聚类分析-Python
聚类分析-Python
K-均值聚类
#读取数据
import psycopg2
import os
import pandas as pd
import numpy as np
#import math
from sklearn.cluster import KMeans
#from sklearn import metrics
import matplotlib.pyplot as plt
#from sklearn.cluster import DBSCAN
#from sklearn import preprocessing
#data = pd.read_csv('data.csv')#从表格读取
os.chdir('C:\\Users\\cx\\Desktop\\zc\\st')#设置默认路径
os.getcwd()
#从数据库读取
conn = psycopg2.connect(database="xxx",
user="xxx",
password="xx",
host="xx",
port="xx")
with conn: #从数据库读取数据
cur=conn.cursor()
cur.execute("""select *,case when bill_fee_avg<=30 then 'low' when bill_fee_avg<=60 then 'mediunm' else 'high' end value_type from tmp.cx_st_julei
;""")
rows = cur.fetchall()
data = pd.DataFrame(rows)
#重命名列标题
data.columns = ['user_id','bill_fee_avg','mo_billing_dura_avg','gprs_flow_avg','gprs_fee_avg',
'call_fee_avg','rent_fee','owe_fee_cnt','owe_fee_avg','bt_cnt','mo_cnt_avg','deposit_fee','month_innet','pay_fee_avg','value_type'
]
#设置数据类型
data[['bill_fee_avg','mo_billing_dura_avg','gprs_flow_avg','gprs_fee_avg',
'call_fee_avg','rent_fee','owe_fee_cnt','owe_fee_avg','bt_cnt','mo_cnt_avg','deposit_fee','month_innet','pay_fee_avg']]
= data[['bill_fee_avg','mo_billing_dura_avg','gprs_flow_avg','gprs_fee_avg','call_fee_avg','rent_fee','owe_fee_cnt','owe_fee_avg','bt_cnt','mo_cnt_avg','deposit_fee','month_innet','pay_fee_avg']].astype(float)
#异常值处理
data_num.describe() #浏览数据
data_num=data[['bill_fee_avg','mo_billing_dura_avg','gprs_flow_avg','gprs_fee_avg',
'call_fee_avg','rent_fee','month_innet']]
#散点图,观察异常值
bill_fee_avg = data['bill_fee_avg']
mo_billing_dura_avg = data['deposit_fee']
#散点图
plt.plot(bill_fee_avg,mo_billing_dura_avg,'o')
plt.show()
#异常值处理
data_num['mo_billing_dura_avg'][(data_num['mo_billing_dura_avg']>8000)]=8000
data_num['bill_fee_avg'][(data_num['bill_fee_avg']>1500)]=1500
#data_num['deposit_fee'][(data_num['deposit_fee']>8000)]=8000
#data_num['pay_fee_avg'][(data_num['pay_fee_avg']>200000)]=1500
#下面是利用R语言得到的9995分位数值来替代异常值
data_num['mo_billing_dura_avg'][(data_num['mo_billing_dura_avg']>2132)]=2132#异常值处理
data_num['bill_fee_avg'][(data_num['bill_fee_avg']>402.00)]=402.00#异常值处理
data_num['gprs_flow_avg'][(data_num['gprs_flow_avg']>296631.0)]=296631#异常值处理
data_num['gprs_fee_avg'][(data_num['gprs_fee_avg']>200.0)]=200.0#异常值处理
data_num['call_fee_avg'][(data_num['call_fee_avg']>107)]=107#异常值处理
data_num['rent_fee'][(data_num['rent_fee']>398)]=398#异常值处理
data_num['month_innet'][(data_num['month_innet']>235.00)]=235.00#异常值处理
data_num['rent_fee'][(data_num['rent_fee']>398)]=398#异常值处理
data_num['deposit_fee'][(data_num['deposit_fee']>87654.00)]=87654.00#异常值处理
data_num['pay_fee_avg'][(data_num['pay_fee_avg']>556.00)]=556.00#异常值处理
#变量间散点图
import seaborn as sns
sns.pairplot(data)
