【层级多标签文本分类】MSML-BERT 模型的层级多标签文本分类方法研究
MSML-BERT 模型的层级多标签文本分类方法研究
1、背景
1、作者(第一作者和通讯作者)
黄伟,刘贵全
2、单位
中国科学技术大学
3、年份
2022-03-16
4、来源
计算机工程与应用
2、四个问题
1、要解决什么问题?
当前方法使用相同的模型结构来预测不同层级的标签,忽略了它们之间的差异性和多样性。并且没有充分地建模层级依赖关系,造成各层级标签尤其是下层长尾标签的预测性能差,且会导致标签不一致性问题。本文应对以上问题提出了新的模型。
2、用了什么方法解决?
将多任务学习架构引入,提出了MSML-BERT模型。该模型将标签结构中每一层的标签分类网络视为一个学习任务,通过任务间知识的共享和传递,提高各层级任务的性能。
3、效果如何?
本文在RCV1-V2、NYT和WOS数据集上进行了充分的实验,结果显示该模型的总体表现尤其是在下层长尾标签上的表现超过了其他主流模型,并且能维持较低的标签不一致比率。
4、还存在什么问题?
论文笔记
0 摘要
作者在摘要中提出了层级多标签文本分类所存在的一些问题,并提出来了新的模型,给出了本篇论文的创新点:
1、多任务学习架构
2、多尺度特征抽取模块(等于“CNN”)
3、多层级信息传播模块(等于“向量拼接”)
4、层次化门控机制
摘要的最后,作者经过三个数据集的实验,表明了提出的模型在数据集上效果良好。
作者总结了当前HMTC(Hierarchical Multi-label Text Classification,层级多标签文本分类)方法面临的两大问题:
(1)使用相同的模型结构来预测不同层级的标签,忽略了不同层级和粒度的标签之间的差异性和多样性,导致对各层级标签的预测性能较差;
(2)没有显式和充分地建模层级依赖关系以及引入了不必要的噪音,造成对下层长尾标签的预测性能尤其差,并且会导致标签不一致问题。
总结的说:用一个模型预测多个层级的标签并不准确;没有使用到层级的标签信息。
针对问题(1):本文设计了多尺度特征抽取模(Multi-scale Feature Extraction Module, MSFEM)用于捕捉不同尺度和粒度的特征,形成不同层级分类任务所需要的各种知识,以提高各层任务的预测性能;
