ClickHouse的入门、使用和优化
ClickHouse是俄罗斯的重要网络服务门户之一Yandex所开源的一套针对数据仓库场景的多维数据存储与检索工具,一个用于联机分析(OLAP)的列式数据库管理系统(DBMS),它通过针对性的设计力图解决海量多维度数据的查询性能问题。
下面,enjoy:
一、数据库的行存与列存
在传统的行式数据库系统中,数据按顺序存储:处于同一行中的数据总是被物理的存储在一起,常见的行式数据库系统有:MySQL、Postgres和MS SQL Server。

行存需要逐行读取而后进行整合,速度较慢
在列式数据库系统中,来自不同列的值被单独存储,来自同一列的数据被存储在一起。列式数据库更适合于OLAP场景(对于大多数查询而言,处理速度至少提高了100倍)。新兴的 Hbase、HP Vertica、EMC Greenplum 等分布式数据库均采用列式存储。
列存能够快速读取同类型数据,速度较行存有着显著提升
ClickHouse采取的就是列示存储的方式。
二、ClickHouse安装及常用命令参数
1.ClickHouse支持的操作系统和硬件环境
只要是Linux,64位都可以。优先支持Ubuntu,Ubuntu有官方编译好的安装包可以使用。其次是CentOS和RedHat,有第三方组织编译好的rpm包可以使用。
如果是其他Linux系统,需要自己编译源码。
而且,机器的CPU必须支持SSE 4.2指令集。
[root@localhost ~]# grep -q sse4_2 /proc/cpuinfo && echo “SSE 4.2 supported” || echo “SSE 4.2 not supported”
2.ClickHouse的安装方法
(1)RPM安装包
推荐使用CentOS、RedHat和所有其他基于rpm的Linux发行版的官方预编译rpm包。
首先,您需要添加官方存储库:
sudo yum install yum-utils
sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86_64
然后运行命令安装:
sudo yum install clickhouse-server clickhouse-client
(2)设置系统参数
CentOS取消打开文件数限制
在/etc/security/limits.conf、/etc/security/limits.d/90-nproc.conf这2个文件的末尾加入以下内容:
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
CentOS取消SELINUX
修改/etc/selinux/config中的SELINUX=disabled后重启
关闭防火墙
Centos 6.X:
service iptables stop
service ip6tables stop
Centos 7.X:
chkconfig iptables off
chkconfig ip6tables off
(3)启动连接
启动服务:service clickhouse-server start
连接客户端:clickhouse-client
3.ClickHouse常用命令参数
(1)进入交互式客户端
用clickhouse-client连接本机clickhouse-server服务器:
clickhouse-client -m
用本机clickhouse-client连接远程clickhouse-server服务器:
clickhouse-client –host http://192.168.x.xxx –port 9000 –database default–user default –password ””
启动失败可以查看日志,日志的目录默认为/var/log/clickhouse-server/下。
(2)服务
停止:
service clickhouse-server stop
启动:
service clickhouse-server start
重启:
service clickhouse-server restart
(3) 设置数据目录
vi /etc/clickhouse-server/config.xml

(4) 放开远程访问
vi /etc/clickhouse-server/config.xml
修改服务器的配置文件/etc/clickhouse-server/config.xml,第65行,放开注释即可。

(5) 内存限制设置
vi /etc/clickhouse-server/users.xml

三、ClickHouse引擎介绍
ClickHouse提供了大量的数据引擎,分为数据库引擎、表引擎,根据数据特点及使用场景选择合适的引擎至关重要。
1.ClickHouse引擎分类
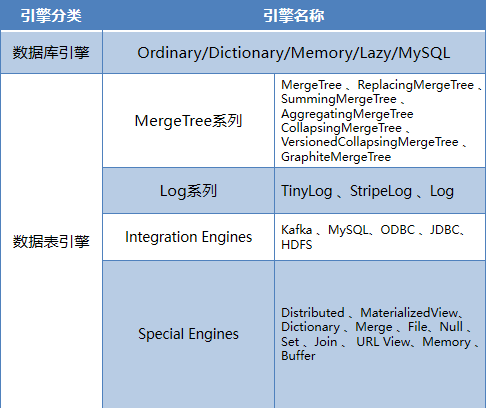
在以下几种情况下,ClickHouse使用自己的数据库引擎:
- 决定表存储在哪里以及以何种方式存储
- 支持哪些查询以及如何支持
- 并发数据访问
- 索引的使用
- 是否可以执行多线程请求
- 数据复制参数
在所有的表引擎中,最为核心的当属MergeTree系列表引擎,这些表引擎拥有最为强大的性能和最广泛的使用场合。对于非MergeTree系列的其他引擎而言,主要用于特殊用途,场景相对有限。而MergeTree系列表引擎是官方主推的存储引擎,支持几乎所有ClickHouse核心功能。
MergeTree作为家族系列最基础的表引擎,主要有以下特点:
- 存储的数据按照主键排序:允许创建稀疏索引,从而加快数据查询速度
- 支持分区,可以通过PRIMARY KEY语句指定分区字段
- 支持数据副本
- 支持数据采样
2.建表引擎参数
ENGINE:ENGINE = MergeTree(),MergeTree引擎没有参数。
ORDER BY:order by 设定了分区内的数据按照哪些字段顺序进行有序保存。
order by是MergeTree中唯一一个必填项,甚至比primary key 还重要,因为当用户不设置主键的情况,很多处理会依照order by的字段进行处理。
要求:主键必须是order by字段的前缀字段。
如果ORDER BY与PRIMARY KEY不同,PRIMARY KEY必须是ORDER BY的前缀(为了保证分区内数据和主键的有序性)。
ORDER BY 决定了每个分区中数据的排序规则;
PRIMARY KEY 决定了一级索引(primary.idx);
ORDER BY 可以指代PRIMARY KEY, 通常只用声明ORDER BY 即可。
PARTITION BY:分区字段,可选。如果不填:只会使用一个分区。
分区目录:MergeTree 是以列文件+索引文件+表定义文件组成的,但是如果设定了分区那么这些文件就会保存到不同的分区目录中。
PRIMARY KEY:指定主键,如果排序字段与主键不一致,可以单独指定主键字段。否则默认主键是排序字段。可选。
SAMPLE BY:采样字段,如果指定了该字段,那么主键中也必须包含该字段。比如SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID))。可选。
TTL:数据的存活时间。在MergeTree中,可以为某个列字段或整张表设置TTL。当时间到达时,如果是列字段级别的TTL,则会删除这一列的数据;如果是表级别的TTL,则会删除整张表的数据。可选。
SETTINGS:额外的参数配置。可选。
3.建表示例


