Spark-SaprkStreaming(概述、架构、原理、DStream转换、案例)
文章目录
-
- SparkStreaming
-
- 概述
- 特点
- 架构
- 原理
-
- DStream和RDD的区别
- DAG
- 如何读取数据(※)
- WordCount 案例实操
-
- 代码
- 解析
- RDD 队列
-
- 用法及说明
- 案例实操
- 自定义数据源
- Kafka 数据源
- DStream 转换
-
- 无状态转化操作
-
- Transform
- join
- 有状态转化操作
-
- UpdateStateByKey
- WindowOperations
- DStream 输出
- 优雅关闭
- 案例实操
-
- 依赖
- 数据生成
- 需求一:广告黑名单
- 需求二:广告点击量实时统计
- 需求三:最近一小时广告点击量
SparkStreaming
概述
Spark Streaming 用于流式数据的处理。Spark Streaming 支持的数据输入源很多,例如:Kafka、 Flume、Twitter、ZeroMQ 和简单的 TCP 套接字等等。数据输入后可以用 Spark 的高度抽象原语 如:map、reduce、join、window 等进行运算。而结果也能保存在很多地方,如 HDFS,数据库等。

和 Spark 基于 RDD 的概念很相似,Spark Streaming 使用离散化流(discretized stream)作为抽象表示,叫作 DStream。DStream 是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为 RDD 存在,而 DStream 是由这些 RDD 所组成的序列(因此得名“离散化”)。所以 简单来将,DStream 就是对 RDD 在实时数据处理场景的一种封装。
特点
-
易用

-
容错

-
易整合到 Spark 体系

架构
简略架构图:
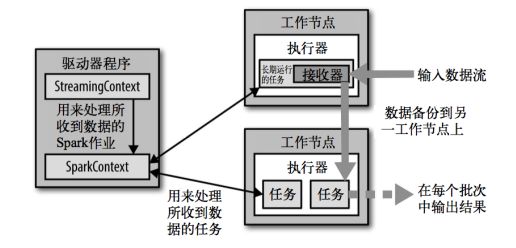
详细架构图:

在 Driver 中,有几个关键模块SparkStreaming Context 、DStreamGraph、JobScheduler、Checkpoint、Receiver Tracker。
(1)StreamingContext:是 Spark Streaming 程序的入口
- 通过StreamingContext(sparkConf, Seconds(1)) 指定sparkConf,指定批次生成的时间
- 通过读取 Kafka, 读取本地文件等创建DStream, 并且作为整个DAG中的InputDStream
- RDD遇到Action才会执行,但是DStream在ssc.start()后才会开始接收数据并计算,使用ssc.awaitTermination()等待计算结束
(2)DStreamGraph:StreamingContext被创建,若当前 checkpoint 可用,会优先从 checkpoint 恢复 graph,否则新建一个。DStreamGraph维护了InputDStream和OutputDStream 的实例:
- 通过InputDStreams持有 Spark Streaming 输入源及接收数据的方式
- 通过OutputDStreams持有 Streaming app 的 output 操作,并记录 DStream 依赖关系
- 通过 generateJobs 方法生成每个 batch 对应的 jobs,会由 JobScheduler 调度启动执行任务。
(3)JobScheduler:调度任务到 Executor 来执行。
(4)Checkpoint:是Spark Streaming 容错机制的核心,会定时对已算好的中间结果以及其他中间状态进行存储,避免了依赖链过长的问题。这样就算某个 DStream 丢失了,也不用从头开始计算,只需从最近的依赖关系开始计算即可。
(5)ReceiverTracker:将Receiver Supervisor调度到各节点,并获取来自Receiver Supervisor 的数据元数据。
Executor 是具体的任务执行者,其中重要的组件有 Receiver、ReceiverSupvisor、ReceiveredBlockHandler。
ReceiverSupvisor 启动后运行 Receiver 实例接收数据,管理所有的 Receiver。Receiver 接收到数据后,用 ReceiverdBlockHandler 以块的方式写到 Executor 的磁盘或者内存,对应的实现是:
- BlockManagerBasedBlockHandler:根据 Executor 的 StorageLevel 写到相应的存储层
- WriteAheadLogBasedBlockHandler:先进行预写日志(Write Ahead Log)对流式数据源提供更好的容错性。
原理
DStream和RDD的区别
- DStream 的数据是不断进入的,RDD 是针对一个数据的操作
- DStream内部是由RDD组成的,DStream 根据时间切片, 划分为多个 RDD
- 针对 DStream 的计算函数, 会作用于每一个 DStream 中的 RDD
- DStream本身也是可以组成DAG,DStream通过一些转换算子生成了新的DStream
DAG
DStream内部如何形成DAG?
每个 DStream 都有一个关联的 DStreamGraph 对象,DStreamGraph 负责表示 DStream 之间的依赖关系和运行步骤,DStreamGraph 中会单独记录 InputDStream 和 OutputDStream。
如何切分RDD?
(1)静态DAG:
DStreamGraph 将 DStream 联合起来, 生成 DStream 之间的 DAG, 这些 DStream 之间的关系是相互依赖的关系, 例如一个 DStream 经过 map 转为另外一个 DStream
DStream 按照时间切片, 一个 DStream DAG 对应了随着时间的推进所产生的无限个 RDD DAG
(2)动态切分:
RDD DAG 的生成是按照时间来切片的, 通过如下步骤生成一个 RDD DAG 后调度执行
- Streaming 会维护一个 Timer, 固定的时间到达后通知 Receiver 将收到的数据暂存, 并汇报存储的元信息, 例如存在哪, 存了什么
- 通过 DStreamGraph 复制出一套新的 RDD DAG
- 将数据暂存的元信息和 RDD DAG 一同交由 JobScheduler 去调度执行
- 提交结束后, 对系统当前的状态 Checkpoint
如何读取数据(※)
Spark Streaming通过一套单独的机制**Receiver来保证并行的读取外部数据源(如kafka),**Receiver可以在每个Executor中运行,因为Receiver是分布式的。
(1)Receiver的结构:
Receiver 是一个对象, 是可以有用户自定义的获取逻辑对象, 表示了如何获取数据
Receiver Tracker 是 Receiver 的协调和调度者, 其运行在 Driver 上
Receiver Supervisor 被 Receiver Tracker 调度到不同的节点上分布式运行, 其会拿到用户自定义的 Receiver 对象, 使用这个对象来获取外部数据
(2)Receiver的执行过程

