- 天文图像处理:星系分类与天体定位
xcLeigh
计算机视觉CV图像处理分类人工智能AI计算机视觉
天文图像处理:星系分类与天体定位一、前言二、天文图像处理基础2.1天文图像的获取2.2天文图像的格式2.3天文图像处理的基本流程三、天文图像预处理3.1去噪处理3.2平场校正3.3偏置校正四、星系分类4.1星系的分类体系4.2基于特征提取的星系分类方法4.3基于深度学习的星系分类方法五、天体定位5.1天体坐标系统5.2基于星图匹配的天体定位方法5.3基于深度学习的天体定位方法六、总结与展望致读者一
- 2019.10.13
蚂蚁_caec
日精进打卡第203天姓名:李敏499期学员努力一组公司:上海缘缀包装材料有限公司【知~学习】《六项精进》1遍,共201遍;《大学》1遍,共201遍未背诵企业使命、愿景、价值观【经典名句分享】付出不亚于任何人的努力一、修身:练字调理身体纠正驼背垃圾分类反省养生二、齐家:与妈妈打电话与骆驼互道早安晚安与骆驼一起做饭三、建功:关注备案信息转发公众号文章关注公司活动沟通奖励票事宜四、【积善】:发愿从201
- AI 人工智能与 Copilot 的融合发展策略
AI天才研究院
AI人工智能与大数据人工智能copilotai
AI人工智能与Copilot的融合发展策略关键词:人工智能、Copilot、代码生成、人机协作、机器学习、自然语言处理、软件开发摘要:本文探讨了人工智能与Copilot技术的融合发展策略。我们将从技术原理、实现方法、应用场景等多个维度深入分析,提出一套完整的融合框架和发展路径。文章首先介绍背景和核心概念,然后详细讲解关键技术,包括自然语言处理、代码生成算法等,接着通过实际案例展示应用效果,最后讨论
- 硬件预取的几个问题 1
1.硬件预取的定义和目标是什么?答案:硬件预取是CPU在程序执行前自动预测并加载可能使用的数据到缓存中的技术,目标是减少缓存未命中带来的延迟,提升指令吞吐量。2.硬件预取与软件预取的核心区别?答案:硬件预取由CPU内部逻辑自动触发,透明且通用;软件预取需程序员显式插入指令(如prefetch),可针对特定场景优化,但依赖代码适配。3.预取算法的主要分类?答案:分为规则驱动型(如顺序、步长预取)和机
- 超级实用!汇总pytest中那些常用的参数
测试开发Kevin
Python自动化测试测试开发单元测试pytest
刚开始使用pytest的同学,可能感觉最复杂的点就是其提供的各种参数,丰富的命令行参数在带来了灵活控制测试行为的同时也增加了对于新手的上手难度。在这里,我总结了一下pytest常用参数的分类,并提供详细的使用方法!如果读者是pytest小白,可以参考下面的文章,快速上手pytest:用最精简的例子带您快速了解Pytest框架中最核心的功能-CSDN博客一、基础运行参数指定运行范围pytest运行指
- 微算法科技技术突破:用于前馈神经网络的量子算法技术助力神经网络变革
MicroTech2025
量子计算算法神经网络
随着量子计算和机器学习的迅猛发展,企业界正逐步迈向融合这两大领域的新时代。在这一背景下,微算法科技(NASDAQ:MLGO)成功研发出一套用于前馈神经网络的量子算法,突破了传统神经网络在训练和评估中的性能瓶颈。这一创新性的量子算法以经典的前馈和反向传播算法为基础,借助量子计算的强大算力,极大提升了网络训练和评估效率,并带来了对过拟合的天然抗性。前馈神经网络是深度学习的核心架构,广泛应用于图像分类、
- MySQL 索引详解:从原理到实战的全方位指南
一切皆有迹可循
mysqlmysql数据库后端javasql
前言索引是MySQL高性能查询的核心驱动力,合理设计索引能将查询性能提升几个数量级,而不当使用则可能导致严重的性能瓶颈。本文从索引的基础概念出发,深入解析数据结构、分类特性、设计原则及实战优化,帮助开发者掌握索引的核心原理与最佳实践。一、索引基础概念1.索引定义与本质索引是存储引擎用于快速查找数据的一种数据结构,本质是「数据项→数据地址」的映射表类比:相当于书籍的目录,通过目录(索引)快速定位章节
- MySQL 锁详解:从原理到实战的并发控制指南
一切皆有迹可循
mysqlmysql数据库后端javasql
