ZK锦集:Zookeeper的下载和安装 | 真/伪集群的快速搭建| 总结的很详细
前言
文章力求:通俗易懂、图文并茂、系统全面,语言精练,主要介绍以下知识点:
1.zk基础知识铺路,做到屋里有粮,心中不慌
2.zk的下载、安装、核心参数配置、节点参数释义
3.zk集群快速搭建的两种方式
注:本文以zk的3.4.6版本展开介绍,如想使用更高zk3.8.0版本[下载](需要下载已编译的bin版本),则需要注意一些细节,本文依然适合你阅读,里面的坑,已经标注。
如果感兴趣ZK常规命令,请参考:
zookeeper常规命令 | Watch | ACL权限操作 | nc四字命令详解
一、概述
1.zk概述
Zookeeper是谷歌基于Java语言开发的分布式协调服务,是Hadoop和Hbase的重要组件。基于java语言开发的分布式组件,Zookeeper的本意就是动物管理员,它里面有大象Hadoop、小猪Pig(组件)、Hive蜜蜂,成员依然在持续壮大中。
2.作用
1.zk节点可以存储1M数据,作为中间件可以提供协调服务(比如用来存储、计算、缓存)
2.可以为大数据服务,比如配置维护、命名服务、同步服务。
3.提高程序的高可用(通过快速选举Leader+分布式锁的watch实现)
3.特性
1.最终一致性︰数据一致性,数据按照顺序分批入库(仅Leader有事务操作权限)
2.原子性︰事务要么成功要么失败,不会局部化
3.统—视图︰客户端连接集群中的任—zk节点,数据都是一致的
4.可靠性︰每次对zk的操作状态都会保存在服务端(一台宕机,无感被切换到另一台继续处理),Keepalive没有这一特性。
5.实时性︰客户端可以读取到zk服务端的最新数据
6.独立性:各个Client之间互不干预
4.版本变迁
ZooKeeper3.6引入了观察者Observer角色,之前版本只有Leader和Flower,截止收稿(2021.12),最新版本更新到ZooKeeper3.7.1[下载]
截止2022年11月13日,zk已更新至 Zookeeper3.8[下载]
1.Observer引入原因
1.早期版本ZooKeeper集群无法做到跨域部署。
2.随着集群规模的变大,Flower越来越多,彼此的网络通信也变得越来越耗时,集群处理写入的性能反而下降。
2.Observer[观察者]特色
1.Observer功能上和Flower的主要区别是它没有选举和被选举权。
2.Observer 可以处理 ZK在集群中的非事务性请求,不参与投票操作,这样既保证了集群扩展性,又避免了因为过多的服务器参与投票相关的操作而影响 ZooKeeper 集群处理事务性会话请求的能力。
3.Observer 不参与 Leader 节点等操作,并不会像 Follow 服务器那样频繁的与 Leader 服务器进行通信。因此,可以将 Observer 服务器部署在不同的网络区间中,这样也不会影响整个 ZooKeeper 集群的性能,也就是所谓的跨域部署。
3.Observer配置示例
peerType=observer 此行代码,只需在observer观察者所在这台机器的zoo.cfg中配置!!!
server.1=192.168.31.214:2888:3888
server.2=192.168.31.215:2888:3888
server.3=192.168.31.216:2888:3888:observer 本行代码,集群中所有配置文件都要一样一般小公司的zk,3、5、6、7、9台机器就够用了,observer用的场景不多。
5.小常识[建议了解]
1.zk集群部署,节点需要是奇数
1.便于容错
因为新的Leader的选举,需要半数通过。
假如有3台服务器,只要有两台就可以半票通过,可以允许坏一台。
假如有4台服务器,3台投票,才能达到半票通过,依然是只能允许坏一台。
容错性相同,从这个角度,考虑没有必要多消耗一台服务资源。
但是,非要部署4台也是可以的,多少能提高点儿效率,成本稍多一点。2.预防脑裂(面试加分项)
因彼此通信不畅,导致一个集群变成2个集群,两个Leader,从而出现脑裂。
如果是5台,脑裂出现的投票组合可能是
2+3 ;3+2; 1+4;4+1;
无论是哪种组合,两个数字,都是一边大一边小,大那组依然可以正常通过半数投票选举机制。如果是6台,脑裂出现的组合可能是
3+3 ;4+2; 4+2;5+1;1+5
一旦脑裂为3+3这种组合,两边相持不下,无法通过半数投票选举机制,选举新的leader。所以,要预防脑裂,避免出现2个Leader,否则数据就会错乱(两个Leader的数据可能会不一致)。
2.不要把ZK当做数据库使用
虽然每个节点,都可以存储1M的数据,但是不建议把它当做数据库使用,如果一定要使用,不如redis(数据类型丰富、操作简单、存储数据没有1M限制)更适合。
3.zk的节点分为临时节点,永久节点
临时节点会随着会话的消失而自动消失,永久节点的数据不会自动消失
4.只有Leader是有一个,且只有它有写权限,Flower只有读权限
除了以上这些,还有很多其他的小常识,篇幅问题,不再一 一罗列,了解了这些,做到屋里有存粮心中不慌,下面开启ZK之旅吧!