针对问题(2):本文设计了多层级信息传播模块(Multi-layer Information Propagation Module, MLIPM),用于充分建模层级依赖,并将上层的特征表示中关键的信息传播到下层特征表示中去,从而利用上层任务的知识来帮助下层的预测任务,以提高对底层长尾标签的预测性能,并降低预测的标签不一致性。
在该模块中,本文设计了层次化门控机(Hierarchical Gating Mechanism),为了过滤不同层级任务之间的知识流动,保留有效知
识而丢弃无效知识。
1、相关工作
1.1、层级多标签文本分类
HMTC 方法主要可以分为:
展平方法:就是不考虑标签的层级结构,直接把层级标签当成普通多标签文本分类来建模。有时候,展平方法是把所有的层级标签都展平,有时候是把最后一层的标签展平。(展平方法对HMTC的效果是有瓶颈的。)
局部方法:局部方法指的是,为层级标签的每个节点都设置一个分类器,这中分类器一般是机器学习的分类器,如SVM等。(这样的效果也做不到最好。)
全局方法:用单个分类器并且更显式地对标签层次结构进行建模,模型通常采用端到端的方式训练并且对所有标签进行一次性地预测。(全局方法旨在更好的利用标签信息、标签的层次结构信息。)
1.2、多任务学习
随着深度学习的蓬勃发展,近期的多任务学习方法主要分为两类:硬参数共享方法和软参数共享方法。
硬参数共享:每个任务的模型由共享层和任务特定层两个部分组成,共享层用于学习和共享通用的知识和表征,而任务特定层用于弥补不同任务之间的差异以及提高不同任务的泛化性。
软参数共享:不同的任务拥有独立的模型,并且使用正则化的方法作用于不同模型参数之间的距离上,以使得相似任务的模型参数也相似
本文采取的多任务学习方法是硬参数共享方法,模型包括共享层和任务特定层。
2、基于 MSML-BERT 模型的层级多标签文本分类方法
HMTC 任务的目的:设计一个模型,在给定任意一条文本输入X的情况下,预测出该条文本对应的标签集合Y,并且该标签集合Y中的多个标签要尽量满足标签结构τ的约束。
模型如下图所示:
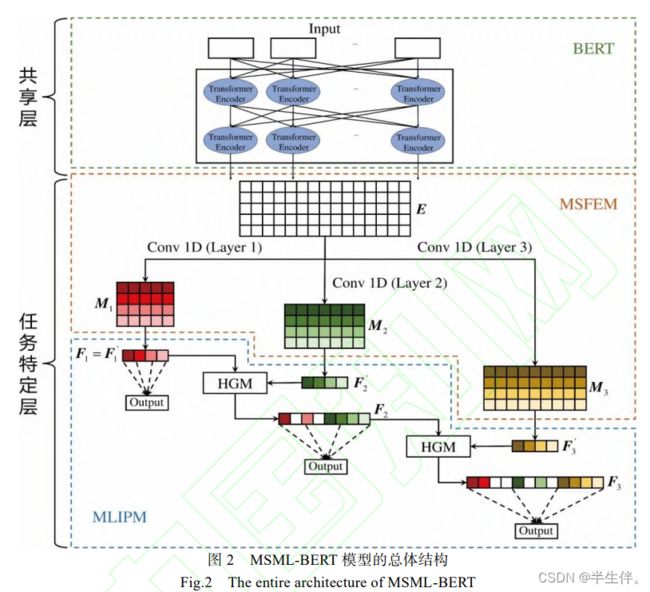
每层的功能如下:
BERT模型充当了整体模型的共享层,用于学习和共享通用的特征和知识。
MSFEM 用于根据不同层分类任务的需求,捕捉不同尺度的特征。
MLIPM 用于将上层特征表示中有价值的信息传递到下层表示,帮助下层的标签分类任务,进而提升 HMTC 任务的整体性能。
2.1、模型共享层
Transformer Encoder 结构是 BERT 模型的基本组成单元,其基本结构如下图所示。
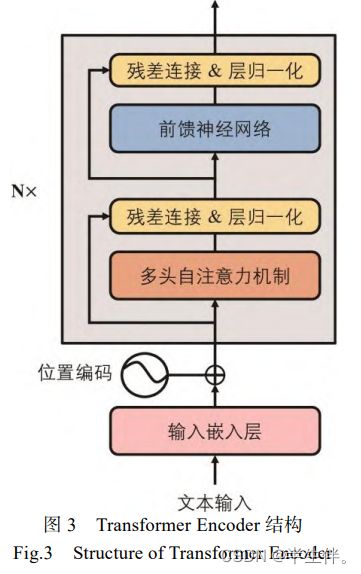
每个 Transformer Encoder 结构包含两个子层:多头自注意力机制和前馈网络。同时,为了模型能够有效地训练和加速收敛,每个子层后面还采用了残差连接和层归一化的操作。
2.1.1、多头自注意力机制
自注意力机制计算如下:
多头自注意力机制计算如下:
2.1.2、前馈网络

2.1.3、残差连接和层归一化

2.2、任务特定层
2.2.1、多尺度特征抽取模块(MSFEM)
特征抽取的意思就是卷积层的卷积,多尺度的意思是采用不同窗口大小的卷积核。图中使用了3个TextCNN模型,对应到数据集中的3层标签结构。
(对于模型提取特征时,不同的层级,卷积层提取的宽度不一样,文中的解释为:对于较上的层级采用较宽的一维卷积核提取粗粒度特征,对于较下的层级采用较窄的一维卷积核提取细粒度特征。)

2.2.2、多层级信息传播模块(MLIPM)
把上一层的输出,拼接在下一层的输入中。不过拼接的方式比较不一样,采用的是HGM(层次化门控机制)。
HGM(层次化门控机制),一种合并向量的门控方式,如下图:
3、实验
3.1、实验准备
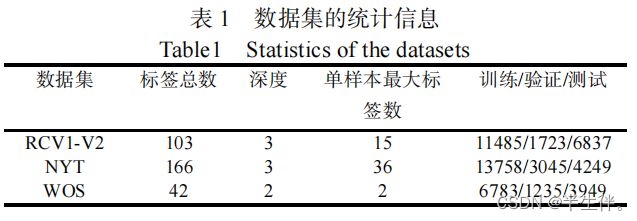
3.1.1、数据集
本文实验所采用的的数据集为三个经典的文本分类公开数据集包括:RCV1-V2(Reuters Corpus Volume I)数据集,NYT(The New York Times Annotated Corpus)数据集和 WOS(Web of Science)数据集。(RCV1-V2是非常经典的一个多标签文本分类数据集。)
RCV1-V2 数据集和 NYT 数据集都是新闻文本语料库,而 WOS 数据集包括来自 Web of Science 的已经发表论文的摘要。这些数据集的标签都组织成树状的层级结构。
3.1.2、评价指标
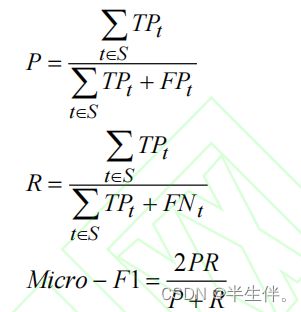
本文所采用的评价指标为Micro-F1 值和 Macro-F1 值。
(1)Micro-F1 值
Micro-F1 值是考虑到所有标签的整体精确率和召回率的 F1 值。用TPt 、FPt 、FNt分别表示总体标签集合S中第t个标签的真阳性、假阳性、假阴性。Micro-F1 值对所有的样本进行均等加权。计算如下所示:
(2)Macro-F1 值
Macro-F1 值是另一种 F1 值,它计算标签结构中所有不同的类别标签的平均 F1 值。Macro-F1 赋予每个标签相同的权重。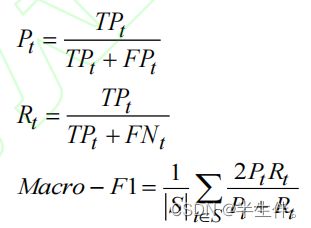
由于 Micro-F1 值对出现更频繁的标签赋予更大的权重,Macro-F1 对所有标签赋予相同的权重,因此 Macro-F1值对更难预测的底层标签更加敏感。
3.2、实验结果
本文提出的MSML-BERT 模型相比其他所有的展平方法、局部方法 和全局方法均取得了更好的表现 ,这体现了MSML-BERT模型在解决 HMTC 问题上的优越性。对于MSML-BERT模型在数据集中取得的最好的Micro-F1值,说明了 MSML-BERT 模型在充分挖掘了层级标签结构,通过建模层次依赖有效地提升了HMTC 任务的整体性能。
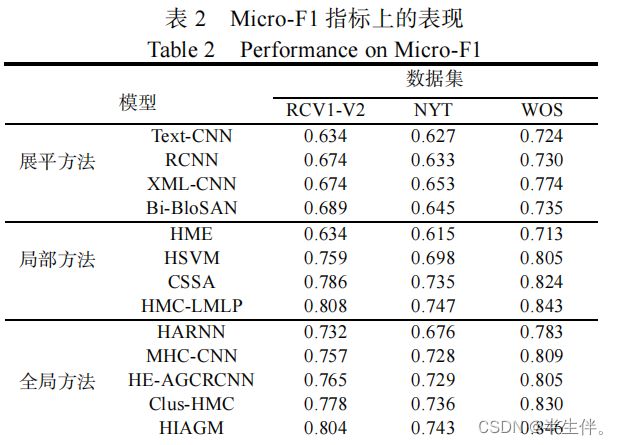
![]()
该模型在 Macro-F1 指标上取得了巨大的提升,结合Macro-F1 指标对稀疏标签更加敏感的特性,可知MSML-BERT 模型在预测下层的稀疏标签上具有更大的优势,这是因为本文的模型通过对层级依赖的建模,利用了从上层学到的知识来帮助下层标签的预测。
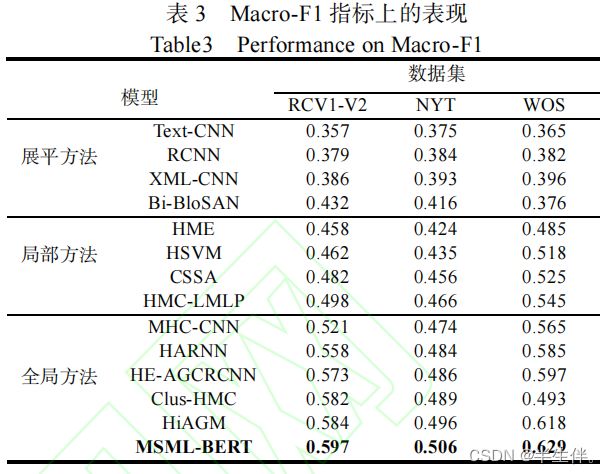
3.3、性能分析
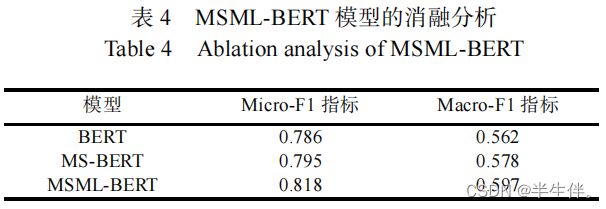
3.3.1、消融实验
其实就是控制变量,这里就证明了,论文提出的模型改进方法确实是有效果的。
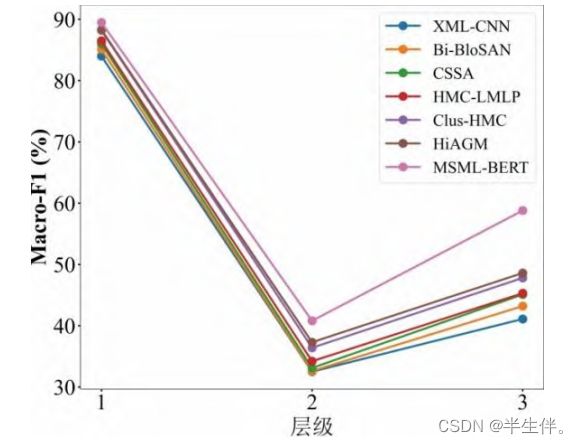
3.3.2、分层表现分析
查看不同模型在不同标签层级的评分,这里就证明了,论文提出的模型,在层级较深时,表现就更好。说明论文的创新点是正确的。
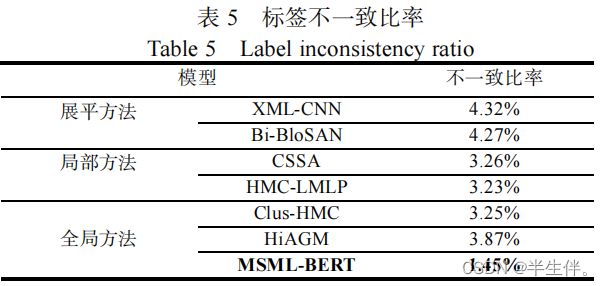
3.3.3、标签一致性分析
标签不一致经常发生在那些采用统一的方式处理不同层的标签分类任务的方法中,这些方法往往采用统一的方式处理不同层级的标签分类任务,独立地预测所有标签,一定程度上忽略了标签层级结构信息,因此会导致标签不一致性的出现。
标签一致性问题是模型预测的每一层标签,并不符合原始标签的层级关系。,这里也证明了论文提出的模型的优点。
本文参考:https://comdy.blog.csdn.net/article/details/124063271