- 在 Spark Streaming 程序开启时候, Receiver Tracker 使用 JobScheduler 分发 Job 到不同的节点, 每个 Job 包含一个 Task , 这个 Task 就是 Receiver Supervisor;
- Receiver Supervisor 启动后运行 Receiver 实例;
- Receiver 启动后, 就将持续不断地接收外界数据, 并持续交给 ReceiverSupervisor 进行数据存储;
- ReceiverSupervisor 持续不断地接收到 Receiver 转来的数据, 并通过 BlockManager 来存储数据;
- 获取的数据存储完成后发送元数据给 Driver 端的 ReceiverTracker, 包含数据块的 id, 位置, 数量, 大小 等信息。
WordCount 案例实操
代码
需求:使用 netcat 工具向 9999 端口不断的发送数据,通过 SparkStreaming 读取端口数据并 统计不同单词出现的次数
(1) 添加依赖
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.12artifactId>
<version>3.0.0version>
dependency>
(2)代码
object StreamWordCount {
def main(args: Array[String]): Unit = {
//1.初始化 Spark 配置信息
val sparkConf = new
SparkConf().setMaster("local[*]").setAppName("StreamWordCount")
//2.初始化 SparkStreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(3))
//3.通过监控端口创建 DStream,读进来的数据为一行行
val lineStreams = ssc.socketTextStream("linux1", 9999)
//将每一行数据做切分,形成一个个单词
val wordStreams = lineStreams.flatMap(_.split(" "))
//将单词映射成元组(word,1)
val wordAndOneStreams = wordStreams.map((_, 1))
//将相同的单词次数做统计
val wordAndCountStreams = wordAndOneStreams.reduceByKey(_+_)
//打印
wordAndCountStreams.print()
//启动 SparkStreamingContext
// 由于SparkStreaming采集器是长期执行的任务,所以不能直接关闭
// 如果main方法执行完毕,应用程序也会自动结束。所以不能让main执行完毕
//ssc.stop()
ssc.start()
ssc.awaitTermination()
}
}
(3)启动程序并通过 netcat 发送数据:
nc -lk 9999
hello spark
解析
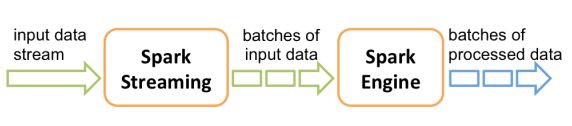
Discretized Stream 是 Spark Streaming 的基础抽象,代表持续性的数据流和经过各种 Spark 原语操作后的结果数据流。在内部实现上,DStream 是一系列连续的 RDD 来表示。每个 RDD 含有 一段时间间隔内的数据。