二、zk的下载和安装
1.下载地址, 官网首页,如下图所示,点击DownLoad
zk3.4.6下载、zk3.5.1下载、zk3.6.3下载、zk3.7.1下载、zk3.8.0下载
1、注意事项
如果想使用3.5.5+=的zk版本,则需要选择下图中,上面已编译的bin版本链接进行下载,否则你即将遇到Error contacting service的错误(更多详情,点击进入),将直接导致zk服务无法启动。

2、如何在java项目中,配置pom.xml中zk依赖
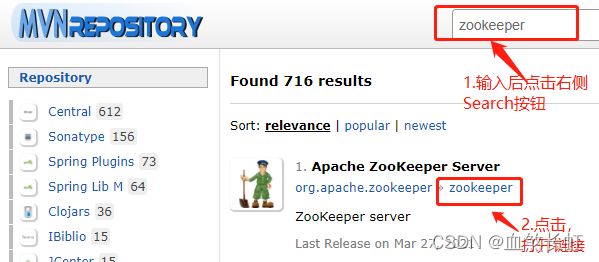
1)如下图所示,点击进入MvnRepository仓库,顶部查询框输入Zookeeper点击Search
2)选择对应版本下载
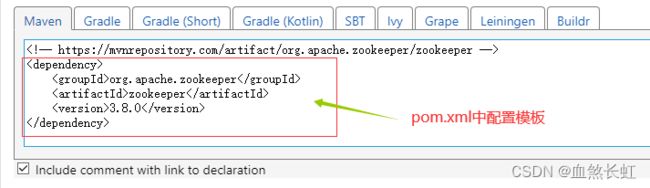
3)复制模板内容到maven工程的pom.xml即可
2.安装步骤
1.上传到指定目录,并解压到指定目录
#rz 上传zk安装包到mypackage目录(视自己习惯而定)
#ls 查看上传列表
zookeeper-3.4.6.tar.gz
#tar -xf zookeeper-3.4.6.tar.gz -C /usr/src 解压到指定本目录
#cd /usr/src zookeeper-3.4.6 && ls 切换到解压目录,并查看解压列表注:解压后的各目录作用,底部附录有单独介绍。
2.配置环境变量(配置环境变量,才可以在任意目录使用zk服务命令)
#vim /etc/profile以下配置,添加到文件内容底部:
export ZOOKEEPER_HOME=/usr/src/zookeeper-3.4.6 解压目录的全路径
export PATH=$PATH:$REDIS_HOME/bin:$TWEMPROXY_HOME/sbin:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin
注意:path后面的分隔符是冒号:不是分号;
总体步骤:
1.配置ZOOKEEPER_HOME,也就是zk的完整解压目录
2.把:ZOOKEEPER_HOME/bin拼接到PATH变量后面(彼此变量之间,分隔符是:)
3.执行命令,#source /etc/profile 刷新环境变量,使配置生效
3.配置zoo.cfg核心配置文件
#cd /usr/src/zookeeper-3.4.6
#cd conf && ls
#cp zoo_sample.cfg zoo.cfg && ls
注:zk启动,默认加载的配置文件是zoo.cfg1.【参数释义】(重要)
1.tickTime计算的时间基础单元
tickTime:发生心跳的间隔时间,用于计算的时间单元的基数单位,默认是2000毫秒
2.initLimit从节点连接主节点的通信(init初始化时)最长等待时间
initLimit :用于集群,slave首次跟随leader,leader最长等待时间,超时没有匹对成功,Flower将会被Leader放弃。
默认是10,它的计算以tickTime的倍数来表示:10*2000=20秒
3.syncLimit心跳时间
syncLimit :主从同步限制(用于集群),master主节点与从节点之间发送消息,请求和应答时间长度。(心跳机制)最长不能超过多少个tickTime的时间长度。
一旦超过设定的心跳时间,主从仍未能流畅应答,从节点就会被抛弃。
