Python实现奇异谱分析法(SSA)+LSTM的组合预测模型
1.引入包
import csv
import numpy as np
import time
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import explained_variance_score
from sklearn import metrics
from sklearn.svm import SVR
import matplotlib.pyplot as plt
from sklearn import metrics
from datetime import datetime
from pandas import Series
from pandas import concat
from pandas import read_csv
from pandas import DataFrame
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from math import sqrt
from matplotlib import pyplot
import random
from sklearn.metrics import mean_absolute_error # 平方绝对误差2.引入数据集
#时间
time=[]
#特征
feature=[]
#目标
target=[]
csv_file = csv.reader(open('新疆XXXX湿度.csv'))
for content in csv_file:
content=list(map(float,content))
if len(content)!=0:
feature.append(content[1:11])
target.append(content[0:1])
csv_file = csv.reader(open('新疆XXXX时间.csv'))
for content in csv_file:
content=list(map(str,content))
if len(content)!=0:
time.append(content)
targets=[]
for i in target:
targets.append(i[0])
feature.reverse()
targets.reverse()
# 标准化转换
scaler = StandardScaler()
# 训练标准化对象
scaler.fit(feature)
# 转换数据集
feature= scaler.transform(feature)
#str转datetime
time_rel=[]
for i,j in enumerate(time):
time_rel.append(datetime.strptime(j[0],'%Y/%m/%d %H:%M'))
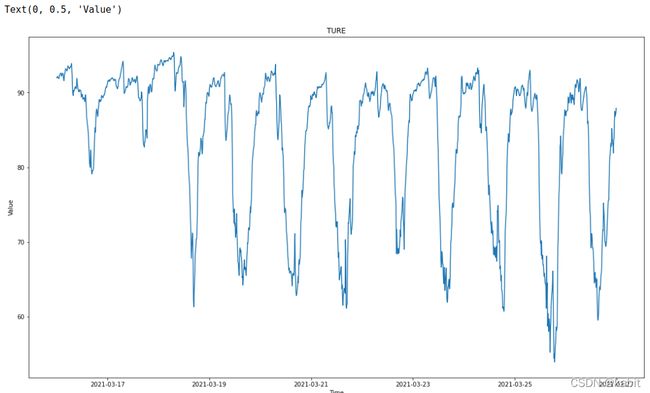
time_rel.reverse()
fig = plt.gcf()
fig.set_size_inches(18.5, 10.5)
plt.title('TURE')
plt.plot(time_rel, targets)
plt.xlabel('Time')
plt.ylabel('Value')图像是这样的,看起来没太大问题
3.奇异谱分析
# step1 嵌入
windowLen = 11 # 嵌入窗口长度
seriesLen = len(feature) # 序列长度
K = seriesLen - windowLen + 1
X = np.zeros((windowLen, K))
for i in range(K):
X[:, i] = targets[i:i + windowLen]
# step2: svd分解, U和sigma已经按升序排序
U, sigma, VT = np.linalg.svd(X, full_matrices=False)
for i in range(VT.shape[0]):
VT[i, :] *= sigma[i]
A = VT
# 重组
rec = np.zeros((windowLen, seriesLen))
for i in range(windowLen):
for j in range(windowLen-1):
for m in range(j+1):
rec[i, j] += A[i, j-m] * U[m, i]
rec[i, j] /= (j+1)
for j in range(windowLen-1, seriesLen - windowLen + 1):
for m in range(windowLen):
rec[i, j] += A[i, j-m] * U[m, i]
rec[i, j] /= windowLen
for j in range(seriesLen - windowLen + 1, seriesLen):
for m in range(j-seriesLen+windowLen, windowLen):
rec[i, j] += A[i, j - m] * U[m, i]
rec[i, j] /= (seriesLen - j)
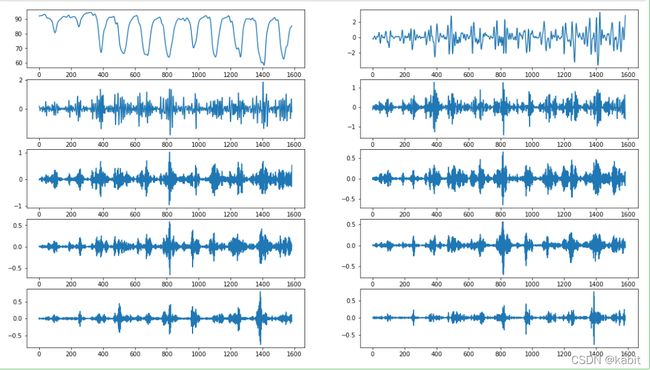
plt.figure()
fig = plt.gcf()
fig.set_size_inches(18.5, 10.5)
for i in range(10):
ax = plt.subplot(5,2,i+1)
ax.plot(rec[i, :])图像是这样的,需要自行选择一个阈值进行分组。正常是应该计算贡献度,我这里就简单计算比重>0.99了,阈值为0.1。
ax = plt.subplot(5,2,1)
ax.plot(rec[10, :])
fig = plt.gcf()
fig.set_size_inches(18.5, 10.5)
4.分组
rrr1 = rec[0,:]+rec[1,:]+rec[2,:]+rec[3,:]+rec[4,:]
rrr2 = +rec[5,:]+rec[6,:]+rec[7,:]+rec[8,:]+rec[9,:]+rec[10,:]5.将两组分别LSTM
