RCNN网络源码解读(Ⅰ) --- 获取数据并预处理数据
目录
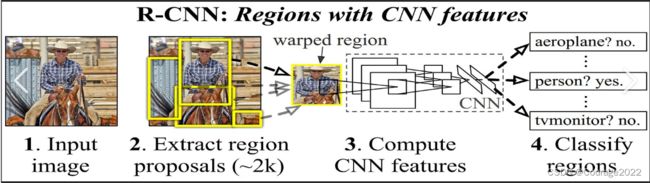
1.RCNN是什么东西
2.处理数据集
2.1 code:下载VOC数据集(pascal_voc.py)
2.2 code: 数据集预处理(pascal_voc_car.py)
3.code区域候选建议(selectivesearch.py)
1.RCNN是什么东西
主要做目标检测用的。
2.处理数据集
你要做目标检测,你要训练数据,你要检测数据,那么这些训练数据是如何获取,哪里下载、如何处理是我们需要知道的。
我们这里用PASCAL VOC数据集。
2.1 code:下载VOC数据集(pascal_voc.py)
pascal_voc.py
import cv2 import numpy as np from torchvision.datasets import vocDetection if __name__ == '__main__': """ 下载PASCAL VOC数据集 """ dataset = VOCDetection('../../data' , year='2007', image_set = 'trainval' , download = True) #打印dataset的大小 print(len(dataset)) #取到这张图片及target img,target = dataset._getitem__(202) img = np.array(img) print(target) print(img.shape) cv2.imshow('img',img) cv2.waitKey(0)vocDetection里面有软件包的数据,直接下载即可。
getitem方法可以取得该数据集的某张图片。
img是一张图片。
这个数据集一共有5011张图片,因此len(dataset)的值为5011。
target是什么呢?我们第202张图片来说:
{'anotation' : {'foldr':'VOC2007', 'filename':'002070.jpg','source' : {'database': 'The VOC2007 Database' , annotation : 'PASCAL VOC 2007','image': 'flicker' ,'flickerid' : '313674620'}, 'size':{'width':'500','height':'189','depth':'3'},'object':{'name':'sofa','pose':'frontal','difficulty':'0','bndbox':'xmin':'8','ymin':'32','xmax':'493','ymax':'173'}}}}这里比较重要的信息就是:
filename是文件(图片)名称
图片大小
bndbox:是框体大小(标定的大小)
'bndbox':'xmin':'8','ymin':'32','xmax':'493','ymax':'173'我们看看这是什么意思:
我们更改这部分的代码:
def draw_box_with_text(img,rect_list,score.list): """ 绘制边框其分类概率 :param img: : param rect_list: : param score_list: : return: """ for i in range(len(rect_list)): xmin,ymin,xmax,ymax = rect_list[i] score = score_list[i] cv2.rectangle(img,(xmin,ymin),(xmax,ymax),color=(0,0,255),thickness=1) cv2.putText(img,"{:.3f}".format(score),(xmin,ymin),cv2.FONT_HERSHEY_SINPLEX,0.5,(255,255,255),1)def draw_box_with_text(img,xmin,ymin,xmax,ymax,text): cv2.rectangle(img,(xmin,ymin),(xmax,ymax),color=(0,0,255),thickness=1) cv2.putText(img,"{:.3f}".format(text),(xmin,ymin),cv2.FONT_HERSHEY_SINPLEX,0.5,(255,255,255),1)更改主函数:
import cv2 import numpy as np from torchvision.datasets import vocDetection if __name__ == '__main__': """ 下载PASCAL VOC数据集 """ dataset = VOCDetection('../../data' , year='2007', image_set = 'trainval' , download = True) #打印dataset的大小 print(len(dataset)) #取到这张图片及target img,target = dataset._getitem__(202) #弄懂bndbox是什么 draw_box_with_text(img,8,32,493,173,'sofa') img = np.array(img) print(target) print(img.shape) cv2.imshow('img',img) cv2.waitKey(0)
我们可以看到这个小沙发被框体框住了。
