪里了,可以使用下面的一些命令来搜索:
which 查看可执行文件的位置。 whereis 查看文件的位置。 locate 配合数据库查看文件位置。 find 实际搜寻硬盘查询文件名称。
15、whereis 命令
whereis 命令只能用于程序名的搜索,而且只搜索二进制文件(参数-b)、man说明文件(参数-m)和源代码文件(参数-s)。如果省略参数,则返回所有信息。whereis 及 locate 都是基于系统内建的数据库进行搜索,因此效率很高,而find则是遍历硬盘查找文件。
16、locate 命令
locate 通过搜寻系统内建文档数据库达到快速找到档案,数据库由 updatedb 程序来更新,updatedb 是由 cron daemon 周期性调用的。默认情况下 locate 命令在搜寻数据库时比由整个由硬盘资料来搜寻资料来得快,但较差劲的是 locate 所找到的档案若是最近才建立或 刚更名的,可能会找不到,在内定值中,updatedb 每天会跑一次,可以由修改 crontab 来更新设定值 (etc/crontab)。
locate 与 find 命令相似,可以使用如 *、? 等进行正则匹配查找
17、find 命令
用于在文件树中查找文件,并作出相应的处理。
18、chmod 命令
用于改变 linux 系统文件或目录的访问权限。用它控制文件或目录的访问权限。该命令有两种用法。一种是包含字母和操作符表达式的文字设定法;另一种是包含数字的数字设定法。
19、tar 命令
用来压缩和解压文件。tar 本身不具有压缩功能,只具有打包功能,有关压缩及解压是调用其它的功能来完成。
20、chown 命令
chown 将指定文件的拥有者改为指定的用户或组,用户可以是用户名或者用户 ID;组可以是组名或者组 ID;文件是以空格分开的要改变权限的文件列表,支持通配符。
21、df 命令
显示磁盘空间使用情况。获取硬盘被占用了多少空间,目前还剩下多少空间等信息,如果没有文件名被指定,则所有当前被挂载的文件系统的可用空间将被显示。
22、du 命令
du 命令也是查看使用空间的,但是与 df 命令不同的是 Linux du 命令是对文件和目录磁盘使用的空间的查看
23、ln 命令
功能是为文件在另外一个位置建立一个同步的链接,当在不同目录需要该问题时,就不需要为每一个目录创建同样的文件,通过 ln 创建的链接(link)减少磁盘占用量。
24、date 命令
显示或设定系统的日期与时间。
25、cal 命令
可以用户显示公历(阳历)日历如只有一个参数,则表示年份(1-9999),如有两个参数,则表示月份和年份
26、grep 命令
强大的文本搜索命令,grep(Global Regular Expression Print) 全局正则表达式搜索。
grep 的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。
27、wc 命令
wc(word count)功能为统计指定的文件中字节数、字数、行数,并将统计结果输出
28、ps 命令
ps(process status),用来查看当前运行的进程状态,一次性查看,如果需要动态连续结果使用 top
30、kill 命令
发送指定的信号到相应进程。不指定型号将发送SIGTERM(15)终止指定进程。如果任无法终止该程序可用"-KILL" 参数,其发送的信号为SIGKILL(9) ,将强制结束进程,使用ps命令或者jobs 命令可以查看进程号。root用户将影响用户的进程,非root用户只能影响自己的进程。
31、free 命令
显示系统内存使用情况,包括物理内存、交互区内存(swap)和内核缓冲区内存。
4. 怎么修改配置文件
vim编辑器
5. 日志查看
tail、head、 cat、tac、sed、less、echo
6. 查看被占用的端口,查看进程
netstat,lsof -i
ps aux, top
7. 空间管理
- df(英文全称:disk full):列出文件系统的整体磁盘使用量
- du(英文全称:disk used):检查磁盘空间使用量
- fdisk:用于磁盘分区
8. 安装过哪种操作系统,遇上了什么困难
9. 压缩解压
- tar命令
解包:tar zxvf FileName.tar
打包:tar zcvf FileName.tar DirName
- gz命令
解压1:gunzip FileName.gz
解压2:gzip -d FileName.gz
压缩:gzip FileName
- .tar.gz 和 .tgz
解压:tar zxvf FileName.tar.gz
压缩:tar zcvf FileName.tar.gz DirName
压缩多个文件:tar zcvf FileName.tar.gz DirName1 DirName2 DirName3 ...
