ResNet在计算机视觉中的应用
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
1.介绍
深度卷积神经网络极大地改变了图像分类的研究前景[1]。
随着更多层的添加,模型的表达能力增强;它能够学习更复杂的表示法。在某种程度上,网络的深度与模型的准确性之间似乎存在正相关关系。
另一方面,随着网络的深入,逐渐消失/爆炸的梯度问题变得更加严重。规范化初始化和规范化层最终解决了这个问题,深度网络开始收敛。
然而,与随后的实验之前的直觉推理不同,随着深度的增加,模型的准确性开始饱和,然后实际上迅速下降。这不是由于过拟合,而是由于用于优化模型的当前解算器的局限性[2]。
引入ResNet解决了退化问题[2]。它引入了一种系统的方法来使用跳跃连接,即跳过一个或多个层的连接。这些短连接只是执行标识映射,它们的输出被添加到堆叠层的输出中(这不会增加额外的参数或计算复杂性)。其背后的想法是,如果多个非线性层可以渐近逼近复杂函数(仍在理论上研究,但是深入学习的基础),那么残差函数也可能发生同样的情况。其优点是,同时简化了求解器的工作。在[3]中研究了其他类型的连接,如缩放、1x1卷积的跳跃连接。
我们的任务是对一系列带标签的图像进行分类。
我们想比较两种不同方法的准确性;第一种是经典的卷积神经网络,第二种是残差网络。我们的目标是展示残差网络的力量,即使在不太深的网络中。
这是一个很好的方法来帮助优化过程,同时解决退化问题。我们对残差网络进行了经验测试,发现它更容易过拟合。为了解决这一问题,我们采用数据扩充策略对数据集进行了综合扩充。
我们使用辛普森字符数据集[4]。我们只过滤数据集以包含包含100多个图像的类(字符)。在对训练、验证和测试数据集进行分割后,数据集的结果大小如下:12411个用于训练的图像、3091个用于验证的图像和950个用于测试的图像。
代码和数据也像往常一样在我的GitHub上可用。
https://github.com/luisroque/deep-learning-articles
2.数据预处理
我们创建生成器将数据提供给模型。我们还应用了一个转换来规范化数据,在训练数据集和验证数据集之间分割数据,并定义32的批大小(请参见[5],以便更好地理解预处理和生成器)。
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Layer, BatchNormalization, Conv2D, Dense, Flatten, Add, Dropout, BatchNormalization
import numpy as np
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import os
from tensorflow.keras import Input, layers
from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPooling2D
import time
directory_train = "./simpsons_data_split/train/"
directory_test = "./simpsons_data_split/test/"
def get_ImageDataGenerator(validation_split=None):
image_generator = ImageDataGenerator(rescale=(1/255.),
validation_split=validation_split)
return image_generator
image_gen_train = get_ImageDataGenerator(validation_split=0.2)
def get_generator(image_data_generator, directory, train_valid=None, seed=None):
train_generator = image_data_generator.flow_from_directory(directory,
batch_size=32,
class_mode='categorical',
target_size=(128,128),
subset=train_valid,
seed=seed)
return train_generator
train_generator = get_generator(image_gen_train, directory_train, train_valid='training', seed=1)
validation_generator = get_generator(image_gen_train, directory_train, train_valid='validation')
Found 12411 images belonging to 19 classes.
Found 3091 images belonging to 19 classes.我们还创建了一个增强数据集,通过应用一组几何和光度变换来减少过拟合的可能性。
几何变换改变图像的几何结构,使CNN在位置和方向上保持不变。光度变换通过调整图像的颜色通道,使CNN对颜色和照明的变化保持不变。
def get_ImageDataGenerator_augmented(validation_split=None):
image_generator = ImageDataGenerator(rescale=(1/255.),
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.1,
brightness_range=[0.8,1.2],
horizontal_flip=True,
validation_split=validation_split)
return image_generator
image_gen_train_aug = get_ImageDataGenerator_augmented(validation_split=0.2)
train_generator_aug = get_generator(image_gen_train_aug, directory_train, train_valid='training', seed=1)
validation_generator_aug = get_generator(image_gen_train_aug, directory_train, train_valid='validation')
Found 12411 images belonging to 19 classes.
