1_14_Python基础0427学习总结_
20190305
Python解释器:将python代码解释给电脑看的一种工具。
当我们编写Python代码时,我们得到的是一个包含Python代码的以.py为扩展名的文本文件。要运行代码,就需要Python解释器去执行.py文件。
由于整个Python语言从规范到解释器都是开源的,所以理论上,只要水平够高,任何人都可以编写Python解释器来执行Python代码(当然难度很大)。事实上,确实存在多种Python解释器。
1.安装python解释器
CPython
当我们从Python官方网站下载并安装好Python 3.x后,我们就直接获得了一个官方版本的解释器:CPython。这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器。
CPython是使用最广的Python解释器。教程的所有代码也都在CPython下执行。
IPython
IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。好比很多国产浏览器虽然外观不同,但内核其实都是调用了IE。
CPython用>>>作为提示符,而IPython用In [序号]:作为提示符。
PyPy
PyPy是另一个Python解释器,它的目标是执行速度。PyPy采用JIT技术,对Python代码进行动态编译(注意不是解释),所以可以显著提高Python代码的执行速度。
绝大部分Python代码都可以在PyPy下运行,但是PyPy和CPython有一些是不同的,这就导致相同的Python代码在两种解释器下执行可能会有不同的结果。如果你的代码要放到PyPy下执行,就需要了解PyPy和CPython的不同点。
Jython
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
IronPython
IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
20190312

如何查看系统环境变量:

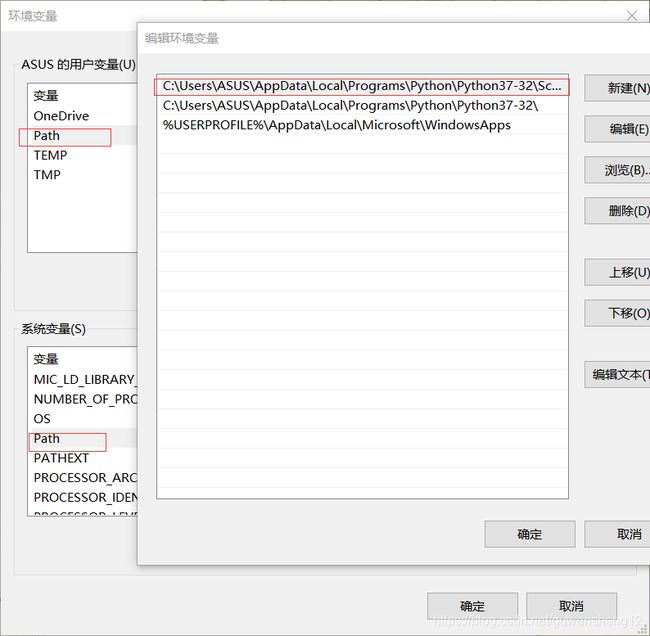
windows+r --------调出运行窗口-----输入CMD-------调出dos命令窗口
python的安装
1.直接安装,勾选 add the python 即可
在dos命令窗口输入python命令 —查看python是否安装好。
如果出现:

说明安装成功,Python 3.6.4表示python的版本。也可以通过 python –V ·r查看python版本。
“>>>” 表示:已经进入了python的交互界面。就可以在这写python代码了。
如何退出: exit() 或者 ctrl+z 然后enter
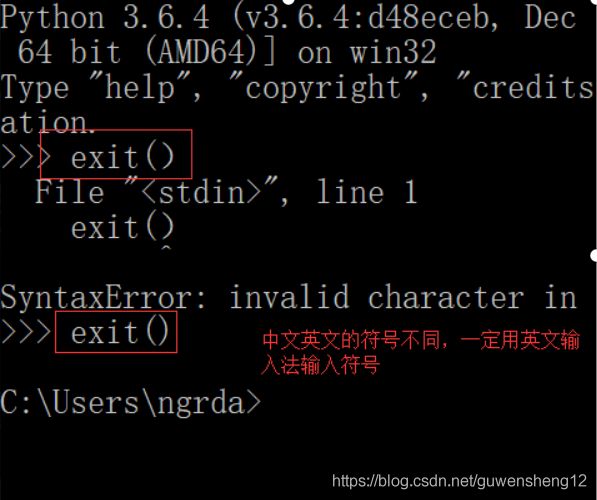
如果出现:

说明:没有添加python.exe的路径到Path。

在dos命令窗口下面,输入 python或者pip 命令。系统首先通过系统环境变量去找python.exe的路径,如果找到了上面的python.exe的路径。那么就能识别pip这个命令(python命令也相同。)
请注意区分命令行模式DOS和Python 交互模式