- bz2命令
解压1:bzip2 -d FileName.bz2
解压2:bunzip2 FileName.bz2
压缩: bzip2 -z FileName
- .tar.bz2
解压:tar jxvf FileName.tar.bz2
压缩:tar jcvf FileName.tar.bz2 DirName
- bz命令
解压1:bzip2 -d FileName.bz
解压2:bunzip2 FileName.bz
压缩:未知
- .tar.bz
解压:tar jxvf FileName.tar.bz
- Z命令
解压:uncompress FileName.Z
压缩:compress FileName
- .tar.Z
解压:tar Zxvf FileName.tar.Z
压缩:tar Zcvf FileName.tar.Z DirName
- zip命令
解压:unzip FileName.zip
压缩:zip FileName.zip DirName
10. 怎么配置远程,有用ssh吗
python
1. 列表和字典的差别
1.列表有序,字典无序
2.列表通过偏移读取,字典使用键-值进行存储
3.两者都可变长度,异构以及任意嵌套
4.列表是可变的序列,字典属于属于可变映射类型
5.列表对象引用数组,字典对象引用表
列表可以当成普通的数组,每当用到引用时,Python总是会将这个引用指向一个对象,所以程序只需处理对象的操作。当把一个对象赋给一个数据结构元素或变量名时,Python总是会存储对象的引用,而不是对象的一个拷贝。
字典存储的是对象引用,不是拷贝,和列表一样。字典的key是不能变的,list不能作为key,字符串、元祖、整数等都可以。
和list比较,dict有以下几个特点:
1.查找和插入的速度极快,不会随着key的增加而增加。
2.需要占用大量的内存,内存浪费多。
而list相反:
1.查找和插入的时间随着元素的增加而增加。
2.占用空间小,浪费内存很少。
所以,dict是用空间来换取时间的一种方法。
2. 列表和元组差别
-
- 列表是动态数组,它们不可变且可以重设长度(改变其内部元素的个数)。
- 元组是静态数组,它们不可变,且其内部数据一旦创建便无法改变。
- 元组缓存于Python运行时环境,这意味着我们每次使用元组时无须访问内核去分配内存。
- 集合
- 集合是一个可变容器
- 集合内的数据对象都是唯一的(不能重复)
- 集合是无序的存储结构,集合内的数据没有先后关系
- 集合是可迭代对象
- 集合相当于是只有键没有值得字典(键就是集合中的数据)
- 集合内的元素是不可变的
- 浅拷贝和深拷贝
- 直接赋值:其实就是对象的引用(别名)。
- 浅拷贝(copy):拷贝父对象,不会拷贝对象的内部的子对象。
- 深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
- 怎么存储
(1)垃圾回收
(2)引用计数
(3)内存池机制
一、垃圾回收:
python不像C++,Java等语言一样,他们可以不用事先声明变量类型而直接对变量进行赋值。对Python语言来讲,对象的类型和内存都是在运行时确定的。这也是为什么我们称Python语言为动态类型的原因(这里我们把动态类型可以简单的归结为对变量内存地址的分配是在运行时自动判断变量类型并对变量进行赋值)。
二、引用计数:
Python采用了类似Windows内核对象一样的方式来对内存进行管理。每一个对象,都维护这一个对指向该对对象的引用的计数。
三、内存池机制
Python的内存机制以金字塔行,-1,-2层主要有操作系统进行操作,
第0层是C中的malloc,free等内存分配和释放函数进行操作;
第1层和第2层是内存池,有Python的接口函数PyMem_Malloc函数实现,当对象小于256K时有该层直接分配内存;
第3层是最上层,也就是我们对Python对象的直接操作;
- 全局变量
global关键字:
为了解决函数内使用全局变量的问题,python增加了global关键字, 利用它的特性, 可以指定变量的作用域。
global关键字的作用:声明变量var是全局的
实例一:函数内赋值不能改变全局变量值:
实例二:全局变量值改变必须要有global关键字
- 垃圾回收机制
在Python中,主要通过引用计数进行垃圾回收;通过 “标记-清除” 解决容器对象可能产生的循环引用问题;通过 “分代回收” 以空间换时间的方法提高垃圾回收效率。
