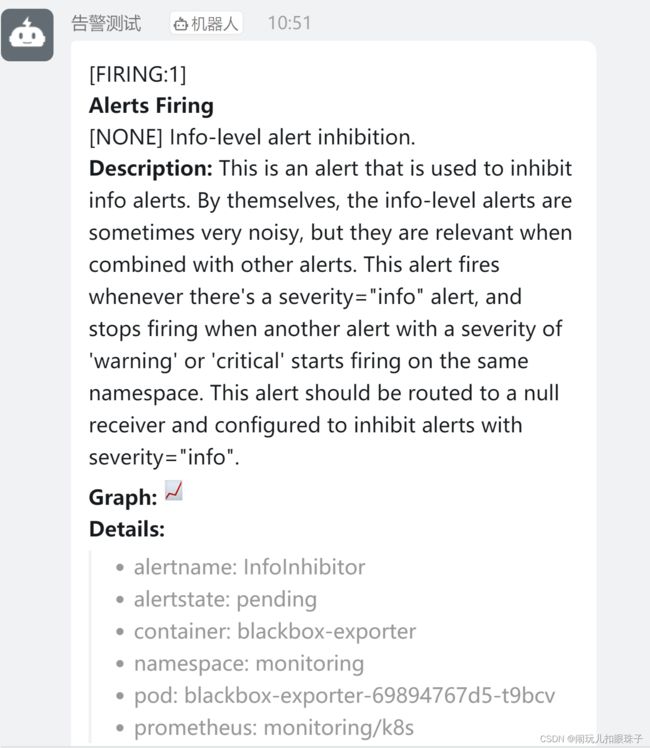
k8s prometheus-operator+grafana+alertmanager+钉钉告警
1、描述
1.1 简介
Prometheus是一个开源系统监控和警报工具包,最初在 SoundCloud构建。自 2012 年成立以来,许多公司和组织都采用了 Prometheus,该项目拥有非常活跃的开发者和用户社区。它现在是一个独立的开源项目,独立于任何公司维护。为了强调这一点,并明确项目的治理结构,Prometheus 于 2016 年加入 云原生计算基金会,成为继Kubernetes之后的第二个托管项目。
Prometheus 将其指标收集并存储为时间序列数据,即指标信息与记录时的时间戳以及称为标签的可选键值对一起存储。
有关 Prometheus 的更详细概述,请参阅 媒体部分链接的资源。
1.2 特征
Prometheus 相比于其他传统监控工具主要有以下几个特点:
- 具有由 metric 名称和键/值对标识的时间序列数据的多维数据模型
- 有一个灵活的查询语言
- 不依赖分布式存储,只和本地磁盘有关
- 通过 HTTP 的服务拉取时间序列数据
- 也支持推送的方式来添加时间序列数据
- 还支持通过服务发现或静态配置发现目标
- 多种图形和仪表板支持
1.3 组件
Prometheus 由多个组件组成,但是其中许多组件是可选的:
- Prometheus Server:用于抓取指标、存储时间序列数据
- exporter:暴露指标让任务来抓
- pushgateway:push 的方式将指标数据推送到该网关
- alertmanager:处理报警的报警组件
- adhoc:用于数据查询
大多数 Prometheus 组件都是用 Go 编写的,因此很容易构建和部署为静态的二进制文件。
1.4 架构
下图是 Prometheus 官方提供的架构及其一些相关的生态系统组件:
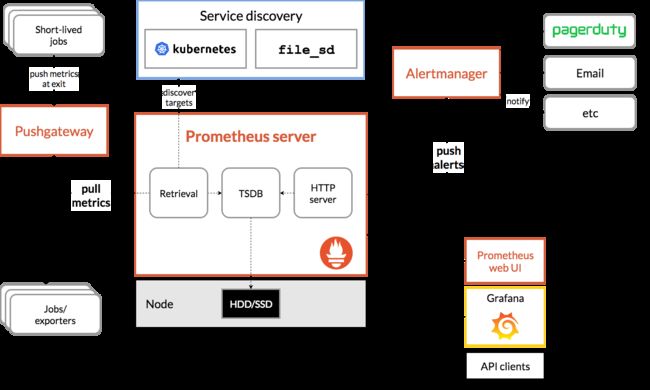
整体流程比较简单,Prometheus 直接接收或者通过中间的 Pushgateway 网关被动获取指标数据,在本地存储所有的获取的指标数据,并对这些数据进行一些规则整理,用来生成一些聚合数据或者报警信息,Grafana 或者其他工具用来可视化这些数据。
---------------------------------------------以上均来自官网介绍------------------------------------------------------
2 监控和告警机制
2.1 监控方案
硬件指标:
通过prometheus-node-exporter采集主机的性能指标数据,并通过暴露的 /metrics 接口用prometheus抓取
daemonset方式部署到每个node
集群组件指标:
通过kube-apiserver、kube-controller-manager、kube-scheduler、etcd、kubelet、kube-proxy自身暴露的 /metrics 获取节点上与k8s集群相关的一些指标数据容器指标:
通过cadvisor采集容器、Pod相关的性能指标数据(容器),并通过暴露的 /metrics 接口用prometheus抓取
通过annotation暴露自身的metrics暴露/metrics
cAdvisor内置在 kubelet 组件之中,数据路径为/api/v1/nodes//proxy/metrics
使用node的服务发现模式,每个节点都有 kubelet,自然都有cAdvisor采集到的数据指标网络指标:
通过blackbox-exporter采集应用的网络性能(http、tcp、icmp等)数据,并通过暴露的 /metrics 接口用prometheus抓取
应用可以在service中指定约定的annotation,实现Prometheus对该应用的网络服务进行探测资源对象指标:
通过kube-state-metrics采集k8s资源对象的状态指标数据,并通过暴露的 /metrics 接口用prometheus抓取
2.2 展示方案
grafana连接prometheus数据库,通过模版视图展示,模版可以自定义,也可以去在线模版仓库获取
2.3 告警方案
prometheus将告警信息推送给alertmanager,然后alertmanager通过邮件,短信、webhook等方式告警,本次我们介绍通过webhook方式推送钉钉告警,webhook也可以推动微信告警,本次略
3 安装
因本次主要介绍钉钉告警,所以不使用手动安装方式,直接使用operator方式快速安装
3.1 安装必要条件
克隆代码
[root@k8s-master ~]# git clone https://github.com/coreos/kube-prometheus.git
正克隆到 'kube-prometheus'...
remote: Enumerating objects: 15481, done.
remote: Counting objects: 100% (167/167), done.
remote: Compressing objects: 100% (108/108), done.
remote: Total 15481 (delta 98), reused 80 (delta 48), pack-reused 15314
接收对象中: 100% (15481/15481), 7.82 MiB | 2.31 MiB/s, 完成.
处理 delta 中: 100% (9860/9860), 完成.
[root@k8s-master ~]#
安装prometheus-operator前提条件,部署CRD
[root@k8s-master ~]# cd kube-prometheus/manifests/
[root@k8s-master manifests]# ls
。。。 。。。
[root@k8s-master manifests]# kubectl apply -f setup/
customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com created
namespace/monitoring created
如果有一个yaml在apply的时候提示too lang就换成create创建,问题如下
[root@k8s-master manifests]# kubectl apply -f setup/0prometheusCustomResourceDefinition.yaml
The CustomResourceDefinition "prometheuses.monitoring.coreos.com" is invalid: metadata.annotations: Too long: must have at most 262144 bytes
[root@k8s-master manifests]# kubectl create -f setup/0prometheusCustomResourceDefinition.yaml
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com created
因为实验环境方便对外访问,我们还需要修改几个地方的暴露方式为nodeport
[root@k8s-master manifests]# vim grafana-service.yaml
spec:
ports:
- name: http
port: 3000
targetPort: http
type: NodePort
[root@k8s-master manifests]# vim prometheus-service.yaml
spec:
ports:
- name: web
port: 9090
targetPort: web
- name: reloader-web
port: 8080
targetPort: reloader-web
type: NodePort
selector:
[root@k8s-master manifests]# vim alertmanager-service.yaml
spec:
ports:
- name: web
port: 9093
targetPort: web
- name: reloader-web
port: 8080
targetPort: reloader-web
type: NodePort
3.2 安装prometheus
[root@k8s-master manifests]# kubectl apply -f .
alertmanager.monitoring.coreos.com/main created
poddisruptionbudget.policy/alertmanager-main created
prometheusrule.monitoring.coreos.com/alertmanager-main-rules created
secret/alertmanager-main created
service/alertmanager-main created
serviceaccount/alertmanager-main created
servicemonitor.monitoring.coreos.com/alertmanager-main created
clusterrole.rbac.authorization.k8s.io/blackbox-exporter created
clusterrolebinding.rbac.authorization.k8s.io/blackbox-exporter created
configmap/blackbox-exporter-configuration created
deployment.apps/blackbox-exporter created
service/blackbox-exporter created
serviceaccount/blackbox-exporter created
servicemonitor.monitoring.coreos.com/blackbox-exporter created
secret/grafana-config created
secret/grafana-datasources created
configmap/grafana-dashboard-alertmanager-overview created
configmap/grafana-dashboard-apiserver created
configmap/grafana-dashboard-cluster-total created
configmap/grafana-dashboard-controller-manager created
configmap/grafana-dashboard-grafana-overview created
configmap/grafana-dashboard-k8s-resources-cluster created
configmap/grafana-dashboard-k8s-resources-namespace created
configmap/grafana-dashboard-k8s-resources-node created
configmap/grafana-dashboard-k8s-resources-pod created
configmap/grafana-dashboard-k8s-resources-workload created
configmap/grafana-dashboard-k8s-resources-workloads-namespace created
configmap/grafana-dashboard-kubelet created
configmap/grafana-dashboard-namespace-by-pod created
configmap/grafana-dashboard-namespace-by-workload created
configmap/grafana-dashboard-node-cluster-rsrc-use created
configmap/grafana-dashboard-node-rsrc-use created
configmap/grafana-dashboard-nodes created
configmap/grafana-dashboard-persistentvolumesusage created
configmap/grafana-dashboard-pod-total created
configmap/grafana-dashboard-prometheus-remote-write created
configmap/grafana-dashboard-prometheus created
configmap/grafana-dashboard-proxy created
configmap/grafana-dashboard-scheduler created
configmap/grafana-dashboard-workload-total created
configmap/grafana-dashboards created
deployment.apps/grafana created
prometheusrule.monitoring.coreos.com/grafana-rules created
service/grafana created
serviceaccount/grafana created
servicemonitor.monitoring.coreos.com/grafana created
prometheusrule.monitoring.coreos.com/kube-prometheus-rules created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
deployment.apps/kube-state-metrics created
prometheusrule.monitoring.coreos.com/kube-state-metrics-rules created
service/kube-state-metrics created
serviceaccount/kube-state-metrics created
servicemonitor.monitoring.coreos.com/kube-state-metrics created
prometheusrule.monitoring.coreos.com/kubernetes-monitoring-rules created
servicemonitor.monitoring.coreos.com/kube-apiserver created
servicemonitor.monitoring.coreos.com/coredns created
servicemonitor.monitoring.coreos.com/kube-controller-manager created
servicemonitor.monitoring.coreos.com/kube-scheduler created
servicemonitor.monitoring.coreos.com/kubelet created
clusterrole.rbac.authorization.k8s.io/node-exporter created
clusterrolebinding.rbac.authorization.k8s.io/node-exporter created
daemonset.apps/node-exporter created
prometheusrule.monitoring.coreos.com/node-exporter-rules created
service/node-exporter created
serviceaccount/node-exporter created
servicemonitor.monitoring.coreos.com/node-exporter created
clusterrole.rbac.authorization.k8s.io/prometheus-k8s created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-k8s created
poddisruptionbudget.policy/prometheus-k8s created
prometheusrule.monitoring.coreos.com/prometheus-k8s-prometheus-rules created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s-config created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s-config created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
service/prometheus-k8s created
serviceaccount/prometheus-k8s created
servicemonitor.monitoring.coreos.com/prometheus-k8s created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
clusterrole.rbac.authorization.k8s.io/prometheus-adapter created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-adapter created
clusterrolebinding.rbac.authorization.k8s.io/resource-metrics:system:auth-delegator created
clusterrole.rbac.authorization.k8s.io/resource-metrics-server-resources created
configmap/adapter-config created
deployment.apps/prometheus-adapter created
poddisruptionbudget.policy/prometheus-adapter created
rolebinding.rbac.authorization.k8s.io/resource-metrics-auth-reader created
service/prometheus-adapter created
serviceaccount/prometheus-adapter created
servicemonitor.monitoring.coreos.com/prometheus-adapter created
clusterrole.rbac.authorization.k8s.io/prometheus-operator created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created
deployment.apps/prometheus-operator created
prometheusrule.monitoring.coreos.com/prometheus-operator-rules created
service/prometheus-operator created
serviceaccount/prometheus-operator created
servicemonitor.monitoring.coreos.com/prometheus-operator created
[root@k8s-master manifests]#
有几个pod创建失败了,因为镜像拉不下来,需要修改其他镜像地址
[root@k8s-master manifests]# kubectl get pod -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 5m2s
alertmanager-main-1 2/2 Running 0 5m2s
alertmanager-main-2 2/2 Running 0 5m2s
blackbox-exporter-69894767d5-t9bcv 3/3 Running 0 5m34s
grafana-7b77d779f6-x5khg 1/1 Running 0 5m33s
kube-state-metrics-c655879df-m5k9z 2/3 ImagePullBackOff 0 5m33s
node-exporter-2pfbx 2/2 Running 0 5m33s
node-exporter-m4htq 2/2 Running 0 5m33s
node-exporter-m5lvn 2/2 Running 0 5m33s
node-exporter-v2cn4 2/2 Running 0 5m33s
prometheus-adapter-6cf5d8bfcf-bgn4n 0/1 ImagePullBackOff 0 5m32s
prometheus-adapter-6cf5d8bfcf-qv8pn 0/1 ImagePullBackOff 0 5m32s
prometheus-k8s-0 2/2 Running 0 39s
prometheus-k8s-1 2/2 Running 0 39s
prometheus-operator-545bcb5949-k2dl5 2/2 Running 0 5m32s
vim kubeStateMetrics-deployment.yaml
镜像换成 bitnami/kube-state-metrics:2.3.0
vim prometheusAdapter-deployment.yaml
镜像换成image: selina5288/prometheus-adapter:v0.9.1
[root@k8s-master manifests]# kubectl apply -f prometheusAdapter-deployment.yaml -f kubeStateMetrics-deployment.yaml
deployment.apps/prometheus-adapter configured
deployment.apps/kube-state-metrics configured
[root@k8s-master manifests]# kubectl get pod -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 18m
alertmanager-main-1 2/2 Running 0 18m
alertmanager-main-2 2/2 Running 0 18m
blackbox-exporter-69894767d5-t9bcv 3/3 Running 0 18m
grafana-7b77d779f6-x5khg 1/1 Running 0 18m
kube-state-metrics-9f5b9468f-qzztn 3/3 Running 0 45s
node-exporter-2pfbx 2/2 Running 0 18m
node-exporter-m4htq 2/2 Running 0 18m
node-exporter-m5lvn 2/2 Running 0 18m
node-exporter-v2cn4 2/2 Running 0 18m
prometheus-adapter-7fc8b8c559-t5qvw 1/1 Running 0 6m54s
prometheus-adapter-7fc8b8c559-vhp56 1/1 Running 0 6m54s
prometheus-k8s-0 2/2 Running 0 13m
prometheus-k8s-1 2/2 Running 0 13m
prometheus-operator-545bcb5949-k2dl5 2/2 Running 0 18m
已经创建成功
3.3 访问页面
下面开始访问页面
[root@k8s-master manifests]# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main NodePort 10.109.63.172 9093:31169/TCP,8080:30473/TCP 20m
alertmanager-operated ClusterIP None 9093/TCP,9094/TCP,9094/UDP 19m
blackbox-exporter ClusterIP 10.110.214.160 9115/TCP,19115/TCP 20m
grafana NodePort 10.101.37.121 3000:32697/TCP 20m
kube-state-metrics ClusterIP None 8443/TCP,9443/TCP 20m
node-exporter ClusterIP None 9100/TCP 20m
prometheus-adapter ClusterIP 10.109.181.16 443/TCP 20m
prometheus-k8s NodePort 10.110.143.173 9090:30136/TCP,8080:32610/TCP 20m
prometheus-operated ClusterIP None 9090/TCP 15m
prometheus-operator ClusterIP None 8443/TCP 20m
[root@k8s-master manifests]#
根据上面查询svc的nodeport可以得出地址(192.168.3.50是我的nodeIP)
prometheus :192.168.3.50:30136/
grafana: 192.168.3.50:32697/
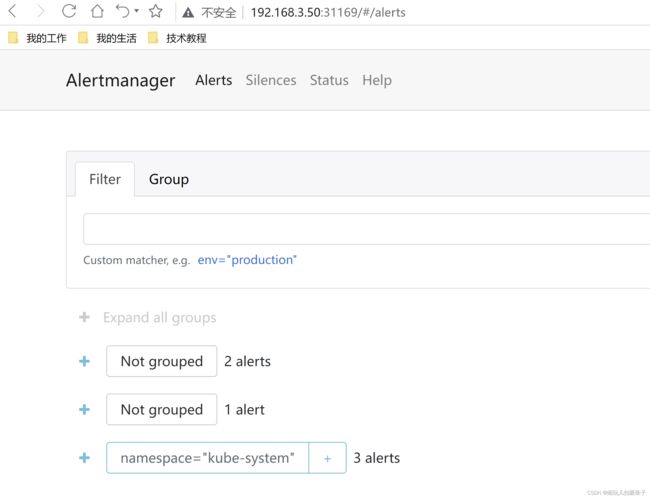
alertmanager: 192.168.3.50:31169/
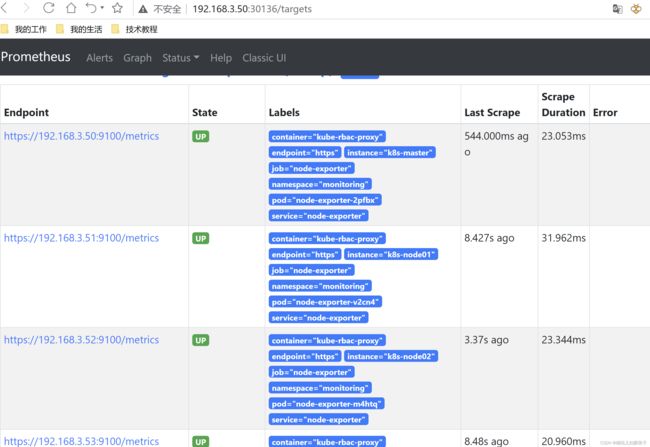
访问prometheus
访问正常,targets中也都是up,node-exporter,kube-state-metrics、blackbox-exporter、集群等都正常
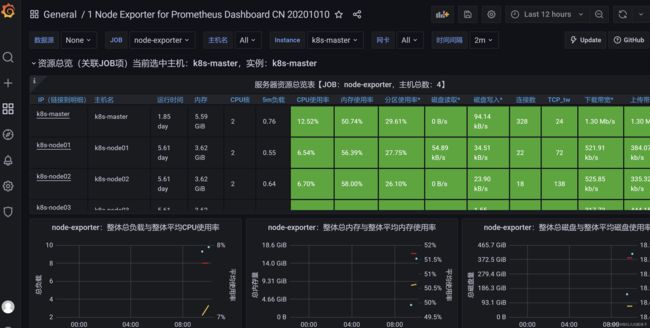
访问grafana
默认密码都是admin,会提示修改密码
创建data sources,其实默认已经有了prometheus的数据源

导入模版,可以到官网搜索模版,
官网地址:Dashboards | Grafana Labs
联网的话直接填写ID即可,好用的模版比如8685、8919、10000等等

访问alertmanager
4 钉钉告警
4.1 创建钉钉机器人
创建钉钉群聊,点击群设置--> 智能群助手-->添加机器人-->webhook方式


此处需要一个安全设置,我这里选择IP,IP是调用钉钉机器人的公网IP,不知道你自己IP的可以百度查询一下,关键字就写IP,第一个结果就是你的公网IP

生成的webhook地址记得保存下来,后面有用
4.2 创建钉钉推送服务
[root@k8s-master manifests]# cat dingtalk-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: dingtalk-config
namespace: monitoring
data:
config.yml: |-
