深度学习日常发问(三):激活函数性能对比
写在开头:今天主要分享一下对不同激活函数性能的理解,无大量案例支撑无专业性,仅当复习知识点。
内容介绍
在本节中我们会对常见的激活函数进行介绍,并介绍其优缺点,最后通过代码的实现来完成对比。
Q1:什么是激活函数?为什么需要激活函数?
Q2:激活函数有哪些?
Q3:这些激活函数之间图像有多大的差异?
Q4:那么怎么来检验各个激活函数之间的性能呢?
开始分享
Q4:那么怎么来检验各个激活函数之间的性能呢?
在此本文使用cifar-10的数据集来对神经网络进行训练,然后神经网络大体采用之前的文章,GPU与CPU当中搭建的小型VGG,这里需要说明的是对于一部分激活函数,Torch有自带的类可直接调用,但Mish、Swish和Maxout则需要自己编写,由于笔者还不太会Maxout的编写,就放一放,比较一起其他10个激活函数的性能,我们会从运行时间、训练集损失函数图像和测试集预测精度三个方面进行对比。代码的话,这里仅展示一个mish激活函数的封装版,至于替他的变化都很简单,会在文章末尾提供百度云盘下载链接的py文件进行。
下面是Mish的代码,首先需要加载数据和包,使用是CIFAR-10的数据,然后网络使用的是一个VGG6的近似网络,注意我们此处的网络都没有加BN层,
#加载包和数据
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import time
import matplotlib.pyplot as plt
import torch.optim as optim
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=0)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=0)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
#1.Mish
class Net(torch.nn.Module):
#网络结构
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 6, 5, 1, 2),
nn.Conv2d(6, 6, 5, 1, 2),
)
self.conv2 = nn.Sequential(
nn.Conv2d(6, 16, 5, 1, 2),
nn.Conv2d(16, 16, 5, 1, 2),
)
self.fc1 = nn.Linear(8*8*16, 80)
self.fc2 = nn.Linear(80, 10)
def mish(self, x):
x = x * F.tanh(F.softplus(x))
return x
def forward(self, x):
x = self.mish((F.max_pool2d(self.conv1(x), 2)))
x = self.mish((F.max_pool2d(self.conv2(x), 2)))
x = x.view(-1, 8*8*16)
x = self.mish(self.fc1(x))
x = self.fc2(x)
return x
#训练函数
def train(self):
starttime = time.time()
time.sleep(2.1) #延时2.1s
hist = []
for epoch in range(3):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
x, y = data
x, y = Variable(x.cuda()), Variable(y.cuda())
optimizer.zero_grad()
outputs = net(x)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
loss = loss.cpu()
# 结果展示
running_loss += loss
if i % 200 == 199:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 200))
hist.append(running_loss/200)
running_loss = 0.0
print('Finished Training')
endtime = time.time()
dtime = endtime - starttime
print("程序运行时间:%.8s s" % dtime)
return hist
#测试函数
def test(self):
correct = 0
total = 0
for data in testloader:
x, y = data
outputs = net(Variable(x.cuda()))
_, predicted = torch.max(outputs.data, 1)
total += y.size(0)
correct += (predicted.cpu() == y).sum()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