1、当内存中有不再使用的部分时,垃圾收集器就会把他们清理掉。它会去检查那些引用计数为0的对象,然后清除其在内存的空间。当然除了引用计数为0的会被清除,还有一种情况也会被垃圾收集器清掉:当两个对象相互引用时,他们本身其他的引用已经为0了。
2、垃圾回收机制还有一个循环垃圾回收器, 确保释放循环引用对象(a引用b, b引用a, 导致其引用计数永远不为0)。
- 排序
sort
- 字符串方法,大小写转换
replace,upper,lower,strip
- 替换空格下划线等
.replace()
re.sub
- python高级用法
1) 列表推导
lista = [item for item in array if item[0] == 'a']
2) 迭代器(Iterator)
迭代器指的是可以使用next()方法来回调的对象,可以对可迭代对象使用iter()方法,将其转换为迭代器。
在构建迭代器时,不是将所有的元素一次性的加载,而是等调用next方法时返回元素,所以不需要考虑内存的问题。
3) 生成器函数
生成器函数基于yield指令,可以暂停一个函数并返回中间结果。当需要一个将返回一个序列或在循环中执行的函数时,就可以使用生成器,因为当这些元素被传递到另一个函数中进行后续处理时,一次返回一个元素可以有效的提升整体性能。
4) lambda表达式
编写简单函数而设计,起到了一个函数速写的作用,使得简单函数可以更加简洁的表示。
5)装饰器
装饰器本质是一个Python函数,它可以让其它函数在没有任何代码变动的情况下增加额外功能。有了装饰器,我们可以抽离出大量和函数功能本身无关的雷同代码并继续重用。
- 装饰器
python装饰器本质上就是一个函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外的功能,装饰器的返回值也是一个函数对象(函数的指针)。装饰器函数的外部函数传入要装饰的函数名字,返回经过修饰后函数的名字;内层函数(闭包)负责修饰被修饰函数。从上面这段描述中我们需要记住装饰器的几点属性,以便后面能更好的理解:
实质:是一个函数
参数:是你要装饰的函数名(并非函数调用)
返回:是装饰完的函数名(也非函数调用)
作用:为已经存在的对象添加额外的功能
特点:不需要对对象做任何的代码上的变动
应用装饰器的场景:插入日志、性能测试、事务处理、权限校验。
- 单引号双引号区别
单引号和双引号没有区别。都可以用就是为了方便,减少写太多的转义字符。
- GIL锁,线程使用时gil锁
GIL:又叫全局解释器锁,每个线程在执行的过程中都需要先获取GIL,保证同一时刻只有一个线程在运行,目的是解决多线程同时竞争程序中的全局变量而出现的线程安全问题。
GIL面试题参考答案:
- Python语言和GIL没有什么关系。仅仅是由于历史原因在Cpython虚拟机(解释器),难以移除GIL。
- GIL:全局解释器锁。每个线程在执行的过程都需要先获取GIL,保证同一时刻只有一个线程可以执行代码。
- 线程释放GIL锁的情况: 在IO操作等可能会引起阻塞的system call之前,可以暂时释放GIL,但在执行完毕后,必须重新获取GIL Python 3.x使用计时器(执行时间达到阈值后,当前线程释放GIL)或Python 2.x,tickets计数达到100。
- Python使用多进程是可以利用多核的CPU资源的。
- 多线程爬取比单线程性能有提升,因为遇到IO阻塞会自动释放GIL锁。
- 列表插入、删除
append,insert
remove,pop
- 去重
set
- 数据类型,可变类型和不可变类型,set可变吗,turple里的列表可变吗
turple中引入的是list地址,list本身可以变化
- ==和is区别
| Is |
比较的是两个对象的id值是否相等,也就是比较俩对象是否为同一个实例对象,是否指向同一个内存地址。 |
| == |
比较的是两个对象的内容是否相等,默认会调用对象的__eq__()方法。 |
- 讲一下request的方式
基本GET请求(headers参数 和 parmas参数)
通过post把数据提交到url地址,等同于一字典的形式提交form表单里面的数据
selenium
1. 有哪几种定位方式?举出三种
id, css, xpath
2. 你最喜欢哪种,为什么?
