MMR: 控制推荐多样性算法
你有考虑过推荐系统的多样性层面是怎么设计的吗?
推荐系统中精排模块是对各个item进行精准预估,而在之后的重排阶段则会整体考虑推荐的N条内容间的关系,给出listwise粒度上最优的推荐序列。
多样性是重排阶段的一个排序策略,已经有文献指出多样性和准确性并非完全矛盾。因为,用户没有点击并不一定是 ctr 预估不准确,而是用户已经点击了类似的东西,这才导致了下一条内容没有点击。所以存在多样性与精确性同时提升的空间。
MMR(Maximal Marginal Relevance)是一种简单、易于实现的多样性控制算法,非常适合快速上线,作为baseline,探索多样性对系统整体的收益空间。
MMR
MMR全称为最大边缘相关模型,同时将相关性和多样性进行衡量。因此,可以方便的调节相关性和多样性的权重来满足偏向“需要相似的内容”或者偏向“需要不同方面的内容”的要求。
MMR公式如下:

其中R是输入的列表,Di是集合R的成员,S是当前返回的结果集。Sim1(Di,Q)代表query与文档之间的相关度,推荐中一般是精排的预估ctr值。Sim2(Di,Dj)代表文档与文档之间的相似度,用来控制最终结果的多样性。
参数 λ调节相关性(相关性=精确性)和多样性之间的偏重程度,一般是通过线上真实流量探索出最优参数设定。
MMR组成最终列表是一个贪心的过程,每次选一个当前最优的文档D加入最终列表S,但不能保证是整体最优。
公式中有两层循环,外层对除去已加入最终列表外的文档进行遍历,计算Sim1(Di,Q)的值;内层循环是在最终列表中找到与当前Di 文档相似度最大的值Sim2(Di,Dj),前面的负号代表希望Di 与现有最终列表文档中最相似的程度尽可能小。通过 λ 参数来调控是更侧重相关度还是更侧重与现有S中文档的差异度。
举个, 假设我们有一个包含5个文档di的数据库和一个查询q,设定的λ的值为0.5,文档间的相似度如下:

>>第一次迭代
目前我们的结果集S是空的。因此,方程的后半部分,即S内的最大成对相似度,将为零。第一次迭代时,MMR方程简化为:
MMR = arg max (Sim (di, q))d1与q相似度最大,因此我们取其加入到S中,现在S = {d1}
>>第二次迭代
由于S = {d1},求S中某元素到给定di的最大距离就是sim(d1,di)。
对于d2:
sim(d1, d2) = 0.11
sim (d2, q) = 0.90
因此,MMR = λ0.90 – (1-λ)0.11 = 0.395同样,d3、d4、d5的MMR值分别为0.135,-0.35和0.19。由于d2具有最大的MMR,我们将其添加到S中,此时S = {d1, d2}。
>>第三次迭代
这次S = {d1, d2}。我们应该找到max。对于方程的第二部分,为sim (di, d1)和sim (di, d2)。
对于d3:
max{sim (d1, d3), sim (d2, d3)} =
max {0.23, 0.29} = 0.29
sim (d3, q) = 0.50
MMR = 0.5*0.5 - 0.5*0.29 = 0.105同理,其他MMR的值计算为: d4: -0.35, d5: 0.06。
d3的MMR最大,因此S = {d1, d2, d3}。此时系统总体的两两相似度和为0.63:
sim (d1, d2) + sim(d1, d3) + sim (d2, d3) = 0.63如果我们完全没有多样性,即 λ=1,那么我们的S将是{d1, d2, d5},此时总两两相似度为0.87。
通过MMR,我们有效地使推荐结果中的项之间的差异度更大。还要注意,推荐结果的总相似度已经从 2.44 减少到 2.31。说明为了多样性,我们牺牲了一些准确性。
改进MMR
1. 内循环中的 max 改为 mean
实际使用中,每次往最终列表S中添加物品时是考虑添加的物品与已在S中物品的平均距离,这样可能会在全局性上保证更多样性化一些。
2. 自定义Sim2
物品间的相似度有很多衡量方法,可以不使用模型建模,而是从业务角度出发实现一套物品间相似度的规则。
例如,在58的跨域推荐分享中提到,58信息流里面处理的是异构item,很难通过一种固定的、简单的距离 ( 算法 ) 来衡量相似度,所以采用了自定义距离的策略。
综上,重排模块采用MMR 的设计如下,逐步从待排列表中选择一个加入已排序列,并更新平均距离。
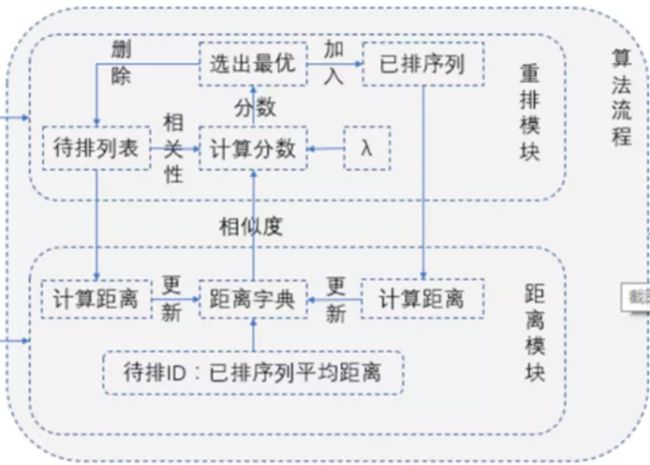
3. λ值
通过调节λ值,控制相关性的大小以及相关性和多样性的权衡。
理想的状态是,随着λ值的增大,多样性的提升,人均的浏览条数基本是在稳定地增加的,并且点击率会在λ为某值的时候达到最大值,随着之后多样性的增加,点击率会逐渐下降。
灵魂拷问
推荐系统发展到今日,单独优化某一个模块已经很难起到效果,需要从整个系统的角度出发,判断尚存的优化空间。比如重排,应该是在精排已经优化得非常准确之后才能发挥其作用。如果ctr 预估还不准确,根本就无法正确平衡多样性与精确性。
随着推荐系统愈发成熟,策略如果没有效果,是否要继续探索下去呢?怎么判断是策略本身不够复杂还是当前系统下根本不需要对应的优化点?
比如在重排阶段使用了MMR 这个算法,如果没有带来提升,那么是由于当前精排不够准确,还是说MMR 算法太简单,应该探索listwise 等包含更多信息的算法呢?接下来的解决思路,评论区交流下你的见解。