默认是5,它的计算,也是以tickTime的倍数来表示:5*2000=10秒
4.dataDir持久化目录
dataDir :必须配置的持久化目录,不建议放在temp的临时目录下
比如,可以存到:/usr/local/zookeeper/dataDir
5.dataLogDir日志目录
dataLogDir :日志目录
比如,可以存到:/usr/local/zookeeper/dataLogDir
6.clientPort客户端端口
clientPort :连接服务器的端口,默认2181
如果是伪分布,我们搭建的三台服务器,各端口可能是不同(依次排列的)
7.server.A=B:C:D (集群参数)
A:是一个数字,表示这个是第几号服务器;
B:服务器的ip地址(伪集群,在同一台虚拟实现集群,IP是一样的,相当于一台电脑安装了多个zk,ip相同,端口不通)
C:主从信息交互端口
D:Leader选举端口。表示的是如果集群中的Leader服务器挂了,需要一个端口来重新进行选举 ,选出一个新的Leader ,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于B都是一样, 所以不同的Zookeeper实例通信端口号不能一样 ,所以要给它们分配不同的端口号
示例:
server.2=192.168.31.215:2888:38882.zoo.cfg单机版,具体配置
#cd /usr/local && ls
#mkdir -p /zookeeper/dataDir /zookeeper/dataLogDir 创建持久化目录和日志存放目录
把dataDir和dataLogDir,两个参数配置一下,如下:
#cd /usr/src/zookeeper-3.4.6
#cd conf && ls
#vim zoo.cfgdataDir=/usr/local/zookeeper/dataDir
dataLogDir=/usr/local/zookeeper/dataLogDir
当然,你也可以把目录建设为/usr/local/datas下面
三、集群的通信原理
1.Redis哨兵的集群是通过哨兵机制自动发现Slave
Redis哨兵只监听master,通过master的发布订阅机制获悉其他的哨兵,然后关键时候这些哨兵集中投票,redis 在配置投票多少算过半是写在哨兵配置文件中的。
2.Zookeeper的集群需要手动配置Flower(暂没自动发现机制)
zk的这个机制要手动配,靠人去规划集群,它没有发布订阅机制,发现其他的“哨兵”,需人为的把这些“哨兵”都罗列一遍,写出来。这些“Flower”的行数÷2+1,就是过半数。
如下配置,需要配置在zoo.cfg的底部(如果是本地部署,下面的ip也可以是服务器的名称)
server.1=192.168.31.214:2888:3888
server.2=192.168.31.215:2888:3888
server.3=192.168.31.216:2888:3888
server.4=192.168.31.217:2888:3888
server.5=192.168.31.218:2888:3888
2888,是通信端口,3888是选举端口。
当leader挂掉时或者第一次启动没有leader时,会通过3888端口建立连接,在3888端口中进行选举、投票,选举完毕后,新的leader会开启2888的端口,后续通过2888彼此进行通信。