id, 准确
3. xpath定位不到
1. 根据其他属性定位
如果有其他固定属性,最先考虑的当然是根据元素的其他属性来定位,定位方式那么多,何必在这一棵树上吊死。。
2. 根据相对关系定位
根据其附近的父节点、子节点、兄弟节点定位,关于这方面,博主之前的一篇文章可作为参考:Python selenium —— 父子、兄弟、相邻节点定位方式详解
3. 根据DOM顺序index定位
这个很简单,找到该元素在主文档或某级父节点中的index,然后根据index可轻松定位,不过这种方式可能不够稳定,如果可以,还是用其他的方法定位更加合适。
4. 根据部分元素属性定位
5.页面还没有加载出来就对页面上的元素进行的操作:sleep几秒
6.有弹出二级页面的,需要定位到弹出框在进行操作
4. 遇到的困难
5. 使用
6. 怎么测试
计算机网络
- TCP和UDP的区别
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的,没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
- IP地址映射为mac地址哪一个协议,简单解释该协议工作原理
使用的是ARP,ARP是地址解析协议。
1:首先,每个主机都会在自己的ARP缓冲区中建立一个ARP列表,以表示IP地址和MAC地址之间的对应关系。
2:当源主机要发送数据时,首先检查ARP列表中是否有对应IP地址的目的主机的MAC地址,如果有,则直接发送数据,如果没有,就向本网段的所有主机发送ARP数据包,该数据包包括的内容有:源主机IP地址,源主机MAC地址,目的主机的IP地址。
3:当本网络的所有主机收到该ARP数据包时,首先检查数据包中的IP地址是否是自己的IP地址,如果不是,则忽略该数据包,如果是,则首先从数据包中取出源主机的IP和MAC地址写入到ARP列表中,如果已经存在,则覆盖,然后将自己的MAC地址写入ARP响应包中,告诉源主机自己是它想要找的MAC地址。
4:源主机收到ARP响应包后。将目的主机的IP和MAC地址写入ARP列表,并利用此信息发送数据。如果源主机一直没有收到ARP响应数据包,表示ARP查询失败。
广播发送ARP请求,单播发送ARP响应
- http状态码
200 - 服务器成功返回网页
404 - 请求的网页不存在
503 - 服务不可用
- get和post差别
- smtp服务器
smtp提供可靠且有效的电子邮件传输的协议。SMTP是建立在FTP文件传输服务上的一种邮件服务,主要用于系统之间的邮件信息传递,并提供有关来信的通知。SMTP独立于特定的传输子系统,且只需要可靠有序的数据流信道支持,SMTP的重要特性之一是其能跨越网络传输邮件,即“SMTP邮件中继”。使用SMTP,可实现相同网络处理进程之间的邮件传输,也可通过中继器或网关实现某处理进程与其他网络之间的邮件传输。
测试
- 使用等价值划分法测试文件上传
文件大小、文件类型、地址是否存在、正在使用中等。
- 讲一下等价值划分法
等价类的定义基于一个假设:等价类是指某个输入域的子集合。在该子集合中,各个输入数据对于揭露程序中的错误都是等效的,并合理地假定:测试某等价类的代表值就等于对这一类其它值的测试,因此,可以把全部输入数据合理划分为若干等价类,在每一个等价类中取一个数据作为测试的输入条件就可以用少量代表性的测试数据取得较好的测试结果。
- 怎么debug? 怎么设置断点?断点出错怎么找到问题?
易出错的地方
- 接口测试
接口测试是测试系统组件间接口的一种测试。接口测试主要用于检测外部系统与系统之间以及内部各个子系统之间的交互点。测试的重点是要检查数据的交换,传递和控制管理过程,以及系统间的相互逻辑依赖关系等。
- 功能测试
功能测试就是对产品的各功能进行验证,根据功能测试用例,逐项测试,检查产品是否达到用户要求的功能。
- 安全测试
安全测试是在IT软件产品的生命周期中,特别是产品开发基本完成到发布阶段,对产品进行检验以验证产品符合安全需求定义和产品质量标准的过程 。
- 黑盒白盒区别
黑盒测试的优点有:
比较简单,不需要了解程序内部的代码及实现;与软件的内部实现无关;从用户角度出发,能很容易的知道用户会用到哪些功能,会遇到哪些问题;基于软件开发文档,所以也能知道软件实现了文档中的哪些功能;在做软件自动化测试时较为方便。
黑盒测试的缺点有:
不可能覆盖所有的代码,覆盖率较低,大概只能达到总代码量的 30%;自动化测试的复用性较低。
白盒测试的优点有:
帮助软件测试人员增大代码的覆盖率,提高代码的质量,发现代码中隐藏的问题。
白盒测试的缺点有:
程序运行会有很多不同的路径,不可能测试所有的运行路径;测试基于代码,只能测试开发人员做的对不对,而不能知道设计的正确与否,可能会漏掉一些功能需求;系统庞大时,测试开销会非常大。
- 测试报告
一、概述
包括项目背景、需求分析
二、测试时间、测试环境
三、测试过程
评审记录、测试范围、测试用例
四、功能实现清单
列出是否已经按照测试计划实现功能
五、缺陷统计
测试缺陷统计;
测试用例执行情况统计
六、测试统计情况
资源统计
执行情况
问题统计
问题列表
遗留的问题
七、测试总结
测试结论;(是否通过)
测试内容、测试用例的覆盖程度、bug的解决程度
- 测试微信发红包
从功能(正常+异常)、性能、安全、兼容性、界面、易用性进行测试
功能测试
1.在红包钱数,和红包个数的输入框中只能输入数字
2.红包里最多和最少可以输入的钱数 200 0.01
3.拼手气红包最多可以发多少个红包
3.超过最大拼手气红包的个数是否有提醒
4.当红包钱数超过最大范围是不是有对应的提示
5.发送的红包个数超过最大范围是不是有提示
6.余额不足时,红包发送失败
7.在红包描述里是否可以输入汉字,英文,符号,表情,纯数字,汉字英语符号,
7.是否可以输入它们的混合搭配
8.输入红包钱数是不是只能输入数字
9.红包描述里许多能有多少个字符 10个
10.红包描述,金额,红包个数框里是否支持复制粘贴操作
12.红包描述里的表情可以删除
13.发送的红包别人是否可以领取
13.发的红包自己可不可以领取 2人
14. 24小时内没有领取的红包是否可以退回到原来的账户
14.超过24小时没有领取的红包,是否还可以领取
15.用户是否可以多次抢一个红包
16.发红包的人是否还可以抢红包 多人
17.红包的金额里的小数位数是否有限制
18.可以按返回键,取消发红包
19. 断网时,无法抢红包
20.可不可以自己选择支付方式
21.余额不足时,会不会自动匹配支付方式
22.在发红包界面能否看到以前的收发红包的记录
23.红包记录里的信息与实际收发红包记录是否匹配
24.支付时可以密码支付也可以指纹支付
25.如果直接输入小数点,那么小数点之前应该有个0
26.支付成功后,退回聊天界面
27.发红包金额和收到的红包金额应该匹配
28.是否可以连续多次发红包
29.输入钱数为0,"塞钱进红包"置灰
性能测试
1.弱网时抢红包,发红包时间
2.不同网速时抢红包,发红包的时间
3.发红包和收红包成功后的跳转时间
4.收发红包的耗电量
5.退款到账的时间
兼容性
1.iOS和安卓是否都可以发送红包
2.电脑端是否可以抢微信红包
界面测试
1.发红包界面没有错别字
2.发红包和收红包界面排版合理
3.发红包和收红包界面颜色搭配合理
安全测试
1.对方微信号异地登录,是否会有提醒
2.红包被领取以后,发送红包人的金额会减少,收红包金额会增加
3.发送红包失败,余额和银行卡里的钱数不会少
4.红包发送成功,是否会收到微信支付的通知
易用性测试
1.红包描述,可以通过语音输入
2.支付方式可以为指纹支付也可以为密码支付
- 测试购物车
1.界面测试
界面布局、排版是否合理;文字是否显示清晰;不同卖家的商品是否区分明显。
2.功能测试
未登录时:
将商品加入购物车,页面跳转到登录页面,登录成功后购物车数量增加;
点击购物车菜单,页面跳转到登录页面。
登录后:
所有链接是否跳转正确;
商品是否可以成功加入购物车;
购物车商品总数是否有限制;
商品总数是否正确;
全选功能是否好用;
删除功能是否好用;
填写委托单功能是否好用;
委托单中填写的价格是否正确显示;
价格总计是否正确;
商品文字太长时是否显示完整;
店铺名字太长时是否显示完整;
创新券商品是否打标;
购物车中下架的商品是否有特殊标识;
新加入购物车商品排序(添加购物车中存在店铺的商品和购物车中不存在店铺的商品);
是否支持TAB、ENTER等快捷键;商品删除后商品总数是否减少;
购物车结算功能是否好用。
3.兼容性测试
不同浏览器测试。
4.易用性测试
删除功能是否有提示;是否有回到顶部的功能;商品过多时结算按钮是否可以浮动显示。
5.性能测试
压力测试;并发测试。
- 对测试的理解
1、寻找 Bug;
2、避免软件开发过程中的缺陷;
3、衡量软件的品质;
4、关注用户的需求。
总的目标是:确保软件的质量。
- 测试需要的品质
细心、耐心、好奇心、沟通能力、总结归纳能力、理解能力、表达能力
