Python机器学习-- KNN学习曲线、K值、交叉验证
文章目录
- 1.breast_cancer 数据集准确度计算
- 2.学习曲线
-
- 2.1 选择最优K值
- 2.2 不同K取值对模型的影响
- 2.3 神器之一:学习曲线
- 2.3.1 选取最优的K值
- 2.4交叉验证
-
- 2.4.1 泛化能力
- 2.5 神器之二:K折交叉验证
- 2.6 绘制带交叉验证的学习曲线
- 2.7 是否需要验证集?
- 2.8 交叉验证的方法
- 2.9 避免折数设置太大!
1.breast_cancer 数据集准确度计算
# breast_cancer 数据集
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
# 探索数据集
data = load_breast_cancer()
x = data['data']
y = data['target']
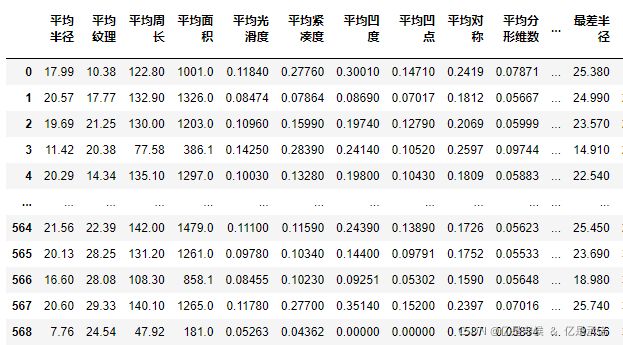
name = ['平均半径','平均纹理','平均周长','平均面积',
'平均光滑度','平均紧凑度','平均凹度',
'平均凹点','平均对称','平均分形维数',
'半径误差','纹理误差','周长误差','面积误差',
'平滑度误差','紧凑度误差','凹度误差',
'凹点误差','对称误差',
'分形维数误差','最差半径','最差纹理',
'最差的边界','最差的区域','最差的平滑度',
'最差的紧凑性','最差的凹陷','最差的凹点',
'最差的对称性','最差的分形维数']
pd.DataFrame(x, columns = name)
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors = 4) #实例化
clf.fit(x, y)
准确率的计算 clf.score(x, y)
0.9472759226713533
2.学习曲线
2.1 选择最优K值
KNN中的k是一个超参数,所谓"超参数",就是需要人为输入,算法不能通过直接计算得出的参数。
KNN中的k代表的是距离需要分类的测试点x最近的k个样本点,如果不输入这个值,那么算法中重要部分“选出k个最近邻”就无法实现。从KNN的原理中可见,是否能够确认合适的k值对算法有极大的影响。
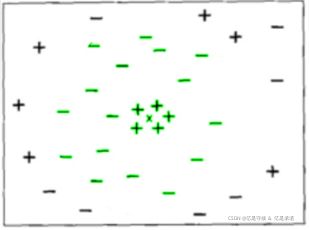
2.2 不同K取值对模型的影响
如果选择的k值较小,就相当于较小的邻域中的训练实例进行预测,这时候只有与输入实例较近的(相似的)训练实例才会对预测结果起作用,但缺点是预测结果会对近邻的实例点非常敏感。如果邻近的实例点恰好是噪声,预测就会出错。
相反地,如果选择的k值较大,就相当于较大的邻域中的训练实例进行预测。这时与输入实例较远的(不相似的)训练实例也会对预测起作用,使预测发生错误。因此,超参数k的选定是KNN的头号问题。
2.3 神器之一:学习曲线
那我们怎样选择一个最佳的k呢? 在这里我们要使用机器学习中的神器:参数学习曲线。参数学习曲线是一条以不同的参数取值为横坐标,不同参数取值下的模型结果为纵坐标的曲线,我们往往选择模型表现最佳点的参数取值作为这个参数的取值。让我们来试试更复杂的乳腺癌数据集吧!
