《机器学习革命》A machine-learning revolution

作者 | Marric Stephens
编译 | CDA数据科学研究院
上世纪中叶奠定了机器学习的基础。但是,正如Marric Stephens所发现的那样,功能日益强大的计算机(采用了过去十年改进的算法)正在推动从医学物理到材料的各种应用的爆炸式增长。
当您的银行打电话来询问在奇怪的时候用您的信用卡进行的一笔可疑的大笔交易时,好心的职员不太可能亲自梳理您的帐户。取而代之的是,一台机器很可能已经学会了与犯罪活动相关的某种行为,并且在您的陈述中发现了意想不到的东西。银行的计算机一直在无声高效地使用算法来监视您的帐户中是否存在盗窃迹象。
以这种方式监视信用卡是“机器学习”的一个示例,即在给定的一组示例中接受训练的计算机系统通过该过程来灵活,自主地执行任务的过程。作为更广泛的人工智能(AI)领域的子集,机器学习技术可以应用在可以挖掘大量复杂数据集以用于输入和输出之间关联的任何地方。对于您的银行,该算法将分析大量合法和非法交易,以根据给定输入(“凌晨3点的高价订单”)产生输出(“可疑欺诈”)。
但是机器学习不仅仅用于金融领域。从医疗保健和交通运输到刑事司法系统,它也被广泛应用于其他领域。王刚(George Wang)是美国伦斯勒理工学院(Rensselaer Polytechnic Institute)的生物医学工程师,他是医学成像技术的先驱者之一。他相信,在机器学习方面,我们正处于革命的风口浪尖。
内幕故事
Wang的研究涉及从对人类患者的扫描(输入)中获取不完整的数据,并“重建”真实的图像(输出)。图像重建本质上是机器学习算法更普遍的应用的反面,机器学习算法通过训练计算机来发现和分类现有图像。例如,您的智能手机可能会使用这些算法来识别您的笔迹,而自动驾驶汽车会使用它们来识别车辆和道路上的其他潜在危险。
图像重建不仅是一种医疗技术,它还可以在港口和机场中找到,在那里,安全人员可以使用X射线对密封的容器进行窥视。它在建筑和材料行业中也很有价值,在这些行业中,3D超声图像可以在结构失效之前很久就揭示出危险的缺陷。但是对于Wang来说,他的目标是克服基于不完善和不完整的医学物理数据重建对象(例如患者心脏)的体积图像时出现的噪音和伪像。
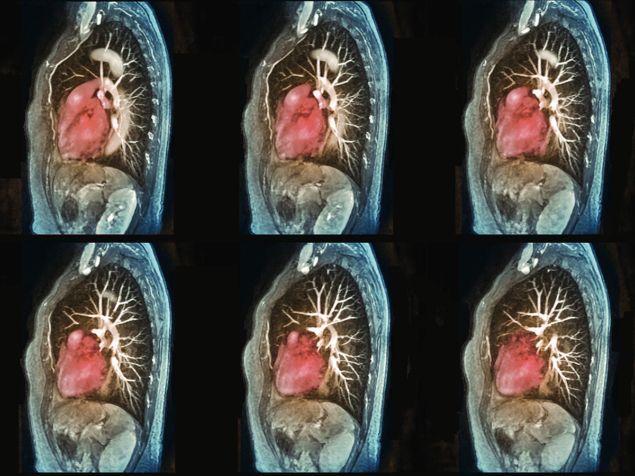
越少越好:快速进行MRI扫描可以避免捕获内部器官的不必要运动,但会导致图像受损。但是,机器学习可以基于不完整的数据重建改进的图像。
有充分的理由来处理尽可能少的数据。例如,在磁共振成像(MRI)中,快速进行扫描可以避免患者心脏和肺部不必要的运动,否则这些运动会给所生成的图片造成不可接受的污点。同时,在X射线计算机断层扫描(CT)中,您希望最大程度地减少对患者的辐射剂量,这意味着仅捕获足够的数据以生成图像即可,而无需再进行其他操作。
传统的“分析”重建方法通过组合从患者周围各个角度获得的测量结果来生成图像,这很困难,因为这意味着要获取完整的数据集。尽管近年来开发的“迭代重建”算法更能容忍数据中的差异,但它们需要大量的计算机功能。这是因为这些算法会产生多个候选图像,每个图像都必须与“正确”数据进行比较,以便逐渐达到最终的重建效果。
在短期内,Wang设想使用机器学习技术来代替重建过程中的特定单个组件。这些技术将基于“人工神经网络”(请参见下面的方框),该网络近似模拟生物大脑的工作,每个输入都由一个或多个“隐藏”的人工神经元层处理。加权各层之间的相互作用,以使过程为非线性,并且这些参数随系统的学习而变化,从而相应地修改输出。所谓的“深度学习”方法是在存在许多隐藏层时利用“深度”网络的方法。
首先,Wang认为,改进将是微不足道的,而不是革命性的。例如,在迭代重建中,使用神经网络基于大数据集对图像进行初始“猜测”,只会使整个过程更高效。另一种替代方法是,神经网络负责确定何时执行了足够的迭代以产生足够的输出。
然而,从长远来看,Wang的野心更大。他呼吁建立一个完全集成的系统,在该系统中,机器学习算法(使用原始成像数据作为输入)将重建图像,然后提取和分类癌症和神经疾病等病理特征。这样的系统甚至可以扩展到涵盖治疗计划,从而使从数据采集到治疗的整个过程自动化。
Wang说,尽管取得了成就和希望,深度学习仍缺乏一个体面的总体理论,这意味着该技术的矛盾之处仍然是神秘的。通过更改一个小像素的值,人工神经网络可以返回奇怪的结果。这并不总是正确的。因此,未来的目标是开发更容易解释,更易于解释的AI,打开黑匣子,Wang开玩笑说,“仍然是一个灰匣子”。