原有leader挂了,在200毫秒内推选出新的leader。实质上,并不是推选的,是按服务名称排位资格最老,数据版本最新的推选为新leader,如上就是server.5 ,是谦让出来的。
3. Zookeeper的集群的myid配置(该步骤不可省略)
需在每个Zookeeper的持久化目录(zoo.cfg中配置的dataDir)dataDir的根目录中创建myid这个文件,文件内容只需要有1个数字,代表当前zk是第几个服务器即可。
四、zk伪集群的搭建
应用场景:电脑配置比较差,硬盘空间不足。
伪分布式集群,一旦一个节点挂机,整个集群将不可用(一般是在同一台服务器上)。
总体步骤预览:
1、在同一台电脑复制三份Zookeeper源文件解压包
2、分别进入zoo.cfg中依次修改port端口,比如2181、2182、2183。
1.部署步骤
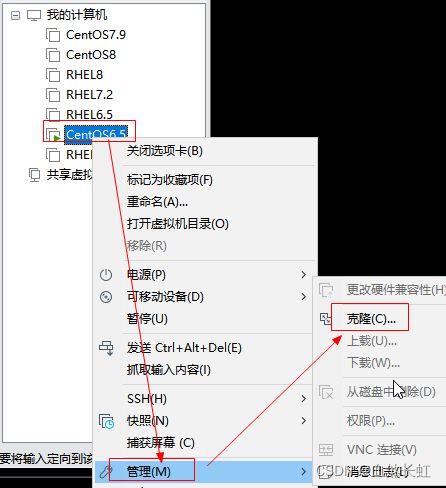
1.准备一台已安装好zk单例模式的linux服务器
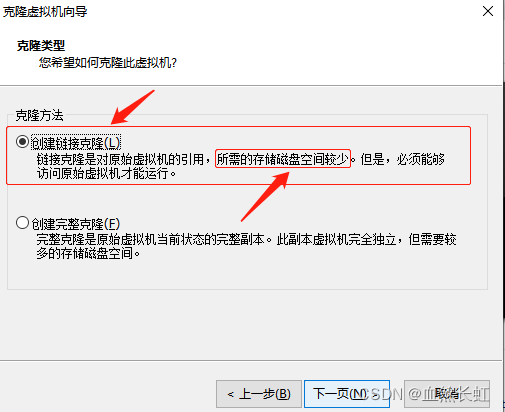
在关机模式下,鼠标右键点击虚拟机上需要被克隆的服务器,依次点击管理、克隆。
注:克隆的时候,选择“创建链接克隆”,比较节省服务器硬盘资源。
2.在克隆机器上,复制两份zk安装包
#cd /usr/src && ls
#cp -rf zookeeper-3.4.6 zookeeper02
#cp -rf zookeeper-3.4.6 zookeeper03
#cd zookeeper-3.4.6/conf && ls3.分别修改各zk安装的zoo.cfg(在解压目录的/conf下)
步骤:
1、需要修改port对外服务端口,分别修改为2181、2182、2183
2、底部添加伪集群配置(其中的端口分别是主从间的通信端口和选举端口,不要和上面的port混淆了)
把zk服务的信息,放在zoo.cfg尾行
server.1=192.168.31.213:2888:3888
server.2=192.168.31.213:2889:3889
server.3=192.168.31.213:2890:38904. 分别进入各zk配置的持久化目录,新建myid,并写入各自的编号1、2、3
示例如下:
#cd /usr/local/zookeeper/dataDir
#vim myid
1
2.分别启动3个节点的server服务
#cd /usr/src/zookeeper-3.4.6/bin && ls
#./zkServer.sh restart#cd /usr/src/zookeeper02/bin && ls
#./zkServer.sh restart#cd /usr/src/zookeeper03/bin && ls
#./zkServer.sh restart
echo stat | nc localhost 2181 //用四字命令查看集群信息,可以得知哪个是leader注:stat是四字命令之一,想更多的了解四字命令,点击进入。
3.验证Node节点
具体验证方法:启动2181客户端,创建节点后退出,登录2182看节点是否存在
1.启动2181客户端,创建节点
#zkCli.sh -server localhost:2181
#create /succ '123'
2.开启新窗口,进入2182客户端,查看节点
#ls / 发现是可以看到在2181创建的节点的
[succ]
#get /succ
123
至此,伪集群搭建完毕!