4.数据导入
clickhouse-client --query "INSERT INTO default.emp_mgetree FORMAT CSV" --max_insert_block_size=100000 < test_data.csv
默认情况下间隔符是 ,
四、ClickHouse的优劣势总结
1.优势
- 为了高效的使用CPU,数据不仅仅按列存储,同时还按向量进行处理
- 数据压缩空间大,减少IO。处理单查询高吞吐量每台服务器每秒最多数十亿行
- 索引非B树结构,不需要满足最左原则,只要过滤条件在索引列中包含即可。即使在使用的数据不在索引中,由于各种并行处理机制ClickHouse全表扫描的速度也很快
- 写入速度非常快,50-200M/s,对于大量的数据更新非常适用
2.劣势
- 不支持事务,不支持真正的删除/更新
- 不支持高并发,官方建议qps为100,在服务器足够好的情况下可以通过修改配置文件增加连接数
- SQL满足日常使用80%以上的语法,join写法比较特殊。最新版已支持类似SQL的join,但性能不好
- 尽量做1000条以上批量的写入,避免逐行insert或小批量的insert,update,delete操作,因为ClickHouse底层会不断的做异步的数据合并,会影响查询性能,这个在做实时数据写入的时候要尽量避开
- Clickhouse快是因为采用了并行处理机制,即使一个查询,也会用服务器一半的CPU去执行,所以ClickHouse不能支持高并发的使用场景,默认单查询使用CPU核数为服务器核数的一半,安装时会自动识别服务器核数,可以通过配置文件修改该参数
- 全量数据导入:数据导入临时表 -> 导入完成后,将原表改名为tmp1 -> 将临时表改名为正式表 -> 删除原表
- 增量数据导入:增量数据导入临时表 -> 将原数据除增量外的也导入临时表 -> 导入完成后,将原表改名为tmp1-> 将临时表改成正式表-> 删除原数据表
五、ClickHouse使用优化总结
1.数据类型
建表时能用数值型或日期时间型表示的字段,就不要用字符串——全String类型在以Hive为中心的数仓建设中常见,但CK环境不应受此影响。
虽然clickhouse底层将DateTime存储为时间戳Long类型,但不建议直接存储Long类型,因为DateTime不需要经过函数转换处理,执行效率高、可读性好。
官方已经指出Nullable类型几乎总是会拖累性能,因为存储Nullable列时需要创建一个额外的文件来存储NULL的标记,并且Nullable列无法被索引。因此除非极特殊情况,应直接使用字段默认值表示空,或者自行指定一个在业务中无意义的值(例如用-1表示没有商品ID)。
2.分区和索引
分区粒度根据业务特点决定,不宜过粗或过细。一般选择按天分区,也可指定为tuple();以单表1亿数据为例,分区大小控制在10-30个为最佳。
必须指定索引列,clickhouse中的索引列即排序列,通过order by指定,一般在查询条件中经常被用来充当筛选条件的属性被纳入进来;可以是单一维度,也可以是组合维度的索引;通常需要满足高级列在前、查询频率大的在前原则;还有基数特别大的不适合做索引列,如用户表的userid字段;通常筛选后的数据满足在百万以内为最佳。
3.表参数
index_granularity 是用来控制索引粒度的 默认是8192,如非必须不建议调整。
如果表中不是必须保留全量历史数据,建议指定TTL,可以免去手动过期历史数据的麻烦。TTL也可以通过ALTER TABLE语句随时修改。
4.单表查询
使用prewhere替代where关键字;当查询列明显多于筛选列时使用prewhere可十倍提升查询性能。
5.数据采样策略
通过采用运算可极大提升数据分析的性能。
数据量太大时应避免使用select * 操作,查询的性能会与查询的字段大小和数量成线性变换;字段越少,消耗的io资源就越少,性能就会越高。
千万以上数据集进行order by查询时需要搭配where条件和limit语句一起使用。
如非必须不要在结果集上构建虚拟列,虚拟列非常消耗资源浪费性能,可以考虑在前端进行处理,或者在表中构造实际字段进行额外存储。
不建议在高基列上执行distinct去重查询,改为近似去重 uniqCombined。
多表Join时要满足小表在右的原则,右表关联时被加载到内存中与左表进行比较。
6.存储
clickhouse不支持设置多数据目录,为了提升数据io性能,可以挂载虚拟券组,一个券组绑定多块物理磁盘提升读写性能;多数查询场景SSD盘会比普通机械硬盘快2-3倍。