布尔检索
前记:
之前做过一个在线电子商城的项目,初次接触到搜索检索技术,用 lucene + compass 做的商品和商家信息搜索,感觉真的很强大。海量的商品,非结构化的数据,复杂的查询条件,如果不用搜索引擎技术,用传统的关系型数据库去做查询,基本上是不可能实现(当然,现在很多关系型数据库开始内置搜索引擎,全文检索,就是弥补这方面的不足)。在做国际机票的运价系统设计时,针对大量机票政策文件,复杂的综合机票查询条件(缺口,联程.....几十个查询条件),如果在秒级时间内快速查询出满足条件的航班信息,都是离不开搜索技术。
现代互联网技术的飞速发展,大数据时代来临,从海量数据中查询,分析,挖掘有用信息,是计算机技术发展的方向,这无疑对现在开发人员更要学习相关这方面的知识,像搜索引擎,数据挖掘,分布式计算,等等。入手 <<Introduction to Information Retrieval>> 这本书,目的就是想系统学习下信息检索这方面的基础理论知识。这本书在行业内知名度还是挺高的,是国外知名学院计算机专业的信息检索教材。之前看英文版的一段时间,由于英语问题,很多地方都没有看透,所以买了一本 王斌 博士翻译的版本,王斌 博士是中科院信息检索组组长,所以这本书翻译得很好,相比一些国内其它翻译的书,真是不如看英文版。接下来的系列文章,就是学习这本书的相关知识后记录的一些笔记,和自己的一些理解,就权当像读书的时候上课做的笔记一样。当然,因为这本书是基础理论知识,所以我会结合书的一些算法,实现一些上机的 代码。
需求
现在有个电子商城(可以想像淘宝网之类),假如后台维护的商品有10万个,归属于30个类别(电器,服装等类似分类),商品本身的属性有:价格,关键描述,详细描述,状态(是否上架),品牌,等等。现在商城首页要做搜索,客户输入关键字,查询出所有满足包括此关键字描述的商品。如果是高级搜索功能的话,用户还可以选择价格区间,状态过滤,品牌选择,等各种过滤条件。
一般我们会这样设计表结构:
| 字段名 | 类型 | 描述 |
| id | int | 商品id |
| name | varchar | 商品名称 |
| description | text | 商品描述 |
| price | number | 商品价格 |
| online_staus | int | 上架状态 |
| brand | varchar | 品牌 |
| category | varchar | 商品类别 |
假如现在用户要查询这样的商品:商品名称包括“电脑”,商品描述里不能有“日本”,价格在3000-4000之间,上架状态为已上架中。写成数学表达式就是:
(name:电脑) & (^描述:日本) & (price:>3000 & price <4000 ) & (onlin_status:1)
如果用sql在表中直接查询是不敢想像的,单“商品描述”这一个字段的全文描述,基本上就淘汰了这个方案(哪怕基于正则表达式的全文扫描在性能上没有问题,在一些检索功能上也达不到要求,比如查询两个关键只能在同一个句子中出现)。我们现在就要考虑一种非线性描述的方式处理这个问题。
倒排索引
倒排索引(inverted index) 倒排二字其实是多余的,很容易让大家搞不清楚这个概念,索引就是索引,加上“倒排二字”,实属多余,但是可以把这二字当成一种强调修饰,着重强调索引与线性扫描的本质区别。前者是反向把文章里的词项整理出来保存起来,后者是查询的时候再全文扫描。