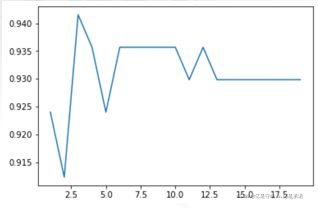
2.3.1 选取最优的K值
如何选取最优的K值?当取临近点个数K为不同值得时候,有不同的学习率。如果一个一个取值会太麻烦了,一般采用循环得方法去获得所有值得学习率。对n_neighbors进行遍历
# 选取最优的K值
# 更换不同的n_neighbors参数的取值,观察结果的变化
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3,random_state = 422)
# 绘制学习曲线
import matplotlib.pyplot as plt
score = []
krange = range(1,20,1)
for i in krange:
clf = KNeighborsClassifier(n_neighbors = i)#n_neighbors:取邻近点的个数k
clf.fit(x_train, y_train)
score.append(clf.score(x_test, y_test))
plt.plot(krange, score)
当n_neighbors=8=k时,有最好的准确率
#准确率
0.96
2.4交叉验证
确定了k之后,我们还能够发现一件事:每次运行的时候学习曲线都在变化,模型的效果时好时坏,这是为什么呢?实际上,这是由于「训练集」和「测试集」的划分不同造成的。模型每次都使用不同的训练集进行训练,不同的测试集进行测试,自然也就会有不同的模型结果。在业务当中,我们的训练数据往往是已有的历史数据,但我们的测试数据却是新进入系统的一系列还没有标签的未知数据。我们的确追求模型的效果,但我们追求的是模型在未知数据集上的效果,在陌生数据集上表现优秀的能力被称为泛化能力,即我们追求的是模型的泛化能力。我们认为,如果模型在一套训练集和数据集上表现优秀,那说明不了问题,只有在众多不同的训练集和测试集上都表现优秀,模型才是一个稳定的模型,模型才具有真正意义上的泛化能力。为此,机器学习领域有着发挥神作用的技能:「交叉验证」,来帮助我们认识模型。
2.4.1 泛化能力
我们在进行学习算法前,通常会将一个样本集分成「训练集」和「测试集」,其中训练集用于模型的学习或训练,而后测试集通常用于评估训练好的模型对于数据的预测性能评估。
训练误差(training error)代表模型在训练集上的错分样本比率。
测试误差(empirical error)是模型在测试集上的错分样本比率。
训练误差的大小,用来判断给定问题是不是一个容易学习的的问题。测试误差则反映了模型对未知数据的预测能力,测试误差小的学习方法具有很好的预测能力,如果得到的训练集和测试集的数据没有交集,通常将此预测能力称为泛化能力(generalization ability) 。
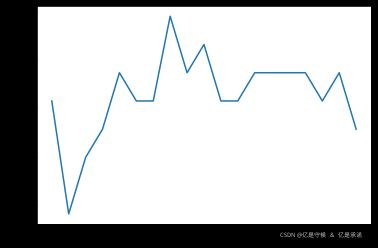
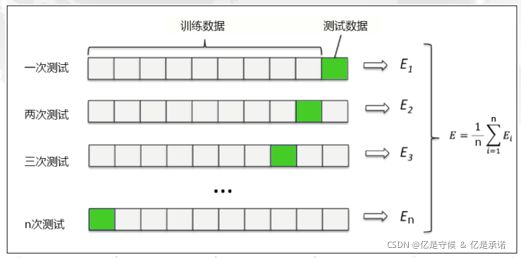
2.5 神器之二:K折交叉验证
最常用的交叉验证是k折交叉验证。我们知道训练集和测试集的划分会干扰模型的结果,因此用交叉验证n次的结果求出的均值,是对模型效果的一个更好的度量。
from sklearn.model_selection import cross_val_score as CVS
clf = KNeighborsClassifier(n_neighbors = 3)
cvresult = CVS(clf, x, y, cv = 5) #cv是把数据切割成5份
cvresult
结果
array([0.87719298, 0.92105263, 0.94736842, 0.93859649, 0.91150442])
- 均值
# 均值:查看模型的平均效果
cvresult.mean()
结果
0.9191429902189101
- 方差
# 方差:查看模型是否稳定
cvresult.var()
结果
0.0005993822421332872
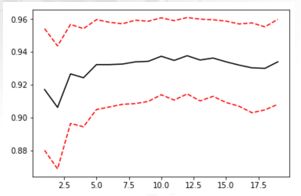
2.6 绘制带交叉验证的学习曲线