plt.title('Pairplot for the Data', fontsize = 20)
plt.show()
#数据处理-标准化
from sklearn.preprocessing import StandardScaler #标准化
ss=StandardScaler()
train_data=pd.DataFrame(ss.fit_transform(data_num))
train_data.columns=['bill_fee_avg','mo_billing_dura_avg','gprs_flow_avg','gprs_fee_avg',
'call_fee_avg','rent_fee','month_innet']
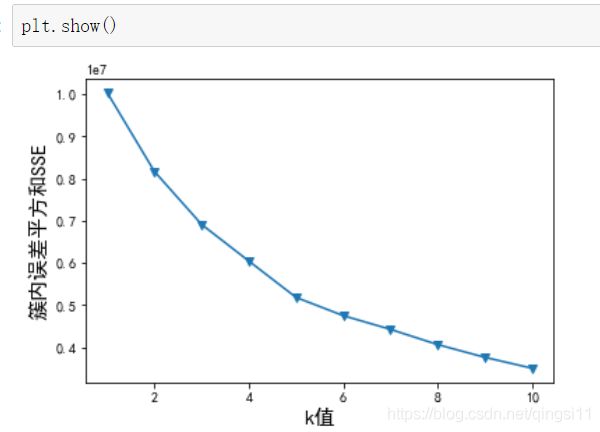
#选取最佳聚类数
import matplotlib.pyplot as plt
#查看最佳聚类
sse = []
for i in range(1,11): #k取1-10,计算簇内误差平方和
km = KMeans(n_clusters=i, random_state=2019)
km.fit(train_data)
sse.append(km.inertia_)
plt.plot(range(1,11), sse, marker='v')
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
plt.xlabel('k值', size=15)
plt.ylabel('簇内误差平方和SSE', size=15)
##进行KMeans聚类
model_4 = KMeans(n_clusters=4, random_state=2019)
model_5 = KMeans(n_clusters=5, random_state=2019)
model_6 = KMeans(n_clusters=6, random_state=2019)
model_4.fit(train_data)
model_5.fit(train_data)
model_6.fit(train_data)
#聚类中心
r4_1 = pd.Series(model_4.labels_).value_counts() #统计各类别的数目
r4_2 = pd.DataFrame(model_4.cluster_centers_) #找出聚类中心
r4 = pd.concat([r4_2,r4_1],axis = 1) #横向连接,得到聚类中心对应的类别下数目
r4.columns = list(train_data.columns) + ['count'] #重命名表头
#计算轮廓系数
##轮廓系数
from sklearn import metrics
score=[]
for i in [model_4,model_5,model_6]:
x_cluster=i.labels_
aa=metrics.silhouette_score(train_data,x_cluster) ##轮廓系数
print(aa)
score.append(aa)
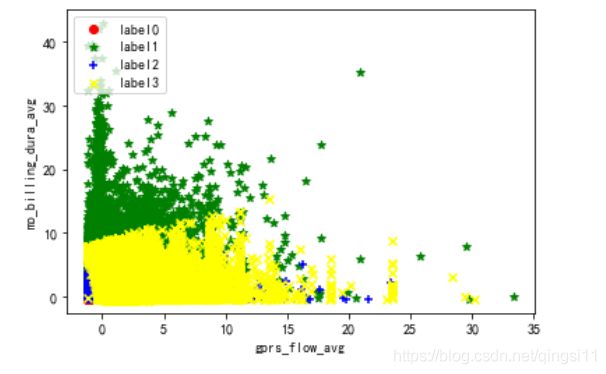
#聚类散点图
label_pred=model_4.labels_
#test_data是数据框,需要iloc,是数组则不用
x0 = train_data[label_pred == 0]
x1 = train_data[label_pred == 1]
x2 = train_data[label_pred == 2]
x3 = train_data[label_pred == 3]
#x4 = train_data[label_pred == 4]
plt.scatter(x0.iloc[:, 0], x0.iloc[:, 1], c = "red", marker='o', label='label0')
plt.scatter(x1.iloc[:, 0], x1.iloc[:, 1], c = "green", marker='*', label='label1')
plt.scatter(x2.iloc[:, 0], x2.iloc[:, 1], c = "blue", marker='+', label='label2')
plt.scatter(x3.iloc[:, 0], x3.iloc[:, 1], c = "yellow", marker='x', label='label3')
#plt.scatter(x4.iloc[:, 0], x4.iloc[:, 1], c = "cyan", marker='v', label='label4')
plt.scatter(km.cluster_centers_[:,0], km.cluster_centers_[:, 1], s = 50, c = 'orange' , label = 'centeroid') #添加聚类中心点
plt.xlabel('gprs_flow_avg')
plt.ylabel('mo_billing_dura_avg')
plt.legend(loc=2)
plt.show()
#数据合并导出到数据库
#注意,如果剔除了部分行,但是索引没变,会导致合并时有空值,所以忽略索引合并
data_km = pd.concat([data[['user_id',]],
pd.Series(model_4.labels_),
pd.Series(model_5.labels_),
pd.Series(model_6.labels_)], axis = 1, ignore_index=True)
data_km.columns = ['user_id','kmeans_4','kmeans_5','kmeans_6']
#导出到数据库
from sqlalchemy import create_engine
engine = create_engine('postgresql+psycopg2://****:*****@133.0.***.*:****/****')
#replace的意思,如果表存在,删了表,再建立一个新表,把数据插入
#append的意思,如果表存在,把数据插入,如果表不存在创建一个表!!