对数据的操作也是按照 RDD 为单位来进行的

计算过程由 Spark Engine 来完成
RDD 队列
用法及说明
测试过程中,可以通过使用 ssc.queueStream(queueOfRDDs)来创建 DStream,每一个推送到 这个队列中的 RDD,都会作为一个 DStream 处理。
案例实操
需求:循环创建几个 RDD,将 RDD 放入队列。通过 SparkStream 创建 Dstream,计算 WordCount
(1)编写代码
object RDDStream {
def main(args: Array[String]) {
//1.初始化 Spark 配置信息
val conf = new SparkConf().setMaster("local[*]").setAppName("RDDStream")
//2.初始化 SparkStreamingContext
val ssc = new StreamingContext(conf, Seconds(4))
//3.创建 RDD 队列
val rddQueue = new mutable.Queue[RDD[Int]]()
//4.创建 QueueInputDStream
val inputStream = ssc.queueStream(rddQueue,oneAtATime = false)
//5.处理队列中的 RDD 数据
val mappedStream = inputStream.map((_,1))
val reducedStream = mappedStream.reduceByKey(_ + _)
//6.打印结果
reducedStream.print()
//7.启动任务
ssc.start()
//8.循环创建并向 RDD 队列中放入 RDD
for (i <- 1 to 5) {
rddQueue += ssc.sparkContext.makeRDD(1 to 300, 10)
Thread.sleep(2000)
}
ssc.awaitTermination()
}
}
(2)结果展示
-------------------------------------------
Time: 1539075280000 ms
-------------------------------------------
(4,60)
(0,60)
(6,60)
(8,60)
(2,60)
(1,60)
(3,60)
(7,60)
(9,60)
(5,60)
-------------------------------------------
Time: 1539075284000 ms
-------------------------------------------
(4,60)
(0,60)
(6,60)
(8,60)
(2,60)
(1,60)
(3,60)
(7,60)
(9,60)
(5,60)
-------------------------------------------
Time: 1539075288000 ms
-------------------------------------------
(4,30)
(0,30)
(6,30)
(8,30)
(2,30)
(1,30)
(3,30)
(7,30)
(9,30)
(5,30)
-------------------------------------------
Time: 1539075292000 ms
-------------------------------------------a
自定义数据源
用法及说明:需要继承 Receiver,并实现 onStart、onStop 方法来自定义数据源采集。
需求:自定义数据源,实现监控某个端口号,获取该端口号内容。
代码:
(1)自定义数据源
class CustomerReceiver(host: String, port: Int) extends Receiver[String](StorageLevel.MEMORY_ONLY) {
//最初启动的时候,调用该方法,作用为:读数据并将数据发送给 Spark
override def onStart(): Unit = {
new Thread("Socket Receiver") {
override def run() {
receive()
}
}.start()
}
//读数据并将数据发送给 Spark
def receive(): Unit = {
//创建一个 Socket
var socket: Socket = new Socket(host, port)
//定义一个变量,用来接收端口传过来的数据
var input: String = null
//创建一个 BufferedReader 用于读取端口传来的数据
val reader = new BufferedReader(new InputStreamReader(socket.getInputStream,
StandardCharsets.UTF_8))
//读取数据
input = reader.readLine()
//当 receiver 没有关闭并且输入数据不为空,则循环发送数据给 Spark
while (!isStopped() && input != null) {
store(input)
input = reader.readLine()
}
//跳出循环则关闭资源
reader.close()
socket.close()
//重启任务
restart("restart")
}
override def onStop(): Unit = {}
}
(2)使用自定义的数据源采集数据
object FileStream {
def main(args: Array[String]): Unit = {
//1.初始化 Spark 配置信息
val sparkConf = new SparkConf().setMaster("local[*]")
.setAppName("StreamWordCount")
//2.初始化 SparkStreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(5))
//3.创建自定义 receiver 的 Streaming
val lineStream = ssc.receiverStream(new CustomerReceiver("hadoop102", 9999))
//4.将每一行数据做切分,形成一个个单词
val wordStream = lineStream.flatMap(_.split("\t"))
//5.将单词映射成元组(word,1)
val wordAndOneStream = wordStream.map((_, 1))
//6.将相同的单词次数做统计
val wordAndCountStream = wordAndOneStream.reduceByKey(_ + _)
//7.打印
wordAndCountStream.print()
//8.启动 SparkStreamingContext
ssc.start()
ssc.awaitTermination()
}
}
Kafka 数据源
ReceiverAPI:需要一个专门的 Executor 去接收数据,然后发送给其他的 Executor 做计算。存在 的问题,接收数据的 Executor 和计算的 Executor 速度会有所不同,特别在接收数据的 Executor 速度大于计算的 Executor 速度,会导致计算数据的节点内存溢出。早期版本中提供此方式,当前版本不适用。
DirectAPI:是由计算的 Executor 来主动消费 Kafka 的数据,速度由自身控制。
(1)需求:通过 SparkStreaming 从 Kafka 读取数据,并将读取过来的数据做简单计算,最终打印 到控制台。
(2)导入依赖
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-8_2.11artifactId>
<version>2.4.5version>
dependency>
(3)代码
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "spark_test",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("spark_test"), kafkaPara)
)
kafkaDataDS.map(_.value()).print()
ssc.start()
ssc.awaitTermination()
DStream 转换
DStream 上的操作与 RDD 的类似,分为 Transformations(转换)和 Output Operations(输 出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及 各种 Window 相关的原语。
无状态转化操作
无状态转化操作就是把简单的 RDD 转化操作应用到每个批次上,也就是转化 DStream 中的每 一个 RDD。部分无状态转化操作列在了下表中。注意,针对键值对的 DStream 转化操作(比如 reduceByKey())要添加 import StreamingContext._才能在 Scala 中使用。