对于带交叉验证的学习曲线,我们需要观察的就不仅仅是最高的准确率了,而是准确率高,方差还相对较小的点,这样的点泛化能力才是最强的。在交叉验证+学习曲线的作用下,我们选出的超参数能够保证更好的泛化能力。
然而交叉验证却没有这么简单。交叉验证有许多坑大家可能会踩进去,在这里给大家列举出来:
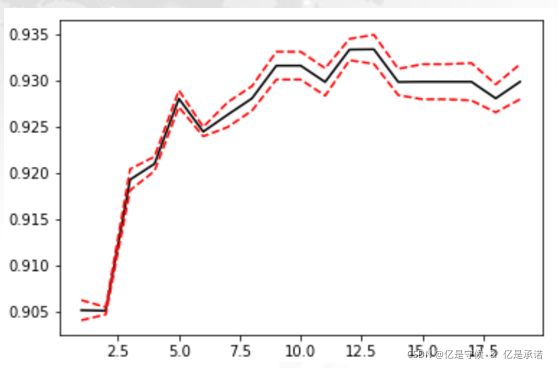
# 绘制带交叉验证的学习曲线
score = []
var_ = []
krange=range(1,20)
for i in krange:
clf = KNeighborsClassifier(n_neighbors=i)
cvresult = CVS(clf,x,y,cv=5)
score.append(cvresult.mean())
var_.append(cvresult.var())
plt.plot(krange,score,color='k')
plt.plot(krange,np.array(score)+np.array(var_)*2,c='red',linestyle='--')
plt.plot(krange,np.array(score)-np.array(var_)*2,c='red',linestyle='--')
pd.Series(score, index = krange).idxmax()
print(bestindex)
print(score[bestindex])
结果
12
0.9332401800962584
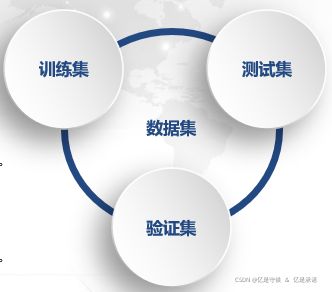
2.7 是否需要验证集?
最标准,最严谨的交叉验证应该有三组数据:训练集、验证集和测试集。 当我们获取一组数据后, 先将数据集分成整体的训练集和测试集,然后我们把训练集放入交叉验证中,从训练集中分割更小的训练集(k-1份) 和验证集(1份) ,此时我们返回的交叉验证结果其实是验证集上的结果。我们使用验证集寻找最佳参数,确认一个我们认为泛化能力最佳的模型,然后我们将这个模型使用在测试集上,观察模型的表现。
通常来说,我们认为经过验证集找出最终参数后的模型的泛化能力是增强了的,因此模型在未知数据(测试集)上的效果会更好, 但尴尬的是,模型经过交叉验证在验证集上的调参之后,在测试集上的结果没有变好的情况时有发生。原因其实是:我们自己分的训练集和测试集,会影响模型的效果;同时,交叉验证后的模型的泛化能力增强了,表示它在未知数据集上方差更小,平均水平更高,但却无法保证它在现在分出来的测试集上预测能力最强。如此说来,是否有测试集的存在,其实意义不大了。
如果我们相信交叉验证的调整结果是增强了模型的泛化能力的,那即便测试集上的测试结果并没有变好(甚至变坏了) , 我们也认为模型是成功的。如果我们不相信交又验证的调整结果能够增强模型的泛化能力,而一定要依赖测试集来进行判断,我们完全没有进行交叉验证的必要,直接用测试集上的结果来跑学习曲线就好了。所以,究竟是否需要验证集,其实是存在争议的,在严谨的情况下,大家还是使用有验证集的方式。
2.8 交叉验证的方法
交叉验证的方法不止"k折”一种, 分割训练集和测试集的方法也不止一种, 分门别类的交叉验证占据了sklearn中非常长的一章:3.1. Cross-validation: evaluating estimator performance
所有的交叉验证都是在分割训练集和测试集,只不过侧重的方向不同,像"k折"就是按顺序取训练集和测试集,ShuffleSplit就侧重于让测试集分布在数据的全方位之内,StratifiedKFold则是认为训练数据和测试数据必须在每个标签分类中占有相同的比例。类交叉验证的原理繁琐,大家在机器学习道路上-定会逐渐遇到更难的交叉验证, 但是万变不离其宗:本质上交叉验证是为了解决训练集和测试集的划分对模型带来的影响,同时检测模型的泛化能力的。

2.9 避免折数设置太大!
交叉验证的折数不可太大,因为折数越大抽出来的数据集越小,训练数据所带的信息量会越小,模型会越来越不稳定。
如果你发现不使用交叉验证的时候模型表现很好,一使用交叉验证模型的效果就骤降,一定要查看你的标签是否有顺序, 然后就是查看你的数据量是否太小,折数是否太高。
所以一般CV=10或者5