0x00000008 目标检测(Object detection with Bounding Box)常用指标AP和mAP及其计算方法源码阅读(pycocotools)
文章目录
- 1. 背景和讨论范围约束
- 2. 从分类任务指标到目标检测指标
- 3. VOC 比赛中AP指标计算
-
- VOC07(11点插值:N-Point Interpolation , N = 11)
- VOC10(全点插值,all-point interpolation):
- 4. COCO 中源码目标检测指标计算
-
- 指标简介
- 源码阅读
- References:
1. 背景和讨论范围约束
目标检测任务是计算机视觉中的基础任务。一般情况下,目标检测任务是要求将图片中的目标通过矩形框形式检测出来,即通过一组检测框坐标(这里一般使用矩形对角顶点(xmin,ymin,xmax,ymax),或者是通过中心点加框长高(xc, yc, w, h)来表示)和对应类别信息(cls_id)。
Fig1. 目标检测任务结果可视化。图片来源于[2],其中绿色为真实标签,红色为检测标签。

一般来说,对于检测器(Detector)而言。输出结果还需要加上每一个框的置信度(confidence)。这种设计往往是允许将结果进行排序,以便对FP,FN样本进行权衡估计,将检测器调试到最佳性能。
这里不讨论一些特殊的检测问题以及其扩展问题(如:文字检测:OCR,旋转目标检测:Rotated Object Detection,视频目标检测 :Video Object Detection 等)。这里将目标检测输出框结果设定为矩形框,以便简单分析。
为了行文简单,以下默认读者了解常用分类模型评价指标的计算方法和相关概念。如:混淆矩阵(confusion matrix),准确度(Accuracy),精确度(Precision),召回率(Recall),F1-score(measure),PR曲线,ROC曲线。单标签多分类(multi-class)问题,多标签(multi-label)多分类问题。以下不加以具体介绍。
2. 从分类任务指标到目标检测指标
AP 指标可以看做是P-R曲线的AUC(Area under the Curve)的近似求解指标。其本身为一个多标签分类任务的评价指标。
P.S: 以下内容为个人对评价指标一些学习思考小总结:
1. 分类任务:大部分使用指标为Acc topk(这是由于最基本的分类任务为二分类和单标签多分类)。
2. 由于该指标受到验证集或者测试集数据类不平衡(class imbalance)性影响大,很多时候会考虑Precision,Recall,F-score(F-measure)指标(或者PR曲线的AUC指标),或者ROC曲线的AUC指标(下面简写为AUC ROC指标)。
3. Precision ,Recall ,F-score 和 AUC ROC指标不同在于:
1)前者聚焦于正例,后者考虑整体性能(正例和负例)。
2)测试集数据不平衡场景下,前者能够更好体现模型效果。
3)对于测试数据集固定,选择模型场景下,更优使用前者指标。
4)对于多批次测试数据,每组测试数据类别分布不同。如果只想评价模型好坏,推荐后者。
4. 但是对于多标签分类,如果使用Precision指标会经常导致:虽然漏检,但是Precison依旧很高的情况。
一个例子:
————————————————
如一张图片有4个人和2个车子,但实际上检测出1个人和1个车(假设都正确),还有将1个人检测为了车。
对于人:P = 100%, R = 25% , F1 = 40%,
对于车:P = 50%, R = 50% , F1 = 50%。
————————————————————————————————
从直观上将,这里F1,P指标有一种“偏高“的误感。这是由于多分类问题,输出结果不会有遗漏(必定有一个结果),然而多标签分类不仅仅要考虑检测是否正确(Precision),还要考虑是否有遗漏(Recall)。