#绘制图像
def plot(self, hist):
plt.plot(hist)
plt.ylabel("Loss")
plt.show()
if __name__ == "__main__":
net = Net()
net = net.cuda()
criterion = nn.CrossEntropyLoss()
criterion = criterion.cuda()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
mish_loss = net.train()
net.test()
net.plot(mish_loss)
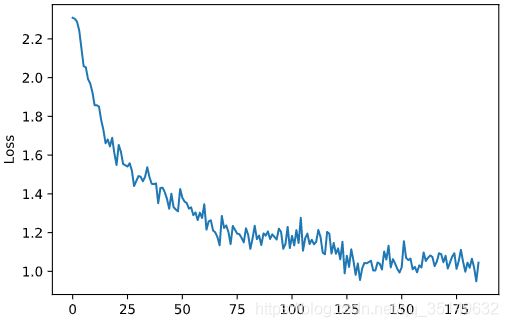
得到其运行部分结果如下,可以看到代码运行了大约320秒,并且在test集上预测准确度为62%,
[3, 11600] loss: 1.019
[3, 11800] loss: 1.065
[3, 12000] loss: 1.020
[3, 12200] loss: 0.948
[3, 12400] loss: 1.045
Finished Training
程序运行时间:320.6590 s
Accuracy of the network on the 10000 test images: 62 %
为了方便观察,使用的是平滑后的损失函数图像,可以看到整个趋势还是不断下降的,那么接下来直接上10个激活函数的对比结果分析。
下面展示10个激活函数运行的时间与test测试精度的结果,我们仅改变激活函数,且只是用一个激活函数,其他网络结构与训练内容不作变动,参数均使用默认参数,得到三个epoch训练一共花费的时间
| 激活函数 | 运行时间(秒) | 预测精度 |
|---|---|---|
| Tanh | 263.7317 | 58% |
| ReLU | 269.6835 | 57% |
| Sigmoid | 273.9964 | 29% |
| Softplus | 276.7813 | 54% |
| ELU | 281.8282 | 62% |
| Leaky ReLU | 281.9654 | 60% |
| Swish | 297.3703 | 64% |
| Mish | 320.6590 | 62% |
| PReLU | 330.5279 | 61% |
| Softsign | 344.7952 | 57% |
下面来分析一下结果,我们根据提出问题然后解答的模式来对结果进行探讨,
1:为什么Tanh速度比Softsign快,而且精度也比他高?
从运行结果可以看到Tanh的速度最快,而Softsign速度最慢,而且tanh的精度要比softsign高,但在前文分析中认为Softsign会比Tanh在饱和区域收敛效果更好,然而在测试中并没有验证这样的结论,这是为什么呢?在上一篇文章中指出Softsign的求导会比tanh慢,因为求导形式要复杂一点,那么我们再此提出猜测是不是训练次数不够多?让我们重新跑一下模型,这次将Epoch设置为12来看看效果。
当设置Epoch为12层后得到的损失函数如下,
| 激活函数 | 运行时间(s) | 预测精度 | 参数说明 |
|---|---|---|---|
| Softsign | 1387.35 | 61% | epochs = 12 |
| Tanh | 1143.246 | 58% | epochs = 12 |
softsign花费了1387.35秒,而tanh花费了1143.246秒,速度要快很多,但是可以看到随着训练次数的增加,softsign整体是在一直往下进行收敛的,而tanh的损失函数还有一种往回上升的趋势,即梯度饱和后不再进行梯度的更新,导致效果一般,而softsign就在这个地方解决了问题。tanh的预测精度为58%,softsign的预测精度为61%提高了3个百分点,整体效果如果在网络更复杂的时候tanh的表现会更加不如softsign。

2:ReLU、PReLU、LeakyReLU和ELU表现如何?
从3个epoch花费时间上来看,排名第二整体运算速度还是可以,但精度似乎处于倒数第三,在ReLU基础上为了解决负空间神经元死亡问题的有PReLU、Leaky ReLU、ELU,这三者的预测精度都要比ReLU好,并且三者之间精度差异不大,从这个角度可以看出确实解决了ReLU负空间的问题后能够提高预测精度,但是随之而来的就是计算代价的上升。整体来看ELU在提升精度上时间也得到有效的控制,对于PReLU因为没有加正则化更新,可能很快将其更新为0,使得下降速度减慢。所以有时为了追求速度一般常用ReLU激活函数。下面来看一下他们损失函数的变化情况,

从图像上来看,ELU确实是损失下降最快也是最小的,preleu的损失函数要比leakyrelu小,然后才是relu。也就是从损失图像来看relu差于leakyrelu差于prelu差于elu。但综合前面的时间来看,relu速度快的优势也可以加入考虑。
3:Sigmoid和Softplus两个损失函数咋样?