因此,通过这个函数,我们收集了PASCAL VOC 2007数据集,这个数据集共有5011张照片,且每张图片有标注信息(bndbox),我们可以拿这个数据集做监督学习的标准。

2.2 code: 数据集预处理(pascal_voc_car.py)
在RCNN论文中,有如下的流程:
一张图片经过处理之后会选出一些框,每个框经过CNN网络之后实现一个二分类。
在处理一张图片时,我们不是将一张图片中的所有图像类别判定出来,而是每次训练一类数据,判断框体里面是否含有这一类的数据。
因此RCNN的过程主要是:抽取数据集中的任何一个类别的数据,作为训练对象。(将这种训练的过程重复进行N次(N是指类别数量)
我们看看VOC2007数据集的目录结构:总共有20类,每个类别有四种数据(训练集train,训练集+测试集trainval,测试集val,test),每一个数据里面存放着照片的索引。RCNN是针对每一个类别都训练一个东西用于判别在图像里选出一堆框这堆框里面是不是这一类的。拿同样的图片到第二个类别再去比对,看看这个图片有没有第二类的东西............
也就是说,我们要训练20个模型(狗、马.....),然后用模型遍历20次我们的图片网格,从而判断一张图片里面有什么(听起来就很low,但是这是入门啊,后面我还会出mask-rcnn,faster-rcnn的教程的)。
因此数据预处理的第一步就是抽出一个类别的数据,只有抽出一个系别的数据,我们才能针对这种东西训练神经网络训练出一个二分类器来判断该张图片是否有该种物体。
这里我们拿处理汽车为例:
import os import shutil import random import numpy as np import xmltodict from util import check_dir #文件后缀 suffix_xml = '.xml' suffix_jpeg = '.jpg' #车的数据集的路径 car_train_path = '../../data/VOCdevkit/VOC2007/Imagesets/Main/car_train.txt' car_val_path = '../../data/VOCdevkit/VOC2007/Imagesets/Main/car_val.txt' #定义车的图片及标注的路径 voc_annotation_dir = '../../data/VOCdevkit/VOC2007/Annotations' voc_jpeg_dir = '../../data/VOCdevkit/VOC2007/JPEGImages/' #为以后创建car的目录用 car_root_dir = '../../data/voc_car/'VOC2007下的数据集文件
数据集car_train的内容如上,是voc_jppg_dir下的图片的索引,是不带后缀的。
就是说,car_train.txt里面的内容是图片的索引,图片的位置是在voc_jpeg_dir下。
我们的目的是建立一个汽车的数据集,即我们要创建car_root_dir目录存放关于车图片的数据集。如下:我们在voc_car的文件夹创立train和val目录,然后在创建标注文件和图片以及索引文件,再将数据从数据集中拷贝过去。
本小节最终目标,创立汽车数据集
我们看它的main函数:
if __name__ == '__main__': samples ={'train': parse_train_val(car_train_path),'val':parse_train_val(car_val_path)} print(samples) #samples = sample_train_val(samples) # print(samples) check_dir(car_root_dir) for name in ['train', 'val']: data_root_dir = os.path.join(car_root_dir, name) data_annotation_dir = os.path.join(data_root_dir,"Annotations ') data_jpeg_dir = os.path.join(data_root_dir,"JPEGImages ') check_dir(data_root_dir) check_dir(data_annotation_dir) check_dir(data_jpeg_dir) save_car(samples[name],data_root_dir,data_annotation_dir,data_jpeg_dir) print('done')这里面几个路径我们说明一下:
car_train_path = '../../data/VOCdevkit/VOC2007/Imagesets/Main/car_train.txt'
car_val_path = '../../data/VOCdevkit/VOC2007/Imagesets/Main/car_val.txt'我们将car_train_pat和car_val_path 传入 parse_train_val函数中,这个函数会将我们的索引文件car_train.txt和car_val.txt按行分割读取装入samples中。
因此,samples最后得到的是一个向量列表。
随后我们建立这些文件夹,check_dir的作用是检查文件夹是否存在,若不存在则创建。
os.path.join是拼接目录的函数。
data_root_dir = data/voc_car/train
data_annotation_dir = data/voc_car/train/annotation
data_jdpg_dir = data/voc_car/train/JPEGImages
