机器学习(5)--数据集划分
sklearn数据集
1、数据集划分
2、sklearn数据集接口介绍
3、 sklearn分类数据集
4、 sklearn回归数据集
数据集划分
机器学习一般的数据集会划分为两个部分:
训练数据:用于训练,构建模型
测试数据:在模型检验时使用,用于评估模型是否有效【不同模型评估方式不同】

【常用比例是:75%:25%】
语法:
sklearn数据集划分API
sklearn.model_selection.train_test_split
sklearn.datasets
加载获取流行数据集
datasets.load_*()
获取小规模数据集,数据包含在datasets里
datasets.fetch_*(data_home=None)
获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
sklearn获取数据格式
load*和fetch*返回的数据类型datasets.base.Bunch(字典格式)
data:特征数据数组,是 [n_samples * n_features] 的二维
numpy.ndarray 数组
target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
DESCR:数据描述
feature_names:特征名【新闻数据,手写数字、回归数据集没有】
target_names:标签名【回归数据集没有】
sklearn分类数据集【例子】

from sklearn.datasets import load_iris, fetch_20newsgroups, load_boston
li = load_iris()
# print("获取特征值")
# print(li.data)
# print("目标值")
# print(li.target)
# print(li.DESCR)
输出结果:


数据描述:

数据集进行分割
sklearn.model_selection.train_test_split(*arrays, **options)
x 数据集的特征值
y 数据集的标签值
test_size 测试集的大小,一般为float
random_state 随机数种子,不同的种子会造成不同的随机
采样结果。相同的种子采样结果相同。
return 训练集特征值,测试集特征值,训练标签,测试标签
【默认乱序随机取】
from sklearn.datasets import load_iris, fetch_20newsgroups, load_boston
from sklearn.model_selection import train_test_split, GridSearchCV
# li = load_iris()
##注意返回值, 训练集 train x_train, y_train 测试集 test x_test, y_test
#x_train, x_test, y_train, y_test = train_test_split(li.data, li.target, test_size=0.25)
#
# print("训练集特征值和目标值:", x_train, y_train)
# print("测试集特征值和目标值:", x_test, y_test)
输出结果:

训练集的数量减少
用于分类的大数据集
sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
subset: 'train'或者'test','all',可选,选择要加载的数据集.
训练集的“训练”,测试集的“测试”,两者的“全部”【一般都选all,然后自己用上边方法划分】
datasets.clear_data_home(data_home=None)
清除目录下的数据
from sklearn.datasets import load_iris, fetch_20newsgroups, load_boston
from sklearn.model_selection import train_test_split, GridSearchCV
li = load_iris()
# news = fetch_20newsgroups(subset='all')
#
# print(news.data)
# print(news.target)
sklearn回归数据集【例子】

from sklearn.datasets import load_iris, fetch_20newsgroups, load_boston
from sklearn.model_selection import train_test_split, GridSearchCV
# lb = load_boston()
#
# print("获取特征值")
# print(lb.data)
# print("目标值")
# print(lb.target)
# print(lb.DESCR)
转换器和估计器
1. 转换器
想一下之前做的特征工程的步骤?
1、实例化 (实例化的是一个转换器类(Transformer))
2、调用fit_transform(对于文档建立分类词频矩阵,不能同时调用)
fit_transform() = fit() + transform()
fit() 以当前列表计算平均值和标准差(如果fit和transform用的数据不一样,按照fit用的数据计算的标准差和平均值转换transform的数据)



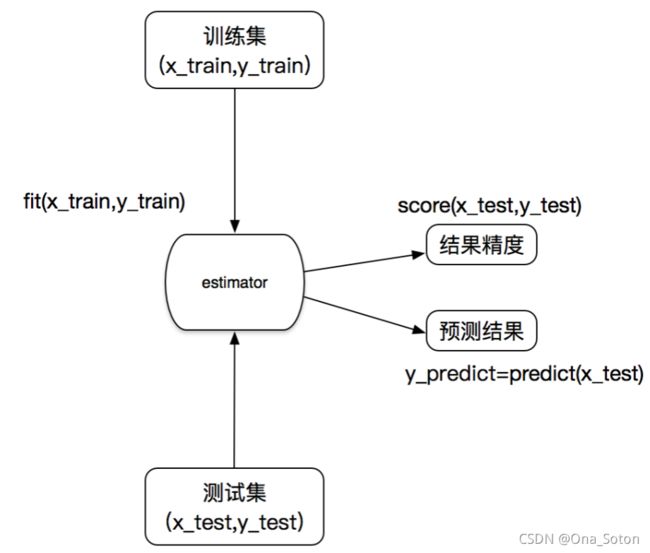
2. 估计器
在sklearn中,估计器(estimator)是一个重要的角色,分类器和回归器都属于estimator,是一类实现了算法的API
1)用于分类的估计器:
sklearn.neighbors k-近邻算法
sklearn.naive_bayes 贝叶斯
sklearn.linear_model.LogisticRegression 逻辑回归
2)用于回归的估计器:
sklearn.linear_model.LinearRegression 线性回归
sklearn.linear_model.Ridge 岭回归
【使用不难,关键在于每个算法API中的参数】
使用流程
1. 输入训练集数据
2. 预测,得到准确率【score默认自带的】