前言在高并发场景下,锁是MySQL保证数据一致性的核心机制。正确理解锁的类型、行为及适用场景,能有效避免数据竞争、死锁等问题,是构建可靠数据库应用的关键。本文从锁的分类、存储引擎差异到实战优化,结合代码示例,系统解析MySQL锁机制的核心原理与最佳实践。一、锁分类:按粒度与功能划分1.按锁粒度划分(1)全局锁(GlobalLock)作用范围:锁定整个数据库实例典型场景:全库逻辑备份(FLUSHTA
- 【第三十二天】STM32 平台全景解析与型号选择实战指南
观熵
每日一练:嵌入式C++开发365天stm32嵌入式硬件单片机学习C++
STM32平台全景解析与型号选择实战指南关键词:STM32、MCU选型、STM32F1、STM32G4、STM32H7、Flash/RAM、外设资源、封装选型、低功耗方案、嵌入式平台摘要:STM32系列是目前嵌入式开发中应用最广泛的ARMCortex-M微控制器平台之一,覆盖从入门级控制器到高性能边缘处理器的多种应用场景。本文从STM32的平台分类、架构演进、性能指标、外设组合、功耗管理等角度展开
- 新媒体运营干货文写作工作流简介
运营怪的杂货铺
为什么生产干货文?我们常说的干货文其实等同于教育型文章,广告界的一位著名大师曾经说过“Teach,Don'tsell”教育,而不是销售任何以销售为目的的产品最开始都应该以教育型内容开头。这是我对这句话的理解。新媒体营销也是如此,如果你需要别人买你的单,那你提供的内容是能帮助到用户,用户才能为你而买单。干货文的分类按照长度分类800字800-1500字1500字以上用户阅读速度150字/分钟,我们通
- 算法竞赛备考冲刺必刷题(C++) | 洛谷 P1179 数字统计
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。欢迎大家订阅我的专栏:算法题解:C++与Python实现!附上汇总贴:算法竞赛备考冲刺必刷题(C++)|汇总【题目来源】洛谷:P1179[NOIP2010普及组]数字
- 算法竞赛备考冲刺必刷题(C++) | 洛谷 P1109 学生分组
热爱编程的通信人
算法c++开发语言
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。欢迎大家订阅我的专栏:算法题解:C++与Python实现!附上汇总贴:算法竞赛备考冲刺必刷题(C++)|汇总【题目来源】洛谷:P1109学生分组-洛谷【题目描述】有n
- 算法竞赛备考冲刺必刷题(C++) | 洛谷 P1449 后缀表达式
热爱编程的通信人
算法c++开发语言
本文分享的必刷题目是从蓝桥云课、洛谷、AcWing等知名刷题平台精心挑选而来,并结合各平台提供的算法标签和难度等级进行了系统分类。题目涵盖了从基础到进阶的多种算法和数据结构,旨在为不同阶段的编程学习者提供一条清晰、平稳的学习提升路径。欢迎大家订阅我的专栏:算法题解:C++与Python实现!附上汇总贴:算法竞赛备考冲刺必刷题(C++)|汇总【题目来源】洛谷:P1449后缀表达式-洛谷【题目描述】所
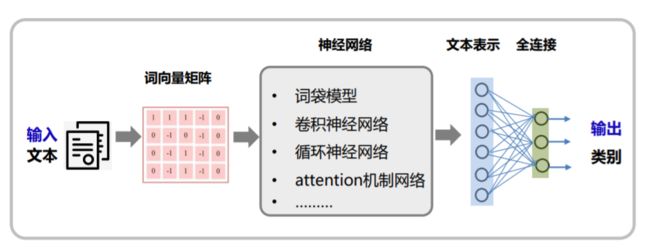
- Java NLP炼金术:从词袋到深度学习,构建AI时代的语言魔方
墨夶
Java学习资料人工智能java自然语言处理
一、JavaNLP的“三剑客”:框架与工具链1.1ApacheOpenNLP:传统NLP的“瑞士军刀”目标:用词袋模型实现文本分类与实体识别代码实战:文档分类器的“炼成术”//OpenNLP文档分类器(基于词袋模型)importopennlp.tools.doccat.*;importopennlp.tools.util.*;publicclassDocumentClassifier{//训练模型
- Java代码异味终结者:三大神器实战拆解与深度优化
墨夶
Java学习资料java开发语言
2025年某电商平台因代码异味导致的崩溃事件,让业界震惊——重复代码占项目总量的32%,单个类方法行数超1500行,最终导致日活下降40%。本文通过代码异味检测工具,带你:1秒定位重复代码与魔法数字0误报率识别God类与空方法自动化修复代码异味,减少80%人工检查一、代码异味的科学分类与检测工具选择1.1代码异味的5大死亡陷阱类别典型症状危害等级重复代码相同逻辑在3处以上重复★★★★★God类单类
