深度学习分析--TextCNN算法原理及分类实现
深度学习算法背景
人工智能发展历史
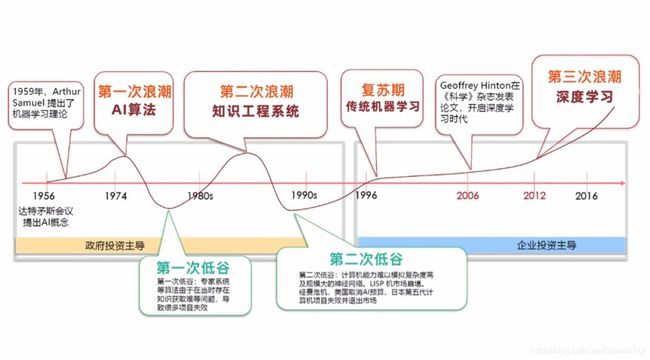
随着算力提高以及深度学习的应用,近几年算法发展很快
应用场景
- 计算机视觉 用于车牌识别和面部识别等的应用。
- 信息检索 用于诸如搜索引擎的应用 - 包括文本搜索和图像搜索。
- 市场营销 针对自动电子邮件营销和目标群体识别等的应用。
- 医疗诊断 诸如癌症识别和异常检测等的应用。
- 自然语言处理 如情绪分析和照片标记标题归类等的应用。
理论基础
梯度下降算法(gradient descent)
神经网络中,将样本中的输入X和输出Y当做已知值(对于一个样本[X,Y],其中X和Y分别是标准的输入值和输出值,X输入到模型中计算得到Y,但是模型中的参数值我们并不知道,所以我们的做法是随机初始化模型的参数,不断更新迭代这些参数,使得模型的输出与Y接近),将连接权和偏置值当做自变量,误差L(损失函数的值)作为因变量。梯度下降的目的是找到全部连接权和偏置值在取何值的情况下误差最小。
反向传播算法(BackPropagation)
反向传播是在神经网络中,利用结果反向求解权重参数的一个方法,其中用到了梯度下降求解极小值和函数求导的链式法则两个工具。正是BP算法思想的提出解决了深度学习中计算量过大的问题,加速深度学习发展。
神经网络模型来源
y= w1 x1 + w2 x2 + w1 x1 +…+ wn xn +b
可以根据公式大概理解:每一层就是相当于wn对变量影响,训练的过程就是得出参数wn的值,b就是偏差矫正
人脑的树突会接收各种信号,通过轴突各层的筛选选择性向下传递,最终输出单个抑制或兴奋的信号。

神经元都是一个多输入单输出的信息处理单元,由此简化建立M-P模型

建模参数对应神经元结构

对于某一个神经元j,它可能接受同时接受了许多个输入信号,用χi表示。
由于生物神经元具有不同的突触性质和突触强度,所以对神经元的影响不同,我们用权值ωij来表示,其大小则代表了突出的不同连接强度。
θj表示为一个阈值(threshold),或称为偏置(bias),超过阈值为兴奋,低于是抑制。
可以对应公式:y= w1 x1 + w2 x2 + w1 x1 +…+ wn xn +b
机器学习和深度学习关系与区别
关系
深度学习是一种特殊的机器学习,通过学习将世界使用嵌套的概念层次来表示并实现巨大的功能和灵活性,其中每个概念都定义为与简单概念相关联,而更为抽象的表示则以较不抽象的方式来计算。所以深度学习是机器学习的子类。
区别
深度学习对比常规的的机器学习来说,它需要训练的数据更多,而且参数可以自动调节,机器学习通常cpu也能训练,但是深度学习通常需要显卡训练。
机器学习算法包括:线性回归,也称为最小二乘回归(用于数值数据)、Logistic回归(用于二进制分类)、线性判别分析(用于多类别分类)、决策树(用于分类和回归)、朴素贝叶斯(用于分类和回归)、K最近邻居,又名KNN(用于分类和回归)、学习向量量化,又名LVQ(用于分类和回归)、支持向量机,又名SVM(用于二进制分类)、随机森林,一种“装袋”集成算法(用于分类和回归)、增强方法(包括AdaBoost和XGBoost)是集成算法,可创建一系列模型,其中每个新模型都试图纠正先前模型的错误(用于分类和回归)
