Spring Boot 集成 ElasticSearch,实现高性能搜索
1、ElasticSearch介绍
Elasticsearch 是java开发的,基于 Lucene 的搜索引擎。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful Web接口。Elasticsearch 可以快速有效地存储,搜索和分析大量数据,而且在处理半结构化数据(即自然语言)时特别有用。
应用集成Elasticsearch有4种方式:
- REST Client
- Jest
- Spring Data
- Spring Data Elasticsearch Repositories
本文主要介绍一下用Spring Data Elasticsearch Repositories 是如何使用的。该方式与spring boot高度集成,日常开发时较方便,只需要简单的配置即可开箱使用。
2、运行 Elasticsearch
为了便于测试,我们使用 Docker 镜像方式快速部署一个单节点的 Elasticsearch实例,容器启动时并绑定宿主机的9200和9300端口
拉取镜像:
docker pull elasticsearch:7.4.2
查看镜像:
docker images
创建宿主机挂载目录:
mkdir -p /mydata/elasticsearch/config/
mkdir -p /mydata/elasticsearch/data/
echo "http.host: 0.0.0.0">>/mydata/elasticsearch/config/elasticsearch.yml
运行容器:
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e ES_JAVA_OPS="-Xms256m -Xmx256m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
参数说明:
-p 9200:9200 将容器的9200端口映射到主机的9200端口;
--name elasticsearch 给当前启动的容器取名叫 elasticsearch
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data 将数据文件夹挂载到主机; -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml 将配置文件挂载到主机;
-d 以后台方式运行(daemon)
-e ES_JAVA_OPS="-Xms256m -Xmx256m" 测试时限定内存小一点
查看容器进程:
docker ps -a
3、项目集成
按照Spring Boot的惯例,我们不必在上下文中提供任何bean来启用对Elasticsearch的支持。我们只需要在pom.xml中添加以下依赖项:
org.springframework.boot
spring-boot-starter-data-jpa
org.springframework.boot
spring-boot-starter-data-elasticsearch
由于spring-boot-starter-parent指定的版本号是2.2.1.RELEASE,所以上面引入的两个starter组件会被强制一样的版本号,便于统一化管理。而底层引入的 spring-data-elasticsearch 是3.2.1.RELEASE
在配置文件 application.yml 中配置 ES 的相关参数,应用程序尝试在localhost上与Elasticsearch连接,具体内容如下:
spring:
application:
name: spring-boot-bulking-elasticsearch
elasticsearch:
rest:
uris: 127.0.0.1:9200
read-timeout: 5s
Spring Boot 操作 ES 数据有三种方式:
- 实现 ElasticsearchRepository 接口
- 引入 ElasticsearchRestTemplate
- 引入 ElasticsearchOperations