Found 3091 images belonging to 19 classes.我们可以遍历生成器,得到一组大小等于上面定义的批量大小的图像。
target_labels = next(os.walk(directory_train))[1]
target_labels.sort()
batch = next(train_generator)
batch_images = np.array(batch[0])
batch_labels = np.array(batch[1])
target_labels = np.asarray(target_labels)
plt.figure(figsize=(15,10))
for n, i in enumerate(np.arange(10)):
ax = plt.subplot(3,5,n+1)
plt.imshow(batch_images[i])
plt.title(target_labels[np.where(batch_labels[i]==1)[0][0]])
plt.axis('off')
3.基准模型
我们定义了一个简单的CNN作为基准模型。
它使用2D卷积层(对图像执行空间卷积)和最大池操作。紧随其后的是具有128个单元和ReLU激活功能的Dense层,以及Dropout率为0.5的Dropout层。最后,最后一层产生我们网络的输出,该网络的单元数等于目标标签的数量,并使用softmax激活函数。
该模型使用Adam优化器编译,具有默认设置和分类交叉熵损失。
def get_benchmark_model(input_shape):
x = Input(shape=input_shape)
h = Conv2D(32, padding='same', kernel_size=(3,3), activation='relu')(x)
h = Conv2D(32, padding='same', kernel_size=(3,3), activation='relu')(x)
h = MaxPooling2D(pool_size=(2,2))(h)
h = Conv2D(64, padding='same', kernel_size=(3,3), activation='relu')(h)
h = Conv2D(64, padding='same', kernel_size=(3,3), activation='relu')(h)
h = MaxPooling2D(pool_size=(2,2))(h)
h = Conv2D(128, kernel_size=(3,3), activation='relu')(h)
h = Conv2D(128, kernel_size=(3,3), activation='relu')(h)
h = MaxPooling2D(pool_size=(2,2))(h)
h = Flatten()(h)
h = Dense(128, activation='relu')(h)
h = Dropout(.5)(h)
output = Dense(target_labels.shape[0], activation='softmax')(h)
model = tf.keras.Model(inputs=x, outputs=output)
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
benchmark_model = get_benchmark_model((128, 128, 3))
benchmark_model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 128, 128, 3)] 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 128, 128, 32) 896
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 64, 64, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 64, 64, 64) 18496
_________________________________________________________________
conv2d_3 (Conv2D) (None, 64, 64, 64) 36928
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 32, 32, 64) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 30, 30, 128) 73856
_________________________________________________________________
conv2d_5 (Conv2D) (None, 28, 28, 128) 147584
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 14, 14, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
dense (Dense) (None, 128) 3211392
_________________________________________________________________
dropout (Dropout) (None, 128) 0
_________________________________________________________________
dense_1 (Dense) (None, 19) 2451
=================================================================
Total params: 3,491,603
Trainable params: 3,491,603
Non-trainable params: 0
_________________________________________________________________
def train_model(model, train_gen, valid_gen, epochs):
train_steps_per_epoch = train_gen.n // train_gen.batch_size
val_steps = valid_gen.n // valid_gen.batch_size
earlystopping = tf.keras.callbacks.EarlyStopping(patience=3)
history = model.fit(train_gen,
steps_per_epoch = train_steps_per_epoch,
epochs=epochs,
validation_data=valid_gen,
callbacks=[earlystopping])
return history
train_generator = get_generator(image_gen_train, directory_train, train_valid='training')
validation_generator = get_generator(image_gen_train, directory_train, train_valid='validation')
history_benchmark = train_model(benchmark_model, train_generator, validation_generator, 50)
Found 12411 images belonging to 19 classes.
Found 3091 images belonging to 19 classes.
