论文精读:《MV-FCOS3D++: Multi-View Camera-Only 4D Object Detection with Pretrained Monocular Backbones》
文章目录
- 论文精读
-
- 摘要
- 1. 介绍(Introduction)
- 2. 方法(Methodology)
-
- 2.1 MV-FCOS3D++
- 2.2 Pretraining with Perspective-View Supervision
- 2.3 Dual-Path Temporal Modeling
论文精读
摘要
在这份技术报告中,我们介绍了我们的解决方案,称为MV-FCOS3D++,用于Waymo Open DataSet Challenge 2022中的仅摄像机三维检测轨道。 对于多视点摄像机的三维检测,基于鸟瞰或三维几何表示的方法可以利用相邻视点之间重叠区域的立体线索,直接进行三维检测,而无需手工制作后处理。 然而,它缺乏对二维主干的直接语义监督,这可以通过预先训练简单的基于单目的检测器来补充。 我们的解决方案是遵循这种范式的4D检测的多视图框架。 它建立在一个简单的单目检测器FCOS3D++上,仅用Waymo的目标注释进行预训练,并将多视图特征转换到三维网格空间,在网格空间上检测三维目标。 设计了一种用于单帧理解和时间立体匹配的双路径颈部,以合并多帧信息。 在训练过程中没有基于激光雷达的深度监控的情况下,我们的方法最终在单一模型下获得了49.75%的MAPL,在WOD挑战赛中获得了第二名。
1. 介绍(Introduction)
CVPR 2022年的Waymo开放数据集挑战赛是自动驾驶领域规模最大、最具挑战性的比赛之一。 今年,它为仅摄像机的3D检测建立了一个新的轨道,这要求算法对仅给定来自多个摄像机的图像的3D对象进行定位和分类。 与以前的基准测试[1,4]和最初的Waymo 3D检测跟踪相比,这个挑战提供了用户友好的摄像机同步标签用于训练,并提出了一个自定义的度量标准Let-3D-APL,以评估仅摄像机的3D检测器。 两者都使这一挑战成为一个有希望的基准,鼓励在这一流中提出新的见解和方法。
在这个挑战中,由IMVoxelNet[10]推动,我们探索了一个通用的解决方案MV-FCOS3D++,它建立在一个显式的3D体素表示上,用于执行多视图仅摄像机的3D检测。 这个预先定义的体素网格提供了一个统一的、规则的结构,将不同视图的单目特征连接起来,并作为时间立体匹配的体空间。 它使框架能够简单、统一地进行多视图的三维检测,但缺乏对二维特征提取的直接图像-视图语义监督。 为了解决这个问题,我们基于一个简单的单目3D检测FCOS3D++1[12,13],在Waymo上只使用对象注释来预训练2D主干。 它增强了主干网对单目图像语义和几何的理解能力,显著提高了三维检测性能。 此外,我们设计了一个双路径方案,将多帧信息纳入我们的主框架。 它将单帧理解从时间立体匹配中分离出来,并在时间匹配失败的情况下自然地补偿后者,如静态场景和运动物体。
2. 方法(Methodology)
本节将介绍我们的获奖解决方案MV-FCOS3D++(图1)的细节。 我们首先从二维特征提取、从透视图(FOV)到鸟瞰(BEV)的特征转换以及随后的简单三维检测器的角度对我们的框架进行了概述。 然后介绍了增强MV-FCOS3D++的预训练和时态建模技术。
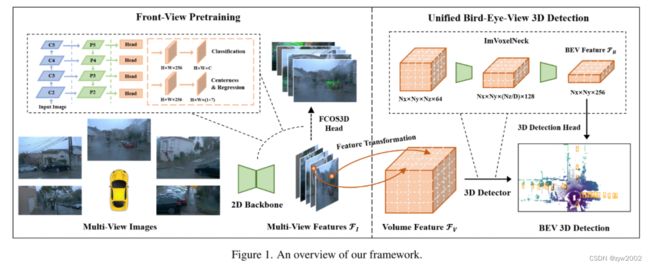
2.1 MV-FCOS3D++
- 2D特征提取(2D Feature Extraction)
给定一幅2D图像 I ∈ R W × H × 3 \mathcal{I} \in\mathcal{R}^{W \times H \times 3} I∈RW×H×3,特征提取模块的目的是提取图像的高层信息,以理解图像中的语义和几何结构。 在文献[10,13]的基础上,利用DCN[3]共享的二维骨干网Resnet-101进行特征提取,并利用特征金字塔网络(FPN)对多尺度特征进行聚合,得到每个视图的 F I ∈ R W 4 × H 4 × c \mathcal{F}_I \in \mathcal{R}^{\frac{W}{4} \times \frac{H}{4} \times c} FI∈R4W×4H×c(P2特征层在图1中)。
- 特征变换(Feature Transformation)
在给定多个视图的视场特征 F I \mathcal{F}_I FI的情况下,特征变换模块利用摄像机的固有特性将其提升到三维空间,得到统一的体特征 F V ∈ R N x × N y × N z × c \mathcal{F}_V \in R^{N_x \times N_y \times N_z \times c} FV∈RNx×Ny×Nz×c,其中 N x 、 N y 、 N z N_x、N_y、N_z Nx、Ny、Nz表示 x , y , z x, y, z x,y,z轴上的网格尺寸。 具体来说,我们首先预先定义三维体素空间,并对每个点进行网格采样,构建三维体特征。 对于每个点 ( x , y , z ) (x,y,z) (x,y,z),通过以下步骤获得相应的3D特征 F V ( x , y , z ) \mathcal{F}_V(x, y, z) FV(x,y,z):
F V ( x , y , z ) = F I ( π ( x , y , z ) ) , \mathcal{F}_V(x, y, z)=\mathcal{F}_I(\pi(x, y, z)), FV(x,y,z)=FI(π(x,y,z)),
其中π表示3D到2D坐标投影(为了简单起见,不考虑rolling shutter)。 由于Waymo数据集中行驶的汽车配备了环绕摄像头,因此一个3D点可能对应于图像中的多个2D点。 为了解决这一问题,我们采用了Mean平均池来聚合来自多个2D点的特征。
- 基于体素的3D检测器(Voxel-Based 3D Detector.)