使用Spring Data Elasticsearch Repositories操作 Elasticsearch,定义实体类,并设置对应的索引名
@Document(indexName = "order", type = "biz1", shards = 2)
public class OrderModel {
@Id
private Long orderId;
private Double amount;
private Long buyerUid;
private String shippingAddress;
}
常用注解说明:
@Document:表示映射到Elasticsearch文档上的领域对象
@Id:表示是文档的id,文档可以认为是mysql中表行的概念
@Filed:文档中字段的类型、是否建立倒排索引、是否进行存储
OrderModel表示订单的索引模型,一个OrderModel对象表示一条ES索引记录。如果用关系数据库做参照,Index相当于表,Document相当于记录
然后,需要自己定义一个业务接口 OrderRepository,并继承扩展接口 ElasticsearchRepository
public interface OrderRepository extends ElasticsearchRepository {
} ElasticsearchRepository 是 Spring boot Elasticsearch 框架预留的扩展接口,内部的类依赖关系如下图所示:
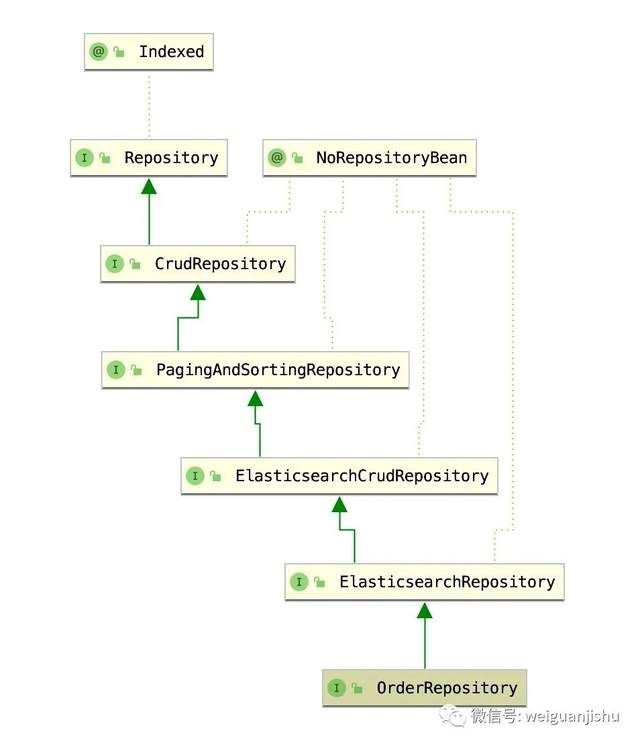
ElasticsearchRepository 接口内提供常用的操作ES的方法,如:新增、修改、删除、各种维度条件查询及分页等,详细方法内容如下:
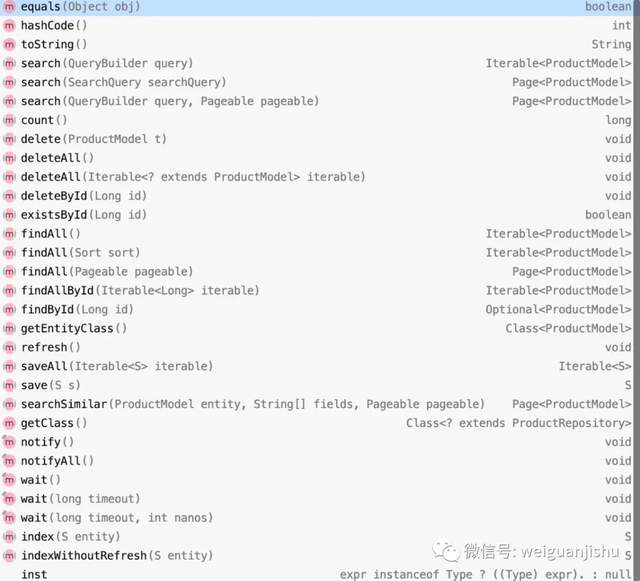
save() 方法是创建索引,如果索引document已经存在,后面的 save 方法则是对之前的数据覆盖。也就是说新增和修改都可以通过 save 方法 实现。
最后,通过编写单元测试类来验证方法功能
@Test
public void test1() {
OrderModel orderModel = OrderModel.builder()
.orderId(1L)
.amount(25.5)
.buyerUid(13201L)
.shippingAddress("上海")
.build();
orderModel = orderRepository.save(orderModel);
System.out.println(orderModel);
}
@Test
public void test2() {
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
NativeSearchQueryBuilder searchQueryBuilder = new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder);
List orderDocumentList = orderRepository.search(searchQueryBuilder.build()).getContent();
System.out.println(JSON.toJSONString(orderDocumentList));
}
使用这个OrderRepository 来操作 ES 中的 OrderModel 数据。我们这里并没有手动创建OrderModel 对应的索引,由 elasticsearch 默认生成。
学习更多java知识关注私信博主免费获取
4、kibana 可视化控制台
安装 kibana,比较简单,这里就不在累述了。先下载kibana安装包,再解压
# bin目录下,执行启动脚本
./kibana
可以看到刚才执行单元测试,创建的索引记录。
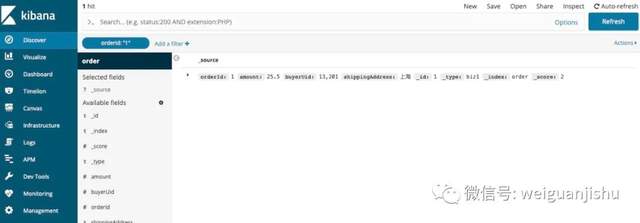
结尾:
我们热衷于收集高并发、系统架构、微服务、消息中间件、 RPC框架、高性能缓存、搜索、分布式数据框架、分布式协同服务、分布式配置中心、中台架构、领域驱动设计、系统监控、系统稳定性等技术知识,有需要的关注+私信博主免费获取