- 系统学习Python——并发模型和异步编程:进程、线程和GIL
分类目录:《系统学习Python》总目录在文章《并发模型和异步编程:基础知识》我们简单介绍了Python中的进程、线程和协程。本文就着重介绍Python中的进程、线程和GIL的关系。Python解释器的每个实例都是一个进程。使用multiprocessing或concurrent.futures库可以启动额外的Python进程。Python的subprocess库用于启动运行外部程序(不管使用何种
- JavaScript 树形菜单总结
Auscy
microsoft
树形菜单是前端开发中常见的交互组件,用于展示具有层级关系的数据(如文件目录、分类列表、组织架构等)。以下从核心概念、实现方式、常见功能及优化方向等方面进行总结。一、核心概念层级结构:数据以父子嵌套形式存在,如{id:1,children:[{id:2}]}。节点:树形结构的基本单元,包含自身信息及子节点(若有)。展开/折叠:子节点的显示与隐藏切换,是树形菜单的核心交互。递归渲染:因数据层级不固定,
- 高效批量单词翻译工具的设计与应用
本文还有配套的精品资源,点击获取简介:在信息技术飞速发展的今天,批量单词翻译工具通过计算机的数据处理能力,大大提高了语言学习和文字处理的效率。用户通过简单输入单词列表到一个文本文件,并运行翻译程序,即可获得翻译结果并保存至指定文件。该工具集成了内置或外部翻译引擎,利用自然语言处理技术实现快速准确的翻译,并可能提供词性识别等附加功能。尽管机器翻译无法完全取代人工校对,但它为用户提供了一种高效的翻译解
- 计算机网络技术
CZZDg
计算机网络
目录一.网络概述1.网络的概念2.网络发展是3.网络的四要素4.网络功能5.网络类型6.网络协议与标准7.网络中常见的概念8.网络拓补结构二.网络模型1.分层思想2.OSI七层模型3.TCP/IP五层模型4.数据的封装与解封装过程三.IP地址1.进制转换2.IP地址定义3.IP地址组成成分4.IP地址分类5.地址划分6、相关概念一.网络概述1.网络的概念两个主机通过传输介质和通信协议实现通信和资源
- UNIX域套接字
1、UNIX域套接字的定义UNIX域套接字是进程间通信(IPC)的一种方式,不涉及网络协议栈,因此在同一台主机上的通信中,它比基于TCP/IP协议的网络套接字更快速、更高效。2、UNIX域套接字的分类字节流套接字(SOCK_STREAM):提供面向连接的、可靠的数据传输服务。数据报套接字(SOCK_DGRAM):提供无连接的数据传输服务,数据以独立的数据报形式传输。3、UNIX套接字与TCP/IP
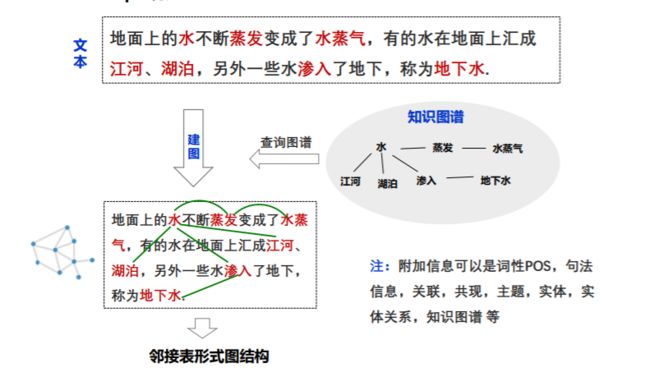
- 深度学习模型表征提取全解析
ZhangJiQun&MXP
教学2024大模型以及算力2021AIpython深度学习人工智能pythonembedding语言模型
模型内部进行表征提取的方法在自然语言处理(NLP)中,“表征(Representation)”指将文本(词、短语、句子、文档等)转化为计算机可理解的数值形式(如向量、矩阵),核心目标是捕捉语言的语义、语法、上下文依赖等信息。自然语言表征技术可按“静态/动态”“有无上下文”“是否融入知识”等维度划分一、传统静态表征(无上下文,词级为主)这类方法为每个词分配固定向量,不考虑其在具体语境中的含义(无法解
- 数据分析常用指标名词解释及计算公式
走过冬季
学习笔记数据分析大数据
数据分析中有大量常用指标,它们帮助我们量化业务表现、用户行为、产品健康度等。下面是一些核心指标的名词解释及计算方式,按常见类别分类:一、流量与用户规模指标页面浏览量名词解释:用户访问网站或应用时,每次加载或刷新一个页面就算一次PV。它衡量的是页面被打开的总次数。计算方式:PV=∑(所有页面被加载的次数)(通常由埋点或日志直接统计)独立访客数名词解释:在特定时间范围内(如一天、一周、一月),访问网站
- V少JS基础班之第五弹
V少在逆向
JS基础班javascript开发语言ecmascript
