机器学习笔记-DBSCAN
DBSCAN简介
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。
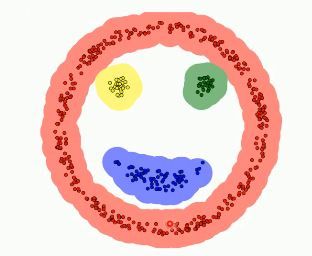
DBSCAN中的特定定义:
Ε邻域:给定对象半径为Ε内的区域称为该对象的Ε邻域;如下图所示,以p为核心点的E为半径的区域。

核心对象:如果给定对象Ε邻域内的样本点数大于等于MinPts,则称该对象为核心对象;
直接密度可达:对于样本集合D,如果样本点q在p的Ε邻域内,并且p为核心对象,那么对象q从对象p直接密度可达。如上图中,若点p为核心对象,则M点在P的领域内则称为直接密度可达。
密度可达:对于样本集合D,给定一串样本点p1,p2….pn,p= p1,q= pn,假如对象pi从pi-1直接密度可达,那么对象q从对象p密度可达。如上图中,P到M为直接密度可达,M到Q为直接密度可达,则p到Q为密度可达。
密度相连:存在样本集合D中的一点o,如果对象o到对象p和对象q都是密度可达的,那么p和q密度相联。
DBSCAN步骤如下所示:
输入:数据集,邻域半径 Eps,邻域中数据对象数目阈值 MinPts;输出:密度联通簇。处理流程如下。
1)从数据集中任意选取一个数据对象点 p;
2)如果对于参数 Eps 和 MinPts,所选取的数据对象点 p 为核心点,则找出所有从 p 密度可达的数据对象点,形成一个簇;
3)如果选取的数据对象点 p 是边缘点,选取另一个数据对象点;
4)重复(2)、(3)步,直到所有点被处理。
DBSCAN 算法的计算复杂的度为 O(n²),n 为数据对象的数目。这种算法对于输入参数 Eps 和 MinPts 是敏感的。
DBSCAN优缺点
优点
-
与K-Means方法相比,DBSCAN不需要事先知道要形成的簇类的数量。
-
与K-Means方法相比,DBSCAN可以发现任意形状的簇类。
-
同时,DBSCAN能够识别出噪声点。
4.DBSCAN对于数据库中样本的顺序不敏感,即Pattern的输入顺序对结果的影响不大。但是,对于处于簇类之间边界样本,可能会根据哪个簇类优先被探测到而其归属有所摆动。
缺点
-
DBSCAN不能很好反映高维数据。
-
DBSCAN不能很好反映数据集以变化的密度。
-
如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差。
DBSCAN实现
导包:
from sklearn.cluster import DBSCAN
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
plt.style.use('ggplot')
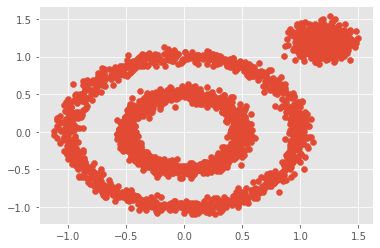
随机生成数据并可视化
x1,y1=datasets.make_circles(n_samples=2000,factor=0.5,noise=0.05)
x2,y2=datasets.make_blobs(n_samples=1000,centers=[[1.2,1.2]],cluster_std=[[.1]])
x=np.concatenate((x1,x2))
plt.scatter(x[:,0],x[:,1],marker='o')
plt.show()
可视化结果如图所示:
使用K-Means算法进行聚类
y_pred=KMeans(n_clusters=3).fit_predict(x)
plt.scatter(x[:,0],x[:,1],c=y_pred)
plt.show()
K-Means算法聚类结果

使用DBSCAN算法使用默认参数进行聚类进行聚类
predict=DBSCAN().fit_predict(x)#不传任何参数时会使用默认值
plt.scatter(x[:,0],x[:,1],c=predict)
plt.show()
聚类结果如下图所示:

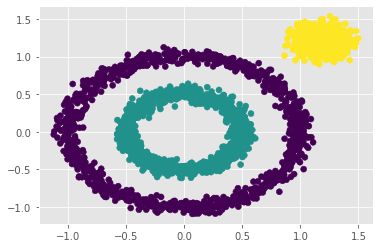
使用eps=0.2 min_samples=50进行DBSCAN聚类
predict=DBSCAN(eps=0.2,min_samples=50).fit_predict(x)
plt.scatter(x[:,0],x[:,1],c=predict)
plt.show()
聚类结果如下图所示:
原文链接:https://blog.csdn.net/hansome_hong/article/details/107596543
参考视频:https://www.bilibili.com/video/BV1Rt411q7WJ?p=71&vd_source=166e4ef02c5e9ffa3f01c2406aec1508
details/107596543