看到类似 C:> 是在 Windows 提供的命令行模式,看到 >>> 是在Python交互式环境下

第一个 Python程序

在写代码之前,请千万不要用“复制”“粘贴”把代码从页面粘贴到你自己的电脑上。写程序也讲究一个感觉,你需要一个字母一个字母地把代码自己敲进去,在敲代码的过程中,初学者经常会敲错代码,所以,你需要仔细地检查、对照,才能以最快的速度掌握如何写程序
在交互式环境的提示符 >>> 下,直接输入代码,按回车,就可以立刻得到代码执行结果。现在,试试输入 100+200 ,看看计算结果是不是 300:
2.print语句:让Python 打印出指定的文字
然后把希望打印的文字用单引号或者双引号括起来,但不能混用单引号和双引号
C语言: 一个字符用单引号括起来,一个以上的字符(字符串)用双引号括起来
python:随意用,不管是几个字符,想用单引号括起来就用单引号,想用双引号就用双引号。
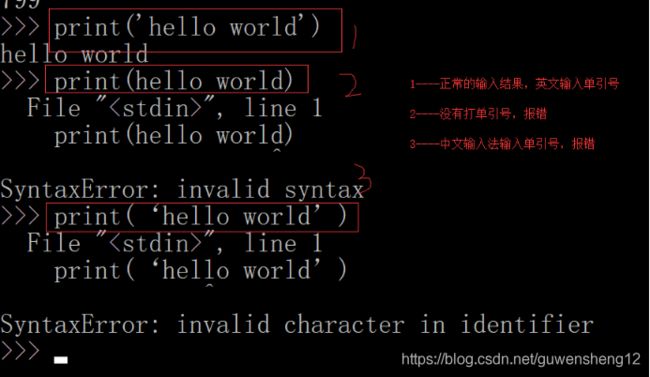

第一个是中文输入法,第二个是英文输入法
如何用python文件保存自己写的代码。因为python交互界面不能保存代码。
步骤:
1.自己选在一个盘(D盘或EFGHIJ盘都可以),然后创建一个文件夹(命名为:python_file)。这个文件夹专门用来装python文件。
2.在python_file文件加下面:创建一个python文件。
(如何创建python文件。首先创建一个txt文件,然后将后缀名改为.py即可)
3.安装一个notepad文本编辑器,就可以通过它编辑python文件。
4.写好python文件之后,如何运行? 可以在 DOS命令窗口,通过 python start.py 来运行我们编辑好的python文件。
注意:python文件的位置

如果python文件不在当DOS路径下,那么用python的绝对路径执行。如上图1所示。
也可以,跳转到要执行的python文件的路径下,通过方式2运行python。
小结:
用文本编辑器写Python 程序,然后保存为后缀为 .py 的文件,就可以用Python直接运行
这个程序了。
直接输入 python 进入交互模式,相当于启动了Python 解释器,但是等待你一行一行地输
入源代码,每输入一行就执行一行。
直接运行 .py 文件相当于启动了Python解释器,然后一次性把 .py 文件的源代码给执行了,
你是没有机会输入源代码的。
**我们以后基本用:**文本编辑器起写python代码。
输入和输出
python2版本: print “hello world” 没有括号
python3版本: print(“hello world”) 有括号
“diandian” “qiuqiu” “明明”
用逗号连接字符串
print(“diandian” “qiuqiu” “明明”)

优化输出结果:

输入:语句:可以让用户输入字符串,并存放到一个变量
python2版本 raw_input()
python3版本 input()

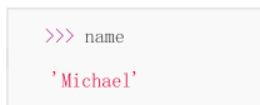
你输入 name = input() 并按下回车后,Python 交互式命令行就在等待你的输入了。
这时,你可以输入任意字符,然后按回车后完成输入
输入完成后,不会有任何提示,Python 交互式命令行又回到 >>> 状态了。那我们刚才输入的内容到哪去了?答案是存放到 name 变量里了。可以直接输入 name 查看变量内容:
还可以:
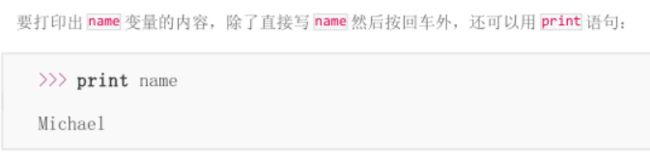
**什么是变量?**请回忆初中数学所学的代数基础知识:
设正方形的边长为 a ,则正方形的面积为 a x a 。把边长 a 看做一个变量,我们就可以根据
a 的值计算正方形的面积,比如:
若a=2,则面积为 a x a = 2 x 2 = 4;
若a=3.5,则面积为a x a = 3.5 x 3.5 = 12.25。
在计算机程序中,变量不仅可以为整数或浮点数,还可以是字符串,因此, name 作为一个
变量就是一个字符串


tips:
ctrl+s :保存
ctrl+c :复制
ctrl+v: 粘贴
后缀名隐藏怎么办:

tab: dos补全快捷键
20190312
搭建python环境
入门python程序 输入输出
20190319
缩进方式
4个空格=一个tab
以#开头的语句是注释
Absolute(绝对值) abs(-177)=177
大小写敏感
Zhangsan zhangsan ZHangsan lisi Lisi
水果:fruit 蔬菜:vegetable
数据类型和变量
数据类型:代表计算机当中不同的数据
Python的数据类型
- 整数
正整数、负整数、0
例如:1,100,-8080,0,等等
二进制和16进制用0x前缀
和0-9,a-f 表示,例如:0xff00,0xa5b4c3d2,等等。
- 浮点数(数学当中的小数)
如1.23,3.14,-9.01,等等。单是对于很大或很小的浮点数,就必须用科学计数法表示,把10用e代替
浮点数也就是小数
- 字符串
字符串是以(“单引号)或者(”"双引号)括起来的任意文本。
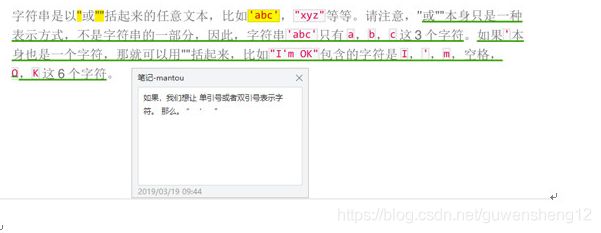
单引号双引号区别:
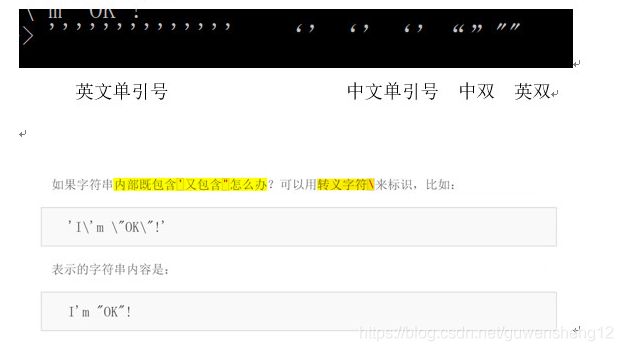
转义字符练习

比如
\n表示换行,
\t表示制表符,字符\本身也要转义,
\表示的字符就是,
可以在Python的交互命令行用print打印字符串看看
转义:就是把特殊字符转换为可以输出的普通字符。
4.布尔值:
布尔值和布尔代数的表示完全一致,一个布尔值只有True、 False两种值,要么是True、要么是False,在Python中,可以直接用True、False表示布尔值(请注意大小写),也可以通过布尔运算计算出来
布尔值可以用and、or和not运算
and——只要有一个为假就是假
or——只要有一个为真就是真
not——非,取反
5.空值 None里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而
None是一个特殊的空值
Python的数据类型:整数、浮点数、字符串、布尔值、空值。
变量:
变量命名:
变量名必须是大小写英文、数字和_的组合,且不能用数字开头
判断下面的变量名是否正确
asd_123 √
_ground_truth_123 √
__123_asd √
123__123_sns ×
a √
_ √
1 ×
asd_1 asd × 有空格
规范命名法:驼峰命名法:第一个字母小写,后面首字母大写。
eg: 桌子和水果:tbleAndFruit
女朋友:girlFriend
性别:
gender
用户名:
userName
密码:
passWord
获取用户名和密码:getUsernameAndPassword #获取用户名和密码
Python定义变量:
a=1 变量a是一个整数。
Java定义变量:
数据类型 变量名=1
int a=;
总结:Python变量的数据是类型,在于你给它赋什么样类型的数据。
a=“asdf " a=True a=1.234
a=None
变量本身数据类型不固定的语言——动态语言 eg:python
静态语言在定义、变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错
eg: java, C++ C#
请不要把赋值语句的等号等同于数学的等号
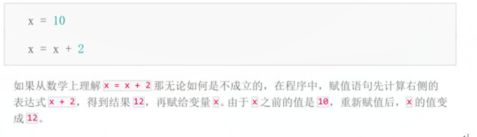
预习:变量在计算机内存中的表现
命名: programming Software
作为计算机系统硬件的对立面的术语
EDVAC ------- 世界上第一架可编程序的电子数字计算机
通用图灵机 -------
20190326
)理解变量在计算机内存中的表示也非常重要
A = ‘abc’时
Python解释器干了两件事情:
1.在内存中创建了一个‘ABC’的字符串
2.在内存中创建了一个名为A的变量,并把它指向‘ABC’
也可以把一个变量 a 赋值给另一个变量 b,这个操作实际上是把变量 b 指向变量 a 所指向的数据,例如下面的代码:

问?最后一行打印出变量B的内容到底是 ‘ABC’呢还是‘XYZ’????
如果从数学意义上理解,就会错误地得出 B 和 A 相同,也应该是’XYZ’
但实际上B的值是‘ABC’。
我们一行一行地执行代码,就可以看到到底发生了什么事
执行A =‘ABC’时, 解释器创建了字符串‘ABC’和变量A,并把A指向‘ABC’

执行 B = A, 解释器创建了变量B, 并把B指向A指向的字符串‘ABC’

执行A=‘XYZ’,并把A的指向改为‘XYZ’但B并没有更改

所以:最后打印变量B的结果自然是 ‘ABC’了
eg:
a = ‘red’
a = ‘blue’
b = a
b = ‘black’
print(a)
常量:
所谓常量就是不能变的变量,比如常用的数学常数 π 就是一个常量。在 Python 中,通常用全部大写的变量名表示常量
PI = 3.1415
但事实上 PI 仍然是一个变量,Python 根本没有任何机制保证 PI 不会被改变,所以,用全
部大写的变量名表示常量只是一个习惯上的用法,如果你一定要改变变量 PI 的值,也没人
能拦住你
最后解释一下整数的除法为什么也是精确的

总结:
整数除法永远是整数,即使除不尽。要做精确的除法,只需把其中一个整数换
成浮点数做除法就可以
无论整数做除法还是取余数,结果永远是整数,所以,整数运算结果永远是精确的。
1.Python 支持多种数据类型。
2.在计算机内部,可以把任何数据都看成一个“对象”。
3.变量就是在程序中用来指向这些数据对象的。
4.变量赋值就是把数据和变量给关联起来。
字符串和编码
字符编码:
首先我们知道,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题!
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理,最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大整数就是255(二进制11111111 = 十进制255),如果要表示更大的整数,就必须用更多的字节。
比如两个字节可以表示的最大整数是65535,4 个字节可以表示的最大整数是4294967295
由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些字符,这个编码表被称为ASCII编码,比如大写字母A的编码时候65
小写字母a的编码是97.
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和 ASCII 编码冲
突,所以,中国制定了 GB2312 编码,用来把中文编进去
你可以想得到的是,全世界有上百种语言,日本把日文编到 Shift_JIS 里,韩国把韩文编到 Euc-kr 里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的 文本中,显示出来会有乱码。

因此,Unicode诞生,Unicode把所有语言都统一到一套编码里,这样就不会再出现乱码
Unicode 标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要 4 个字节)。现代操作系统和大多数编程语言都直接支持 Unicode
现在,捋一捋 ASCII 编码和 Unicode 编码的区别:ASCII 编码是 1 个字节,而 Unicode 编码通常是 2 个字节。
字母 A 用 ASCII 编码是十进制的 65,二进制的 01000001;
字符 0 用 ASCII 编码是十进制的 48,二进制的 00110000,注意字符’0’和整数 0 是不同的;
汉字中已经超出了 ASCII 编码的范围,用 Unicode 编码是十进制的 20013,二进制的
01001110 00101101。
你可以猜测,如果把 ASCII 编码的 A 用 Unicode 编码,只需要在前面补 0 就可以,因此,A 的 Unicode 编码是 00000000 01000001。
新的问题又出现了:如果统一成 Unicode 编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用 Unicode 编码比 ASCII 编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把 Unicode 编码转化为“可变长编码”的 UTF8 编码 。
UTF-8 编码把一个 Unicode 字符根据不同的数字大小编码成 1-6 个字节,常用的英文字母被编码成 1 个字节,汉字通常是 3 个字节,只有很生僻的字符才会被编码成 4-6 个字节。如果你要传输的文本包含大量英文字符,用 UTF-8 编码就能节省空间
总结:
在计算机内存中,统一使用 Unicode 编码,当需要保存到硬盘或者需要传输的时候,就转换为 UTF8 编码。
用记事本编辑的时候,从文件读取的 UTF8 字符被转换为 Unicode 字符到内存里,编辑完 成后,保存的时候再把 Unicode 转换为 UTF8 保存到文件:

浏览网页的时候,服务器会把动态生成的 Unicode 内容转换为 UTF8 再传输到浏览器:

所以你看到很多网页的源码上会有类似的信息,表示该网页正是 用的 UTF8 编码。
Python字符串
python中字母与ascii码的相互转换
ord©:参数是长度为1的字符串,简称字符。ord(‘a’)返回整形数值97
chr(i):返回一个字符,字符的ascii码等于参数中的整形数值。例如chr(97)返回字符’a’,该方法是ord()的反方法。参数必须是0-255的整形数值,否则会抛出valueError错误
软件工程第二章 : 可行性研究
2.1可行性研究的任务
可行性研究就是要回答“所定义的问题有可行的解决办法吗?”
可行性研究的目的: 用最小的代价在尽可能短的时间内确定问题是否有解,以及是否值得去解。
可行性研究所需时间取决于工程的规模,所需要的成本要占工程总成本的5%-10%
20190402
pycharm补充:
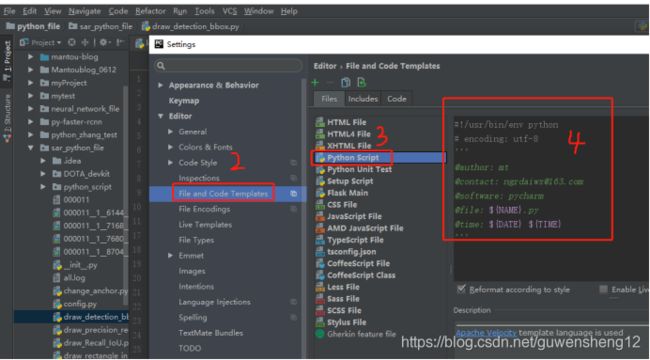
#!/usr/bin/env python
-- coding: utf-8 --
第一行注释是为了告诉 Linux/OS X 系统,这是一个 Python 可执行程序,Windows 系统会忽略这个注释;
第二行注释是为了告诉 Python 解释器,按照 UTF8 编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码
格式化:
我们经常会输出类似’亲爱的 xxx 你好!你xx 月的话费是 xx,余额是 xx’
之类的字符串
而 xxx 的内容都是根据变量变化的,所以,需要一种简便的格式化字符串的方式。```
举例说明:
print(‘Hello, %s’ % ‘world’)
print(‘Hi, %s, you have $%d.’ % (‘Michael’, 1000000))
说出的是什么
总结: %,%s,%d
% -----------------占位符。
%s ----------------表示字符串的占位符。
%d-----------------表示整数的占位符
常见的占位符: %d %f %s
print(’%2d-%02d’ % (3, 1))
print(’%.2f’ % 3.1415926)
总结:
%2d -----表示两个占位符,如果数不够,用空格来站位
%02d-----也表示两个占位符,如果数不够,用0来站位
%.2f ------保留小数点后面两位。
如果你不太确定应该用什么占位符,
%s 永远起作用,它会把任何数据类型转换为字符串
print(‘Age: %s. Gender: %s’ % (25, True))
print(‘Age: %s. Gender: %s,score: %.5s’ % (25, True,89.786))
eg:89.786
%.3s ------表示3个位置,包括小数点,空格等。
89.
%.3f ------表示小数点后面三位。
89.786
有些时候,字符串里面的%是一个普通字符怎么办?
这个时候就需要转义,用%%来表示一个%
print(‘growth rate: %d %%’ % 7)
7%
format()
另一种格式化字符串的方法是使用字符串的format()方法,它会用传入的参数依次替换字符串内的占位符{0}、{1}……,不过这种方式写起来比%要麻烦得多:
print(‘Hello, {0}, 成绩提升了 {1:.1f}%’.format(‘小明’, 17.125)
练习
小明的成绩从去年的72分提升到了今年的85分,请计算小明成绩提升的百分点,并用字符串格式化显示出’xx.x%’,只保留小数点后1位:显示类容为: hello, XXX,成绩提高了 xx.x%
s1 = 72
s2 = 85
r =
print(’???’ % r)
s1 = 72
s2 = 85
r = (s2 - s1)/s1*100
name = ‘小明’
print(‘hello, %s, 成绩提高了:%.2f %%’ % (name,r))
print(‘hello, %s, 成绩提高了:%.4s %%’ % (name,r))
使用 list 和 tuple
也是一种python内置的数据类型。
Python 内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中
的元素
语法以及定义方式:
a = [] : []------方括号表示集合;【】[]

len(classmates)-1: 表示列表当中最后一个元素的索引。
L[3] = L[len(classmates)-1]
超出列表索引会报错 eg: classmate[4]报错,超出索引
IndexError: list index out of range
添加元素方法:
append() : 在列表最后插入元素 (一个参数)
insert():在指定索引处,插入元素。(两个参数)
classmates = [‘张三’, ‘李四’, ‘王五’,‘小明’]
print(len(classmates))
classmates的长度是多少?
超出列表索引会报错
IndexError: list index out of range
如何将 '小红’加入当classmates这个列表当中
classmates.append(‘小红’)
append(): 向列表当中添加元素。列表当中的方法,用’.'点,调用。
append():添加的元素是在列表的最后。
#如何添加到列表的指定位置,eg:添加到第一个位置
classmates.append(0,‘小白’)
TypeError: append() takes exactly one argument (2 given)
#append(): 只能接受一个参数,我们给了它两个参数,所以会报错
classmates.insert(0,‘小白’)
insert():在指定索引处,插入元素。
删除元素:
#pop() :删除列表当中最后一个元素
#pop(index): 删除指定索引的元素
classmates = [‘张三’, ‘李四’, ‘王五’,‘小明’]
print(classmates)
#删除元素
classmates.pop()
print(classmates)
classmates.pop(1)
print(classmates)
列表内置方法:
pop() :删除列表当中最后一个元素
pop(index): 删除指定索引的元素
append(value) : 在列表最后插入元素 (一个参数)
insert(index,value):在指定索引处,插入元素。(两个参数)
列表插入删除练习:
fruit = [‘苹果’,’香蕉’,’橘子’]
1.添加 ‘西瓜’到fruit列表的最后,打印输出fruit
2.添加 ‘草莓’到苹果的后面,打印输出fruit
3.删除 fruit列表的最后一个元素,然后打印输出fruit
4.删除 fruit列表的第2个元素,然后打印输出fruit
5.打印输出 ‘橘子’
答案:
1.fruit.append(‘西瓜’)
2.fruit.insert(1,‘草莓’)
3.fruit.pop()
4.fruit.pop(2)
print(fruit[2])