需要记住的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个 DStream 在内部 是由许多 RDD(批次)组成,且无状态转化操作是分别应用到每个 RDD 上的。
例如:reduceByKey()会归约每个时间区间中的数据,但不会归约不同区间之间的数据。
Transform
Transform 允许 DStream 上执行任意的 RDD-to-RDD 函数。即使这些函数并没有在 DStream 的 API 中暴露出来,通过该函数可以方便的扩展 Spark API。该函数每一批次调度一次。其实也就是对 DStream 中的 RDD 应用转换。
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lines = ssc.socketTextStream("localhost", 9999)
// transform方法可以将底层RDD获取到后进行操作
// 1. DStream功能不完善
// 2. 需要代码周期性的执行
// Code : Driver端
val newDS: DStream[String] = lines.transform(
rdd => {
// Code : Driver端,(周期性执行)
rdd.map(
str => {
// Code : Executor端
str
}
)
}
)
// Code : Driver端
val newDS1: DStream[String] = lines.map(
data => {
// Code : Executor端
data
}
)
ssc.start()
ssc.awaitTermination()
join
两个流之间的 join 需要两个流的批次大小一致,这样才能做到同时触发计算。计算过程就是对当前批次的两个流中各自的 RDD 进行 join,与两个 RDD 的 join 效果相同。
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val data9999 = ssc.socketTextStream("localhost", 9999)
val data8888 = ssc.socketTextStream("localhost", 8888)
val map9999: DStream[(String, Int)] = data9999.map((_,9))
val map8888: DStream[(String, Int)] = data8888.map((_,8))
// 所谓的DStream的Join操作,其实就是两个RDD的join
val joinDS: DStream[(String, (Int, Int))] = map9999.join(map8888)
joinDS.print()
ssc.start()
ssc.awaitTermination()
有状态转化操作
UpdateStateByKey
UpdateStateByKey 原语用于记录历史记录,有时,我们需要在 DStream 中跨批次维护状态(例 如流计算中累加 wordcount)。针对这种情况,updateStateByKey()为我们提供了对一个 状态变量 的访问,用于键值对形式的 DStream。给定一个由(键,事件)对构成的DStream,并传递一个指 定如何根据新的事件更新每个键对应状态的函数,它可以构建出一个新的 DStream,其内部数据为(键,状态) 对。
updateStateByKey() 的结果会是一个新的 DStream,其内部的 RDD 序列是由每个时间区间对 应的(键,状态)对组成的。
updateStateByKey 操作使得我们可以在用新信息进行更新时保持任意的状态。为使用这个功能,需要做下面两步:
- 定义状态,状态可以是一个任意的数据类型。
- 定义状态更新函数,用此函数阐明如何使用之前的状态和来自输入流的新值对状态进行更 新。
使用 updateStateByKey 需要对检查点目录进行配置,会使用检查点来保存状态。
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc.checkpoint("cp")
// 无状态数据操作,只对当前的采集周期内的数据进行处理
// 在某些场合下,需要保留数据统计结果(状态),实现数据的汇总
// 使用有状态操作时,需要设定检查点路径
val datas = ssc.socketTextStream("localhost", 9999)
val wordToOne = datas.map((_,1))
//val wordToCount = wordToOne.reduceByKey(_+_)
// updateStateByKey:根据key对数据的状态进行更新
// 传递的参数中含有两个值
// 第一个值表示相同的key的value数据(当前批次)
// 第二个值表示缓存区相同key的value数据(以往批次)
val state = wordToOne.updateStateByKey(
( seq:Seq[Int], buff:Option[Int] ) => {
val newCount = buff.getOrElse(0) + seq.sum
Option(newCount)
}
)
state.print()
ssc.start()
ssc.awaitTermination()
WindowOperations
Window Operations 可以设置窗口的大小和滑动窗口的间隔来动态的获取当前 Steaming 的允许 状态。所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长:
- 窗口时长:计算内容的时间范围;
- 滑动步长:隔多久触发一次计算。
注意:这两者都必须为采集周期大小的整数倍。
窗口转换操作如下图所示:

如下图所示,批处理间隔是 1 个时间单位,窗口间隔是 3 个时间单位,滑动间隔是 2 个时间单位。对于初始的窗口(time 1~time 3),只有窗口间隔满足了才会触发数据的处理。

上图所表达的就是对每三秒钟的数据执行一次滑动窗口计算,这3秒内的3个RDD会被聚合起来进行处理,然后过了两秒钟,又会对最近三秒内的数据执行滑动窗口计算。所以每个滑动窗口操作,都必须指定两个参数,窗口长度以及滑动间隔,而且这两个参数值都必须是batch间隔的整数倍。
注:有可能初始的窗口没有被流入的数据撑满,但是随着时间的推进/窗口最终会被撑满。每过 2 个时间单位,窗口滑动一次,这时会有新的数据流入窗口,窗口则移去最早的 2 个时间单位的数据,而与最新的 2 个时间单位的数据进行汇总形成新的窗口(time 3~ time 5)。
(1)window(windowLength, slideInterval)
该操作由一个DStream对象调用,传入一个窗口长度参数,一个窗口移动速率参数,然后将当前时刻当前长度窗口中的元素取出形成一个新的DStream。
示例:以长度为3,移动速率为1截取源DStream中的元素形成新的DStream。
val conf = new SparkConf().setMaster("local[2]").setAppName("TestCount")
val ssc = new StreamingContext(conf,Seconds(1))
val lines = ssc.socketTextStream("localhost",9999)
val words = lines.flatMap (_.split(" "))
val windowCounts = words.window(Second(3),Second(1))
windowCounts.print()
//通过start()启动消息采集和处理
ssc.start()
//启动完成后就不能再做其它操作
//等待计算完成
ssc.awaitTermination()