在获得三维体素特征后,利用IMVoxelNet[10]后面的三维卷积神经网络组成的多个残差块来聚合三维空间信息,并沿Z轴压缩得到BEV特征 F B ∈ R N x × N y × 4 c \mathcal{F}_B \in \mathcal{R}^{N_x \times N_y \times 4 c} FB∈RNx×Ny×4c
利用BEV特征 F B \mathcal{F}_B FB,我们遵循基于BEV的检测器[6,9,10],在2D空间中进行3D检测。 在本次竞赛中,我们主要研究了两种检测头:基于锚的3D头[6]和无锚的、基于中心的3D头[16]。
基于锚框的3D检测头(The anchor-based 3D head)
一种类似于SSD[8]的结构也广泛应用于基于激光雷达的三维目标检测[6,15]。 它由三个部分组成:锚分类、包围盒回归和方向分类。 锚分类识别积极的锚并估计相应的语义类(即汽车、行人和自行车手)。 在[10,15]之后,正锚点由BEV空间中具有地面真值的锚点之间的IOU确定。 汽车的正负阈值分别为0.6和0.45,行人和骑自行车的正负阈值分别为0.5和0.35。 在训练过程中,基于锚的头部损失定义如下:
L = L cls + λ reg L reg + λ dir L dir \mathcal{L}=\mathcal{L}_{\text {cls }}+\lambda_{\text {reg }} \mathcal{L}_{\text {reg }}+\lambda_{\text {dir }} \mathcal{L}_{\text {dir }} L=Lcls +λreg Lreg +λdir Ldir
其中 L c l s \mathcal{L}{c l s} Lcls表示锚分类时的焦点损失, L reg \mathcal{L}{\text {reg }} Lreg 表示包围盒回归时的光滑L1损失, L dir \mathcal{L}{\text {dir }} Ldir 表示方向分类时的交叉熵损失, λ reg \lambda{\text {reg }} λreg 和 λ dir \lambda_{\text {dir }} λdir 分别为2和0.2。 在推理过程中,我们通过非极大值抑制(NMS)对冗余预测进行过滤,其中冗余判据是基于BEV空间中的IOU。 NMS前后的预测数分别设置为4096和500,以提高召回性能。
基于中心的三维检测头 (The center-based 3D head)
基于中心的3D头[16]是无锚的检测头。 该方法首先基于关键点网络对对象中心进行局部化,然后对边界框属性进行回归。 回归部分由目标位置、尺寸和包围盒偏航角的余弦值和正弦值组成。 总体损失定义如下:
L = L key + λ reg L reg , \mathcal{L}=\mathcal{L}{\text {key }}+\lambda{\text {reg }} \mathcal{L}{\text {reg }}, L=Lkey +λreg Lreg ,
其中 L k e y \mathcal{L}{k e y} Lkey表示用于关键点定位的基于高斯的focal 损失, L reg \mathcal{L}{\text {reg }} Lreg 表示用于回归部分的L1损失, λ reg \lambda{\text {reg }} λreg 为0.25。 在推理过程中,我们利用基于池的峰值关键点提取来获取目标中心并构造三维包围盒。
2.2 Pretraining with Perspective-View Supervision
正如文献[9,14]所观察到的,基于BEV的3D探测器可以从基于单眼的范例的主干预训练中受益,因为缺乏透视图监督。 为此,我们首先通过一个简单的基于单目的三维检测器FCOS3D++[12,13]对二维特征提取分量进行预训练,只带有对象注释,然后在BEV空间训练检测器时,用较小的学习速率(0.1×)对其进行优化。 FCOS3D++的实现遵循其开源版本[2],同时根据Waymo上的统计数据调整深度和3D大小先验值。 此外,我们只使用P3-P5(图1),回归范围设置为(0,128,256,∞),以更有效地产生多水平预测。 到目前为止,我们已经建立了一个可以从单帧多视点图像中进行三维检测的基线。 虽然它在相邻视图之间的重叠区域引入了一些立体线索,但对于精确估计目标深度仍然有限。 接下来,我们将展示如何利用连续帧提供的立体声提示。