量子问题
机器学习也可能对量子物理学产生深远的影响,尤其是解决“量子多体问题”。当您有一组相互作用的对象时,只有考虑到它们的量子性质,才能理解这些问题。“这些问题的共同点是,从原理上讲,研究它们的特性需要对多体波函数有充分的了解,” 美国西蒙斯基金会的Flatiron研究所的物理学家Giuseppe Carleo说。
用Carleo的话说,多体波函数是“一个怪物,它的复杂性与成分的数量成指数关系”。例如,想像一个粒子系统,每个粒子系统都可以顺时针或逆时针旋转。对于两个粒子,您有四个可能的状态。具有三个粒子,八个状态,这仍然是可管理的。但是,走得更远,事情很快就会失控。
解决量子多体问题的同样困难也出现在“量子态层析成像”中。就像层析成像可以通过不进行任何测量来重建对象的内部一样,量子态层析成像可以通过对系统更易接近的部分进行的少量测量来确定系统的量子态。与量子多体问题一样,波动函数中编码的信息随系统中组件的数量呈指数增长。
描述量子态的一种方式是纠缠量子计算机中的量子位,这使量子态断层扫描对于理解这种计算机如何应对噪声和相干性损失至关重要。问题是,任何值得拥有的量子计算机都将包含数十或数百个量子位,因此用蛮力方法确定其量子状态将是不够的。正是在那里,人工神经网络才得以解救,卡尔雷发现了这一点,从而有可能有效地重建包括100个量子比特的量子计算机的状态。相反,标准方法仅限于大约8个量子位。

新的学习方式:人工神经网络近似模拟真实生物大脑的工作,每个输入都由一个或多个“隐藏”的人工神经元层处理。
还有更多。机器学习方法仅在最近才应用于该领域,这意味着研究人员使用的技术仍处于原理验证阶段。确实,Carleo及其同事演示的方法通常涉及仅具有一或两个隐藏层的神经网络,而更成熟的商业应用程序(例如Google和Facebook之类的应用程序)可以采用更深层次的体系结构,并在专用硬件上运行已经针对这项工作进行了优化。
不幸的是,量子物理学臭名昭著的怪异性意味着这些更复杂的神经网络不能简单地直接转换为量子态。Carleo和其他人几乎不得不从头开始重写算法,并且还无法与机器学习应用程序最前沿看到的复杂性相提并论。赶上那些成熟的系统将使人工神经网络能够解决更复杂的量子问题。“我认为在接下来的几年中,这种方法和技术上的差距将会越来越小,导致我们现在无法想象的应用,” Carleo说。
未来几年,人工神经网络将能够解决更复杂的量子问题
寻找新材料
人工神经网络通常必须先输送大量数据,然后才能产生有用的结果,而在美国弗吉尼亚大学,Prasanna Balachandran所使用的工具并不那么耗数据。他的研究的目的是从广阔的多维空间中识别出能够产生具有良好性能的材料的相对较少的配方。通过反复试验来探索这样的空间将花费太长时间,并且映射的区域(对应于其特性已知的材料)在整体中只占很小的一部分。