rrr1:
from numpy.random import seed
seed(5)
import tensorflow
tensorflow.random.set_seed(5)
test=rrr1[int(len(targets)*0.9):int(len(targets))]
def timeseries_to_supervised(data, lag=1):
df = DataFrame(data)
columns = [df.shift(i) for i in range(1, lag+1)]
columns.append(df)
df = concat(columns, axis=1)
df.fillna(0, inplace=True)
return df
def fit_lstm(train, batch_size, nb_epoch, neurons):
X, y = train[:, 0:-1], train[:, -1]
X = X.reshape(X.shape[0], 1, X.shape[1])
model = Sequential()
model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
for i in range(nb_epoch):
model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False)
model.reset_states()
return model
# make a one-step forecast
def forecast_lstm(model, batch_size, X):
X = X.reshape(1, 1, len(X))
yhat = model.predict(X, batch_size=batch_size)
return yhat[0,0]
c2d=[]
for i in rrr1:
c2d.append([i,i])
scaler = StandardScaler() # 标准化转换
scaler.fit(c2d) # 训练标准化对象
supervised= scaler.transform(c2d) # 转换数据集
c1d=[]
for j in supervised:
c1d.append(j[0])
supervised = timeseries_to_supervised(c1d, 1)
train_scaled, test_scaled =supervised[0:int(len(supervised)*0.90)], supervised[int(len(supervised)*0.90):int(len(supervised))]
train_scaled=np.array(train_scaled)
test_scaled=np.array(test_scaled)
print("开始")
# fit the model
lstm_model = fit_lstm(train_scaled, 1, 10, 12)
# forecast the entire training dataset to build up state for forecasting
train_reshaped = train_scaled[:, 0].reshape(len(train_scaled), 1, 1)
lstm_model.predict(train_reshaped, batch_size=1)
# walk-forward validation on the test data
predictions = list()
for i in range(len(test_scaled)):
# make one-step forecast
X, y = test_scaled[i, 0:-1], test_scaled[i, -1]
yhat = forecast_lstm(lstm_model, 1, X)
# store forecast
predictions.append(yhat)
print("结束")
predictions2d=[]
for i in predictions:
predictions2d.append([i,i])
predictions2dsupervised= scaler.transform(c2d) # 转换数据集
predictions2d=scaler.inverse_transform(predictions2d)
predictions1d1=[]
for j in predictions2d:
predictions1d1.append(j[0])
# report performanceprint("MSE:",mean_sq2uared_error(test,predictions1d))
print("R2 = ",metrics.r2_score(test,predictions1d1)) # R2
# line plot of observed vs predicted
fig = pyplot.gcf()
fig.set_size_inches(18.5, 10.5)
pyplot.plot(test)
pyplot.plot(predictions1d1)
pyplot.legend(['True','R'])
pyplot.show()
rrr2:
from numpy.random import seed
seed(5)
import tensorflow
tensorflow.random.set_seed(5)
test=rrr2[int(len(targets)*0.9):int(len(targets))]
def timeseries_to_supervised(data, lag=1):
df = DataFrame(data)
columns = [df.shift(i) for i in range(1, lag+1)]
columns.append(df)
df = concat(columns, axis=1)
df.fillna(0, inplace=True)