文章目录一、前言二、本节涉及知识点三、重点内容1-函数的定义2-函数的构成1.函数参数详解1)参数个数不固定2)默认参数3)arguments对象(类数组)4)剩余参数(Rest参数)5)函数参数是按值传递的6)解构参数传递7)参数校验技巧(JavaScript没有类型限制,需要手动校验)2.函数返回值详解3-函数的分类1-函数声明式:2-函数表达式:3-箭头函数:4-构造函数:5-IIFE:6-
- Python爬虫实战:利用最新技术爬取B站直播数据
Python爬虫项目
2025年爬虫实战项目python爬虫开发语言html百度
1.B站直播数据爬取概述B站(哔哩哔哩)是中国最大的年轻人文化社区和视频平台之一,其直播业务近年来发展迅速。爬取B站直播数据可以帮助我们分析直播市场趋势、热门主播排行、观众喜好等有价值的信息。常见的B站直播数据类型包括:直播间基本信息(标题、分类、主播信息)实时观看人数与弹幕数据礼物打赏数据直播历史记录分区热门直播数据本文将重点介绍如何获取直播间基本信息和分区热门直播数据。2.环境准备与工具选择2
- 目标检测(object detection)
加油吧zkf
目标检测目标检测人工智能计算机视觉
目标检测作为计算机视觉的核心技术,在自动驾驶、安防监控、医疗影像等领域发挥着不可替代的作用。本文将系统讲解目标检测的概念、原理、主流模型、常见数据集及应用场景,帮助读者构建对这一技术的完整认知。一、目标检测的核心概念目标检测(ObjectDetection)是指在图像或视频中自动定位并识别出所有感兴趣的目标的技术。它需要解决两个核心问题:分类(Classification):确定图像中每个目标的类
- 不同行业的 AI 数据安全与合规实践:7 大核心要点全解析
观熵
人工智能DeepSeek私有化部署
不同行业的AI数据安全与合规实践:7大核心要点全解析关键词AI数据安全、行业合规、私有化部署、数据分类分级、国产大模型、隐私保护、DeepSeek部署摘要随着国产大模型在金融、医疗、政务、教育等关键领域的深入部署,AI系统对数据安全与行业合规提出了更高要求。本文结合DeepSeek私有化部署实战,系统梳理当前各行业主流的数据安全合规标准与落地策略,从数据分类分级、访问控制、审计追踪到敏感信息识别与
- STM32 ADC详解
月入鱼饵
stm32嵌入式硬件单片机
本文介绍stm32ADC的使用,本文较长,可以配合目录跳转到需要的地方阅读。ADC转换原理本文重点在于STM32的ADC的使用,介绍ADC转换原理是为了更好理解STM32中关于ADC的配置,所以这里只是简单介绍一下ADC的转换原理,想详细了解ADC的转换原理可以看看看完这篇文章,终于搞懂了ADC原理及分类!和ADC基本工作原理-CSDN。简单来说,模拟信号输入进来,经过低通滤波操作预处理信号之后,
- 深度学习图像分类数据集—桃子识别分类
AI街潜水的八角
深度学习图像数据集深度学习分类人工智能
该数据集为图像分类数据集,适用于ResNet、VGG等卷积神经网络,SENet、CBAM等注意力机制相关算法,VisionTransformer等Transformer相关算法。数据集信息介绍:桃子识别分类:['B1','M2','R0','S3']训练数据集总共有6637张图片,每个文件夹单独放一种数据各子文件夹图片统计:·B1:1601张图片·M2:1800张图片·R0:1601张图片·S3:
- c++中迭代器的本质
三月微风
c++开发语言
C++迭代器的本质与实现原理迭代器是C++标准模板库(STL)的核心组件之一,它作为容器与算法之间的桥梁,提供了统一访问容器元素的方式。下面从多个维度深入解析迭代器的本质特性。一、迭代器的基本定义与分类迭代器的本质迭代器是一种行为类似指针的对象,用于遍历和操作容器中的元素。它提供了一种统一的方式来访问不同容器中的元素,而无需关心容器的具体实现细节。标准分类体系C++标准定义了5种迭代器类型,按功能
- udev 规则文件命名规范
奇妙之二进制
#嵌入式/Linuxlinux网络运维
