手把手教你在FPGA上移植NVDLA+Tengine并且跑通任意神经网络(4)
手把手教你在FPGA上移植NVDLA+Tengine并且跑通任意神经网络(4)
- 一.前言
- 二. pytorch转onnx
- 三.模型量化
-
- 3.1 如果校准数据为非图形数据集怎么办
- 四.模型推理
一.前言
前一篇文章手把手教你在FPGA上移植NVDLA+Tengine并且跑通任意神经网络(3)
截止上文已经实现了在ARM-FPGA中跑通一个demo历程。也恰恰说明了搭建的硬件和软件的正确性。那么如何转换设计的神经网络并且使用Tengine框架调用NVDLA后端呢?Tengine社区的example中给了我们最好的答案。首先将pytorch设计的模型转换为onnx模式然后再调用Tengine的model convert工具将模型转换为TMFILE。使用Tengine自带的量化工具进行量化,最后调用tengine的api完成推理过程。
二. pytorch转onnx
Tengine转换工具链是不支持直接转换为tmfile,需要先转换为onnx中间格式。
注意一道要model.eval()和设置opset版本为10
import torch.onnx
#Function to Convert to ONNX
def Convert_ONNX():
# set the model to inference mode
model.eval()
# Let's create a dummy input tensor
dummy_input = torch.randn(1, input_size, requires_grad=True)
# Export the model
torch.onnx.export(model, # model being run
dummy_input, # model input (or a tuple for multiple inputs)
"totmfile.onnx", # where to save the model
export_params=True, # store the trained parameter weights inside the model file
opset_version=10, # the ONNX version to export the model to
do_constant_folding=True, # whether to execute constant folding for optimization
input_names = ['modelInput'], # the model's input names
output_names = ['modelOutput'], # the model's output names
dynamic_axes={'modelInput' : {0 : 'batch_size'}, # variable length axes
'modelOutput' : {0 : 'batch_size'}})
print(" ")
print('Model has been converted to ONNX')
导入权重文件,转换模型
if __name__ == "__main__":
# Let's build our model
#train(5)
#print('Finished Training')
# Test which classes performed well
#testAccuracy()
# Let's load the model we just created and test the accuracy per label
model = Network()
path = "$pthname$.pth"
model.load_state_dict(torch.load(path))
# Test with batch of images
#testBatch()
# Test how the classes performed
#testClassess()
# Conversion to ONNX
Convert_ONNX()
三.onnx转tmfile
在上文下载的Tengine工程下,新建一个编译路径,启动模型转换选项。
mkdir build && cd build
cmake -DTENGINE_BUILD_CONVERT_TOOL=ON ..
make -j`nproc`
然后进入编译出的可执行文件中build/tools/convert_tool
xuan@ubuntu:~/Tengine/build2/tools/convert_tool$ ./convert_tool -h
[Convert Tools Info]: optional arguments:
-h help show this help message and exit
-f input type path to input float32 tmfile
-p input structure path to the network structure of input model(*.param, *.prototxt, *.symbol, *.cfg, *.pdmodel)
-m input params path to the network params of input model(*.bin, *.caffemodel, *.params, *.weight, *.pb, *.onnx, *.tflite, *.pdiparams)
-o output model path to output fp32 tmfile
[Convert Tools Info]: example arguments:
./convert_tool -f onnx -m ./mobilenet.onnx -o ./mobilenet.tmfile
./convert_tool -f caffe -p ./mobilenet.prototxt -m ./mobilenet.caffemodel -o ./mobilenet.tmfile
./convert_tool -f mxnet -p ./mobilenet.params -m ./mobilenet.json -o ./mobilenet.tmfile
./convert_tool -f darknet -p ./yolov3.weights -m ./yolov3.cfg -o yolov3.tmfile
xuan@ubuntu:~/Tengine/build2/tools/convert_tool$ ./convert_tool -f onnx -m WDCNN2d_01_23.onnx -o WCDNN_01_23.tmfile
---- Tengine Convert Tool ----
Version : v1.0, 04:59:54 Apr 26 2022
Status : float32
----------onnx2tengine begin----------
Model op set is: 9
Internal optimize in onnx serializer done.
----------onnx2tengine done.----------
graph opt begin
graph opt done.
Convert model success. WDCNN2d_01_23.onnx -----> WCDNN_01_23.tmfile
三.模型量化
安装依赖库
sudo apt install libopencv-dev
新建编译环境
mkdir build && cd build
cmake -TENGINE_BUILD_QUANT_TOOL=ON ..
make -j`nproc`
进入build/tools/quantize文件夹下
$ ./quant_tool_int8 -h
[Quant Tools Info]: optional arguments:
-h help show this help message and exit
-m input model path to input float32 tmfile
-i image dir path to calibration images folder
-o output model path to output int8 tmfile
-a algorithm the type of quant algorithm(0:min-max, 1:kl, default is 1)
-g size the size of input image(using the resize the original image,default is 3,224,224
-w mean value of mean (mean value, default is 104.0,117.0,123.0
-s scale value of normalize (scale value, default is 1.0,1.0,1.0)
-b swapRB flag which indicates that swap first and last channels in 3-channel image is necessary(0:OFF, 1:ON, default is 1)
-c center crop flag which indicates that center crop process image is necessary(0:OFF, 1:ON, default is 0)
-y letter box flag which indicates that letter box process image is necessary(maybe using for YOLO, 0:OFF, 1:ON, default is 0)
-t num thread count of processing threads(default is 4)
使用量化工具前, 你需要 Float32 tmfile 和 Calibration Dataset(量化校准数据集)。
- 校准数据内容,尽可能的覆盖该模型的所有应用场景,一般我们的经验是从训练集中随机抽取;
- 校准数据张数,根据经验我们建议使用 500-1000 张。
3.1 如果校准数据为非图形数据集怎么办
matio库:https://github.com/tbeu/matio
在Tengine\tools\quantize下CMakeList.txt加入前端读入数据的库文件,本工程要读入matlab 的 .m文件 引入libmatio库 ,具体修改如下。
TARGET_LINK_LIBRARIES (${name} PRIVATE ${CMAKE_PROJECT_NAME}-static ${OpenCV_LIBS} ${TENGINE_TOOL_LINK_LIBRARIES} libmatio.a -lz)
修改quan_tool_int8.cpp
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* License); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing,
* software distributed under the License is distributed on an
* AS IS BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
* KIND, either express or implied. See the License for the
* specific language governing permissions and limitations
* under the License.