如果分开考虑简单求解F1,往往会导致以上结果。所以该任务指标需要将P,R结果同时考虑,计算PR曲线下面积更好符合这一目标。
如何使用一个分类问题评价指标来评价一个检测问题。简单来说只需要将目标框评价设计就可以了,这里通常使用IOU的方式进行评价。由于篇幅不再赘述。
Fig2. IOU计算。图片来源于[2],其中绿色为真实标签,红色为检测标签。
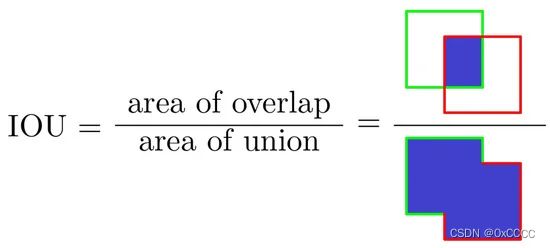
考虑到叙述简单,这里首先对单类检测问题进行讨论,多类别检测同理讨论即可:
假设检测出一系列框,输出为框坐标,置信度(B, C)。下面对这个结果进行评价:
通过与真实值IOU 阈值将输出框可以分为两类,一类为预测正确的(TP),一类为预测错误的(FP)。然后对于真实值框,没有预测出来的集合为(FN)。这里就可以计算该情况下P和R值。
进一步的,通过调节置信度分数阈值来控制输出框数量,从而得到P-R曲线(例如Fig 3)。
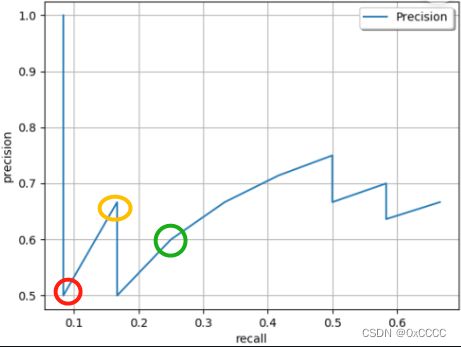
Fig3. 一个真实场景下的PR曲线绘制(这里设置IOU threshold = 0.75)。图片来源于[2]
其中数据为[2]中提供的,如下:
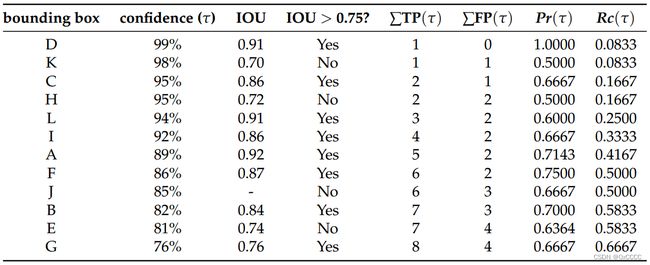
可以发现一些简单的规律
- 曲线从左到右。随着confidence threshold变小,P为下降趋势,R为上升趋势。
- 最左边点一定为confidence threshold = 100%情况, 最右边点认定为confidence threshold = 0情况。
下面简单讨论一些特殊点:(建议将P,R计算公式进行对照)
a. 第一次下降(Fig3 红色圈):阈值降低到有FP样本添加(但无法判断有多少个)。
b. 第一次上升(Fig3 黄色圈):阈值降低到有一个TP样本添加。
c. 第二次下降(Fig3 绿色圈):阈值降低到有TP样本添加,后续折线表明有TP样本持续添加。
由于阈值减低,只会导致TP和FP样本添加(预测为正的样例),而FN样本不会。从而曲线表现如上形状。
3. VOC 比赛中AP指标计算
一般来说有如下几种计算算法:
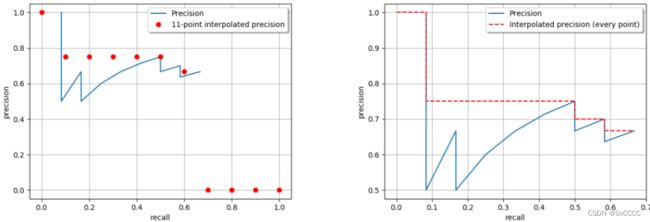
VOC07(11点插值:N-Point Interpolation , N = 11)
主要是测量了点 L=[0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] 中的召回率,图示如4(左):公式为。
AP 11 = 1 11 ∑ R ∈ { 0 , 0.1 , ⋅ , 0.9 , 1 } . P in t e r p ( R ) , \begin{equation*} \text{AP}_{11}=\frac{1}{11}\sum_{R\in\{0,0.1,\cdot,0.9,1\}}.P_{\text{in}\mathrm{t}\mathrm{e}\mathrm{r}\mathrm{p}}(R), \end{equation*} AP11=111R∈{0,0.1,⋅,0.9,1}∑.Pinterp(R),
其中:
P i n t e r p ( R ) = max R ‾ : R ‾ ≥ R P ( R ~ ) . \begin{equation*} P_{\mathrm{i}\mathrm{n}\mathrm{t}\mathrm{e}\mathrm{r}\mathrm{p}}(R) = \max_{\overline{R}:\overline{R}\geq R}P(\tilde{R}). \end{equation*} Pinterp(R)=R:R≥RmaxP(R~).
