BigQuery ML功能上新:时间序列和非时间序列数据的无监督异常检测
在涉及到异常检测时,很多时候面临的主要挑战是很难对异常进行定义,举个栗子,我们该如何定义和预测异常网络入侵、系统缺陷和安全欺诈呢?如果已经标记了已知的异常数据,那么我们可以从 BigQuery ML 中已支持的各种受监督的机器学习模型(详情见下方链接)类型中进行选择。但是,如果我们不知道会发生异常,并且没有标记数据,我们可以做什么呢?与利用监督学习的典型预测技术不同,这个时候我们可能需要能够在没有标记数据的情况下检测异常。
机器学习模型:https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-create#create_model_syntax
七月初,Google 对外宣布在 BigQuery ML 中公开预览新的异常检测功能,该功能利用无人监督的机器学习来帮助检测异常,而无需标记数据。根据训练数据是否为时间序列,用户现在可以使用新的 ML.DETECT_ANOMALIES 函数使用以下模型检测训练数据或新输入数据中的异常:
-
Autoencoder 模型,正在内测;
-
K- means 模型,已对外开放;
-
ARIMA_PLUS 时间系列模型,已对外开放。
如何使用 ML.DETECT_ANOMALIES 模型进行异常检测?
要检测非时间系列数据中的异常,我们可以使用:
K-means 聚类模型:当使用 K-means 模型时,根据每个输入数据点与其最近集群的规范化距离值来识别异常。如果该距离超过用户提供的污染值确定的阈值,则数据点被识别为异常。
Autoencoder 模型:当使用Autoencoder 模型时,会根据每个数据点的重建错误来识别异常。如果错误超过由污染值确定的阈值,则将其识别为异常。
要检测时间系列数据中的异常,可以使用:
ARIMA_PLUS 时间系列模型:在使用 ARIMA_PLUS 模型时,会根据该时间戳的置信区间识别异常。如果时间戳中的数据点发生在预测区间之外的概率超过用户提供的概率阈值,则数据点被识别为异常。
下面我们一一展示每个场景的 BigQuery ML 中异常检测的代码示例。
CREATE MODEL `mydataset.my_kmeans_model`OPTIONS(MODEL_TYPE = 'kmeans',NUM_CLUSTERS = 8,KMEANS_INIT_METHOD = 'kmeans++') ASSELECT* EXCEPT(Time, Class)FROM`bigquery-public-data.ml_datasets.ulb_fraud_detection`;
训练 K-means 聚类模型后,运行 ML.DETECT_ANOMALIES 以检测训练数据或新输入数据中的异常。这时需使用 ML.DETECT_ANOMALIES 与训练期间使用的相同数据:
SELECT*FROMML.DETECT_ANOMALIES(MODEL `mydataset.my_kmeans_model`,STRUCT(0.02 AS contamination),TABLE `bigquery-public-data.ml_datasets.ulb_fraud_detection`);
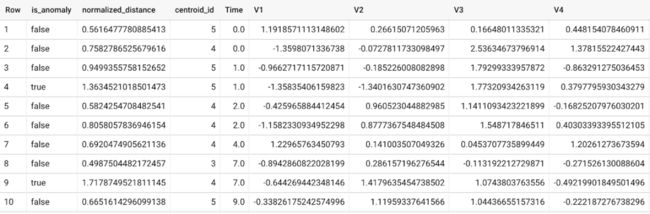
还需使用 ML.DETECT_ANOMALIES 并提供新数据作为输入:
SELECT*FROMML.DETECT_ANOMALIES(MODEL `mydataset.my_kmeans_model`,STRUCT(0.02 AS contamination),(SELECT * FROM `mydataset.newdata`));

K-means 聚类模型的异常检测是如何工作的?