深度学习算法:CNN(Convolutional Neural Networks,卷积神经网络)、GRU神经网络(Gated Recurrent Unit,门控循环单元神经网络)、LSTM(Long Short Memory Network,长短时记忆网络)、 RNN(Recurrent Neural Network,循环神经网络)等
TextCNN算法原理
若有兴趣可以看这篇文章:Understanding Convolutional Neural Networks for NLP
Yoon Kim于2014年发表论文Convolutional Neural Networks for Sentence Classification将CNN第一次引入NLP(自然语言处理)的应用,此前CNN几乎都是应用于图像识别领域。
CNN
CNN全称 Convolutional Neural Networks ,卷积神经网络,正如他的名字他的灵感来源是人的神经结构,最先由科学家杨立昆(Yann Lee Cun)提出,
何谓卷积,就是利用一种数学方法提取信息的特征。对于图片用矩阵可以很好描述像素点的分布特征,文字则需要一些映射方法
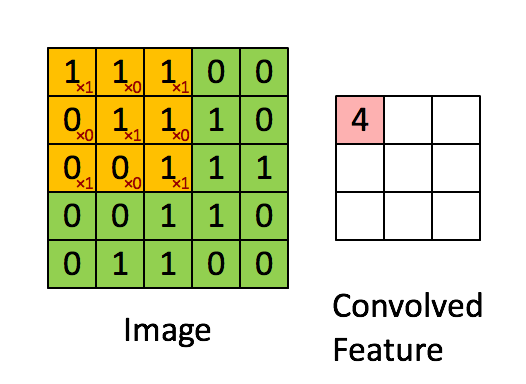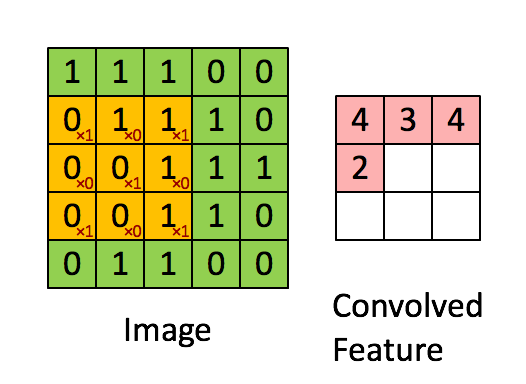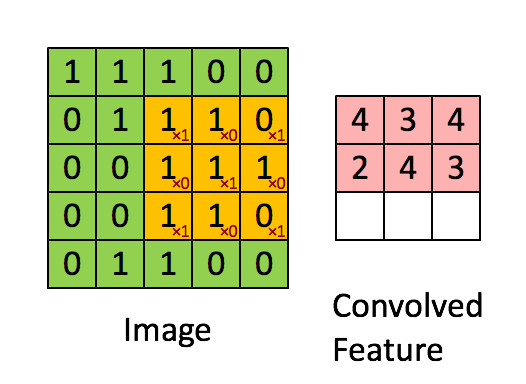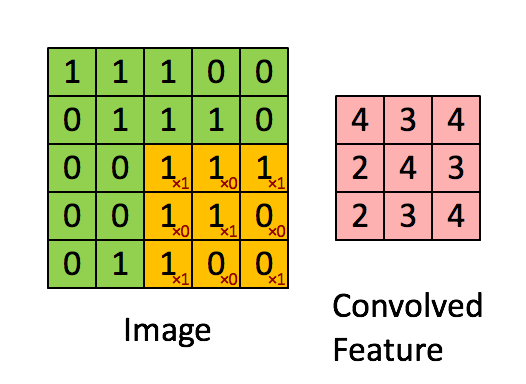
动图理解卷积运算的过程就是矩阵点乘的过程
TextCNN结构

嵌入层(embedding layer)
TextCNN使用预先训练好的词向量作embedding layer。对于数据集里的所有词,因为每个词都可以表征成一个向量,因此我们可以得到一个嵌入矩阵MM, MM里的每一行都是词向量。这个MM可以是静态(static)的,也就是固定不变。可以是非静态(non-static)的,也就是可以根据反向传播更新。
多种模型:Convolutional Neural Networks for Sentence Classification文章中给出了几种模型,其实这里基本都是针对Embedding layer做的变化。CNN-rand、CNN-static、CNN-non-static、CNN-multichannel
具体介绍及实验结果可见原论文,以上是学术定义
我个人理解:
文字无法被直接被计算机识别,需要编码,将其映射为2维的矩阵
卷积池化层(convolution and pooling)
卷积(convolution)
输入一个句子,首先对这个句子进行切词,假设有s个单词。对每个词,跟句嵌入矩阵M, 可以得到词向量。假设词向量一共有d维。那么对于这个句子,便可以得到s行d列的矩阵AϵRs×d.