从谷壳中选出小麦:统计学习可用于将大量可能的物质结构筛选为可管理的数量以进行实验。
Balachandran用于解决此问题的方法是一种特殊的机器学习形式,称为统计学习。通过假设数据中的模式遵循严格的统计规则,这种方法可以满足对大型训练集的需求。他解释说:“我们训练机器学习模型来了解我们已经知道的事情,然后将这些模型应用于预测我们不知道的事情。”
在这种情况下,我们知道某些材料组合的行为,而我们本质上希望预测的是其他所有可能配方的特性。但是,可以预测给定材料的属性的置信度取决于对周围邻域的了解程度,因此-对于每次预测-Balachandran也会量化与每个预期值相关的误差线。
因此,可以识别缺乏知识的区域,并且系统可以建议接下来要进行的最有利可图的实验。这是一种新颖的方法。Balachandran说:“通常,在材料科学中,进行实验的方式因进行实验的科学家的直觉而有偏差。”
美国和中国的Balachandran及其同事最近通过从将近一百万种可能的成分中发现了一套高性能的“形状记忆合金”,证明了这种方法的有效性。这样的材料是有用的,因为它们在加热或冷却时随着相变而变形。相变的温度取决于转变的方向,这种差异(热滞后)决定了合金适合的应用。Balachandran的小组特别热衷于使用具有尽可能小的热滞现象的材料,并且发现,根据机器的预测,他们合成的几十种合金中,几乎有一半的合金是迄今为止最好的样品。
探索材料特性的无限空间可能是欧内斯特·卢瑟福(Ernest Rutherford)嘲笑为仅仅是“邮票收集”的活动之一,但这可能是发现新物理学的关键。Balachandran说:“在接下来的五到十年中,我们希望超越关联,开始考虑因果关系。” “您需要使用正确的数据来探讨因果关系本身的概念。在我看来,我们已经解决了难题的这一部分,而且我们知道如何快速找到针对我们感兴趣的任何给定问题的代表性样本。”
统计,统计,统计
虽然机器学习技术已经在医学,量子和材料物理领域取得了具体的成果和见解,而在其他方面则是不可能的,但统计物理领域的进展却不那么明显。“我们仍在等待一个伟大的榜样,即社区会同意没有机器学习就不会做的事情,” 在法国巴黎萨克莱大学研究机器学习理论的LenkaZdeborová承认。
当然,统计物理学已经有了令人鼓舞的发展,但是Zdeborová说,到目前为止,这些技术尚未在该领域的前沿部署。她指出了数十篇使用神经网络研究诸如2D Ising模型之类的论文的模型,该模型描述了2D晶格上旋转的粒子之间的相互作用,但到目前为止,还没有任何一篇告诉我们任何根本上的新知识。

令人失望的是,机器学习尚未推动统计物理学的进步,但是知识和见识肯定正在以另一种方式流动。例如,想象一下识别图像所需的神经网络。每个图像将包含大量数据(像素)并且嘈杂(因为任何给定图像都将被大量不相关的特征掩盖);并且网络中不同权重之间也会存在相关性。
令人高兴的是,自上世纪中叶以来,多维,嘈杂和相关的问题就是统计物理学家一直在学习的方法。兹德伯罗瓦(Zdeborová)说:“只需考虑物理学在无序系统中发展的理论,”他的背景是一种特殊的无序磁体,即自旋玻璃。这样的系统具有很多粒子(即很多尺寸),一个有限的温度(即热噪声)和许多粒子间的相互作用(即很多相关性)。实际上,在某些情况下,描述机器学习模型的方程与用于处理统计物理学中系统的方程完全相同。
这种见解可能是发展全面理论的关键,该理论解释了为什么这些方法如此有效。机器学习的进步可能比几十年前的普遍预期要高,但是它的成功仍然主要来自经验的试错法。Zdeborová总结道:“我们希望能够预测最佳架构,如何设置参数以及算法是什么。” “目前,我们不知道如何在不付出巨大努力的情况下得到那些。”
机器学习术语
人工智能(AI)
机器表现出的智能行为。但是智能的定义是有争议的,因此最能满足AI要求的更笼统的描述是:一个系统的行为,该行为根据其环境和先前的经验来适应其行为。
机器学习
作为为机器赋予人工智能的一组方法,机器学习本身就是一门广泛的类别。从本质上讲,这是系统从培训集中学习的过程,以便系统可以自动对新数据做出适当的响应。
人工神经网络
机器学习的子集,其中,学习机制是根据生物大脑的行为建模的。输入信号经过神经元的网络层之前会被修改,然后再作为输出出现。通过改变网络中神经元之间的交互强度来编码经验。