VOC10(全点插值,all-point interpolation):
针对全部的点(可以理解为每次阈值调节后,添加的正样例),使用如下插值算法:
AP a 11 = ∑ n ( R n + 1 − R n ) P in t e r p ( R n + 1 ) , \begin{equation*} \text{AP}_{\mathrm{a}11}=\sum_{n}(R_{n+1}-R_{n}) P_{\text{in}\mathrm{t}\mathrm{e}\mathrm{r}\mathrm{p}}(R_{n+1}),\end{equation*} APa11=n∑(Rn+1−Rn)Pinterp(Rn+1),
其中:
P in t e r p ( R n + 1 ) = max R ~ : R ~ ≥ R n + 1 P ( R ~ ) . \begin{equation*} P_{\text{in}\mathrm{t}\mathrm{e}\mathrm{r}\mathrm{p}}(R_{n+1}) = \max_{\tilde{R}:\tilde{R}\geq R_{n+1}}P(\tilde{R}).\end{equation*} Pinterp(Rn+1)=R~:R~≥Rn+1maxP(R~).
Fig4. VOC AP计算(这里设置IOU threshold = 0.75)。图片来源于[2]
最后,mAP计算比较简单,直接将所有类型AP求平均即可。注意的是,VOC所使用的IOU threshold = 0.5。
4. COCO 中源码目标检测指标计算
指标简介
在COCO比赛中,为了更加全面的评价,设计了如下指标
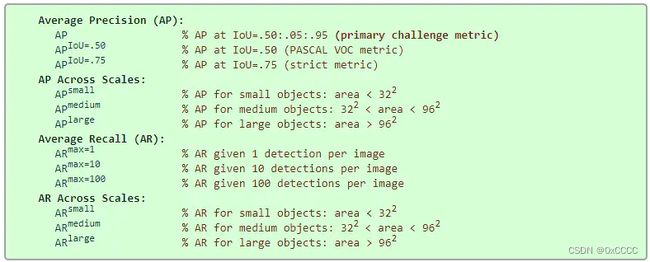
其中除了AP,还有AR(即在预测结果中占真实标签比率,计算方式简单这里不多赘述),并且对不同范围目标进行分类评价(samll ,medium ,large)。
其中AP与VOC不同的是,该方法是设置N = 101召回点进行插值计算。
并且通过阅读源码发现,这101个点的Precision值不是与该值大于等于Recall的所有Precision最大的那一个,而是寻找第一个改变的Precision,图示如下(绿色圆圈标注的为所采用的Precision的值)
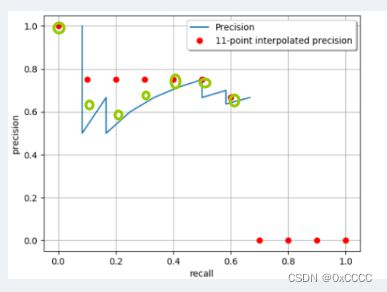
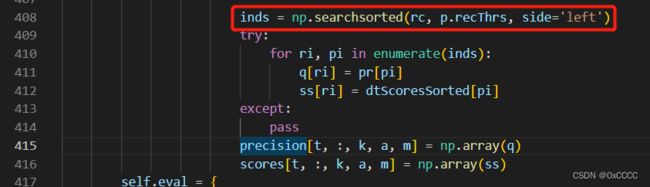
P.S, 如果阅读源码,这一个插值实现的关键语句在COCOeval的accumulate(该函数功能是将每一张图检测结果汇总,计算每一个类,每一个阈值,每一个面积范围下recall,precision等结果)中的下面这句话:
源码阅读
由于VOC metric代码原始为matlab,在很多目标检测论文开源项目中可以找到,如Faster RCNN官方代码。这里不做细致解读。
对于coco源代码,针对目标检测部分进行简单阅读。
这里推荐和pycocoDemo.ipynb,pycocoEvalDemo.ipynb文件配合使用阅读更容易理解,下面根据这两个文件改写成测试代码,使用pdb等调试工具进行调试:
Tips:
如果操作系统是Windows ,请使用这个版本的cocoapi进行测试:
https://github.com/philferriere/cocoapi
如果操作系统是Linux,使用这个版本cocoapi进行测试:
https://github.com/cocodataset/cocoapi/tree/master/PythonAPI
# 注意使用这个文件需要放在pycocotools同级目录
# 首先阅读setup.py,对整个包进行编译处理后才能正常使用
# 注意results/ 文件夹下有instances_val2014_fakebbox100_results.json文件
# 可能需要修改的地方:class Params中 setDetParams函数 np.linspace 传入的num参数需要使用int.不然会报错(在我测试的版本中)
import os, sys, zipfile
import urllib.request
import shutil
import numpy as np
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
### Step1. 下载val.json 数据测试文件
print("-" * 20 + "Download test data file" + "-" * 20)
dataType = 'val2014'
dataDir = './'
annDir = '{}/annotations'.format(dataDir)
annZipFile = '{}/annotations_train{}.zip'.format(dataDir, dataType)
annFile = '{}/instances_{}.json'.format(annDir, dataType)
annURL = 'http://images.cocodataset.org/annotations/annotations_train{}.zip'.format(dataType)
print(annFile, annZipFile, annURL)
if not os.path.exists(annDir):
os.makedirs(annDir)
if not os.path.exists(annFile):
if not os.path.exists(annZipFile):
print("Downloading zipped annotations to " + annZipFile + " ...")
with urllib.request.urlopen(annURL) as resp, open(annZipFile, 'wb') as out:
shutil.copyfileobj(resp, out)
print("... done downloading.")
print("Unzipping " + annZipFile)
with zipfile.ZipFile(annZipFile, "r") as zip_ref:
zip_ref.extractall(dataDir)
print("... done unzipping")
print("Will use annotations in " + annFile)
### Step2. 使用coco计算检测指标
print("-" * 20 + "Compute the metric" + "-" * 20)
annType = 'bbox'
prefix = 'instances'
print('Running demo for *%s* results.' % (annType))
#initialize COCO ground truth api