- 测试流程
1、阅读相关技术文档(如产品PRD、UI设计、产品流程图等)。
2、参加需求评审会议。
3、根据最终确定的需求文档编写测试计划。
4、编写测试用例(等价类划分法、边界值分析法等)。
5、用例评审(主要参与人员:开发、测试、产品、测试leader)。
6、开发提交代码至SVN或者GIT ,配管搭建测试环境。
7、执行测试用例,记录发现的问题。
8、验证bug与回归测试。
9、编写测试报告。
10、产品上线。
需求调查:全面了解系统概况、应用领域、软件开发周期、软件开发环境、开发组织、时间安排、功能需求、性能需求、质量需求及测试要求等。根据系统概况进行项目所需的人员、时间和工作量估计以及项目报价。
制定初步的项目计划。
测试准备:组织测试团队、培训、建立测试和管理环境等。
测试设计:按照测试要求进行每个测试项的测试设计,包括测试用例的设计和测试脚本的开发等。
测试实施:按照测试计划实施测试。
测试评估:根据测试的结果,出具测试评估报告。
- 为什么做测试
- 抓包了解吗
将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作,也用来检查网络安全。抓包也经常被用来进行数据截取等。
fiddler
- 开发者工具里的内容
- 元素(Elements):用于查看或修改HTML元素的属性、CSS属性、监听事件、断点等。css可以即时修改,即时显示。大大方便了开发者调试页面
- 控制台(Console):控制台一般用于执行一次性代码,查看JavaScript对象,查看调试日志信息或异常信息。还可以当作Javascript API查看用。例如我想查看console都有哪些方法和属性,我可以直接在Console中输入"console"并执行~
- 源代码(Sources):该页面用于查看页面的HTML文件源代码、JavaScript源代码、CSS源代码,此外最重要的是可以调试JavaScript源代码,可以给JS代码添加断点等。
- 网络(Network):网络页面主要用于查看header等与网络连接相关的信息。
- 测试枯燥、压力大,怎么克服
- python数据结构的应用
- 压力测试
- 微信登录测试
- 一条bug包含什么
- 讲一下单元测试、集成测试、系统测试、回归测试、验收测试
- 常用测试方法
- 逻辑覆盖
- 循环覆盖
- 基本路径覆盖
1 .等价类划分
划分等价类: 等价类是指某个输入域的子集合.在该子集合中,各个输入数据对于揭露程序中的错误都是等效的.并合理地假定:测试某等价类的代表值就等于对这一类其它值的测试.因此,可以把全部输入数据合理划分为若干等价类,在每一个等价类中取一个数据作为测试的输入条件,就可以用少量代表性的测试数据.取得较好的测试结果.等价类划分可有两种不同的情况:有效等价类和无效等价类.
2.边界值分析法
边界值分析方法是对等价类划分方法的补充。测试工作经验告诉我,大量的错误是发生在输入或输出范围的边界上,而不是发生在输入输出范围的内部.因此针对各种边界情况设计测试用例,可以查出更多的错误.
使用边界值分析方法设计测试用例,首先应确定边界情况.通常输入和输出等价类的边界,就是应着重测试的边界情况.应当选取正好等于,刚刚大于或刚刚小于边界的值作为测试数据,而不是选取等价类中的典型值或任意值作为测试数据.
3.错误推测法
基于经验和直觉推测程序中所有可能存在的各种错误, 从而有针对性的设计测试用例的方法.
错误推测方法的基本思想: 列举出程序中所有可能有的错误和容易发生错误的特殊情况,根据他们选择测试用例. 例如, 在单元测试时曾列出的许多在模块中常见的错误. 以前产品测试中曾经发现的错误等, 这些就是经验的总结. 还有, 输入数据和输出数据为0的情况. 输入表格为空格或输入表格只有一行. 这些都是容易发生错误的情况. 可选择这些情况下的例子作为测试用例.
4.因果图方法
前面介绍的等价类划分方法和边界值分析方法,都是着重考虑输入条件,但未考虑输入条件之间的联系, 相互组合等. 考虑输入条件之间的相互组合,可能会产生一些新的情况. 但要检查输入条件的组合不是一件容易的事情, 即使把所有输入条件划分成等价类,他们之间的组合情况也相当多. 因此必须考虑采用一种适合于描述对于多种条件的组合,相应产生多个动作的形式来考虑设计测试用例. 这就需要利用因果图(逻辑模型). 因果图方法最终生成的就是判定表. 它适合于检查程序输入条件的各种组合情况.
- 当开发人员说不是BUG时,你如何应付?