异常是基于每个输入数据点到其最近集群的归一化距离的值来识别的,如果超过由污染值确定的阈值,则将其识别为异常。以 K-means 模型和数据作为输入,ML.DETECT_ANOMALIES 首先计算每个输入数据点到模型中所有聚类质心的绝对距离,然后通过各自的聚类半径(定义为该簇中所有点到质心的绝对距离)。对于每个数据点,ML.DETECT_ANOMALIES 根据 normalized_distance 返回最近的 centroid_id,如上面的屏幕截图所示。用户指定的污染值决定了数据点是否被视为异常的阈值。例如,污染值为 0.1 意味着从训练数据降序归一化距离的前 10% 将用作截止阈值。如果数据点的归一化距离超过阈值,则将其识别为异常。设置适当的污染将高度依赖于用户或企业的要求。
有关使用 K-means 聚类进行异常检测的更多信息,可阅读:
https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-detect-anomalies#kmeans_model_example
使用 Autoencoder 模型进行异常检测
使用 Autoencoder 模型,通过运行 ML.DETECT_ANOMALIES 来检测训练数据或新输入数据中的异常。
首先创建一个 Autoencoder 模型:
CREATE MODEL `mydataset.my_autoencoder_model`OPTIONS(model_type='autoencoder',activation_fn='relu',batch_size=8,dropout=0.2,hidden_units=[32, 16, 4, 16, 32],learn_rate=0.001,l1_reg_activation=0.0001,max_iterations=10,optimizer='adam') ASSELECT* EXCEPT(Time, Class)FROM`bigquery-public-data.ml_datasets.ulb_fraud_detection`;
要检测训练数据中的异常,需使用 ML.DETECT_ANOMALIES 与训练期间使用的相同数据:
SELECT*FROMML.DETECT_ANOMALIES(MODEL `mydataset.my_autoencoder_model`,STRUCT(0.02 AS contamination),TABLE `bigquery-public-data.ml_datasets.ulb_fraud_detection`)
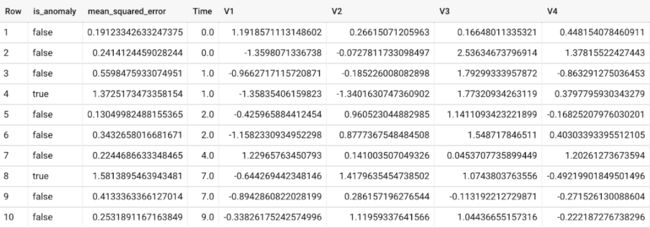
要检测新数据中的异常,需使用 ML.DETECT_ANOMALIES 并提供新数据作为输入:
SELECT*FROMML.DETECT_ANOMALIES(MODEL `mydataset.my_autoencoder_model`,STRUCT(0.02 AS contamination),(SELECT * FROM `mydataset.newdata`));

Autoencoder 模型的异常检测如何工作?
异常基于每个输入数据点的重构误差值进行识别,如果超过由污染值确定的阈值,则将其识别为异常。使用 Autoencoder 模型和数据作为输入,ML.DETECT_ANOMALIES 首先计算每个数据点的原始值和重建值之间的 mean_squared_error。用户指定的污染值决定了数据点是否被视为异常的阈值。例如,污染值为 0.1 意味着训练数据降序误差的前 10% 将用作截止阈值。设置适当的污染将高度依赖于用户或企业的要求。
有关使用 Autoencoder 模型进行异常检测的更多信息,可以阅读文档:
https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-detect-anomalies#autoencoder_model_example
使用 ARIMA_PLUS 时间序列模型进行异常检测
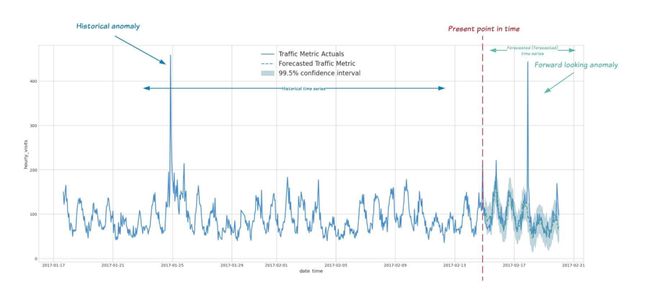
我们现在可以使用 ARIMA_PLUS 时间序列模型在(历史)训练数据或新输入数据中检测异常。以下是部分场景下检测时间序列数据异常的一些示例:
检测历史数据中的异常:
清理用于预测和建模目的的数据,例如在使用历史时间序列训练 ML 模型之前对其进行预处理。