2.3 Dual-Path Temporal Modeling
与典型的多视图或双目设置类似,在静态环境中,两个时间附近的图像也具有立体对应关系。 与基于单眼的理解相比,立体深度估计的基本原理是不同的:它依赖于匹配而不是数据分离的单眼先验信息。 因此,我们使用级联而不是简单的平均池来构造多帧体积特征。 此外,虽然立体估计可以利用绝对自我运动提供的强线索,但也有许多情况是立体估计方法无法处理的,如静态场景和运动物体。 因此,我们进一步设计了一个双路径方案来保持单目理解分支,并允许其自适应地补偿立体估计。
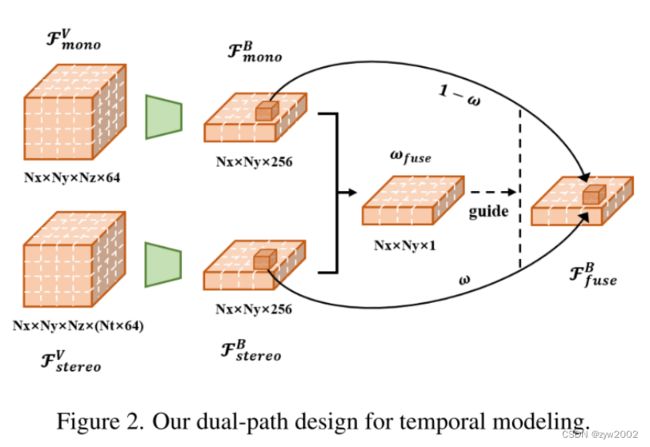
形式上,如图所示 2、从连续帧中提取体特征,并将其转换到当前帧中的EGO坐标系中,沿着特征通道将其连接起来,得到 F s t e r e o V \mathcal{F}_{stereo }^V FstereoV。 然后,我们使用两个IMVoxelneck分别聚合单目 F m o n o V \mathcal{F}_{mono }^V FmonoV和立体( F stereo V \mathcal{F}_{\text {stereo }}^V Fstereo V)特征。 立体声路径的网络与其他网络共享相同的结构,不同的是输入信道乘以帧数 N t N_t Nt。 然后我们有两个形状相同的BEV特征。 为了融合这些特征,我们将它们串联到一个简单的由1×1核组成的二维卷积层中,并沿着特征通道进行聚合,得到一个逐点加权的特征映射。 然后该特征的sigmoid响应作为引导 F mono B \mathcal{F}_{\text {mono }}^B Fmono B和 F stereo B \mathcal{F}_{\text {stereo }}^B Fstereo B融合的 ω f u s e \omega_{f u s e} ωfuse。 将卷积网络表示为 ϕ \phi ϕ,此过程表示如下:
ω fuse = σ ( ϕ ( F mono B , F stereo B ) ) , F fuse B = ω fuse ∘ F stereo B + ( 1 − ω fuse ) ∘ F mono B . \begin{gathered} \omega_{\text {fuse }}=\sigma\left(\phi\left(\mathcal{F}_{\text {mono }}^B, \mathcal{F}_{\text {stereo }}^B\right)\right), \\ \mathcal{F}_{\text {fuse }}^B=\omega_{\text {fuse }} \circ \mathcal{F}_{\text {stereo }}^B+\left(1-\omega_{\text {fuse }}\right) \circ \mathcal{F}_{\text {mono }}^B . \end{gathered} ωfuse =σ(ϕ(Fmono B,Fstereo B)),Ffuse B=ωfuse ∘Fstereo B+(1−ωfuse )∘Fmono B.
这里 σ \sigma σ表示sigmoid函数, ∘ \circ ∘表示元素相乘。 导出的双目特征 F fuse B \mathcal{F}_{\text {fuse }}^B Ffuse B最终被输入到后续的3D检测头。
在实际应用中,为了避免大量的内存开销,我们对前一帧的二维主干进行梯度反向传播,只从前十帧中抽取一帧来构造立体声对。 在推断过程中,我们使用最前面的一帧(最多前10帧)来保证相对较大的视图变化。 当没有前一帧时,我们复制当前帧作为前一帧,权重可以根据经验切换到依赖单目路径。 这种训练和推理设置的经验表现最好,超过其他选择(5或20帧)0.5%的MAPL。