基本上每秒输入一个字母,然后取出当前时刻3秒这个长度中的所有元素,打印出来。从上面的截图中可以看到,下一秒时已经看不到a了,再下一秒,已经看不到b和c了。表示a, b, c已经不在当前的窗口中。
(2)countByWindow(windowLength,slideInterval)
返回指定长度窗口中的元素个数
**示例:**统计当前3秒长度的时间窗口的DStream中元素的个数:
val conf = new SparkConf().setMaster("local[2]").setAppName("TestCount")
val ssc = new StreamingContext(conf,Seconds(1))
val lines = ssc.socketTextStream("localhost",9999)
val words = lines.flatMap (_.split(" "))
val windowCounts = words.countByWindow(Second(3),Second(1))
windowCounts.print()
//通过start()启动消息采集和处理
ssc.start()
//启动完成后就不能再做其它操作
//等待计算完成
ssc.awaitTermination()

(3)reduceByWindow(func, windowLength,slideInterval)
类似于上面的reduce操作,只不过这里不再是对整个调用DStream进行reduce操作,而是在调用DStream上首先取窗口函数的元素形成新的DStream,然后在窗口元素形成的DStream上进行reduce。
val conf = new SparkConf().setMaster("local[2]").setAppName("TestCount")
val ssc = new StreamingContext(conf,Seconds(1))
val lines = ssc.socketTextStream("localhost",9999)
val words = lines.flatMap (_.split(" "))
val windowCounts = words.reduceByWindow(_+"-"+_,Second(3),Second(1))
windowCounts.print()
//通过start()启动消息采集和处理
ssc.start()
//启动完成后就不能再做其它操作
//等待计算完成
ssc.awaitTermination()

(4)reduceByKeyAndWindow(func,windowLength, slideInterval, [numTasks])
调用该操作的DStream中的元素格式为(k, v),整个操作类似于前面的reduceByKey,只不过对应的数据源不同,reduceByKeyAndWindow的数据源是基于该DStream的窗口长度中的所有数据。该操作也有一个可选的并发数参数。
示例:将当前长度为3的时间窗口中的所有数据元素根据key进行合并,统计当前3秒中内不同单词出现的次数。
val conf = new SparkConf().setMaster("local[2]").setAppName("TestCount")
val ssc = new StreamingContext(conf,Seconds(1))
val lines = ssc.socketTextStream("localhost",9999)
val words = lines.flatMap (_.split(" "))
val pairs = words.map(x => (x, 1))
val windowCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int)=>(a+b),Second(3),Second(1))
windowCounts.print()
//通过start()启动消息采集和处理
ssc.start()
//启动完成后就不能再做其它操作
//等待计算完成
ssc.awaitTermination()

(5)reduceByKeyAndWindow(func, invFunc,windowLength, slideInterval, [numTasks])
这个窗口操作和上一个的区别是多传入一个函数invFunc。前面的func作用和上一个reduceByKeyAndWindow相同,后面的invFunc是用于处理流出rdd的。
如果把3秒的时间窗口当成一个公交车,每一秒都会有上或者下,那么第一个函数表示每上来一个人,就在该公交车上人数的基础上的数量累加一个人。而第二个函数表示每下去一个人,就在该公交车上人数的总数量上减去一个人。
示例:最终的结果是该3秒长度的窗口中历史上出现过的所有不同单词个数都为0。
val conf = new SparkConf().setMaster("local[2]").setAppName("TestCount")
val ssc = new StreamingContext(conf,Seconds(1))
val lines = ssc.socketTextStream("localhost",9999)
val words = lines.flatMap (_.split(" "))
val pairs = words.map(x => (x, 1))
val windowCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int)=>(a+b),(a:Int,b:Int)=>(a-b),Second(3),Second(1))
windowCounts.print()
//通过start()启动消息采集和处理
ssc.start()
//启动完成后就不能再做其它操作
//等待计算完成
ssc.awaitTermination()

一段时间不输入任何信息,最终结果如下:

(6)countByValueAndWindow(windowLength,slideInterval, [numTasks])
类似于前面的countByValue操作,调用该操作的DStream数据格式为(K, v),返回的DStream格式为(K, Long)。统计当前时间窗口中元素值相同的元素的个数。
示例:
val conf = new SparkConf().setMaster("local[2]").setAppName("TestCount")
val ssc = new StreamingContext(conf,Seconds(1))
val lines = ssc.socketTextStream("localhost",9999)
val words = lines.flatMap (_.split(" "))
val windowCounts = words.countByValueAndWindow(Second(3),Second(1))
windowCounts.print()
//通过start()启动消息采集和处理
ssc.start()
//启动完成后就不能再做其它操作
//等待计算完成
ssc.awaitTermination()

DStream 输出
输出操作指定了对流数据经转化操作得到的数据所要执行的操作(例如把结果推入外部数据库 或输出到屏幕上)。与 RDD 中的惰性求值类似,如果一个 DStream 及其派生出的 DStream 都没 有被执行输出操作,那么这些 DStream 就都不会被求值。如果 StreamingContext 中没有设定输出 操作,整个 context 就都不会启动。
输出操作如下:
- print():在运行流程序的驱动结点上打印 DStream 中每一批次数据的最开始 10 个元素。这 用于开发和调试。在 Python API 中,同样的操作叫 print()。
- saveAsTextFiles(prefix, [suffix]):以 text 文件形式存储这个 DStream 的内容。每一批次的存 储文件名基于参数中的 prefix 和 suffix。”prefix-Time_IN_MS[.suffix]”。
- saveAsObjectFiles(prefix, [suffix]):以 Java 对象序列化的方式将 Stream 中的数据保存为 SequenceFiles . 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]". Python 中目前不可用。
- saveAsHadoopFiles(prefix, [suffix]):将 Stream 中的数据保存为 Hadoop files. 每一批次的存 储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]"。Python API 中目前不可用。
- foreachRDD(func):这是最通用的输出操作,即将函数 func 用于产生于 stream 的每一个 RDD。其中参数传入的函数 func 应该实现将每一个 RDD 中数据推送到外部系统,如将 RDD 存入文件或者通过网络将其写入数据库。
通用的输出操作 foreachRDD(),它用来对 DStream 中的 RDD 运行任意计算。这和 transform() 有些类似,都可以让我们访问任意 RDD。在 foreachRDD()中,可以重用我们在 Spark 中实现的 所有行动操作。比如,常见的用例之一是把数据写到诸如 MySQL 的外部数据库中。
注意:
- 连接不能写在 driver 层面(序列化);
- 如果写在 foreach 则每个 RDD 中的每一条数据都创建,得不偿失;
- 增加 foreachPartition,在分区创建(获取)。
优雅关闭
流式任务需要 7*24 小时执行,但是有时涉及到升级代码需要主动停止程序,但是分布式程序,没办法做到一个个进程去杀死,所有配置优雅的关闭就显得至关重要了。 使用外部文件系统来控制内部程序关闭。
/*
线程的关闭:
val thread = new Thread()
thread.start()
thread.stop(); // 强制关闭
*/
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lines = ssc.socketTextStream("localhost", 9999)
val wordToOne = lines.map((_,1))
wordToOne.print()
ssc.start()
// 如果想要关闭采集器,那么需要创建新的线程
// 而且需要在第三方程序中增加关闭状态
new Thread(
new Runnable {
override def run(): Unit = {
// 优雅地关闭
// 计算节点不在接收新的数据,而是将现有的数据处理完毕,然后关闭
// Mysql : Table(stopSpark) => Row => data
// Redis : Data(K-V)
// ZK : /stopSpark
// HDFS : /stopSpark
/*
while ( true ) {
if (true) {
// 获取SparkStreaming状态
val state: StreamingContextState = ssc.getState()
if ( state == StreamingContextState.ACTIVE ) {
ssc.stop(true, true)
}
}
Thread.sleep(5000)
}
*/
Thread.sleep(5000)
val state: StreamingContextState = ssc.getState()
if ( state == StreamingContextState.ACTIVE ) {
ssc.stop(true, true)
}
System.exit(0)
}
}
).start()
ssc.awaitTermination() // block 阻塞main线程
案例实操
依赖
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.12artifactId>
<version>3.0.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.12artifactId>
<version>3.0.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-10_2.12artifactId>
<version>3.0.0version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.1.10version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.27version>
dependency>
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-coreartifactId>
<version>2.10.1version>
dependency>
dependencies>
数据生成
def main(args: Array[String]): Unit = {
// 生成模拟数据
// 格式 :timestamp area city userid adid
// 含义: 时间戳 区域 城市 用户 广告
// Application => Kafka => SparkStreaming => Analysis
val prop = new Properties()
// 添加配置
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "linux1:9092")
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String, String](prop)
while ( true ) {
mockdata().foreach(
data => {
// 向Kafka中生成数据