return df
def fit_lstm(train, batch_size, nb_epoch, neurons):
X, y = train[:, 0:-1], train[:, -1]
X = X.reshape(X.shape[0], 1, X.shape[1])
model = Sequential()
model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
for i in range(nb_epoch):
model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False)
model.reset_states()
return model
# make a one-step forecast
def forecast_lstm(model, batch_size, X):
X = X.reshape(1, 1, len(X))
yhat = model.predict(X, batch_size=batch_size)
return yhat[0,0]
c2d=[]
for i in rrr2:
c2d.append([i,i])
scaler = StandardScaler() # 标准化转换
scaler.fit(c2d) # 训练标准化对象
supervised= scaler.transform(c2d) # 转换数据集
c1d=[]
for j in supervised:
c1d.append(j[0])
supervised = timeseries_to_supervised(c1d, 1)
train_scaled, test_scaled =supervised[0:int(len(supervised)*0.90)], supervised[int(len(supervised)*0.90):int(len(supervised))]
train_scaled=np.array(train_scaled)
test_scaled=np.array(test_scaled)
print("开始")
# fit the model
lstm_model = fit_lstm(train_scaled, 1, 10, 12)
# forecast the entire training dataset to build up state for forecasting
train_reshaped = train_scaled[:, 0].reshape(len(train_scaled), 1, 1)
lstm_model.predict(train_reshaped, batch_size=1)
# walk-forward validation on the test data
predictions = list()
for i in range(len(test_scaled)):
# make one-step forecast
X, y = test_scaled[i, 0:-1], test_scaled[i, -1]
yhat = forecast_lstm(lstm_model, 1, X)
# store forecast
predictions.append(yhat)
print("结束")
predictions2d=[]
for i in predictions:
predictions2d.append([i,i])
predictions2dsupervised= scaler.transform(c2d) # 转换数据集
predictions2d=scaler.inverse_transform(predictions2d)
predictions1d2=[]
for j in predictions2d:
predictions1d2.append(j[0])
# report performanceprint("MSE:",mean_sq2uared_error(test,predictions1d))
print("R2 = ",metrics.r2_score(test,predictions1d2)) # R2
# line plot of observed vs predicted
fig = pyplot.gcf()
fig.set_size_inches(18.5, 10.5)
pyplot.plot(test)
pyplot.plot(predictions1d2)
pyplot.legend(['True','R'])
pyplot.show()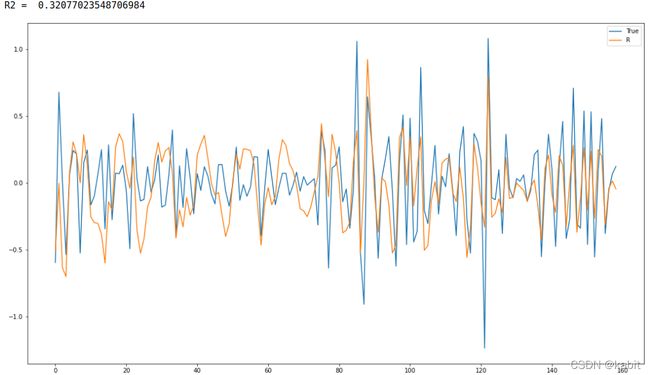
6.预测非SSA处理的LSTM模型
from numpy.random import seed
seed(5)
import tensorflow
tensorflow.random.set_seed(5)
test=targets[int(len(targets)*0.9):int(len(targets))]
def timeseries_to_supervised(data, lag=6):
df = DataFrame(data)
columns = [df.shift(i) for i in range(1, lag+1)]
columns.append(df)
df = concat(columns, axis=1)
df.fillna(0, inplace=True)
return df
def fit_lstm(train, batch_size, nb_epoch, neurons):
X, y = train[:, 0:-1], train[:, -1]
X = X.reshape(X.shape[0], 1, X.shape[1])
model = Sequential()
model.add(LSTM(neurons, batch_input_shape=(batch_size, X.shape[1], X.shape[2]), stateful=True,input_length=6))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