开发人员说不是bug,有2种情况,一是需求没有确定,所以我可以这么做,这个时候可以找来产品经理进行确认,需不需要改动,3方商量确定好后再看要不要改。二是这种情况不可能发生,所以不需要修改,这个时候,我可以先尽可能的说出是BUG的依据是什么?如果还是不行,那我可以给这个问题提出来,跟开发经理和测试经理进行确认,如果要修改就改,如果不要修改就不改。其实有些真的不是bug,我也只是建议的方式写进TD中,如果开发人员不修改也没有大问题。如果确定是bug的话,一定要坚持自己的立场,让问题得到最后的确认。
将问题提交到缺陷管理库里面进行备案。
要获取判断的依据和标准: 根据需求说明书、产品说明、设计文档等,确认实际结果是否与计划有不一致的地方,提供缺陷是否确认的直接依据; 如果没有文档依据,可以根据类似软件的一般特性来说明是否存在不一致的地方,来确认是否是缺陷; 根据用户的一般使用习惯,来确认是否是缺陷;
与设计人员、开发人员和客户代表等相关人员探讨,确认是否是缺陷;
合理的论述,向测试经理说明自己的判断的理由,注意客观、严谨,不参杂个人情绪。
等待测试经理做出最终决定,如果仍然存在争议,可以通过公司政策所提供的渠道,向上级反映,并有上级做出决定。
- 开发人员说需求无法实现
- 写出bug报告当中一些必备的内容。
一条 Bug 记录最基本应包含:编号、Bug 所属模块、Bug 描述、Bug 级别、发现日期、发现人、修改日期、修改人、修改方法、回归结果等等;
- 游戏测试
- 对redis了解吗
- app测试
数据结构
- 讲一下链表的插入和搜索的时间复杂度
单向链表要删除某一节点时,必须要先通过遍历的方式找到前驱节点(通过待删除节点序号或按值查找)。若仅仅知道待删除节点,是不能知道前驱节点的,故单链表的增删操作复杂度为O(n)。
双链表(双向链表)知道要删除某一节点p时,获取其前驱节点q的方式为 q = p->prior,不必再进行遍历。故时间复杂度为O(1)。而若只知道待删除节点的序号,则依然要按序查找,时间复杂度仍为O(n)。
单、双链表的插入操作,若给定前驱节点,则时间复杂度均为O(1)。否则只能按序或按值查找前驱节点,时间复杂度为O(n)。
至于查找,二者的时间复杂度均为O(n)。 对于最基本的CRUD操作,双链表优势在于删除给定节点。但其劣势在于浪费存储空间(若从工程角度考量,则其维护性和可读性都更低)。
- 哈希,哈希列表与哈希链表
哈希表(散列表),是基于关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数(哈希函数),存放记录的数组叫做散列表。
直接定址法、除留余数法、数字分析法 、随机数法 、平方取中法、折叠法
冲突解决:开放地址法、二次探测再散列、多哈希法、拉链法 、建立一个公共溢出区
哈希链表
linux内核中的哈希链表和其他链表不一样。他是头节点用单个的链表,只有next指针,但其他链表节点是有next和prev两个指针的双链表。
linux内核处理冲突的方法是
链地址法,hash链表中存在两种结构体,
一种是hash表头,一种是hash节点。
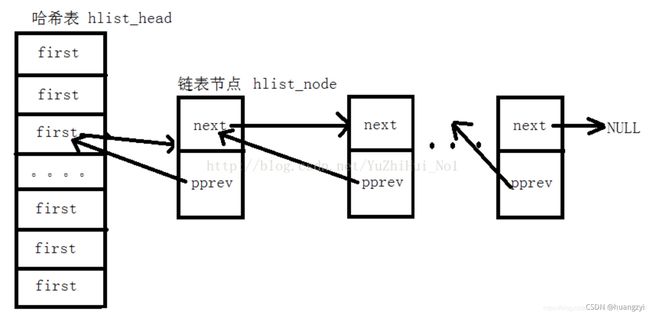
- 常用结构
- 冒泡排序和快速排序,什么情况下快速排序变成冒泡排序

- 链表和列表区别。为什么链表增删快,列表查找快
操作系统
- 协程
协程, 又称微线程, 纤程。 英文名 Coroutine, 是一种用户态的轻量级线程。
子程序, 或者称为函数, 在所有语言中都是层级调用, 比如 A 调用 B, B 在执行过程
中又调用了 C, C 执行完毕返回, B 执行完毕返回, 最后是 A 执行完毕。 所以子程序调用是
通过栈实现的, 一个线程就是执行一个子程序。 子程序调用总是一个入口, 一次返回, 调用
顺序是明确的。 而协程的调用和子程序不同。
线程是系统级别的它们由操作系统调度, 而协程则是程序级别的由程序根据需要自己调
度。 在一个线程中会有很多函数, 我们把这些函数称为子程序, 在子程序执行过程中可以中