Epoch 1/50
387/387 [==============================] - 139s 357ms/step - loss: 2.7674 - accuracy: 0.1370 - val_loss: 2.1717 - val_accuracy: 0.3488
Epoch 2/50
387/387 [==============================] - 136s 352ms/step - loss: 2.0837 - accuracy: 0.3757 - val_loss: 1.7546 - val_accuracy: 0.4940
Epoch 3/50
387/387 [==============================] - 130s 335ms/step - loss: 1.5967 - accuracy: 0.5139 - val_loss: 1.3483 - val_accuracy: 0.6102
Epoch 4/50
387/387 [==============================] - 130s 335ms/step - loss: 1.1952 - accuracy: 0.6348 - val_loss: 1.1623 - val_accuracy: 0.6619
Epoch 5/50
387/387 [==============================] - 130s 337ms/step - loss: 0.9164 - accuracy: 0.7212 - val_loss: 1.0813 - val_accuracy: 0.6907
Epoch 6/50
387/387 [==============================] - 130s 336ms/step - loss: 0.7270 - accuracy: 0.7802 - val_loss: 1.0241 - val_accuracy: 0.7240
Epoch 7/50
387/387 [==============================] - 130s 336ms/step - loss: 0.5641 - accuracy: 0.8217 - val_loss: 0.9674 - val_accuracy: 0.7438
Epoch 8/50
387/387 [==============================] - 130s 336ms/step - loss: 0.4496 - accuracy: 0.8592 - val_loss: 1.0701 - val_accuracy: 0.7441
Epoch 9/50
387/387 [==============================] - 130s 336ms/step - loss: 0.3677 - accuracy: 0.8758 - val_loss: 0.9796 - val_accuracy: 0.7645
Epoch 10/50
387/387 [==============================] - 130s 336ms/step - loss: 0.3041 - accuracy: 0.8983 - val_loss: 1.0681 - val_accuracy: 0.75614.ResNet
深残差网络由许多堆叠的单元组成,这些单元可定义为:,
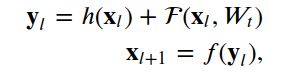
其中x_l和x_{l+1}是第l个单位的输入和输出,F是残差函数,h(x_l)是恒等映射,F是激活函数。W_t是与第l个残差单位相关联的一组权重(和偏差)。
由[2]提出的层数是2或3。我们将F定义为两个3x3卷积层的堆栈。在[2]中f是在元素添加之后应用的ReLU函数。我们遵循了[3]后来提出的架构,其中f只是一个标识映射。在本例中,
![]()
我们可以写为,
![]()
或者更一般地写为,
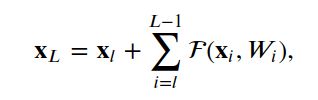
对于任何较深的单元L和较浅的单元L。特征为
![]()
对于任何深度单位,L是所有前面剩余函数的输出加上x_0的总和。
就优化过程而言,反向传播提供了一些关于为什么这种类型的连接有助于优化过程的直觉。我们可以这样写:
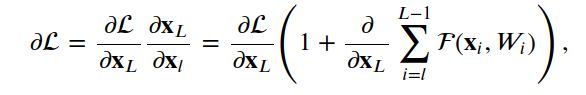
其中L是损失函数,注意梯度
![]()
而项
![]()
通过权重层传播。可以证明,使用这种形式,即使权重任意小,层的梯度也不会消失。
4.1残差单位
我们使用层子类化来构建残差单元。自定义层类有3个方法:__init__, build和call。
__init__方法使用定义的关键字参数调用基本层类初始值设定项。build方法创建层。在我们的例子中,我们定义了两组BatchNormalization,后面是Conv2D层,最后一组使用与层输入相同数量的滤波器。
call方法通过层处理输入。在我们的例子中,我们有以下顺序:第一个BatchNormalization,ReLu激活函数,第一个Conv2D,第二个BatchNormalization,另一个ReLu激活函数,第二个Conv2D。最后,我们将输入添加到第二个Conv2D层的输出。
class ResidualUnit(Layer):
def __init__(self, **kwargs):
super(ResidualUnit, self).__init__(**kwargs)
def build(self, input_shape):
self.bn_1 = tf.keras.layers.BatchNormalization(input_shape=input_shape)
self.conv2d_1 = tf.keras.layers.Conv2D(input_shape[3], (3, 3), padding='same')
self.bn_2 = tf.keras.layers.BatchNormalization()
self.conv2d_2 = tf.keras.layers.Conv2D(input_shape[3], (3, 3), padding='same')
def call(self, inputs, training=False):
x = self.bn_1(inputs, training)
x = tf.nn.relu(x)
x = self.conv2d_1(x)
x = self.bn_2(x, training)
x = tf.nn.relu(x)
x = self.conv2d_2(x)
x = tf.keras.layers.add([inputs, x])
return x