文章目录udev规则文件名的含义、规范及数字开头的原因一、udev规则文件的基本概念二、udev规则文件名的规范与含义1.文件名格式规范2.名称各部分的含义3.文件扫描路径三、为何规则文件名通常以数字开头?1.执行顺序的精确控制2.便于分类和管理3.兼容性与标准化四、示例与实践建议1.常见规则文件示例2.自定义规则命名建议五、总结udev规则文件名的含义、规范及数字开头的原因一、udev规则文件的
- PHP,安卓,UI,java,linux视频教程合集
cocos2d-x小菜
javaUIPHPandroidlinux
╔-----------------------------------╗┆
- 各表中的列名必须唯一。在表 'dbo.XXX' 中多次指定了列名 'XXX'。
bozch
.net.net mvc
在.net mvc5中,在执行某一操作的时候,出现了如下错误:
各表中的列名必须唯一。在表 'dbo.XXX' 中多次指定了列名 'XXX'。
经查询当前的操作与错误内容无关,经过对错误信息的排查发现,事故出现在数据库迁移上。
回想过去: 在迁移之前已经对数据库进行了添加字段操作,再次进行迁移插入XXX字段的时候,就会提示如上错误。
&
- Java 对象大小的计算
e200702084
java
Java对象的大小
如何计算一个对象的大小呢?
- Mybatis Spring
171815164
mybatis
ApplicationContext ac = new ClassPathXmlApplicationContext("applicationContext.xml");
CustomerService userService = (CustomerService) ac.getBean("customerService");
Customer cust
- JVM 不稳定参数
g21121
jvm
-XX 参数被称为不稳定参数,之所以这么叫是因为此类参数的设置很容易引起JVM 性能上的差异,使JVM 存在极大的不稳定性。当然这是在非合理设置的前提下,如果此类参数设置合理讲大大提高JVM 的性能及稳定性。 可以说“不稳定参数”
- 用户自动登录网站
永夜-极光
用户
1.目标:实现用户登录后,再次登录就自动登录,无需用户名和密码
2.思路:将用户的信息保存为cookie
每次用户访问网站,通过filter拦截所有请求,在filter中读取所有的cookie,如果找到了保存登录信息的cookie,那么在cookie中读取登录信息,然后直接
- centos7 安装后失去win7的引导记录
程序员是怎么炼成的
操作系统
1.使用root身份(必须)打开 /boot/grub2/grub.cfg 2.找到 ### BEGIN /etc/grub.d/30_os-prober ### 在后面添加 menuentry "Windows 7 (loader) (on /dev/sda1)" {
- Oracle 10g 官方中文安装帮助文档以及Oracle官方中文教程文档下载
aijuans
oracle
Oracle 10g 官方中文安装帮助文档下载:http://download.csdn.net/tag/Oracle%E4%B8%AD%E6%96%87API%EF%BC%8COracle%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3%EF%BC%8Coracle%E5%AD%A6%E4%B9%A0%E6%96%87%E6%A1%A3 Oracle 10g 官方中文教程
- JavaEE开源快速开发平台G4Studio_V3.2发布了
無為子
AOPoraclemysqljavaeeG4Studio
我非常高兴地宣布,今天我们最新的JavaEE开源快速开发平台G4Studio_V3.2版本已经正式发布。大家可以通过如下地址下载。
访问G4Studio网站
http://www.g4it.org
G4Studio_V3.2版本变更日志
功能新增
(1).新增了系统右下角滑出提示窗口功能。
(2).新增了文件资源的Zip压缩和解压缩
- Oracle常用的单行函数应用技巧总结
百合不是茶
日期函数转换函数(核心)数字函数通用函数(核心)字符函数
单行函数; 字符函数,数字函数,日期函数,转换函数(核心),通用函数(核心)
一:字符函数:
.UPPER(字符串) 将字符串转为大写
.LOWER (字符串) 将字符串转为小写
.INITCAP(字符串) 将首字母大写
.LENGTH (字符串) 字符串的长度
.REPLACE(字符串,'A','_') 将字符串字符A转换成_
- Mockito异常测试实例
bijian1013
java单元测试mockito
Mockito异常测试实例:
package com.bijian.study;
import static org.mockito.Mockito.mock;
import static org.mockito.Mockito.when;
import org.junit.Assert;
import org.junit.Test;
import org.mockito.
- GA与量子恒道统计
Bill_chen
JavaScript浏览器百度Google防火墙
前一阵子,统计**网址时,Google Analytics(GA) 和量子恒道统计(也称量子统计),数据有较大的偏差,仔细找相关资料研究了下,总结如下:
为何GA和量子网站统计(量子统计前身为雅虎统计)结果不同?
首先:没有一种网站统计工具能保证百分之百的准确出现该问题可能有以下几个原因:(1)不同的统计分析系统的算法机制不同;(2)统计代码放置的位置和前后
- 【Linux命令三】Top命令
bit1129
linux命令
Linux的Top命令类似于Windows的任务管理器,可以查看当前系统的运行情况,包括CPU、内存的使用情况等。如下是一个Top命令的执行结果:
top - 21:22:04 up 1 day, 23:49, 1 user, load average: 1.10, 1.66, 1.99
Tasks: 202 total, 4 running, 198 sl
- spring四种依赖注入方式
白糖_
spring
平常的java开发中,程序员在某个类中需要依赖其它类的方法,则通常是new一个依赖类再调用类实例的方法,这种开发存在的问题是new的类实例不好统一管理,spring提出了依赖注入的思想,即依赖类不由程序员实例化,而是通过spring容器帮我们new指定实例并且将实例注入到需要该对象的类中。依赖注入的另一种说法是“控制反转”,通俗的理解是:平常我们new一个实例,这个实例的控制权是我
- angular.injector
boyitech
AngularJSAngularJS API
angular.injector
描述: 创建一个injector对象, 调用injector对象的方法可以获得angular的service, 或者用来做依赖注入. 使用方法: angular.injector(modules, [strictDi]) 参数详解: Param Type Details mod
- java-同步访问一个数组Integer[10],生产者不断地往数组放入整数1000,数组满时等待;消费者不断地将数组里面的数置零,数组空时等待
bylijinnan
Integer
public class PC {
/**
* 题目:生产者-消费者。
* 同步访问一个数组Integer[10],生产者不断地往数组放入整数1000,数组满时等待;消费者不断地将数组里面的数置零,数组空时等待。
*/
private static final Integer[] val=new Integer[10];
private static
- 使用Struts2.2.1配置
Chen.H
apachespringWebxmlstruts
Struts2.2.1 需要如下 jar包: commons-fileupload-1.2.1.jar commons-io-1.3.2.jar commons-logging-1.0.4.jar freemarker-2.3.16.jar javassist-3.7.ga.jar ognl-3.0.jar spring.jar
struts2-core-2.2.1.jar struts2-sp
- [职业与教育]青春之歌
comsci
教育
每个人都有自己的青春之歌............但是我要说的却不是青春...