val record = new ProducerRecord[String, String]("atguiguNew", data)
producer.send(record)
println(data)
}
)
Thread.sleep(2000)
}
}
def mockdata() = {
val list = ListBuffer[String]()
val areaList = ListBuffer[String]("华北", "华东", "华南")
val cityList = ListBuffer[String]("北京", "上海", "深圳")
for ( i <- 1 to new Random().nextInt(50) ) {
val area = areaList(new Random().nextInt(3))
val city = cityList(new Random().nextInt(3))
var userid = new Random().nextInt(6) + 1
var adid = new Random().nextInt(6) + 1
list.append(s"${System.currentTimeMillis()} ${area} ${city} ${userid} ${adid}")
}
list
}
需求一:广告黑名单
实现实时的动态黑名单机制:将每天对某个广告点击超过 100 次的用户拉黑。
注:黑名单保存到 MySQL 中。
(1)思路分析
- 读取 Kafka 数据之后,并对 MySQL 中存储的黑名单数据做校验;
- 校验通过则对给用户点击广告次数累加一并存入 MySQL;
- 在存入 MySQL 之后对数据做校验,如果单日超过 100 次则将该用户加入黑名单。
(2)MySQL 建表
# 存放黑名单用户的表
CREATE TABLE black_list (userid CHAR(1) PRIMARY KEY);
# 存放单日各用户点击每个广告的次数
CREATE TABLE user_ad_count (
dt varchar(255),
userid CHAR (1),
adid CHAR (1),
count BIGINT,
PRIMARY KEY (dt, userid, adid)
);
(3)代码
object SparkStreaming11_Req1_BlackList1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("atguiguNew"), kafkaPara)
)
val adClickData = kafkaDataDS.map(
kafkaData => {
val data = kafkaData.value()
val datas = data.split(" ")
AdClickData(datas(0),datas(1),datas(2),datas(3),datas(4))
}
)
val ds = adClickData.transform(
rdd => {
// TODO 通过JDBC周期性获取黑名单数据
val blackList = ListBuffer[String]()
val conn = JDBCUtil.getConnection
val pstat = conn.prepareStatement("select userid from black_list")
val rs: ResultSet = pstat.executeQuery()
while ( rs.next() ) {
blackList.append(rs.getString(1))
}
rs.close()
pstat.close()
conn.close()
// TODO 判断点击用户是否在黑名单中
val filterRDD = rdd.filter(
data => {
!blackList.contains(data.user)
}
)
// TODO 如果用户不在黑名单中,那么进行统计数量(每个采集周期)
filterRDD.map(
data => {
val sdf = new SimpleDateFormat("yyyy-MM-dd")
val day = sdf.format(new java.util.Date( data.ts.toLong ))
val user = data.user
val ad = data.ad
(( day, user, ad ), 1) // (word, count)
}
).reduceByKey(_+_)
}
)
ds.foreachRDD(
rdd => {
// rdd. foreach方法会每一条数据创建连接
// foreach方法是RDD的算子,算子之外的代码是在Driver端执行,算子内的代码是在Executor端执行
// 这样就会涉及闭包操作,Driver端的数据就需要传递到Executor端,需要将数据进行序列化
// 数据库的连接对象是不能序列化的。
// RDD提供了一个算子可以有效提升效率 : foreachPartition
// 可以一个分区创建一个连接对象,这样可以大幅度减少连接对象的数量,提升效率
rdd.foreachPartition(iter => {
val conn = JDBCUtil.getConnection
iter.foreach{
case ( ( day, user, ad ), count ) => {
}
}
conn.close()
}
)
rdd.foreach{
case ( ( day, user, ad ), count ) => {
println(s"${day} ${user} ${ad} ${count}")
if ( count >= 30 ) {
// TODO 如果统计数量超过点击阈值(30),那么将用户拉入到黑名单
val conn = JDBCUtil.getConnection
val sql = """
|insert into black_list (userid) values (?)
|on DUPLICATE KEY
|UPDATE userid = ?
""".stripMargin
JDBCUtil.executeUpdate(conn, sql, Array( user, user ))
conn.close()
} else {
// TODO 如果没有超过阈值,那么需要将当天的广告点击数量进行更新。
val conn = JDBCUtil.getConnection
val sql = """
| select
| *
| from user_ad_count
| where dt = ? and userid = ? and adid = ?
""".stripMargin
val flg = JDBCUtil.isExist(conn, sql, Array( day, user, ad ))
// 查询统计表数据
if ( flg ) {
// 如果存在数据,那么更新
val sql1 = """
| update user_ad_count
| set count = count + ?
| where dt = ? and userid = ? and adid = ?
""".stripMargin
JDBCUtil.executeUpdate(conn, sql1, Array(count, day, user, ad))
// TODO 判断更新后的点击数据是否超过阈值,如果超过,那么将用户拉入到黑名单。
val sql2 = """
|select
| *
|from user_ad_count
|where dt = ? and userid = ? and adid = ? and count >= 30
""".stripMargin
val flg1 = JDBCUtil.isExist(conn, sql2, Array( day, user, ad ))
if ( flg1 ) {
val sql3 = """
|insert into black_list (userid) values (?)
|on DUPLICATE KEY
|UPDATE userid = ?
""".stripMargin