列表:
list = [1,2,3,True,’小明’,None,3.124, [] ]
二维列表:

练习:
1.请用索引取出下面list的指定元素:
-- coding: utf-8 --
L = [
[‘Apple’, ‘Google’, ‘Microsoft’],
[‘Java’, ‘Python’, ‘Ruby’, ‘PHP’],
[‘Adam’, ‘Bart’, ‘Lisa’]
]
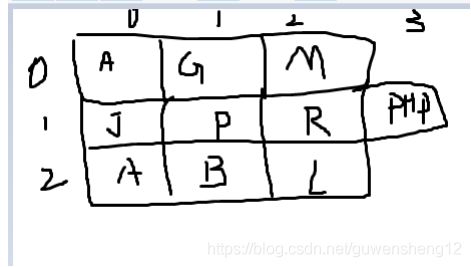
打印Apple:
print(?) L[0][0]
打印Python: L[1][1]
print(?)
PHP: L[1][3]
打印Lisa:
print(?)
20190409
知识点学习:
1.list复习, tuple学习
list列表: 一种数据类型,有序集合,可以任意添加删除元素。 []
tuple元组:也是一种数据类型,有序,不能添加或删除元素,即:tuple一但初始化就不能修改了。没有list 的添加删除方法(没有append(),insert(), pop()等方法)。 定义:L=() ,其他和list相同,eg:索引表示,计算tuple长度:len()。
classmates = (‘zhangsan’,’lisi’,’wangwu ’,’’sdf”)
money=(3000,4000,5000)
tuple的意义优点:tuple一但初始化就不能修改了,代码更安全。如果可能,能有tuple代替list就尽量用tuple。
list = [[]] : 二维列表。
tuple = ([1,2,3],[4,5,6],[7,8,9])
如果tuple里面有list,那么可以改变list的元素。
tuple = ([1, 2, 3], [4, 5, 6], [7, 8, 9])
print(tuple[0])
print(type(tuple[0]))
print(tuple[0].append(122))
print(tuple)
6 --------- tuple[1][2]
tuple 的缺陷:当你定义一个tuple时,在定义的时候,tuple 的元素就必须被确定下来。
eg:
t = (1,2)
t
(1,2)
1.定义一个空tuple: tuple = ()
2.定义只有一个元素的tuple: tuple = (1,)
2. 请问以下变量哪些是tuple类型:
√ a = ()
b = (1)
c = [2]
√ d = (3,)
√ e = (4,5,6)
2.条件判断语句
if…else
比如,输入用户年龄,根据年龄打印输出不同的类容
age = 20
if age >= 18:
print(‘你的年龄是 %s’ % age)
print(“成人”)
根据python的缩进规则,如果if语句判断是True,就把缩进的两行print语句执行了。
如果if语句判断是False, 就不执行。(否则什么都不做。)
也可以给if添加一个else语句,意思是,如果if判断为False,不要执行if 的内容,
去执行else 里面的内容。
age = 5
if age >= 18:
print(‘你的年龄是 %s’ % age)
print(“成人”)
else:
print(‘你的年龄是 %s’ % age)
print(“未成人”)
注意: 不要少写了冒号 :
可以用else if 缩写: elif
age = 16
if age>=18:
print(“adult”)
elif age >= 10:
print(“青少年”)
elif age >=6:
print(“青少年1”)
else:
print(“kid”)
elif 是 else if 的缩写,完全可以有多个elif。
语法
‘’’
if <条件判断1>:
<执行内容1>
elif <条件判断2>:
<执行内容2>
elif <条件判断3>:
<执行内容3>
else:
<执行内容n>
‘’’
说明: 从上往下判断,如果在某个判断上为True,那么把判断对应的语句执行后,
就忽略掉剩下的elif和else。
练习:
小明身高1.75m,体重80.5kg。请根据BMI公式(体重除以身高的平方)帮小明计算他的BMI指数,并根据BMI指数:
低于18.5:过轻
18.5-25:正常
25-28:过重
28-32:肥胖
高于32:严重肥胖
用if-elif判断并打印结果:
-- coding: utf-8 --
height = 1.75
weight = 80.5
bmi = ???
if ???:
print(“”)
答案:
weight = 80.5
height = 1.75
bmi = weight/(height*height)
if bmi<18.5:
print(“过轻”)
elif bmi<=25:
print(“正常”)
elif bmi<=28:
print(“过重”)
elif bmi<=32:
print(“肥胖”)
else:
print(“严重肥胖”)
改版: 用户自动输入,加格式化练习
name = input(“请输入名字:”)
weight = float(input(“请输入体重:”))
height = float(input(“请输入身高:”))
bmi = weight/(height*height)
if bmi<18.5:
print(name,“的bmi为:%.2f,为 %s” % (bmi,“过轻”))
elif bmi<=25:
print(name, “的bmi为:%.2f,为 %s” % (bmi, “正常”))
elif bmi<=28:
print(name, “的bmi为:%.2f,为 %s” % (bmi, “过重”))
elif bmi<=32:
print(name, “的bmi为:%.2f,为 %s” % (bmi, “肥胖”))
else:
print(name, “的bmi为:%s,为 %s” % (bmi, “严重肥胖”))
改版二: 加上list练习
分别计算 张三、小明和小红的 bmi
classmate = [[‘张三’, 67, 1.75],[‘小明’, 77, 1.80],[‘小红’, 88, 1.90]]
name = classmate[0][0]
weight = classmate[0][1]
height = classmate[0][2]
bmi = weight / (height * height)
if bmi < 18.5:
print(name, “的bmi为:%.2f,为 %s” % (bmi, “过轻”))
elif bmi <= 25:
print(name, “的bmi为:%.2f,为 %s” % (bmi, “正常”))
elif bmi <= 28:
print(name, “的bmi为:%.2f,为 %s” % (bmi, “过重”))
elif bmi <= 32:
print(name, “的bmi为:%.2f,为 %s” % (bmi, “肥胖”))
else:
print(name, “的bmi为:%s,为 %s” % (bmi, “严重肥胖”))
预习: python循环
20190416
1.循环
首先