五、zk集群的搭建
伪集群的搭建:
主要是节省硬盘空间,一台机器上,复制多份Zookeeper,然后分别配置为不同的端口号2181、2182、2183,因为在同一台机器,所以他们的IP是相同的。缺点是,一台都不能挂掉。
注:2181、2182、2183端口号,分别是在各zk安装目录的zoo.cfg文件中配置,具体在上面第四章节已介绍。
真集群的搭建:
相对就需要较多的资源,因为是部署在不同的机器上,ip自然不同,但是他们的端口号可以相同,都是2181,且集群中的通信端口和选举端口也都可以是相同的。
1.部署步骤
1.准备一台已配置了单机版zk的服务器,克隆3台node节点
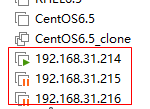 注意:是完整克隆,非链接模式克隆
注意:是完整克隆,非链接模式克隆
2.分别进入进入node1、node2、node3修改配置
#vim zoo.cfgserver.1=192.168.31.214:2888:3888
server.2=192.168.31.215:2888:3888
server.3=192.168.31.216:2888:3888
注:只需在zoo.cfg底部添加上面相同配置即可,对外提供服务的port端口2181不必修改。
3.分别进入各zk配置的持久化目录,新建myid,并写入各自的编号1、2、3
示例如下:
#cd /usr/local/zookeeper/dataDir
#vim myid
1
2.验证步骤
1.分别进入不同的集群,命令启动zkServer服务
# zkServer.sh start
2.分别查看每个节点的status,可以得知主从信息
# zkServer.sh status
3.在Leader所在机器,登录zk客户端,设置新节点,再登录任一Flower节点客户端查看节点
示例如下:
#zkCli.sh -server 192.168.31.212:2181
#create /real-cluster '222'
#zkCli.sh -server 192.168.31.213 2181
#get /real-cluster
#zkCli.sh -server 192.168.31.214 2181
#get /real-cluster
最终可以发现,在一台机器上设置的节点,在集群中的其他zk上都可以获取到。
4.zk选举测试
模拟步骤:
1.进入leader所在机器,模拟leader宕机
#./zkServer.sh stop
2.剩余的Flowers会在极短时间(200毫秒内)内推选出新的Leader
一般会优先推选myid大的节点当做leader,这里就是node3
3.当旧的Leader从宕机,重新启动zkServer.sh服务后,会自动成为Flower.
具体,自己可以在本机自己实验一下,只需要关闭leader的服务即可。
六、附注
1.Zookeeper解压目录介绍
1.bin目录
# ls bin
README.txt zkCli.cmd zkEnv.cmd zkServer.cmd zookeeper.out
zkCleanup.sh zkCli.sh zkEnv.sh zkServer.sh可以看到,里面有zk客户端和服务端的启动命令,其中sh结尾的是linux系统下的启动命令,cmd结尾的是Windows系统下的启动命令。
2.conf目录
# ls conf
configuration.xsl log4j.properties zookeeper.out zoo_sample.cfgzoo_sample.cfg是模板配置文件,zk启动时要读取的,稍后需要据此复制一份做为zk服务的配置文件。
log4j.properties,可以直接复制一份到java工程中使用,可以更详细的打印zk的日志信息。
3.contrib目录
# ls contrib/
fatjar loggraph rest zkfuse zkperl zkpython zktreeutil ZooInspector目录存放的是zk对附加功能的支持
4.dist-maven目录(maven相关依赖包)
# ls dist-maven/
zookeeper-3.4.6.jar zookeeper-3.4.6.pom.md5
zookeeper-3.4.6.pom zookeeper-3.4.6-tests.jar.md5
zookeeper-3.4.6.pom.asc zookeeper-3.4.6-tests.jar.sha1 …… …… ……
里面Maven相关的jar包、pom文件
5.docs文档帮助目录
# ls docs/
api skin
bookkeeperConfig.html zookeeperAdmin.html
index.html zookeeperOver.html
index.pdf zookeeperOver.pdf …… …… ……主要作用:方便离线查看,很详细,点击index.html即可
6.lib目录,存放java开发常用jar包
# ls lib
netty-3.7.0.Final.jar jdiff log4j-1.2.16.jar slf4j-api-1.6.1.jar jline-0.9.94.jar slf4j-log4j12-1.6.1.jar ……
7.recipes案例Demo
# ls recipes/lock/
build.xml src test
# ls recipes/lock/src/
c java
# ls recipes/lock/src/java/
org
# ls recipes/lock/src/java/org/apache/zookeeper/recipes/lock/
LockListener.java WriteLock.java ZooKeeperOperation.java
ProtocolSupport.java ZNodeName.java主要是提供了Java和C两种语言的操作案例,协助我们快速上手客户端代码
8.src源码目录
# ls src
c docs lastRevision.bat packages zookeeper.jute
contrib java lastRevision.sh recipes
便于在项目中查看zk的class源码
尾言
至此,本文已经把zk的下载到安装,然后又分别介绍了zk集群的两种搭建方式,希望对你有所帮助,如果觉得还不错,赶快收藏一下吧!
猜你还可能感兴趣
1、Curator/Zookeeper如何判断一个节点是否存在
2、ZK 常规命令、监控命令、ACL权限操作 、四字命令详解
3、java代码实现CountDownLatch 调度中心模拟火箭发射场景