test_model = tf.keras.Sequential([ResidualUnit(input_shape=(128, 128, 3), name="residual_unit")])
test_model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
residual_unit (ResidualUnit) (None, 128, 128, 3) 192
=================================================================
Total params: 192
Trainable params: 180
Non-trainable params: 12
_________________________________________________________________4.2增加维度的残差单元
在[2]提出的架构中,存在增加维度的残差单元。这是通过使用快捷连接的线性投影来实现的,以匹配所需的尺寸:
![]()
在这种情况下,它由1x1卷积层完成。
class FiltersChangeResidualUnit(Layer):
def __init__(self, out_filters, **kwargs):
super(FiltersChangeResidualUnit, self).__init__(**kwargs)
self.out_filters = out_filters
def build(self, input_shape):
number_filters = input_shape[0]
self.bn_1 = tf.keras.layers.BatchNormalization(input_shape=input_shape)
self.conv2d_1 = tf.keras.layers.Conv2D(input_shape[3], (3, 3), padding='same')
self.bn_2 = tf.keras.layers.BatchNormalization()
self.conv2d_2 = tf.keras.layers.Conv2D(self.out_filters, (3, 3), padding='same')
self.conv2d_3 = tf.keras.layers.Conv2D(self.out_filters, (1, 1))
def call(self, inputs, training=False):
x = self.bn_1(inputs, training)
x = tf.nn.relu(x)
x = self.conv2d_1(x)
x = self.bn_2(x, training)
x = tf.nn.relu(x)
x = self.conv2d_2(x)
x_1 = self.conv2d_3(inputs)
x = tf.keras.layers.add([x, x_1])
return x
test_model = tf.keras.Sequential([FiltersChangeResidualUnit(16, input_shape=(32, 32, 3), name="fc_resnet_unit")])
test_model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
fc_resnet_unit (FiltersChang (None, 32, 32, 16) 620
=================================================================
Total params: 620
Trainable params: 608
Non-trainable params: 12
_________________________________________________________________4.3模型
最后,我们可以构建完整的模型。
我们首先定义一个包含32个过滤器、一个7x7内核和一个2步长的Conv2D层。
在第一层之后,我们添加残差单元。然后,我们添加一个包含32个过滤器、一个3x3内核和一个2步长的新Conv2D层。
然后,我们添加残差单元,允许使用输出改变维度64.为了最终确定我们的模型,我们将数据展平,并使用softmax激活函数和与类数相同的单元数将其送入Dense层。
class ResNetModel(Model):
def __init__(self, **kwargs):
super(ResNetModel, self).__init__()
self.conv2d_1 = tf.keras.layers.Conv2D(32, (7, 7), strides=(2,2))
self.resb = ResidualUnit()
self.conv2d_2 = tf.keras.layers.Conv2D(32, (3, 3), strides=(2,2))
self.filtersresb = FiltersChangeResidualUnit(64)
self.flatten_1 = tf.keras.layers.Flatten()
self.dense_o = tf.keras.layers.Dense(target_labels.shape[0], activation='softmax')
def call(self, inputs, training=False):
x = self.conv2d_1(inputs)
x = self.resb(x, training)
x = self.conv2d_2(x)
x = self.filtersresb(x, training)
x = self.flatten_1(x)
x = self.dense_o(x)
return x
resnet_model = ResNetModel()
resnet_model(inputs= tf.random.normal((32, 128,128,3)))
resnet_model.summary()
Model: "res_net_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_6 (Conv2D) multiple 4736
_________________________________________________________________
residual_unit (ResidualUnit) multiple 18752
_________________________________________________________________
conv2d_7 (Conv2D) multiple 9248