如果list里面有100这样的元素怎么办??
list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99]
range(N)--------生成0-N个元素组成的列表。 [0,N) ,左闭右开
range(m,n) ------生成m-n个元素组成的列表
range(0,100,2) -----在[0-99)中,以step=2的间隔生成元素,组成列表。

python2版本才可以测试:

循环:Python 的循环有两种,一种是 for…in 循环,依次把 list 或 tuple 中的每个元素迭代出来
for循环语法:
for 迭代变量 in 对象(序列):
循环体
流程图:



循环去做:
计算 1-10的整数之和:
sum = 0
for i in range(0, 11):
sum += i
print(“sum=”, sum)
‘’’
解释:
sum = 0+1 -----> sum=1
sum = 1+2 ------> sum = 3
sum = 3+3 -----> sum =6
…
sum = sum+10 -----> sum=55
计算机当中: sum= sum+i
一般写成 sum+=i
‘’’
计算1-100的整数之和。
sum = 0
for i in range(1, 101):
sum += i
print(“sum=”, sum)
计算1-100的偶数之和。
sum = 0
for i in range(0, 101,2):
sum += i
print(“sum=”, sum)
计算1-100的奇数之和。
sum = 0
for i in range(1, 101,2):
sum += i
print(“sum=”, sum)
练习
请利用循环依次对list中的每个名字打印出Hello, xxx!:
L = [‘Bart’, ‘Lisa’, ‘Adam’]
for i in L:
print(‘Hello,’,i,"!")
while 循环:
语法:
while 条件表达式:
循环体
流程图:
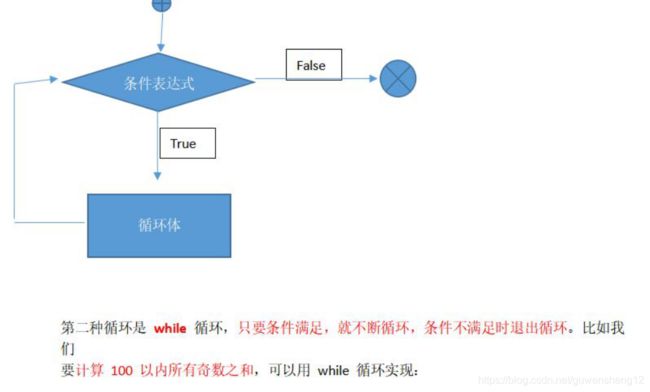
第二种循环是 while 循环,只要条件满足,就不断循环,条件不满足时退出循环。比如我们
要计算 100 以内所有奇数之和,可以用 while 循环实现:
计算 100 以内所有奇数之和