大家如果在自己的职业生涯没有给自己以后创业留一点点机会,仅仅凭学历和人脉关系,是难以在竞争激烈的市场中生存下去的....
&nbs
- oracle连接(join)中使用using关键字
daizj
JOINoraclesqlusing
在oracle连接(join)中使用using关键字
34. View the Exhibit and examine the structure of the ORDERS and ORDER_ITEMS tables.
Evaluate the following SQL statement:
SELECT oi.order_id, product_id, order_date
FRO
- NIO示例
daysinsun
nio
NIO服务端代码:
public class NIOServer {
private Selector selector;
public void startServer(int port) throws IOException {
ServerSocketChannel serverChannel = ServerSocketChannel.open(
- C语言学习homework1
dcj3sjt126com
chomework
0、 课堂练习做完
1、使用sizeof计算出你所知道的所有的类型占用的空间。
int x;
sizeof(x);
sizeof(int);
# include <stdio.h>
int main(void)
{
int x1;
char x2;
double x3;
float x4;
printf(&quo
- select in order by , mysql排序
dcj3sjt126com
mysql
If i select like this:
SELECT id FROM users WHERE id IN(3,4,8,1);
This by default will select users in this order
1,3,4,8,
I would like to select them in the same order that i put IN() values so:
- 页面校验-新建项目
fanxiaolong
页面校验
$(document).ready(
function() {
var flag = true;
$('#changeform').submit(function() {
var projectScValNull = true;
var s ="";
var parent_id = $("#parent_id").v
- Ehcache(02)——ehcache.xml简介
234390216
ehcacheehcache.xml简介
ehcache.xml简介
ehcache.xml文件是用来定义Ehcache的配置信息的,更准确的来说它是定义CacheManager的配置信息的。根据之前我们在《Ehcache简介》一文中对CacheManager的介绍我们知道一切Ehcache的应用都是从CacheManager开始的。在不指定配置信
- junit 4.11中三个新功能
jackyrong
java
junit 4.11中两个新增的功能,首先是注解中可以参数化,比如
import static org.junit.Assert.assertEquals;
import java.util.Arrays;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.junit.runn
- 国外程序员爱用苹果Mac电脑的10大理由
php教程分享
windowsPHPunixMicrosoftperl
Mac 在国外很受欢迎,尤其是在 设计/web开发/IT 人员圈子里。普通用户喜欢 Mac 可以理解,毕竟 Mac 设计美观,简单好用,没有病毒。那么为什么专业人士也对 Mac 情有独钟呢?从个人使用经验来看我想有下面几个原因:
1、Mac OS X 是基于 Unix 的
这一点太重要了,尤其是对开发人员,至少对于我来说很重要,这意味着Unix 下一堆好用的工具都可以随手捡到。如果你是个 wi
- 位运算、异或的实际应用
wenjinglian
位运算
一. 位操作基础,用一张表描述位操作符的应用规则并详细解释。
二. 常用位操作小技巧,有判断奇偶、交换两数、变换符号、求绝对值。
三. 位操作与空间压缩,针对筛素数进行空间压缩。
&n
- weblogic部署项目出现的一些问题(持续补充中……)
Everyday都不同
weblogic部署失败
好吧,weblogic的问题确实……
问题一:
org.springframework.beans.factory.BeanDefinitionStoreException: Failed to read candidate component class: URL [zip:E:/weblogic/user_projects/domains/base_domain/serve
- tomcat7性能调优(01)
toknowme
tomcat7
Tomcat优化: 1、最大连接数最大线程等设置
<Connector port="8082" protocol="HTTP/1.1"
useBodyEncodingForURI="t
- PO VO DAO DTO BO TO概念与区别
xp9802
javaDAO设计模式bean领域模型
O/R Mapping 是 Object Relational Mapping(对象关系映射)的缩写。通俗点讲,就是将对象与关系数据库绑定,用对象来表示关系数据。在O/R Mapping的世界里,有两个基本的也是重要的东东需要了解,即VO,PO。
它们的关系应该是相互独立的,一个VO可以只是PO的部分,也可以是多个PO构成,同样也可以等同于一个PO(指的是他们的属性)。这样,PO独立出来,数据持