_________________________________________________________________
filters_change_residual_unit multiple 30112
_________________________________________________________________
flatten_1 (Flatten) multiple 0
_________________________________________________________________
dense_2 (Dense) multiple 1094419
=================================================================
Total params: 1,157,267
Trainable params: 1,157,011
Non-trainable params: 256
_________________________________________________________________
optimizer_obj = tf.keras.optimizers.Adam(learning_rate=0.001)
loss_obj = tf.keras.losses.CategoricalCrossentropy()
@tf.function
def grad(model, inputs, targets, loss):
with tf.GradientTape() as tape:
preds = model(inputs)
loss_value = loss(targets, preds)
return loss_value, tape.gradient(loss_value, model.trainable_variables)
def train_resnet(model, num_epochs, dataset, valid_dataset, optimizer, loss, grad_fn):
train_steps_per_epoch = dataset.n // dataset.batch_size
train_steps_per_epoch_valid = valid_dataset.n // valid_dataset.batch_size
train_loss_results = []
train_accuracy_results = []
train_loss_results_valid = []
train_accuracy_results_valid = []
for epoch in range(num_epochs):
start = time.time()
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.CategoricalAccuracy()
epoch_loss_avg_valid = tf.keras.metrics.Mean()
epoch_accuracy_valid = tf.keras.metrics.CategoricalAccuracy()
i=0
for x, y in dataset:
loss_value, grads = grad_fn(model, x, y, loss)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
epoch_loss_avg(loss_value)
epoch_accuracy(y, model(x))
if i>=train_steps_per_epoch:
break
i+=1
j = 0
for x, y in valid_dataset:
model_output = model(x)
epoch_loss_avg_valid(loss_obj(y, model_output))
epoch_accuracy_valid(y, model_output)
if j>=train_steps_per_epoch_valid:
break
j+=1
# End epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
train_loss_results_valid.append(epoch_loss_avg_valid.result())
train_accuracy_results_valid.append(epoch_accuracy_valid.result())
print("Training -> Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
print("Validation -> Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg_valid.result(),
epoch_accuracy_valid.result()))
print(f'Time taken for 1 epoch {time.time()-start:.2f} sec\n')
return train_loss_results, train_accuracy_results
train_loss_results, train_accuracy_results = train_resnet(resnet_model,
40,
train_generator_aug,
validation_generator_aug,
optimizer_obj,
loss_obj,
grad)
Training -> Epoch 000: Loss: 2.654, Accuracy: 27.153%
Validation -> Epoch 000: Loss: 2.532, Accuracy: 23.488%
Time taken for 1 epoch 137.62 sec
[...]
Training -> Epoch 039: Loss: 0.749, Accuracy: 85.174%
Validation -> Epoch 039: Loss: 0.993, Accuracy: 75.218%
Time taken for 1 epoch 137.56 sec5.结果
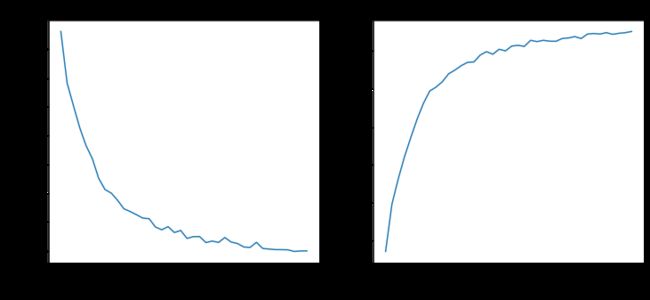
残差网络在测试集上显示出更好的准确率,与基准模型的75.6%相比,准确率接近81%。
我们可以很容易地使残差网络更深,从而提取更多价值。
fig, axes = plt.subplots(1, 2, sharex=True, figsize=(12, 5))
