用Python自动批量提取Tableau报表数据源中用的数据库表
一、背景
我们公司很多部门都有人会用Tableau等可视化开发工具开发各类报表,并发布到报表平台进行共享查看。我所在的团队负责公司BI平台的运维管理,面对数量日益增加的各种报表,为了方便统一规范和监控管理,有一项管理需求就是期望可以及时获知所有报表连接的数据源中所涉及的数据连接信息、数据库表清单等,人工维护显然会存在滞后性和遗漏的可能,所以考虑是否可以用程序进行自动提取。
二、实现思路
搞定Tableau报表所用数据库表的自动批量解析问题,一共需要两步:
第一步:搞定一个报表的自动解析,获取其数据源信息
第二步:把上述解析一个报表的方法封装起来,想办法搞定批量自动操作。
(1)、如何获取一个Tableau报表中的数据源信息?
1、从Tableau Server 的自带存储库获取数据
Tableau Server管理员一般都知道,在Tableau Server服务器上,存在一个PostgreSQL数据库,是Tableau Server安装的同时自动安装的,用于存储和记录Tableau服务器上的配置、用户操作、工作薄、数据源、报表访问记录、数据提取作业等信息,不过默认情况下,该数据库不能通过Tableau Server以外的机器进行远程访问,但是可以进行设置开启,详细操作参见官方文档:启用对 Tableau PostgreSQL 数据库的外部访问。
事实上,如果是服务器管理员或者站点管理员用户,在Tableau Server的管理页面(TSM)上,你可以看到一些服务器监控看板页面,这些监控页面的数据来源就是上述提到的PostgreSQL数据库。如果你觉得Tableau Server上默认提供的监控看板不能满足你当前面临的复杂的服务器管理需求,你完全可以基于这个数据库中的数据记录,去构建和定制自己需要的监控运维看板,前提是理清了这个数据库中各表之间的关联关系,这里有一份Tableau官方的PostgreSQL数据库中的表和字段信息字典,拿走不谢:Tableau Server上的PostgreSQL存储库数据字典。
以下几个表存储了Tableau工作薄中所用的数据源连接信息:

其中:connection_tables这个表中,记录了Tableau工作薄数据源所连接的表和自定义SQL。我们把这个表的字段单拎出来看:

对于Tableau数据源为直接连接数据库表的,表里会记录一行数据,[type]字段值为'TABLE',[table_value]字段存储的值即为所连的数据库表名,而对于数据源为自定义SQL的,[type]字段值为'CUSTOM_SQL',这段数据库查询的SQL语句则会存储在[custom_sql]字段中 。看到这里,似乎我开头所提到的需求已经基本得到解决了,只要拿到这个表的信息不就全都搞定了!剩下的问题就是对自定义SQL语句进行解析,提取出SQL语句中所涉及的数据库表(关于SQL中提取涉及的数据库表这个问题,论坛中有很多相关话题和技术的讨论,大家可以从中找到解决思路,本文就不多做探讨。)。但实际情况并非这么简单,原因是我后来发现,在这个数据库中,并未存储Tableau发布数据源的中所用的数据库表和自定义SQL信息,而我们目前在用的很多报表,都是连接到发布在Tableau Server上的发布数据源的,这就不能完全解决我的问题。(如果你们并不使用发布数据源,那么看到这里就能解决你的问题了,如果你也和我一样也涉及发布数据源,请继续往下看。)
2、解析Tableau报表文件(.twb)及tableau数据源文件(.tds)获取数据
Tableau报表的所有信息都会存储在报表文件本身之中,所以我们可否尝试解析报表文件,来提取其中的信息呢?答案是 可以 。
众所周知,XML 格式是一种极为通用且使用广泛的信息系统数据传输、存储格式,大量的软件开发商都在自己的产品中采用了这一标准,Tableau也不例外,大家可以尝试下把 .twb 格式的Tableau报表文件后缀改为 .xml,或者甚至直接用文本编辑器打开.twb文件,就会发现,原来Tableau文件的本质也就是XML文件,Tableau软件按照自己设定的规则解析这个XML文件,读取其中存储的信息,最终在软件的界面中渲染成我们所看到的报表样式。
以下是一个示例报表以XML形式打开后的树形结构,其中的datasources节点就存储的是此工作薄中的数据源信息,对该节点展开后经过一番分析,就能找到其中的数据连接信息、数据库表、查询语句等数据的提取规则。如果大家有XML解析经验,或者写过爬虫,有HTML的解析经验,这里的信息提取也就轻车熟路了。
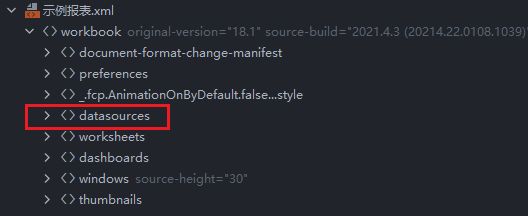
类似的,对于.tds文件,以XML形式打开后,大家会发现,它的XML结构就是 .twb 文件中的 datasources 节点中的内容,解析方式基本一致。
此外,需要特别补充的一点是:对于Tableau工作薄,除了.twb格式文件外,还有一种叫"打包工作薄",文件后缀为'.twbx',这种则是包含了外部文件的工作薄,他的实质是个'.zip'格式的压缩包文件,我们只需要粗暴地把文件后缀'.twbx'改为'.zip',然后直接进行解压就可以得到其中的.twb格式报表文件和工作薄中包含的其他文件,再对.twb格式报表文件进行解析即可。类似地,数据源文件也有'.tdsx'后缀文件,处理方式相同。
至此,我们基本清楚了单个报表文件的解析思路,按照这个思路去做代码实现即可,剩下的问题就是如何批量获得所有的报表文件和发布数据源,并自动进行解析了。
(2)、批量获取Tableau Server上的所有报表文件和发布数据源。
Tableau的官网上提供了非常全面和详细的官方文档,包括Tableau Desktop、Tableau Server的各种操作、运维文档,还有Tableau的开发文档,其中就包含Tableau REST API文档和基于Tableau REST API做好了封装的Tableau Server Client文档,Tableau Server Client是Tableau官方提供的Python SDK工具包,封装了很多非常有用的开发操作,例如登录鉴权、工作薄、数据源操作、用户管理、服务器管理、任务调度等等,利用它可以进行二次开发实现很多Tableau Server的运维自动化。
Tableau REST API , Tableau Server Client(Python)
我就是使用 Tableau Server Client(Python)批量获取的所有工作薄和发布数据源。不过有个前提,就是你至少得是Tableau Server的站点管理员用户,或者是服务器管理员用户,我们需要在程序中使用这种权限角色的账号密码登录 Tableau Server 。
贴一些关键步骤的示例代码:
安装 Tableau Server Client(Python):
pip install tableauserverclient在你的Python程序中登录 Tableau Server ,有两种方式:
用令牌登录:
import tableauserverclient as TSC
tableau_auth = TSC.PersonalAccessTokenAuth('TOKEN_NAME', 'TOKEN_VALUE', 'SITENAME')
server = TSC.Server('https://SERVER_URL', use_server_version=True) server.auth.sign_in(tableau_auth)
# Do awesome things here!
server.auth.sign_out()在使用以上代码之前,你需要先登录 Tableau Server 获取 TOKEN_NAME 和 TOKEN_VALUE 和 SITENAME
其中SITENAME 为你要服务器站点名称,在页面左上角LOGO下面,TOKEN信息的获取页面为服务器上的“我的账户设置”页面下如下图所示位置,点击创建新令牌即可获得。

用账号密码登录:
import tableauserverclient as TSC
tableau_auth = TSC.TableauAuth('USERNAME', 'PASSWORD', 'SITENAME')
server = TSC.Server('https://SERVER_URL', use_server_version=True) server.auth.sign_in(tableau_auth)
# Do awesome things here!
server.auth.sign_out()获取指定站点上的所有工作薄清单:
import tableauserverclient as TSC
tableau_auth = TSC.TableauAuth('username', 'password', site_id='site')
server = TSC.Server('https://servername')
with server.auth.sign_in(tableau_auth):
all_workbooks_items, pagination_item = server.workbooks.get()
print([workbook.id for workbook in all_workbooks_items])
以上方法获取到了所有工作薄的ID,我们可以再根据ID逐个下载工作薄:
workbooks.download(workbook_id, filepath='指定的文件路径', no_extract=False)no_extract=False 参数默认为False,表示下载时不包含数据提取文件,我们这里不需要,所以使用默认设置。
类似的,你也能从中找到下载数据源文件的方法
datasources.download(datasource_id, filepath='指定的文件路径', include_extract=False, no_extract=None)至此,批量获取到工作薄或数据源文件的思路也理清了,要想解决我开头提到的自动批量解析Tableau报表中数据源所用的数据库表的需求,已经没有技术困难了,剩下的工作就都是写代码的体力活了,详细的代码实现大家可以参照我文中给的文档链接,去官方文档中查找详细的实现代码和说明。