断去执行别的子程序, 而别的子程序也可以中断回来继续执行之前的子程序, 这个过程就称
为协程。 也就是说在同一线程内一段代码在执行过程中会中断然后跳转执行别的代码, 接着
在之前中断的地方继续开始执行。
协程拥有自己的寄存器上下文和栈。 协程调度切换时, 将寄存器上下文和栈保存到其他
地方, 在切回来的时候, 恢复先前保存的寄存器上下文和栈。 因此: 协程能保留上一次调用
时的状态(即所有局部状态的一个特定组合) , 每次过程重入时, 就相当于进入上一次调用
的状态, 换种说法: 进入上一次离开时所处逻辑流的位置。
- 进程和线程差别
线程是进程中执行运算的最小单位,是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。一个线程可以创建和撤消另一个线程,同一进程中的多个线程之间可以并发执行。
好处 :(1)易于调度。
(2)提高并发性。通过线程可方便有效地实现并发性。进程可创建多个线程来执行同一程序的不同部分。
(3)开销少。创建线程比创建进程要快,所需开销很少。。
(4)利于充分发挥多处理器的功能。通过创建多线程进程,每个线程在一个处理器上运行,从而实现应用程序的并发性,使每个处理器都得到充分运行
进程与线程
进程:每个进程都有独立的代码和数据空间(进程上下文),进程间的切换会有较大的开销,一个进程包含1--n个线程。(进程是资源分配的最小单位)
线程:同一类线程共享代码和数据空间,每个线程有独立的运行栈和程序计数器(PC),线程切换开销小。(线程是cpu调度的最小单位)
nlp
- 讲讲nlp
php
- php 怎么工作的
java
- 继承
- 基本数据类型
byte(位)、short(短整数)、int(整数)、long(长整数)、float(单精度)、double(双精度)、char(字符)和boolean(布尔值)
- 多态
多态是同一个行为具有多个不同表现形式或形态的能力。
多态就是同一个接口,使用不同的实例而执行不同操作,
- 设计模式
- 复制值与地址的区别
值传递(pass by value)是指在调用函数时将实际参数 复制 一份传递到函数中,这样在函数中如果对 参数 进行修改,将不会影响到实际参数。传递对象往往为整型浮点型字符型等基本数据结构。
地址传递(pass by reference)是指在调用函数时将实际参数的地址 直接 传递到函数中,那么在函数中对 参数 所进行的修改,将影响到实际参数。(类似于共同体) 传递对象往往为数组等地址数据结构。
- 旧gc和新gc的
git
- 怎么协作
- 怎么进行版本控制
diff, log, status
- 使用
pull, push
- 分支
branch, checkout, merge
- 多人同时上传
remote 查看远程仓库
- fetch和pull区别
- git和svn区别
- commit后,从版本10回退到版本9会保留版本9还是保留1-9
算法
1. 给出一个整型数组 numbers 和一个目标值 target,请在数组中找出两个加起来等于目标值的数的下标,返回的下标按升序排列。
讲两个思路。给10分钟解决
2. 最长不重复子字符串
3. 将相互认识的群聊里的人分成两个互不认识的群聊
正则表达式
- 怎么匹配11位的手机号
项目/实习
- 难点
- 收获、不足、遗憾
- 成就
hr
- 自我介绍
- 最困难的事,怎么解决的
- 你的优势
- 怎么理解执行力
- 应聘理由
- 职业规划,达成这个目标要做的努力
- 兴趣爱好
- 为什么选择上海/杭州
- 你了解我们公司吗?(国企)
- 对加班怎么看
- 最大成就
- 怎么进行学习
- 倾向于协作还是独立开发
- 家庭情况
- 有什么要补充的
- 还有什么要问的吗
建议
1. 尽量不做技术支持
2. 银行转岗,不建议做柜台
参考链接:
计网:计算机网络之面试常考_笔经面经_牛客网
mysql: 程序员校招必看系列一:MySQL八股文背诵版_云峰小罗-CSDN博客
测试:2021年软件测试面试题大全_hard_days的博客-CSDN博客_软件测试面试题