FCN笔记
FCN的主要创新点在于通过微调普通的分类网络(如AlexNet,VGGNet,GoogleNet),将其后面的全连接层全部变成卷积层,以此实现端到端训练,适应任意尺寸的输入(好像并不是真正意义上的任意尺寸,输入的尺寸要求在五次下采样的过程中尺寸始终保持为偶数,因此在输入图像在输入网络前要经过裁剪),并通过反卷积进行上采样,输出相应尺寸的输出。同时使用了类似resnet的shortcut的跳跃连接将深层的,粗糙的语义信息和浅层的,精细的表征信息融合,以实现更加精细的语义分割。
FCN使用的主体特征提取网络是VGG16,并保存第三次和第四次下采样后得到的特征图,后面的全连接层使用卷积层代替,并在特征提取结束后对得到的heatmap使用五次反卷积进行上采样恢复成原图尺寸。
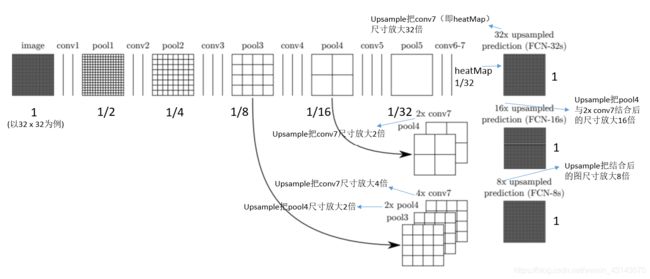
FCN8s:在第一次上采样后将得到的特征图与第四次下采样得到的特征图进行融合(add或通道融合),在第二次上采样后将得到的特征图与第三次下采样得到的特征图进行融合(add或通道融合),最后进行三次上采样恢复成原图尺寸;
FCN16s:在第一次上采样后将得到的特征图与第四次下采样得到的特征图进行融合(add或通道融合),然后进行四次上采样恢复成原图尺寸。
FCN32s:将特征提取结束后的heatmap直接反卷积恢复成原图尺寸。
分割指标计算:
1.PA(pixel accuracy):标记正确的像素个数占所有像素的比例。

2.mPA(mean pixel accuracy)计算每个类中标记正确的像素个数占该类的像素的比例,再求所有类的平均。

3.IoU:真实值和预测值的交集和并集之比(对于某一类)。
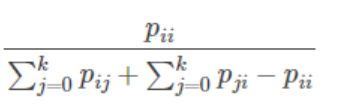
4.mIoU:真实值和预测值的交集和并集之比,并求平均。

实际计算指标时通常先用预测标签图和真实标签图构造一个confusion matrix,具体构造方法如下:

第一步根据预测标签和真实标签计算n*label+predict

第二步初始化一个n^2的数组,将n*label+predict中出现的元素的个数填入数组,具体可用np.bincount(初始化一个长度为输入数据最大值的numpy数组,统计输入数据中每个元素出现的次数)来实现

最后将这个numpy数组reshape成n*n的形状,得到的矩阵即为混淆矩阵

在混淆矩阵中,
PA=对角线之和 / 总和
PA = np.diag(confusion).sum() / confusion.sum()(np.diag()若输入一个一维数组,则返回一个以数组元素为对角线元素的二维矩阵,若输入为二维矩阵则返回该二维矩阵的对角线元素);
MPA= [(第0类中标记正确的/第0类总和) + (第1类中标记正确的/第1类总和) + ... + (第k类中标记正确的/第k类总和)] / (k+1)
class_accuracy = np.nanmean(np.diag(confusion) / np.sum(confusion, axis=1)) (np.nanmean在计算均值时将nan取值为0,并在分母中忽略这一项,因为nan代表这一类别的物体在图中并没有出现,我们希望的是nan不参与计算,而不是将nan当成0来算平均);
IoU = pii / (第i行元素和+第i列元素和 - pii),mIoU对每一类的IoU相加后的结果求平均
iou_denominator = (confusion.sum(axis=1) + confusion.sum(axis=0) - np.diag(confusion))
iou = np.diag(confusion) / iou_denominator
MIoU = np.nanmean(iou)