例如,当有大量的零售需求时间序列(数百家商店或邮政编码中的数千种产品)时,我们可能希望快速确定哪些商店和产品类别具有异常的销售模式,然后对出现异常的原因进行更深入的分析案子。
前瞻性异常检测:
尽早检测消费者行为和定价异常:例如如果特定产品页面的流量突然意外激增,可能是由于定价过程中的错误导致价格异常低。
当有大量的零售需求时间序列(数百家商店或邮政编码的数千种产品)时,我们可以根据预测确定哪些商店和产品类别的销售模式存在异常,以便可以快速响应任何意外的尖峰或低谷。
那么如何使用 ARIMA_PLUS 检测异常?首先创建一个 ARIMA_PLUS 时间序列模型:
CREATE OR REPLACE MODEL mydataset.my_arima_plus_modelOPTIONS(MODEL_TYPE='ARIMA_PLUS',TIME_SERIES_TIMESTAMP_COL='date',TIME_SERIES_DATA_COL='total_amount_sold',IME_SERIES_ID_COL='item_name',HOLIDAY_REGION='US') ASSELECTdate,item_description AS item_name,SUM(bottles_sold) AS total_amount_soldFROM`bigquery-public-data.iowa_liquor_sales.sales`GROUP BYdate,item_nameHAVINGdate BETWEEN DATE('2016-01-04') AND DATE('2017-06-01')AND item_name IN ("Black Velvet", "Captain Morgan Spiced Rum","Hawkeye Vodka", "Five O'Clock Vodka", "Fireball Cinnamon Whiskey")
要检测训练数据中的异常,还需对上面获得的模型使用 ML.DETECT_ANOMALIES
SELECT*FROMML.DETECT_ANOMALIES(MODEL `mydataset.my_arima_plus_model`,STRUCT(0.8 AS anomaly_prob_threshold));
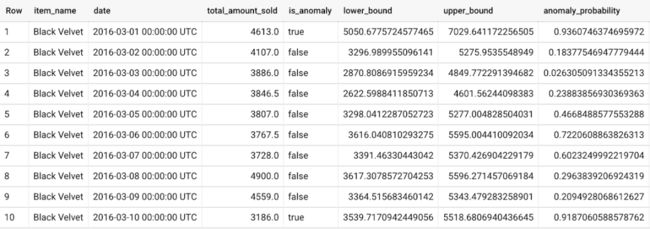
另外,我们还要使用 ML.DETECT_ANOMALIES 并提供新数据作为输入:
WITHnew_data AS (SELECTdate,item_description AS item_name,SUM(bottles_sold) AS total_amount_soldFROM`bigquery-public-data.iowa_liquor_sales.sales`GROUP BYdate,item_nameHAVINGdate BETWEEN DATE('2017-06-02')AND DATE('2017-10-01')AND item_name IN ('Black Velvet','Captain Morgan Spiced Rum','Hawkeye Vodka',"Five O'Clock Vodka",'Fireball Cinnamon Whiskey') )SELECT*FROMML.DETECT_ANOMALIES(MODEL `mydataset.my_arima_plus_model`,STRUCT(0.8 AS anomaly_prob_threshold),(SELECT*FROMnew_data));
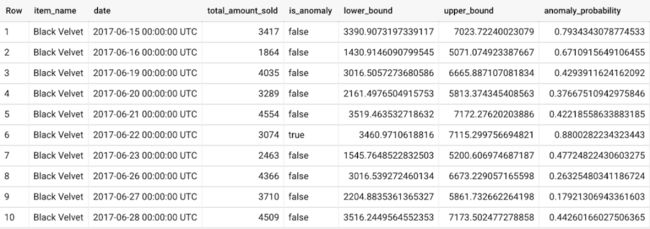
最后,有关使用 ARIMA_PLUS 时间序列模型进行异常检测的更多信息,可参考文档:https://cloud.google.com/bigquery-ml/docs/reference/standard-sql/bigqueryml-syntax-detect-anomalies#arima_plus_model_example_without_specified_settings
编译自:What's new with BigQuery ML: Unsupervised anomaly detection for time series and non-time series data