JDBCUtil.executeUpdate(conn, sql3, Array( user, user ))
}
} else {
val sql4 = """
| insert into user_ad_count ( dt, userid, adid, count ) values ( ?, ?, ?, ? )
""".stripMargin
JDBCUtil.executeUpdate(conn, sql4, Array( day, user, ad, count ))
}
conn.close()
}
}
}
}
)
ssc.start()
ssc.awaitTermination()
}
// 广告点击数据
case class AdClickData( ts:String, area:String, city:String, user:String, ad:String )
}
需求二:广告点击量实时统计
描述:实时统计每天各地区各城市各广告的点击总流量,并将其存入 MySQL。
(1)思路分析
- 单个批次内对数据进行按照天维度的聚合统计;
- 结合 MySQL 数据跟当前批次数据更新原有的数据。
(2) MySQL 建表
CREATE TABLE area_city_ad_count (
dt VARCHAR(255),
area VARCHAR(255),
city VARCHAR(255),
adid VARCHAR(255),
count BIGINT,
PRIMARY KEY (dt,area,city,adid)
);
(3)代码
object SparkStreaming12_Req2 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("atguiguNew"), kafkaPara)
)
val adClickData = kafkaDataDS.map(
kafkaData => {
val data = kafkaData.value()
val datas = data.split(" ")
AdClickData(datas(0),datas(1),datas(2),datas(3),datas(4))
}
)
val reduceDS = adClickData.map(
data => {
val sdf = new SimpleDateFormat("yyyy-MM-dd")
val day = sdf.format(new java.util.Date( data.ts.toLong ))
val area = data.area
val city = data.city
val ad = data.ad
( ( day, area, city, ad ), 1 )
}
).reduceByKey(_+_)
reduceDS.foreachRDD(
rdd => {
rdd.foreachPartition(
iter => {
val conn = JDBCUtil.getConnection
val pstat = conn.prepareStatement(
"""
| insert into area_city_ad_count ( dt, area, city, adid, count )
| values ( ?, ?, ?, ?, ? )
| on DUPLICATE KEY
| UPDATE count = count + ?
""".stripMargin)
iter.foreach{
case ( ( day, area, city, ad ), sum ) => {
pstat.setString(1,day )
pstat.setString(2,area )
pstat.setString(3, city)
pstat.setString(4, ad)
pstat.setInt(5, sum)
pstat.setInt(6,sum )
pstat.executeUpdate()
}
}
pstat.close()
conn.close()
}
)
}
)
ssc.start()
ssc.awaitTermination()
}
// 广告点击数据
case class AdClickData( ts:String, area:String, city:String, user:String, ad:String )
}
需求三:最近一小时广告点击量
结果展示:
1:List [15:50->10,15:51->25,15:52->30]
2:List [15:50->10,15:51->25,15:52->30]
3:List [15:50->10,15:51->25,15:52->30]
(1)思路分析
- 开窗确定时间范围;
- 在窗口内将数据转换数据结构为((adid,hm),count);
- 按照广告 id 进行分组处理,组内按照时分排序。
(2)代码
object SparkStreaming13_Req3 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "atguigu",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("atguiguNew"), kafkaPara)
)
val adClickData = kafkaDataDS.map(
kafkaData => {
val data = kafkaData.value()
val datas = data.split(" ")
AdClickData(datas(0),datas(1),datas(2),datas(3),datas(4))
}
)
// 最近一分钟,每10秒计算一次,例如:12:01算在12:00这个点计算
// 12:01 => 12:00
// 12:11 => 12:10
// 12:19 => 12:10
// 12:25 => 12:20
// 12:59 => 12:50
// 55 => 50, 49 => 40, 32 => 30
// 55 / 10 * 10 => 50
// 49 / 10 * 10 => 40
// 32 / 10 * 10 => 30
// 这里涉及窗口的计算
val reduceDS = adClickData.map(
data => {
val ts = data.ts.toLong
val newTS = ts / 10000 * 10000 //例子:12:01 ==> 12:00,时间戳以毫秒为单位
( newTS, 1 )
}
).reduceByKeyAndWindow((x:Int,y:Int)=>{x+y}, Seconds(60), Seconds(10))
//将结果保存到文件中,用于实时显示折线图
reduceDS.foreachRDD(
rdd => {
val list = ListBuffer[String]()
val datas: Array[(Long, Int)] = rdd.sortByKey(true).collect()
datas.foreach{
case ( time, cnt ) => {
val timeString = new SimpleDateFormat("mm:ss").format(new java.util.Date(time.toLong))
list.append(s"""{"xtime":"${timeString}", "yval":"${cnt}"}""")
}
}
// 输出文件
val out = new PrintWriter(new FileWriter(new File("D:\\mineworkspace\\idea\\classes\\atguigu-classes\\datas\\adclick\\adclick.json")))
out.println("["+list.mkString(",")+"]")
out.flush()
out.close()
}
)
ssc.start()
ssc.awaitTermination()
}
// 广告点击数据
case class AdClickData( ts:String, area:String, city:String, user:String, ad:String )
}