targets:
webhook:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxx #设置成刚才的webhook地址
mention:
all: true
[root@k8s-master manifests]# cat dingtalk-deployment.yaml
apiVersion: v1
kind: Service
metadata:
name: dingtalk
namespace: monitoring
labels:
app: dingtalk
annotations:
prometheus.io/scrape: 'false'
spec:
selector:
app: dingtalk
ports:
- name: dingtalk
port: 8060
protocol: TCP
targetPort: 8060
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: dingtalk
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: dingtalk
template:
metadata:
name: dingtalk
labels:
app: dingtalk
spec:
containers:
- name: dingtalk
image: timonwong/prometheus-webhook-dingtalk:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8060
volumeMounts:
- name: config
mountPath: /etc/prometheus-webhook-dingtalk
volumes:
- name: config
configMap:
name: dingtalk-config
[root@k8s-master manifests]#
[root@k8s-master manifests]# kubectl apply -f dingtalk-config.yaml -f dingtalk-deployment.yaml
configmap/dingtalk-config created
service/dingtalk created
deployment.apps/dingtalk created
[root@k8s-master manifests]# kubectl get pod -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 73m
alertmanager-main-1 2/2 Running 0 73m
alertmanager-main-2 2/2 Running 0 73m
blackbox-exporter-69894767d5-t9bcv 3/3 Running 0 73m
dingtalk-77d475cc8-gdqf4 1/1 Running 0 16s
grafana-7b77d779f6-x5khg 1/1 Running 0 73m
kube-state-metrics-9f5b9468f-qzztn 3/3 Running 0 56m
node-exporter-2pfbx 2/2 Running 0 73m
node-exporter-m4htq 2/2 Running 0 73m
node-exporter-m5lvn 2/2 Running 0 73m
node-exporter-v2cn4 2/2 Running 0 73m
prometheus-adapter-7fc8b8c559-t5qvw 1/1 Running 0 62m
prometheus-adapter-7fc8b8c559-vhp56 1/1 Running 0 62m
prometheus-k8s-0 2/2 Running 0 69m
prometheus-k8s-1 2/2 Running 0 69m
prometheus-operator-545bcb5949-k2dl5 2/2 Running 0 73m
4.3 修改alertmanager告警访问为webhook
alertmanager的配置文件是alertmanager.yaml,需要被做成configmaps挂载进去,prometheus-operator是做成了secert,其实是一样的功效,下面我们修改secert
将alertmanager-secert.yaml中stringData里的alertmanager.yaml内容修改成如下内容,原有的可删掉
[root@k8s-master manifests]# cat alertmanager-secret.yaml
apiVersion: v1
kind: Secret
metadata:
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.23.0
name: alertmanager-main
namespace: monitoring
stringData:
alertmanager.yaml: |-
"global":
"resolve_timeout": "5m"
"receivers":
- "name": "Webhook"
"webhook_configs":
- "url": "http://dingtalk.monitoring.svc.cluster.local:8060/dingtalk/webhook/send"
"route":
"group_by":
- "namespace"
"group_wait": "30s"
"receiver": "Webhook"
"repeat_interval": "12h"
"routes":
- "matchers":
- "alertname = Webhook"
"receiver": "Webhook"
type: Opaque
[root@k8s-master manifests]# kubectl apply -f alertmanager-secret.yaml
secret/alertmanager-main configured
我们可以通过查看alertmanager的status页面的底部,发现配置已经修改,如果长时间还未生效可以尝试重启一下alertmanager-main的pod

4.4 测试告警
随便搞乱点什么