我们可以把矩阵A看成是一幅图像,使用卷积神经网络去提取特征。由于句子中相邻的单词关联性总是很高的,因此可以使用一维卷积,即文本卷积与图像卷积的不同之处在于只在文本序列的一个方向(垂直)做卷积,卷积核的宽度固定为词向量的维度d。高度是超参数,可以设置。 对句子单词每个可能的窗口做卷积操作得到特征图(feature map) c = [c_1, c_2, …, c_s-h+1]。
对一个卷积核,可以得到特征cϵRs−h+1, 总共s−h+1个特征。我们可以使用更多高h不同的卷积核,得到更丰富的特征表达。
池化(pooling)
不同尺寸的卷积核得到的特征(feature map)大小也是不一样的,因此我们对每个feature map使用池化函数,使它们的维度相同。
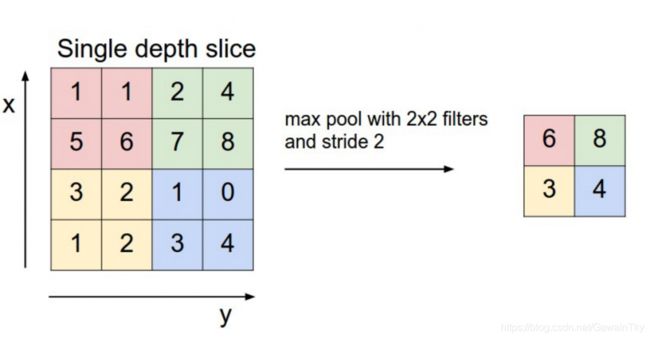
Max Pooling
最常用的就是1-max pooling,提取出feature map照片的最大值,通过选择每个feature map的最大值,可捕获其最重要的特征。这样每一个卷积核得到特征就是一个值,对所有卷积核使用1-max pooling,再级联起来,可以得到最终的特征向量。
Average Pooling
average pooling即取每个维度的均值而不是最大值。
其他池化方式K-Max Pooling、动态k-max pooling以及池化的的具体细节可见论文《Event Extraction via Dynamic Multi-Pooling Convolutional Neural Network》
简单模型结构的示例分析
分析《A Sensitivity Analysis …》模型示意图:

word embedding的维度是5,对于句子 i like this movie very much,转换成矩阵AϵR7×5;
有6个卷积核,尺寸为(2×5), (3×5), (4×5),每种尺寸各2个,A分别与以上卷积核进行卷积操作(这里的Stride Size相当于等于高度h);
再用激活函数激活,每个卷积核得到了特征向量(feature maps);
使用1-max pooling提取出每个feature map的最大值;
然后在级联得到最终的特征表达;
将特征输入至softmax layer进行分类, 在这层可以进行正则化操作( l2-regulariation)。
实验参数分析
TextCNN模型中,超参数主要有词向量,Region Size的大小,Feature Map的数量,激活函数的选择,Pooling的方法,正则化的影响。《A Sensitivity Analysis…》论文前面几章对实验内容和结果进行了详细介绍,在9个数据集上基于Kim Y的模型做了大量的调参实验,得出AUC进行比较,根据的实验对比:
1)初始化词向量:一般不直接使用One-hot。除了随机初始化Embedding layer的外,使用预训练的word2vec、 GloVe初始化的效果都更加好(具体哪个更好依赖于任务本身)。非静态的比静态的效果好一些。
2)卷积核的尺寸filter_sizes:影响较大,通常过滤器的大小范围在1-10之间,一般取为3-5。对不同尺寸ws的窗口进行结合会对结果产生影响。当把与最优ws相近的ws结合时会提升效果,但是如果将距离最优ws较远的ws相结合时会损害分类性能。刚开始,我们可以只用一个filter,调节Region Size来比对各自的效果,来看看哪种size有最好的表现,然后在这个范围在调节不同Region的匹配。
3)卷积核的数量num_filters(对每个巻积核尺寸来说):有较大的影响,一般取100~600(需要兼顾模型的训练效率) ,同时一般使用Dropout(0~0.5)。最好不要超过600,超过600可能会导致过拟合。可设为100-200。
4)激活函数:可以尽量多尝试激活函数,实验发现ReLU和tanh两种激活函数表现较佳。
5)池化选择:1-max pooling(1-max pooling的方式已经足够好)。
6)Dropout和正则化:Dropout rate / dropout_keep_prob:dropout一般设为0.5。随着feature map数量增加,性能减少时,可以考虑增大正则化的力度,如尝试大于0.5的Dropout。
7)batch_size: 批次大小是每一次训练神经网络送入模型的样本数,在卷积神经网络中,大批次通常可使网络更快收敛,但由于内存资源的限制,批次过大可能会导致内存不够用或程序内核崩溃。bath_size通常取值为[16,32,64,128]
8)学习率(learning rate或作lr): 是指在优化算法中更新网络权重的幅度大小。学习率可以是恒定的、逐渐降低的,基于动量的或者是自适应的。不同的优化算法决定不同的学习率。当学习率过大则可能导致模型不收敛,损失loss不断上下震荡;学习率过小则导致模型收敛速度偏慢,需要更长的时间训练。通常lr取值为[0.01,0.001,0.0001]
其它的训练参数:num_epochs:20(迭代次数);每checkpoint_every:100轮便保存模型;仅保存最近num_checkpoints:5次模型
实现文本分类的过程
Text Classification with CNN
使用卷积神经网络进行中文文本分类
软件环境
- Python 3.6.8
- TensorFlow 1.8.0
- numpy
- scikit-learn
- scipy
硬件环境
- CPU:Ryzen 2500U(2.0GHZ)
- Menmory: 16G
- 注:轻薄本不适合训练深度学习,该环境运行10+小时,同时内存需要16G,不然第二次迭代会爆内存
可以使用谷歌的colab,Tesla T4的显卡,训练速度大概4秒100条,但是只能免费使用12小时,数据量小也够用了
数据集
本训练集由predict_check_data表的17万条产品名称和对应分类组成。
预处理
data_prepare.py运行该程序,即可根据数据表,生成指定的训练,测试,验证集。
data/cnews_loader.py为数据的预处理文件。
read_file(): 读取文件数据;build_vocab(): 构建词汇表,使用字符级的表示,这一函数会将词汇表存储下来,避免每一次重复处理;read_vocab(): 读取上一步存储的词汇表,转换为{词:id}表示;read_category(): 将分类目录固定,转换为{类别: id}表示;to_words(): 将一条由id表示的数据重新转换为文字;process_file(): 将数据集从文字转换为固定长度的id序列表示;batch_iter(): 为神经网络的训练准备经过shuffle的批次的数据。
经过数据预处理,数据的格式如下:
| Data | Shape | Data | Shape |
|---|---|---|---|
| x_train | [50000, 600] | y_train | [50000, 10] |
| x_val | [5000, 600] | y_val | [5000, 10] |
| x_test | [10000, 600] | y_test | [10000, 10] |
CNN卷积神经网络
配置项
CNN可配置的参数如下所示,在cnn_model.py中。
class TCNNConfig(object):
"""CNN配置参数"""
embedding_dim = 128 # 词向量维度
seq_length = 300 # 序列长度
# num_classes = 668 # 类别数
num_filters = 1024 # 卷积核数目
kernel_size = 3 # 卷积核尺寸
vocab_size = 8000 # 词汇表大小
hidden_dim = 256 # 全连接层神经元
dropout_keep_prob = 0.55 # dropout保留比例
learning_rate = 1e-3 # 学习率
batch_size = 64 # 每批训练大小
num_epochs = 20 # 总迭代轮次
print_per_batch = 100 # 每多少轮输出一次结果
save_per_batch = 10 # 每多少轮存入tensorboard
CNN模型
class TextCNN(object):
"""文本分类,CNN模型"""
def __init__(self, config):
self.config = config
# 三个待输入的数据
self.input_x = tf.placeholder(tf.int32, [None, self.config.seq_length], name='input_x')
self.input_y = tf.placeholder(tf.float32, [None, self.config.num_classes], name='input_y')
self.keep_prob = tf.placeholder(tf.float32, name='keep_prob')
self.cnn()
def cnn(self):
"""CNN模型"""
# 词向量映射
with tf.device('/cpu:0'):
embedding = tf.get_variable('embedding', [self.config.vocab_size, self.config.embedding_dim])
embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x)
with tf.name_scope("cnn"):
# CNN layer 3*3
conv_1 = tf.layers.conv1d(embedding_inputs, self.config.num_filters, self.config.kernel_size, name='conv_1')
# global max pooling layer
gmp_1 = tf.reduce_max(conv_1, reduction_indices=[1], name='gmp_1')
with tf.name_scope("score"):
# 全连接层,后面接dropout以及relu激活
fc_1 = tf.layers.dense(gmp_1, self.config.hidden_dim, name='fc_1')
fc_1 = tf.contrib.layers.dropout(fc_1, self.keep_prob)
fc_1 = tf.nn.relu(fc_1)
# 分类器
self.logits = tf.layers.dense(fc_1, self.config.num_classes, name='fc_2')
self.y_pred_cls = tf.argmax(tf.nn.softmax(self.logits), 1) # 预测类别
with tf.name_scope("optimize"):
# 损失函数,交叉熵
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=self.input_y)
self.loss = tf.reduce_mean(cross_entropy)
# 优化器
self.optim = tf.train.AdamOptimizer(learning_rate=self.config.learning_rate).minimize(self.loss)