dataDir = './'
dataType = 'val2014'
annFile = '%s/annotations/%s_%s.json' % (dataDir, prefix, dataType)
cocoGt = COCO(annFile)
#initialize COCO detections api
resFile = '%s/results/%s_%s_fake%s100_results.json'
resFile = resFile % (dataDir, prefix, dataType, annType)
cocoDt = cocoGt.loadRes(resFile)
imgIds = sorted(cocoGt.getImgIds())
imgIds = imgIds[0:100]
imgId = imgIds[np.random.randint(100)]
cocoEval = COCOeval(cocoGt, cocoDt, annType)
cocoEval.params.imgIds = imgIds
cocoEval.evaluate()
cocoEval.accumulate()
cocoEval.summarize()
输出结果如下:
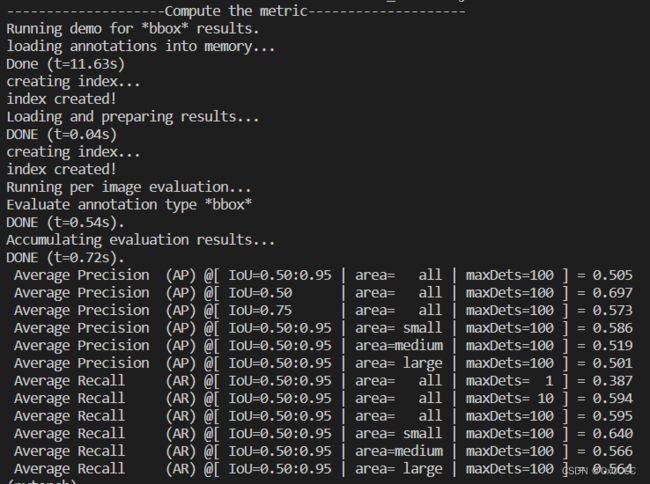
通过等调试工具运行上述代码,调试来理解清楚代码结构:
这里只展示本人阅读源码和调试中理解的该项目关键部分(源码比较复杂,写完估计文章太长了,而且里面有写代码使用了CPython加速,如计算iou阈值时候,考虑篇幅不多赘述)。
即构建的类和关键成员函数及其功能(下图使用百度脑图绘制:http://minder.yoqi.me/, 导出的原图和.xmind工程项目访问here (免费使用,转载等请注明来源)):
-
关键的3个类
-
COCO类信息
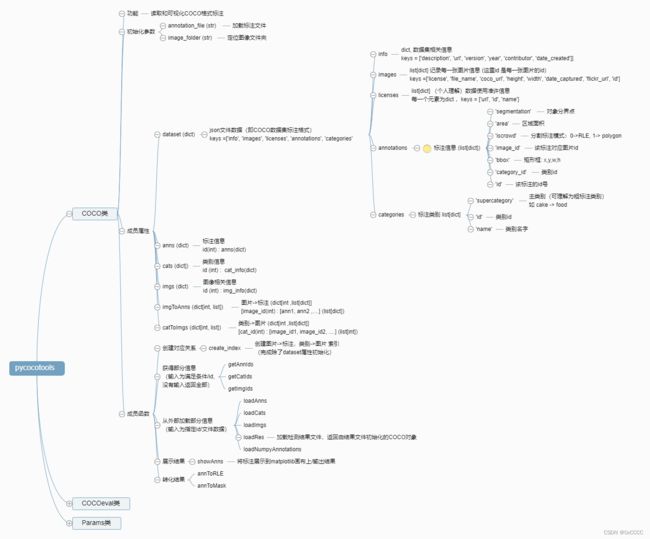
-
Params类信息

-
COCOeval类信息

-
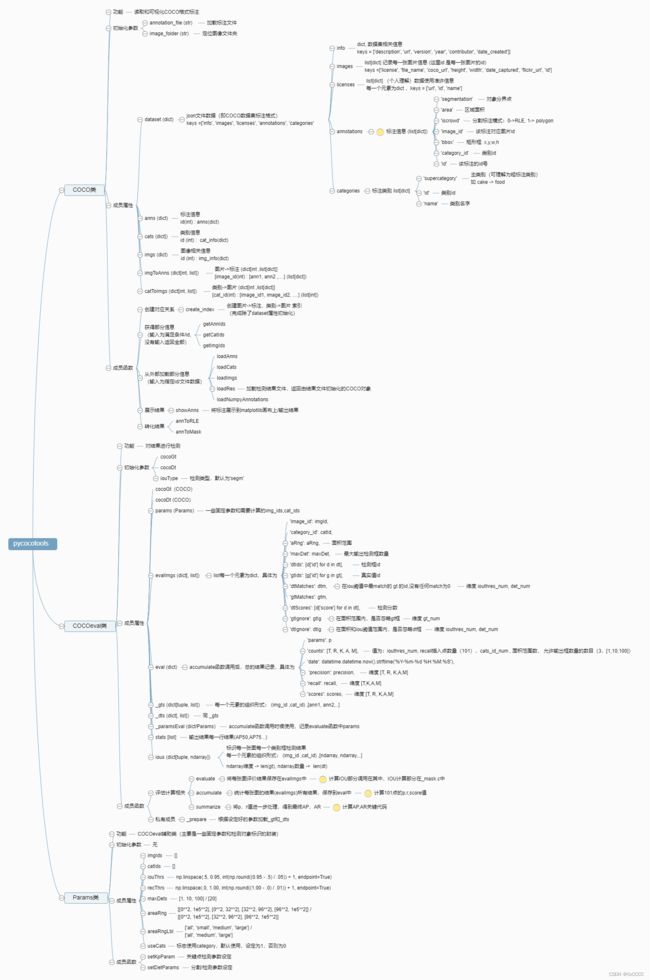
整张导图(太密,推荐下载矢量图here)
References:
- Padilla, Rafael et al. “A Survey on Performance Metrics for Object-Detection Algorithms.” 2020 International Conference on Systems, Signals and Image Processing (IWSSIP) (2020): 237-242.
- Padilla, Rafael et al. “A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit.” Electronics (2021): n. pag.
- COCO 比赛Metric 所参考源码地址:https://github.com/cocodataset/cocoapi/tree/master/PythonAPI/pycocotools
- 相关代码和工具:https://github.com/rafaelpadilla/review_object_detection_metrics
https://github.com/rafaelpadilla/Object-Detection-Metrics