Sigmoid和Softplus是两个不以0为中心的激活函数,两者激活函数图像均在0的上方,这样就会导致效率的减慢,如果训练次数不够多的话很有可能没有到达收敛解就结束了,而且Softplus的负空间值很小很容易就导致饱和,因此速度更慢,因为两者都是由指数形式的激活函数速度要慢与ReLU,这样综合考虑其实ReLU是要比这两个都好的,下面来看一下两者的损失函数图像,
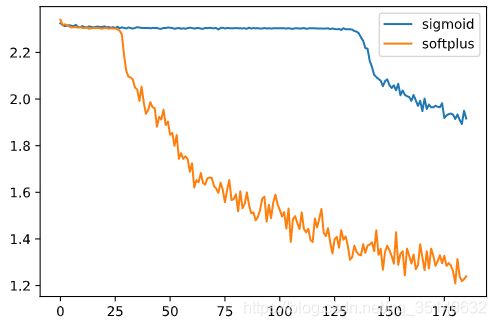
从图像上来看,证实了之前的观点因为这两个激活函数不是以0为中心,这样梯度下降的速度就很慢,从图中也可以看到,两个激活函数都是在一定的准备期过后才开始梯度下降,而sigmoid准备的时间更长,如果给两个函数足够多的训练次数可能效果会好很多,但其效率过低,很难让使用者满意。
4:Mish为何败与Swish?
根据前文的参考文献支出,Mish是在增加一点点复杂度的情况下,比Swish和ReLU要更好的模型,那么是在我们的设计中Swish要优一点还是训练次数不够导致,又或者说会不会是网路太浅导致的,而且Swish需要BN层的加入来提高效率,为了解决这个疑问,我们加入BN层来对比一下两者的效果,并且增加训练次数来看一下训练的效果,这里就不对网络层数进行改动,以后有机会会继续探究。
在每层卷积后都加入了BN层的网络,在epoch12的训练下,效果良好,Mish花费了1916.187s并且预测精度为70%,而Swish花费了1750.237s精度也达到了69%,从这样的结果来看,Mish只比Swish提高了一点点精度但多花费了100多秒,所以单单在我们的试验中这样一个案例下,Swish似乎表现更好,
| 激活函数 | 运行时间(s) | 预测精度 | 参数说明 |
|---|---|---|---|
| Swish | 1750.237 | 69% | epochs = 12,4层BN层 |
| Mish | 1916.187 | 70% | epochs = 12,4层BN层 |
下面我们来看一下两者的损失函数图吧,两者的损失函数图十分的接近,并且都呈现出了一种锯齿状,但总体趋势是在不断下降的,具体锯齿状的原因还不清楚,需要后续学习了后补充。刚刚问了老师说可以使用学习率衰减,后面学习了再更新。

5:那怎么选择激活函数呢?
从这一个样本和网络的训练不能得出任何的结论,并且还没有调参数,没有BN层,那么每个激活函数对于不同的网络和不同的数据都有着各自的特点,如果说你追求时间那就简单一点直接ReLU,如果你追求精度那可以尝试一下Mish和Swish,毕竟笔者网络还太浅无法展现他们的功力,所以这个激活函数也是因人而异,想用哪个用哪个,觉得哪个好用哪个,一般很多时候直接上ReLU.
结语
对于激活函数性能对比就到此结束了,本文只是一个简单的探讨不同激活函数的效果,没有大量的实例与数据,也没有很深的网络,仅当试一次小练习吧。
谢谢阅读。
代码下载请看:(使用的vscode中的jupyter模块编写,每个网络单独封装)
链接:https://pan.baidu.com/s/1xUPoHOgJJ3fnODQjIHxobg
提取码:8p29