with tf.name_scope("accuracy"):
# 准确率
correct_pred = tf.equal(tf.argmax(self.input_y, 1), self.y_pred_cls)
self.acc = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
训练与验证
运行 python run_cnn.py train,可以开始训练。
若之前进行过训练,请把tensorboard/textcnn删除,避免TensorBoard多次训练结果重叠。
Configuring CNN model...
Configuring TensorBoard and Saver...
Loading training and validation data...
Time usage: 0:00:14
Training and evaluating...
Epoch: 1
Iter: 0, Train Loss: 8.9, Train Acc: 0.00%, Val Loss: 8.9, Val Acc: 0.00%, Time: 0:00:15
Iter: 100, Train Loss: 7.1, Train Acc: 3.12%, Val Loss: 7.3, Val Acc: 1.75%, Time: 0:00:22 *
Iter: 200, Train Loss: 6.7, Train Acc: 9.38%, Val Loss: 6.9, Val Acc: 7.68%, Time: 0:00:29 *
Iter: 300, Train Loss: 5.8, Train Acc: 20.31%, Val Loss: 6.4, Val Acc: 15.43%, Time: 0:00:35 *
Iter: 400, Train Loss: 5.8, Train Acc: 18.75%, Val Loss: 5.8, Val Acc: 23.33%, Time: 0:00:42 *
Iter: 500, Train Loss: 5.4, Train Acc: 29.69%, Val Loss: 5.3, Val Acc: 30.68%, Time: 0:00:49 *
Iter: 600, Train Loss: 4.1, Train Acc: 40.62%, Val Loss: 5.0, Val Acc: 37.10%, Time: 0:00:56 *
Iter: 700, Train Loss: 4.3, Train Acc: 40.62%, Val Loss: 4.7, Val Acc: 39.64%, Time: 0:01:03 *
Iter: 800, Train Loss: 4.1, Train Acc: 48.44%, Val Loss: 4.5, Val Acc: 43.47%, Time: 0:01:10 *
Iter: 900, Train Loss: 4.2, Train Acc: 37.50%, Val Loss: 4.3, Val Acc: 45.70%, Time: 0:01:17 *
Iter: 1000, Train Loss: 3.0, Train Acc: 56.25%, Val Loss: 4.1, Val Acc: 48.36%, Time: 0:01:23 *
Iter: 1100, Train Loss: 4.3, Train Acc: 50.00%, Val Loss: 4.0, Val Acc: 50.28%, Time: 0:01:30 *
Iter: 1200, Train Loss: 3.5, Train Acc: 53.12%, Val Loss: 3.9, Val Acc: 51.55%, Time: 0:01:37 *
Iter: 1300, Train Loss: 4.2, Train Acc: 50.00%, Val Loss: 3.8, Val Acc: 52.80%, Time: 0:01:44 *
Iter: 1400, Train Loss: 2.6, Train Acc: 59.38%, Val Loss: 3.6, Val Acc: 54.80%, Time: 0:01:51 *
Iter: 1500, Train Loss: 4.0, Train Acc: 51.56%, Val Loss: 3.5, Val Acc: 55.76%, Time: 0:01:58 *
Iter: 1600, Train Loss: 4.1, Train Acc: 46.88%, Val Loss: 3.5, Val Acc: 56.52%, Time: 0:02:05 *
Iter: 1700, Train Loss: 3.0, Train Acc: 59.38%, Val Loss: 3.4, Val Acc: 57.38%, Time: 0:02:12 *
Iter: 1800, Train Loss: 2.9, Train Acc: 60.94%, Val Loss: 3.3, Val Acc: 58.31%, Time: 0:02:19 *
Iter: 1900, Train Loss: 3.8, Train Acc: 50.00%, Val Loss: 3.2, Val Acc: 58.58%, Time: 0:02:26 *
Iter: 2000, Train Loss: 3.9, Train Acc: 54.69%, Val Loss: 3.2, Val Acc: 59.42%, Time: 0:02:33 *
.