构建倒排索引的过程大概这样,这里以商品描述字段构建倒排索引:顺序依次查询出商品表中的所有商品,针对每条商品的描述字段进行分词,把此商品的id和处理后的分词关键词项关联存储起来,直到所有商品处理完成。最后的数据结构如下图所示:
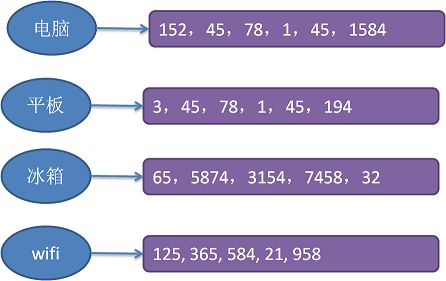
上图所描述的信息就是:在商品描述字段里,包括“电脑”词项的商品id有:152,45,78,1,45,1584,包括“平板”的词项商品id有:3,45,78,1,45,194,后面的信息依此类推。
如果搜索“平板 电脑”,则先把输入条件进行 分词 (分词相关知识下篇会讲到),得到“电脑”和“平板”两个词项,然后根据这两个词项得到对应的 倒排记录表 ,剩下的工作就是把这两个倒排记录表进行交集操作后得到的结果就是最终查询的商品列表(45,78)。
布尔运算基础知识及布尔查询处理
上面提到,对于查询条件:criteria1 AND criteria2 AND criteria3.......的处理,就是对各个单元子查询结果集进行交集操作,在数学布尔运算中就是“逻辑与”操作。
交集运算的思路如所示:
- 两个指针分别指向倒排记录表的首元素位置。
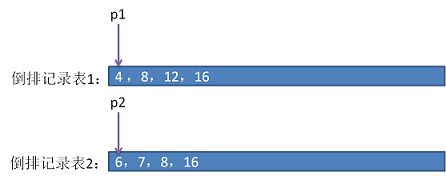
- 如果p1 指向的值小于p2 指向的值,则指针p1向后移动指向下一个位置。
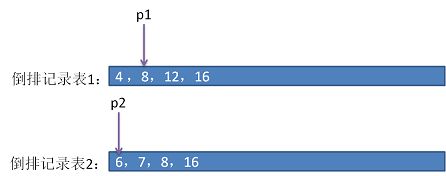
- 如果p1 指向的值大于p2 指向的值,则指针p2向后移动指向下一个位置。
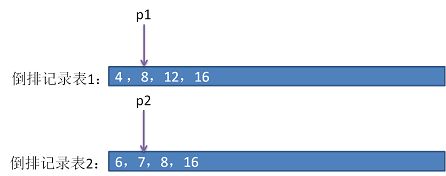
- 因为p1指向的值大于p2指向的值,所以p2向后移动,
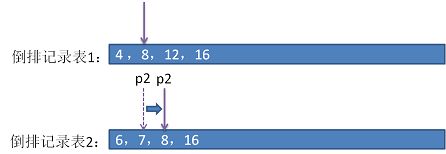
此时,p1和p2所指向的值都是 8 ,则把该值添加到待返回结果集中,然后p1,p2同时向后移动指下到下一个位置。 - 根据 2,3,4的规则移动当前指针,每次移动前检测是否满足完成操作条件:如果p1和p2任一个已经指向的倒排列表的末尾,则操作完成。最后返回的结果集是(8,16)
注意:前面的算法是基于倒排列表是有序的,这是上述算法的必要前提条件。
算法复杂度:
如果两个倒排列表的长度分别是x,y,则查询时间的复杂度是:θ(x+y)。严格意义上讲,应该是:θ(N),N是文档的总数量。所以这个复杂度是常数级的。
查询优化:
针对如下查询:
criteria1 AND criteria2 AND criteria3
一般的步骤是从先查出criteria1,criteria2的集合,然后两者交集运算后得到的结果集合再与criteria2的集合进行交集运算。扩展到N个查询条件,也是从前往后依次进行交集运算。针对这样的运算特殊性,有没有什么技巧可以优化整个运算呢?我们知道数学的“逻辑与”操作符,得到的是结果肯定是小于或等于任何其中一个运算项的,即同时满足criteria1和criteria2的结果集肯定是是criteria1和criteria2的子集。所以我们可以按集合大小来从小到大重新排列后再依次进行交集运算。假如上面的criteria3 > criteria2 > criteria1,则我们进行交集运算的时候先排列后再运算:criteria3 AND criteria2 AND criteria1。