最后然后处理samples中的数据。
def parse_train_val(data_path): """ 获取指定类别数据 """ samples=[] with open(data_path,'r') as file: lines = file.readlines() for line in lines: res = line.strip().split(' ') if len(res) == 3 and int(res[2]) == 1: samples.append(res[0]) return np.array(samples)def save_car(car_samples,data_root_dir,data_annotation_dir,data_jpeg_dir): """ 保存类别Car的样本图片和标注文件 """ #分别遍历val中和train中的sample数据放到对应文件夹里 #这里的samplename就是 train 或者 val 字符串 for sample_name in car_samples: src_annotation_path = os.path.join(voc_annotation_dir,sample_name +suffix_xml) dst_annotation_path = os.path.join(data_annotation_dir,sample_name +suffix_xml) shutil.copyfile(src_annotation_path, dst_annotation_path) src_jpeg_path = os.path.join(voc_jpeg_dir,sample_name + suffix_jpeg) dst_jpeg_path = os.path.join(data_jpeg_dir,sample_name + suffix_jpeg) shutil.copyfile(src_jpeg_path, dst_jpeg_path) csv_path = os.path.join(data_root_dir,'car.csv') np.savetxt(csv_path,np.array(car_samples), fmt='%s')这里目录:
src_annotation_path = data/VOCdevkit/VOC2007/annotations/009774.xml
dst_annotation_path = data/voc_car/train/annotation/009774.xml

3.code区域候选建议(selectivesearch.py)
import sys import cv2 def get_selective_search(): gs = cv2.ximgproc.segmentation.createselectiveSearchSegmentation() return gs区域候选建议是使用cv2的模块(opencv 3.4.2 版本有这个模块)
gs是定义了一个区域候选建议的一个方法。
该方法有s、f、q三种形式,根据方法不一样,选出来的候选框也不一样。config函数是进行配置,get_nects是进行画框的过程。
def config(gs,img,strategy='q'): gs.setBaseImage(img) if(strategy == 's'): gs.switchToSinglestrategy() elif(strategy == 'f'): gs.switchToSelectiveSearchFast() elif (strategy == 'q'): gs.switchToSelectivesearchQuality() else: print(__doc__) sys.exit(1) def get_nects(gs): rects =gs.process() rects[:,2] += rects[:, 0] rects[:,3] += rects[:, 1] return rects
论文说我们采用一个区域候选的方法在一个图中选出大约2K个搜索区域
if __name__ == ' __main__': """ 选择性搜索算法操作 """ gs = get_selective_search() img = cv2.imread('d:/code/R-CNN/imgs/00057905.jpg',cv2.IMREAD_COLOR) config(gs,img,strategy='q') rects = get_rects(gs) print(len(rects)) color = (255,255,255) rect_img(img, color, rects)rects得到框体,最后我们显示图像。
一个图像处理2000个候选框执行起来是这样,CPU运算会很慢
显示框体的函数如下:
def rect_ img(img,color,rects): for x1,y1,×2,y2 in rects[0:2000]: cv2.rectangle(img,(x1,y1),(x2,y2),,color,thickness=2) #cv2.putText(img,objectname,(x1,y1),cv.FONT_HERSHEY_COMPLEX,0.7,(0,255,0), # thickness=2) #cv2.imshow('head',img) cv2.imwnite('d:/code/R-CNN/imgs/00057903_rect.jpg',img)这个方法的缺点是使用cpu进行计算生成候选框,这就大大拖慢了我们预测时候的速度。预处理也很慢。