axes[0].set_xlabel("Epochs", fontsize=14)
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].set_title('Loss vs epochs')
axes[0].plot(train_loss_results)
axes[1].set_title('Accuracy vs epochs')
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epochs", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()图2:残差网络几个epoch的训练准确率和loss演变:
def test_model(model, test_generator):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.CategoricalAccuracy()
train_steps_per_epoch = test_generator.n // test_generator.batch_size
i = 0
for x, y in test_generator:
model_output = model(x)
epoch_loss_avg(loss_obj(y, model_output))
epoch_accuracy(y, model_output)
if i>=train_steps_per_epoch:
break
i+=1
print("Test loss: {:.3f}".format(epoch_loss_avg.result().numpy()))
print("Test accuracy: {:.3%}".format(epoch_accuracy.result().numpy()))
print('ResNet Model')
test_model(resnet_model, validation_generator)
print('Benchmark Model')
test_model(benchmark_model, validation_generator)
ResNet Model
Test loss: 0.787
Test accuracy: 80.945%
Benchmark Model
Test loss: 1.067
Test accuracy: 75.607%
num_test_images = validation_generator.n
random_test_images, random_test_labels = next(validation_generator)
predictions = resnet_model(random_test_images)
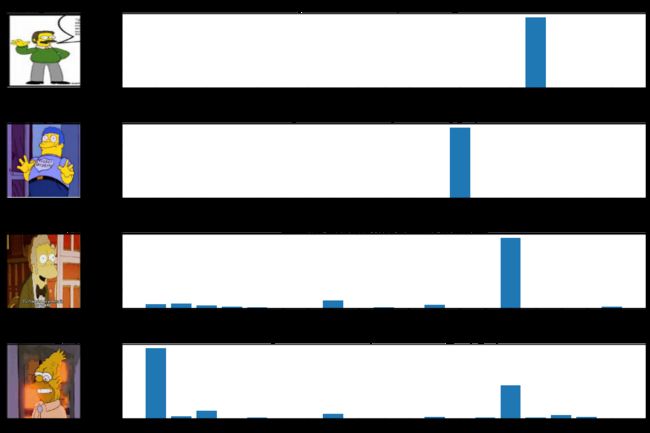
fig, axes = plt.subplots(4, 2, figsize=(25, 12))
fig.subplots_adjust(hspace=0.5, wspace=-0.35)
j=0
for i, (prediction, image, label) in enumerate(zip(predictions, random_test_images, target_labels[(tf.argmax(random_test_labels, axis=1).numpy())])):
if j >3:
break
axes[i, 0].imshow(np.squeeze(image))
axes[i, 0].get_xaxis().set_visible(False)
axes[i, 0].get_yaxis().set_visible(False)
axes[i, 0].text(5., -7., f'Class {label}')
axes[i, 1].bar(np.arange(len(prediction)), prediction)
axes[i, 1].set_xticks(np.arange(len(prediction)))
axes[i, 1].set_xticklabels([l.split('_')[0] for l in target_labels], rotation=0)
pred_inx = np.argmax(prediction)
axes[i, 1].set_title(f"Categorical distribution. Model prediction: {target_labels[pred_inx]}")
j+=1
plt.show()图3:随机图像(左侧)和残差网络(右侧)产生的预测的相应分类分布。
6.结论
残差网络被证明可以稳定深度网络的优化过程。此外,残差网络的性能优于传统CNN,显示了快捷连接的威力。
该方法可以通过增加模型的深度来扩展。这尤其适用于残差网络不存在退化问题的情况。
7.参考引用
[1] [Krizhevsky et al., 2012] Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25:1097–1105.
[2] [He et al., 2015] He, K., Zhang, X., Ren, S., and Sun, J. (2015). Deep residual learning for image recognition.
[3] [He et al., 2016] He, K., Zhang, X., Ren, S., and Sun, J. (2016). Identity mappings in deep residual networks.
[4] https://www.kaggle.com/alexattia/the-simpsons-characters-dataset
[5]https://towardsdatascience.com/transfer-learning-and-data-augmentation-applied-to-the-simpsons-image-dataset-e292716fbd43
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python+OpenCV视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:Pytorch常用函数手册
在「小白学视觉」公众号后台回复:pytorch常用函数手册,即可下载含有200余个Pytorch常用函数的使用方式,帮助快速入门深度学习。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