![]()
在循环内部变量 n 不断自减,直到变为-1 时,不再满足 while 条件,循环退出。
continue语句会立即跳到循环的顶端,即跳过本次循环,执行下一次循环
break 语句会立即离开循环
练习:
1.输入5个同学的name,weight,height.请根据BMI公式(体重除以身高的平方)分别求出他们的BMI指数,并根据BMI指数:
低于18.5:过轻
18.5-25:正常
25-28:过重
28-32:肥胖
高于32:严重肥胖
2.猜数字;
编写一个猜数字的小游戏,随机生成一个1-10(包括1和10)之间的数字作为基准数,玩家每次通过键盘输入一个数字,如果输入的数字和基准数相同,则成功过关,否则重新输入,如果玩家输入-1,则表示退出游戏。效果图如下:
提示:
import random # 导入随机数模块
random = random.randint(1, 10) # 生成1到10之间的随机数
3.打印输出(循环):
(1)
*
**
提示: \n ----表示换行 ‘ ’-----表示输出空格
(2)
*
**
20190423(2)
#!/usr/bin/env python
-- coding: utf-8 --
‘’’
@author:MT
@file: 0423.py
@time: 2019/4/23 8:54
‘’’
userName = [“1111”,“zhangsan”,“lisi”,“wangwu”,“xiaoming”]
for i in userName:
if “zhangsan” ==i: # i ==“zhangsan”
break;
print(i)
大家给我记住了: 缩进符号很重要,
‘’’
1.如果全篇(就是python代码)没有缩进“tab”,那说明没有for while if
else eilf 等条件(流程)控制语句和循环控制语句。
‘’’
print("-------猜数字游戏-------")
import random # 导入随机数模块
random = random.randint(1, 10) # 生成1到10之间的随机数
print(“random:”,random)
num = int(input(“请输入1-10之间的任意一个数:”))
while True:
num = int(input(“请输入1-10之间的任意一个数:”))
if num >random:
print(“大了,请重新输入:”)
elif num
print(“小了,请重新输入:”)
elif num == -1:
print(“游戏结束”)
break
else:
print(“猜对了”)
break
for i in range(5):
print(" “(5-i),"”*(i+1))
#定义好字典 {键:值,键:值}键:值,以逗号分隔
d = {“zhangsan”: 89, “lisi”: 90, “wangwu”: 78}
print(d)
print(d[“zhangsan”]) # 取字典里面的某个值
#改变字典当中的值
#方式一
d[“zhangsan”]=99
print(d[“zhangsan”])
#如果键不存在于字典当中会报错。
d[“xiaoming”]
KeyError: ‘xiaoming’
#判断键是否存在于字典当中
print("----:",d.get(“lisi1”))
#删除字典当中的wangwu元素
d.pop(“wangwu”)
print(d)
一行一行的输出字典当中的键值
print(d[“zhangsan”])
print(d[“zhangsan”])
print(d[“lisi”])
循环打印字典
d1 = {“zhangsan”: 89, “lisi”: 90, “wangwu”: 78}
for i in d1: # i 表示的是字典当中的键, d[i]—字典当中的值
print("—",i,d1[i])
总结,和list相比,dict的优缺点
‘’’
1.查找和插入的速度快,不会随着key的增加而增加
2.需要占用大量内存,内存浪费
‘’’
list 优缺点
‘’’
1.查找和插入的时间,随着元素的增加而增加
2.占用空间小,浪费内存小。
‘’’
#dict的注意事项
‘’’
字典当中的key是不可变对象,唯一,不能重复
通过key计算位置的算法(字典),我们称为: 哈希算法
‘’’
a = {1:“asd”,1:“qwe”}
print(a)
dic1 = {“zhangsan”:[180,87,98]}
#如何取87
l = dic1[“zhangsan”]
l[1]
print(dic1[“zhangsan”][1])
dic2 = {‘lisi’:{“爱好”:[1,2,3],“score”:98}}
#如何取3
a = dic2[‘lisi’][“爱好”][2]
print(a)
print(“小了,请重新输入:”)
elif num == -1:
print(“游戏结束”)
break
else:
print(“猜对了”)
break
for i in range(5):
print(" “(5-i),"”*(i+1))
#定义好字典 {键:值,键:值}键:值,以逗号分隔
d = {“zhangsan”: 89, “lisi”: 90, “wangwu”: 78}
print(d)
print(d[“zhangsan”]) # 取字典里面的某个值
#改变字典当中的值
#方式一
d[“zhangsan”]=99
print(d[“zhangsan”])
#如果键不存在于字典当中会报错。
d[“xiaoming”]
KeyError: ‘xiaoming’
#判断键是否存在于字典当中
print("----:",d.get(“lisi1”))
#删除字典当中的wangwu元素
d.pop(“wangwu”)
print(d)
一行一行的输出字典当中的键值
print(d[“zhangsan”])
print(d[“zhangsan”])
print(d[“lisi”])
循环打印字典
d1 = {“zhangsan”: 89, “lisi”: 90, “wangwu”: 78}
for i in d1: # i 表示的是字典当中的键, d[i]—字典当中的值
print("—",i,d1[i])
总结,和list相比,dict的优缺点
‘’’
1.查找和插入的速度快,不会随着key的增加而增加
2.需要占用大量内存,内存浪费
‘’’
list 优缺点
‘’’
1.查找和插入的时间,随着元素的增加而增加
2.占用空间小,浪费内存小。
‘’’
#dict的注意事项
‘’’
字典当中的key是不可变对象,唯一,不能重复
通过key计算位置的算法(字典),我们称为: 哈希算法
‘’’
a = {1:“asd”,1:“qwe”}
print(a)
dic1 = {“zhangsan”:[180,87,98]}
#如何取87
l = dic1[“zhangsan”]
l[1]
print(dic1[“zhangsan”][1])
dic2 = {‘lisi’:{“爱好”:[1,2,3],“score”:98}}
#如何取3
a = dic2[‘lisi’][“爱好”][2]
print(a)