#fail的意思如果表存在,啥也不做
count=0
for i in range(0, 1500001, 100000):
data_km1=data_km.iloc[count:i,]
count =i
pd.io.sql.to_sql(data_km1,'st_julei_result2',engine,
schema='tmp',if_exists='append',index=False) #数据导入到数据库
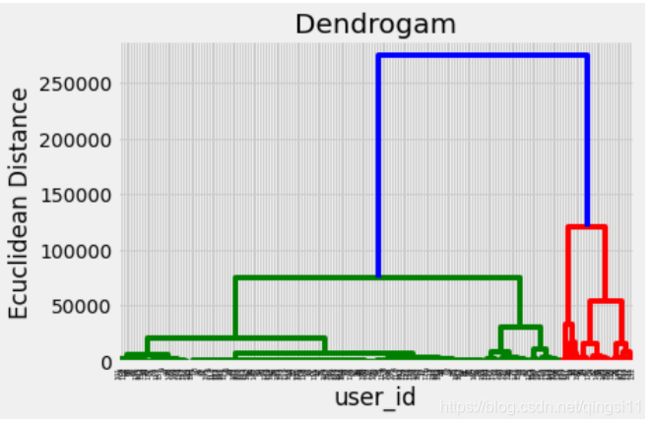
#层次聚类
import scipy.cluster.hierarchy as sch
x = data_num[['bill_fee_avg', 'mo_billing_dura_avg', 'gprs_flow_avg']].values
dendrogram = sch.dendrogram(sch.linkage(x, method = 'ward'))
plt.title('Dendrogam', fontsize = 20)
plt.xlabel('Customers')
plt.ylabel('Ecuclidean Distance')
plt.show()
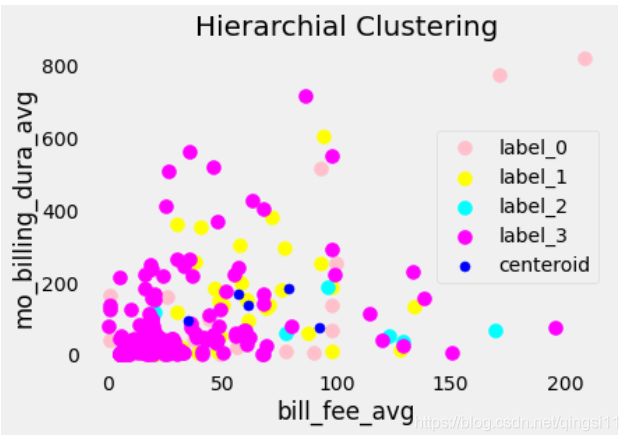
from sklearn.cluster import AgglomerativeClustering
hc = AgglomerativeClustering(n_clusters = 4, affinity = 'euclidean', linkage = 'ward')
y_hc = hc.fit_predict(x)
plt.scatter(x[y_hc == 0, 0], x[y_hc == 0, 1], s = 100, c = 'pink', label = 'label_0')
plt.scatter(x[y_hc == 1, 0], x[y_hc == 1, 1], s = 100, c = 'yellow', label = 'label_1')
plt.scatter(x[y_hc == 2, 0], x[y_hc == 2, 1], s = 100, c = 'cyan', label = 'label_2')
plt.scatter(x[y_hc == 3, 0], x[y_hc == 3, 1], s = 100, c = 'magenta', label = 'label_3')
#plt.scatter(x[y_hc == 4, 0], x[y_hc == 4, 1], s = 100, c = 'orange', label = 'careful')
plt.scatter(km.cluster_centers_[:,0], km.cluster_centers_[:, 1], s = 50, c = 'blue' , label = 'centeroid')
plt.style.use('fivethirtyeight')
plt.title('Hierarchial Clustering', fontsize = 20)
plt.xlabel('bill_fee_avg')
plt.ylabel('mo_billing_dura_avg')
plt.legend()
plt.grid()
plt.show()