.#训练迭代10次后
.
Epoch: 11
Iter: 20800, Train Loss: 0.013, Train Acc: 100.00%, Val Loss: 0.44, Val Acc: 92.10%, Time: 0:24:38 *
Iter: 20900, Train Loss: 0.012, Train Acc: 100.00%, Val Loss: 0.44, Val Acc: 92.15%, Time: 0:24:45 *
Iter: 21000, Train Loss: 0.025, Train Acc: 98.44%, Val Loss: 0.47, Val Acc: 91.75%, Time: 0:24:51
Iter: 21100, Train Loss: 0.026, Train Acc: 100.00%, Val Loss: 0.43, Val Acc: 92.22%, Time: 0:24:58 *
Iter: 21200, Train Loss: 0.094, Train Acc: 98.44%, Val Loss: 0.46, Val Acc: 91.80%, Time: 0:25:05
Iter: 21300, Train Loss: 0.17, Train Acc: 98.44%, Val Loss: 0.45, Val Acc: 92.25%, Time: 0:25:12 *
Iter: 21400, Train Loss: 0.094, Train Acc: 96.88%, Val Loss: 0.46, Val Acc: 92.18%, Time: 0:25:18
Iter: 21500, Train Loss: 0.029, Train Acc: 98.44%, Val Loss: 0.45, Val Acc: 91.92%, Time: 0:25:25
Iter: 21600, Train Loss: 0.11, Train Acc: 98.44%, Val Loss: 0.44, Val Acc: 92.10%, Time: 0:25:31
Iter: 21700, Train Loss: 0.099, Train Acc: 98.44%, Val Loss: 0.46, Val Acc: 91.93%, Time: 0:25:38
Iter: 21800, Train Loss: 0.069, Train Acc: 98.44%, Val Loss: 0.46, Val Acc: 91.68%, Time: 0:25:45
Iter: 21900, Train Loss: 0.097, Train Acc: 96.88%, Val Loss: 0.46, Val Acc: 91.90%, Time: 0:25:51
Iter: 22000, Train Loss: 0.024, Train Acc: 98.44%, Val Loss: 0.45, Val Acc: 92.13%, Time: 0:25:58
Iter: 22100, Train Loss: 0.01, Train Acc: 100.00%, Val Loss: 0.43, Val Acc: 92.14%, Time: 0:26:05
Iter: 22200, Train Loss: 0.11, Train Acc: 98.44%, Val Loss: 0.43, Val Acc: 92.25%, Time: 0:26:11
Iter: 22300, Train Loss: 0.011, Train Acc: 100.00%, Val Loss: 0.43, Val Acc: 92.21%, Time: 0:26:18
No optimization for a long time, auto-stopping...
在验证集上的最佳效果为92.25%.
测试
运行 python run_cnn.py test 在测试集上进行测试。
Configuring CNN model...
Loading test data...
Testing...
Test Loss: 0.46, Test Acc: 91.85%
在测试集上的准确率达到了91.85%。
预测
运行 python run_cnn.py predict 在预测集上进行预测。
预测集命名为name2category.predict.txt,放入data中的name2category文件夹,每行一个产品名称。
输出在目录文件夹,名称为predicted_data.txt
功能调用
调用方法为:
from run_cnn import name2subcategory
name_list = ['乔思伯 JONSBO CR-201RGB版本RGBCPU散热器(黑色/多平台/4热管/温控/12CM风扇/支持AURARGB/附硅脂)']
a = name2subcategory()
category = a.namelyst_predict(name_list)
输入一个含有多个产品名称的列表,返回一个各名称子类的列表。
总结