*/
/*
* Copyright (c) 2021, OPEN AI LAB
* Author: [email protected]
*/
#include 然后进行量化,选择min-max量化方式,量化过程和模型推理过程相同,是在模型推理过程中找到最优的量化方案。
四.模型推理
主要是调用tengine的api。
编写Tenginetest.cpp
//tengine推理框架
int tengine_classify(const char *model_file, int loop_count, int num_thread, int affinity) {
struct options opt;
opt.num_thread = num_thread;
opt.cluster = TENGINE_CLUSTER_ALL;
opt.precision = TENGINE_DT_INT8;
opt.affinity = affinity;
if (init_tengine() != 0) {
fprintf(stderr, "Initial tengine failed.\n");
return -1;
}
fprintf(stderr, "tengine-lite library version: %s\n", get_tengine_version());
/* create graph, load tengine model xxx.tmfile */
graph_t graph = create_graph(NULL, "tengine", model_file);
if (NULL == graph)
{
fprintf(stderr, "Create graph failed.\n");
return -1;
}
/* set the shape, data buffer of input_tensor of the graph */
int dims[] = { 1, 1, 1, 2048 }; // nchw
float *input_data = (float *)malloc(2048 * sizeof(float));
if (!input_data) {
fprintf(stderr, "Input_data malloc failed\n");
return -1;
}
tensor_t input_tensor = get_graph_input_tensor(graph, 0, 0);
if (input_tensor == NULL)
{
fprintf(stderr, "Get input tensor failed\n");
return -1;
}
if (set_tensor_shape(input_tensor, dims, 4) < 0)
{
fprintf(stderr, "Set input tensor shape failed\n");
return -1;
}
if (set_tensor_buffer(input_tensor, input_data, 2048 * sizeof(float)) < 0)
{
fprintf(stderr, "Set input tensor buffer failed\n");
return -1;
}
/* prerun graph, set work options(num_thread, cluster, precision) */
if (prerun_graph_multithread(graph, opt) < 0)
{
fprintf(stderr, "Prerun multithread graph failed.\n");
return -1;
}
//测试代码
/* prepare process input data, set the data mem to input tensor */
//std::default_random_engine e;
//std::uniform_real_distribution u(0, 1);
//for (uint16_t i = 0; i < 2048; ++i) {
// input_data[i] = u(e);
//}
//get_bear_data("\\mytinydnn\\test_X.mat", input_data);
//读取5个轴承数据进行测试
int n = 5;
while (n > 0) {
/* run graph */
double min_time = DBL_MAX;
double max_time = DBL_MIN;
double total_time = 0.;
get_bear_data("\\mytinydnn\\test_X.mat", input_data, n);
for (int i = 0; i < loop_count; i++)
{
double start = get_current_time();
if (run_graph(graph, 1) < 0)
{
fprintf(stderr, "Run graph failed\n");
return -1;
}
double end = get_current_time();
double cur = end - start;
total_time += cur;
if (min_time > cur)
min_time = cur;
if (max_time < cur)
max_time = cur;
}
fprintf(stderr, "\nmodel file : %s\n", model_file);
fprintf(stderr, "Repeat %d times, thread %d, avg time %.2f ms, max_time %.2f ms, min_time %.2f ms\n", loop_count,
num_thread, total_time / loop_count, max_time, min_time);
fprintf(stderr, "--------------------------------------\n");
/* get the result of classification */
tensor_t output_tensor = get_graph_output_tensor(graph, 0, 0);
float *output_data = (float *)get_tensor_buffer(output_tensor);
int output_size = get_tensor_buffer_size(output_tensor) / sizeof(float);
print_topk(output_data, output_size, 5);
fprintf(stderr, "--------------------------------------\n");
n--;
}
/* release tengine */
free(input_data);
postrun_graph(graph);
destroy_graph(graph);
release_tengine();
return 0;
}
export LD_LIBRARY_PATH= ~/Tengine/build/source
g++ -std=gnu++11 ./Tenginetest.cpp -o TengineTest libtengine-lite.so /usr/local/lib/libmatio.a -lz
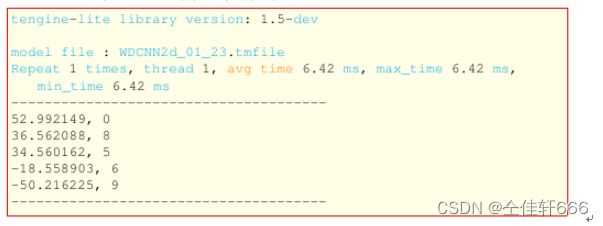
运行得到的推理结果: