【层级多标签文本分类】Incorporating Hierarchy into Text Encoder: a Contrastive Learning Approach for Hierarchic
Incorporating Hierarchy into Text Encoder: a Contrastive Learning Approach for Hierarchical Text Classification
1、背景
1、作者(第一作者和通讯作者)
王子涵,王厚峰
2、单位
Peking University
3、年份
2022
4、来源
ACL
2、四个问题
1、要解决什么问题?
层次文本分类是多标签分类的一个极具挑战性的子任务,因为它的标签层次结构复杂。解决层次文本分类下的多标签分类任务
2、用了什么方法解决?
提出了层次导引对比学习(HGCLR),将层次结构直接嵌入到文本编码器中。
3、效果如何?
在三个基准数据集上的大量实验验证了HGCLR的有效性。
4、还存在什么问题?
论文笔记
1、INTRODUCTION
Hierarchical Text Classification(HTC)是指文本标签之间存在层次结构文本分类任务。不同的标签之间存在的潜在关联会为分类提供正向指导。一般来说,HTC大致可以分为两类:为每个节点或级别构建分类器的局部方法,仅为整个图构建一个分类器的全局方法。
现有的HTC方法不同程度地引入了层次化信息。最先进的模型分别对文本和标签层次进行编码,并在按混合特征分类之前聚合两个表示。如下图左侧所示,他们的主要目标是在文本和结构之间充分交互,以实现混合表示,这对分类非常有用。但是,由于标签层次结构对于所有文本输入都保持不变,因此无论输入是什么,图形编码器都会提供完全相同的表示。因此,文本表示与恒定的层次表示相互作用,因此这种相互作用似乎是多余的且效率较低。
本文提出一种用于层次文本分类的对比学习方法。Hierarchy guided Contrastive Learning (HGCLR)直接将分层嵌入到文本编码器中而不是单独地创建层次的结构。在训练过程中,HGCLR在标签层次结构的指导下,为输入文本构建正样本。通过将输入文本和它的正样本放在一起,文本编码器可以学习独立地生成支持层次结构的文本表示。具体的结构如下:

上图:引入层次结构信息的两种方式。(a)将以前的工作模型文本和标签分开,并找到混合的表示法。(b)我们的方法将层次信息结合到文本编码器中以获得层次感知的文本表示。
2 Related Work
2.1 Hierarchical Text Classification
HTC现有的工作可以根据它们处理标签层次的方式分为局部方法和全球方法。局部方法为每个节点或级别构建分类器,而全局方法仅为整个图构建一个分类器。早期的方法忽略掉了标签的层次结构,并将问题视为平面多标签分类。
2.2 Contrastive Learning
对比学习最早是在计算机视觉中提出的一种弱监督表征学习方法。对比学习是一种自监督学习方法,用于在没有标签的情况下,通过让模型学习哪些数据点相似或不同来学习数据集的一般特征。
4 Methodology
总体的模型结构如下:
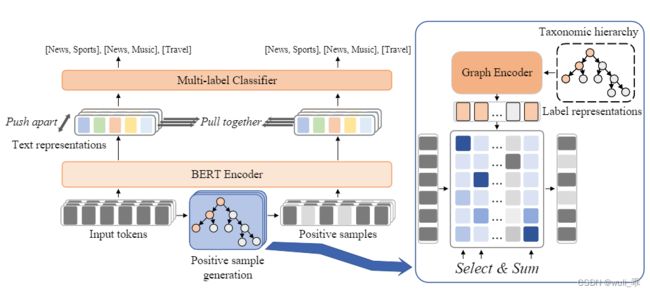
4.1 Text Encoder
首先,本文利用BERT作为文本的编码器:
![]()
[CLS]和[SEP]是指示序列的开始和结束的两个特殊标记,输入被送入BERT
得到的不同token的隐状态为:
![]()
4.2 Graph Encoder
将图结构构建为一个Directed Acyclic Graph (DAG)无环有向图 G = ( Y ; E ) ,并使用Graphormer对图进行编码。标签作为节点,其初始特征为其编号以及文本的嵌入的加和:
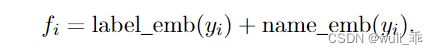
之后,采用基于Transformer的传播方式在标签图上进行特征传播。首先,Graphormer利用两个节点fi,fj之间的一些潜在特征为其生成相似矩阵:

遵从Graphormer,公式中的三个项分别表示节点fi,fj之间的注意力、cij 表示节点之间的边的编码,bϕ则表示两个节点之间的连通性。在这里,还是参照一下Graphormer中的定义:
ϕ ϕ ϕ(yi,yj)表示节点之间的最短路径长度,然后bϕ是针对最短路径的值indexed的一个可学习的标量。这个项目很明显用于统计一些静态的图信息,最短路径值值是固定的。
cij则是节点之间路径上的边的特征编码: c i j = 1 N ∑ n = 1 N x e n ( w n E ) T c_{ij}=\frac{1}{N} {\sum \limits_{n=1}^{N}}x_{e_n}(w^E_n)^T cij=N1n=1∑Nxen(wnE)T
这里的N表示路径上的边的条数, x e n x_{e_n} xen是相应的边的特征。而在本文中,cij的定义略有不同,省略了可学习的变换 w n E w^E_n wnE: c i j = 1 D ∑ n = 1 D w e n c_{ij}=\frac{1}{D}{\sum_{n=1}^D}w_{e_n} cij=D1∑n=1Dwen,D就是N, w e i w_{e_i} wei∈R1是一个可学习的量。之后,类似于Transformer中的操作,也对 A i j G A^G_{ij} AijG做Softmax乘一个可学习的参数矩阵V,然后添加残差F(所有节点的初始特征矩阵):
![]()
4.3 Positive Sample Generation
其实上述针对标签图的学习主要还是对Graphormer做一个相关回顾,本文的重点我觉得还是在如何构造对比学习上。为了选取正样本,需要利用上一步学习到的标签特征对样本做一个注意力的选择(也就是图2中蓝色框内的部分):

其中ei是token的表示:
![]()
Aij最终的实际含义就是每一个不同token对相应的标签的贡献概率,通过softmax获取到一个概率分布。如此一来,通过给定一个特定的标签,可以从这个分布中抽取token x ^ \hat{x} x^并形成一个正样本。为了使得采样的过程可微,将softmax改写为Gumbel-Softmax:![]()
这里的Pij表示token对不同标签的影响的概率。对于多标签分类,只需将所有ground-truth的概率相加,得到一个令牌xi对其ground-truth标签集y的概率为:

在这里,通过设置一个阈值 γ \gamma γ确定采样的token的数量:
![]()
其中0是一个特殊的token,其embedding的每一位都是0。正样品与原始样本送入相同的BERT:![]()
4.3 Contrastive Learning Module
负样本的构建过程要相对简单。对于学习到的真实样本表示hi以及相应的正例 h i ^ \hat{h_i} hi^,只需要通过添加一个非线性层即可得到两个对应的负样本: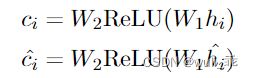
所以,对于一个batch为N的输入,会产生2(N−1)个负例。然后,采用NT-Xent强迫正负例之间的距离变大:
sim()是余弦相似度, μ \mu μ的定义为: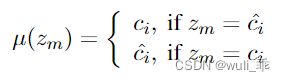
τ则是很常见的温度参数。总对比损失是所有例子的平均损失:
4.5 Classification and Objective Function
之后,将多标签分类的层次结构扁平化。将隐藏的特征输入线性层,并使用sigmoid函数计算概率:

则样本的多标签损失则是常用的BCE损失函数:
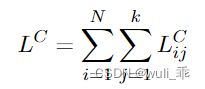
同样,对比学习中的正样本应该也有一个一样的损失 L ^ C \hat{L}^C L^C。最终的损失函数是原始数据的分类损失、构造正样本的分类损失和对比学习损失的组合: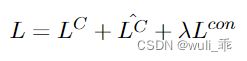
在测试过程中,只使用文本编码器进行分类,模型退化为带分类头的BERT编码器。
5 Experiments
5.1 Experiment Setup

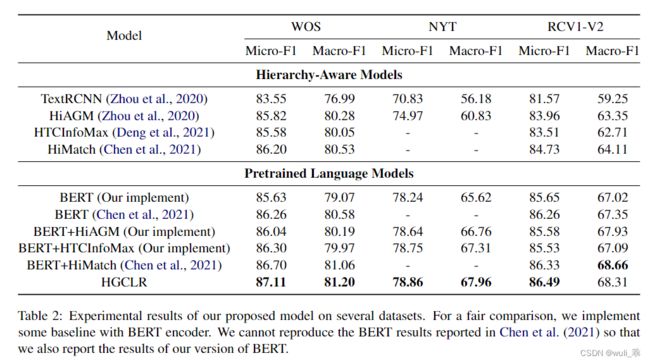
5.2 Experimental Results
消融实验,其中rp表示替代; rm表示移除: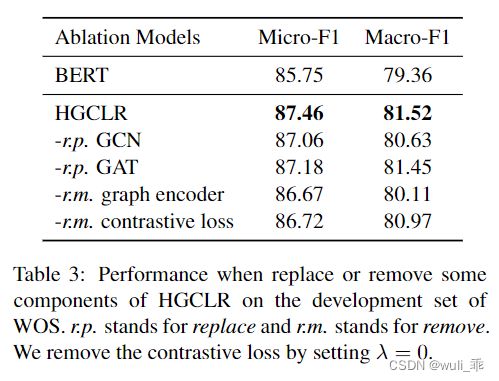
标签可视化的分析:
同一个颜色表示具有相同的父亲,本文的方法能够很好地提取出标签之间的层次结构相比于BERT来说。BERT的标签表示是分散的,而我们方法的标签表示是集群的,这表明我们的文本编码器可以学习层次感知的表示。
一些基于Graphormer的变体:
不同正例生成技术的影响:将模型复制为正例是有效的,但表现不佳

本文参考:https://blog.csdn.net/qq_36618444/article/details/124512478?spm=1001.2014.3001.5502