for i in range(nb_epoch):
model.fit(X, y, epochs=1, batch_size=batch_size, verbose=0, shuffle=False)
model.reset_states()
return model
# make a one-step forecast
def forecast_lstm(model, batch_size, X):
X = X.reshape(1, 1, len(X))
yhat = model.predict(X, batch_size=batch_size)
return yhat[0,0]
c2d=[]
for i in targets:
c2d.append([i,i])
scaler = StandardScaler() # 标准化转换
scaler.fit(c2d) # 训练标准化对象
supervised= scaler.transform(c2d) # 转换数据集
c1d=[]
for j in supervised:
c1d.append(j[0])
supervised = timeseries_to_supervised(c1d, 1)
train_scaled, test_scaled =supervised[0:int(len(supervised)*0.90)], supervised[int(len(supervised)*0.90):int(len(supervised))]
train_scaled=np.array(train_scaled)
test_scaled=np.array(test_scaled)
print("开始")
# fit the model
lstm_model = fit_lstm(train_scaled, 1, 10, 12)
# forecast the entire training dataset to build up state for forecasting
train_reshaped = train_scaled[:, 0].reshape(len(train_scaled), 1, 1)
lstm_model.predict(train_reshaped, batch_size=1)
# walk-forward validation on the test data
predictions = list()
for i in range(len(test_scaled)):
# make one-step forecast
X, y = test_scaled[i, 0:-1], test_scaled[i, -1]
yhat = forecast_lstm(lstm_model, 1, X)
# store forecast
predictions.append(yhat)
print("结束")
predictions2d=[]
for i in predictions:
predictions2d.append([i,i])
predictions2dsupervised= scaler.transform(c2d) # 转换数据集
predictions2d=scaler.inverse_transform(predictions2d)
predictions1d=[]
for j in predictions2d:
predictions1d.append(j[0])
# report performanceprint("MSE:",mean_sq2uared_error(test,predictions1d))
print("R2 = ",metrics.r2_score(test,predictions1d)) # R2
# line plot of observed vs predicted
fig = pyplot.gcf()
fig.set_size_inches(18.5, 10.5)
pyplot.plot(test)
pyplot.plot(predictions1d)
pyplot.legend(['True','R'])
pyplot.show()
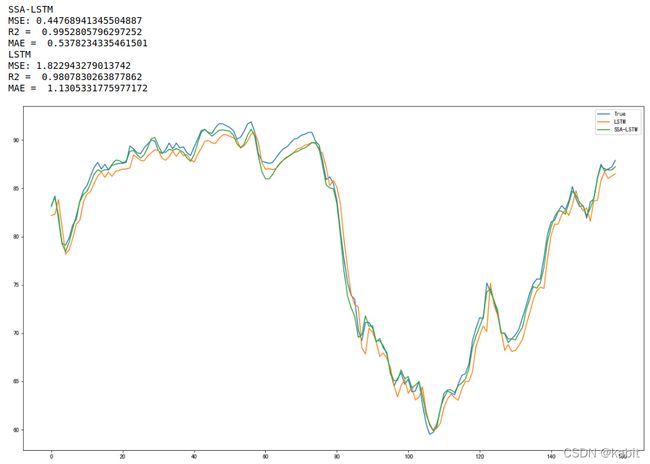
7.对比
将rrr1与rrr2的预测结果累加,与非SSA的LSTM预测模型作对比
predictions1d1=np.array(predictions1d1)
predictions1d2=np.array(predictions1d2)
ssalstm=predictions1d1+predictions1d2
testtest=targets[int(len(targets)*0.9):int(len(targets))]
print("SSA-LSTM")
print("MSE:",mean_squared_error(testtest,ssalstm))
print("R2 = ",metrics.r2_score(testtest,ssalstm)) # R2
print("MAE = ",mean_absolute_error(testtest,ssalstm)) # R2
print("LSTM")
print("MSE:",mean_squared_error(testtest,predictions1d))
print("R2 = ",metrics.r2_score(testtest,predictions1d)) # R2
print("MAE = ",mean_absolute_error(testtest,predictions1d)) # R2
# line plot of observed vs predicted
fig = pyplot.gcf()
fig.set_size_inches(18.5, 10.5)
pyplot.plot(testtest)
pyplot.plot(predictions1d)
pyplot.plot(ssalstm)
pyplot.legend(['True','LSTM','SSA-LSTM'])
pyplot.show()结果如下,各方面指标都显著提升: