0002深度学习初体验-基于Tensorflow and Keras 实现卷积神经网络(CNN-AlexNET)实现CIFAR图像训练
0002深度学习初体验-基于Tensorflow and Keras 实现卷积神经网络(CNN-AlexNET)实现CIFAR图像训练
摘要
LeNet 是最早推动深度学习领域发展的卷积神经网络之一。这项由 Yann LeCun等完成的开创性工作自1988年以来多次成功迭代之后被命名为LeNet 5,被应用于手写体的识别。AlexNet 是 Alex等人在 2012 年发表的《ImageNet Classification with Deep Convolutional Neural Networks》论文中提出的,并夺得了 2012 年 ImageNet LSVRC 的冠军,引起了很大的轰动。AlexNet 可以说是具有历史意义的一个深层网络结构,在此之前,深度学习已经沉寂了很长时间,自 2012 年 AlexNet 诞生之后,后面的 ImageNet 冠军都是用卷积神经网络(CNN)来做的,并且层次越来越深,使得CNN成为在图像识别分类的核心算法模型,带来了深度学习的大爆发。本文将详细讲解 AlexNet 模型及使用 Keras与Tensorflow 搭建AlexNet的过程,完成对CIFAR 中图像的分类,准确率达到99.64%。
关键词 卷积神经网络;AlexNet;图像分类;深度学习;CIFAR
AlexNet Image Recognition Based on Deep Convolution Neural Network
LeNet is one of the earliest convolutional neural networks to promote the development of deep learning. This pioneering work completed by Yann LeCun et al. has been successfully iterated since 1988, and then named LeNet 5, which has been applied to handwriting recognition. AlexNet was put forward by Alex et al. in the paper ImageNet Classification with Deep Voluntary Neural Networks published in 2012, and won the title of ImageNet LSVRC in 2012, which caused a great sensation. AlexNet can be said to be a deep network structure with historical significance. Before that, deep learning has been silent for a long time. Since AlexNet was born in 2012, the following ImageNet champions are all made by Convolutional Neural Network (CNN), and the level is getting deeper and deeper, which makes CNN become the core algorithm model in image recognition and classification, which brings a great explosion of deep learning. In this paper, the AlexNet model and the process of building AlexNet with Keras and Tensorflow will be explained in detail, and the classification of images in CIFAR will be completed, with an accuracy rate of 99.62%.
Key words CNN;AlexNet ;Image classification ;Deep learning;
CIFAR
1.引言
Artificial Intelligence,即人工智能。自1939年阿兰·图灵(Alan Turing)设计出第一台机器—恩尼格玛(Enigma)以来,机器智能的命题就一直延续到现在。1956年,在美国汉诺夫小镇的达特茅斯学院来了很多像香农(Shanon)、明斯基(Minsky)等天才专家,他们尝试着弄清楚如何让机器像人类一样思考,如何使用自然语言来交流,如何伸出手去抓取东西,他们想要解决人类现存的各种问题,这次会议被命名为“人工智能夏季研讨班”,这也是“人工智能”这一名词被首次提出,从那以后,人工智能的相关研究历经沉浮。
[1] Alex Krizhevsky,Ilya Sutskever,Geoffrey E. Hinton. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM,2017,60(6).
虽然计算机技术已经取得了长足的进步,但是到目前为止,还没有一台电脑能产生“自我”的意识。在人类和大量现成数据的帮助下,电脑可以表现的十分强大,但是离开了这两者,它甚至都不能分辨出图片中是一只猫还是一条狗[2]。
AI许多早期的成功发生在相对朴素且形式化的环境中,而且不要求计算机具备很多关于世界的知识。例如,IBM的深蓝(Deep Blue)国际象棋系统在1997年击败了世界冠军卡斯帕洛夫Garry Kasparov 。依靠硬编码的知识体系面临着各种问题,AI系统需要具备自己获取知识的能力,即从原始数据中提取模式的能力。这种能力被称为机器学习。引入机器学习使计算机能够解决涉及现实世界知识的问题,并能做出看似主观的决策。
[2] Ian Goodfellow,Yoshua Bengio ,Aaron Courville. Deep learning [M]. MIT press, 2016.
近年来,深度学习技术在图像处理、视频音频处理、语音识别等领域的发展速度迅猛,尤其是以卷积神经网络CNN(Convolutional Neural Networks)为代表的深层结构前向反传神经网络[1]。对卷积神经网络的主要研究始于上世纪80到90年代,Yann LeCun 等在1989年首次提出将反向传播算法引入卷积神经网络之中,并发明了权值共享、池化等技巧,扩大了卷积神经网络适用范围与算法性能。深度学习的概念最早由Hinton等人在2006年提出,基于深度置信网络(DBN,Deep Belief Networks),提出非监督贪心逐层训练算法,为解决深层结构相关的优化难题带来希望,随后提出多层自动编码器深层结构[2]。此外LeCun等人提出的卷积神经网络是第一个真正意义上的多层结构学习算法,它利用空间相对关系减少参数数目以提高训练性能。Alex在2012年提出的AlexNet网络结构模型引爆了神经网络的应用热潮,并赢得了图像识别大赛的冠军,使得CNN成为在图像分类上的核心算法模型[1]。
在解决如何识别图像中的物体之前,我们还要知道是什么导致了卷积神经网络的发展?
1981年的诺贝尔医学奖,颁发给了 David Hubel(出生于加拿大的美国神经生物学家) 和Torsten Wiesel。1962年,他们的发现对当代深度学习模型最大的影响就是基于记录猫的单个神经元的活动。他们观察了猫的脑内神经元如何响应投影在猫前面屏幕上精确位置的图像,他们伟大的发现是提出了“感受野”的概念。1979年,日本学者Fukushima 在局部感受野的基础上提出了神经认知机模型,该模型被认为是实现的第一个卷积神经网络。1989年,LeCun等人首次使用了权值共享技术,设计了LeNet。1998年,LeCun等人又将卷积层和下采样层相结合,设计卷积神经网络的主要结构,形成了现代卷积神经网络的雏形LeNet 5[2]。2012年,卷积神经网络的发展取得了历史性的突破,Alex等人采用修正线性单元(Rectified Linear Unit,RELU)作为激活函数,并在大规模图像测评中远超第二名并获得冠军,这是一次在人工智能历史上的重要拐点。2016年3月在韩国打响的又一场世纪大战,则在全球范围内迅速引爆了人工智能的热潮,随着李世乭被使用深度学习算法的AlphaGo以4:1击败后,人工智能又一次进入了大众的视野。
卷积神经网络与其他机器学习方法不同的是引入了权值共享的机制。在处理图像数据时,由于图像的像素值以及使用全连接神经网络,得到的权值参数以及偏置会非常多,这不但影响了网络的处理速度,也使网络的泛化能力降低。以往的BP(Back Propagation)神经网络会由于神经元个数以及各种权值与偏置参数过多,导致训练速度慢的问题[3]。
典型的深层网络往往存在梯度消失和梯度爆炸的问题,也就是说,累积的反向传播误差信号在神经网络的层数增加时出现指数衰减或爆炸的现象,从而导致数值计算快速收缩或越界。深度神经网络正式发展于2006年,Hinton等人[2]发表了题为“A fast learning algorithm for deep belief nets”以及“Reducing the dimensionality of the data with neural networks”,在此之后,各种深度学习模型都相继发展起来,包括深度置信网络(DBN,Deep Belief Network)、循环神经网络(RNN,Recurrent Neural Network)以及卷积神经网络(CNN,Convolutional Neural Network)、长短时记忆网络(LSTM,Long Short-Term Memory Network)、生成对抗网络(GAN,Generative Adversarial Network)、残差神经网络(Residual Neural Network)以及图神经网络(GNN,Graph Neural Networks)等[4]。
2.基于卷积神经网络的AlexNet网络识别
2.1图像信息
AlexNet的图像数据均来自于由斯坦福大学的华裔科学家李飞飞(Fei-Fei Li)2010年正式组织并启动的大规模视觉图像识别赛(ImageNet Large Scale Visual Recognition Challenge , ILSVRC)的数据库ImageNet,另外一个比较著名的华人科学家吴恩达(Andrew Ng)创立了人工智能在线教育平台Coursera。该数据集包含 14,197,122张图片和21,841个Synset索引。 Synset是WordNet层次结构中的一个节点,它又是一组同义词集合[1]。

ImageNet数据集一直是评估图像分类算法性能的基准。ImageNet是一个按照WordNet层次结构(目前只有名词)组织的图像数据库,其中层次结构的每个节点都由成百上千个图像来描述。目前,我们平均每个节点有500多个图像。ImageNet数据集的意义:1.ImageNet拥有用于分类、定位和检测任务评估的数据。2.与分类数据类似,定位任务有1000个类别。准确率是根据最高五项检测结果计算出来的。 3.所有图像中至少有一个边框。对200个目标的检测问题有470000个图像,平均每个图像有1.1个目标[2]。
由于ImageNet中的数据太过庞大,数据超过1TB,所需要的算力非常大,训练时间非常长。所以我们使用对CIFAR进行测试,这个数据集是 Visual Dictionary(Teaching computers to recognize objects) 的子集,由Alex Krizhevsky、Vinod Nair和Geoffrey Hinton三个教授收集,主要来自Google和各类搜索引擎的图片[5]。

与MNIST数据集的灰度图片不同,CIFAR-10数据集由10类32x32的RGB彩色图片组成,一共包含60000张图片,每一类包含6000图片。其中50000张图片作为训练集,10000张图片作为测试集。
**
2.2Alex卷积神经网络详解
**
2012年,Alex使用卷积神经网络AlexNet夺得冠军,搭建了如下图所示的网络结构。
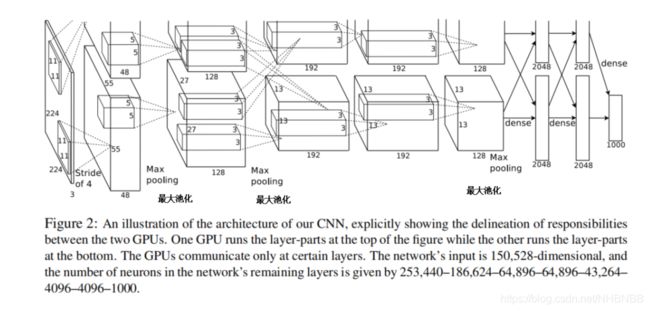
由图2-4可以看出,AlexNet有6000万个参数,65万个神经元,包含输入层、5个卷积层和3个全连接层。其中,有三个卷积层还做了最大池化操作。AlexNet各层的组织结构图如下表2.1所示,其中conv表示卷积运算操作,ReLU(Rectified Linear Unit)表示线性修正单元,pool表示池化操作,norm表示局部响应归一化,dropout表示丢失输出操作,IP表示全连接,Softmax表示归一化分类器,具体结构如下图2-5所示[1]。
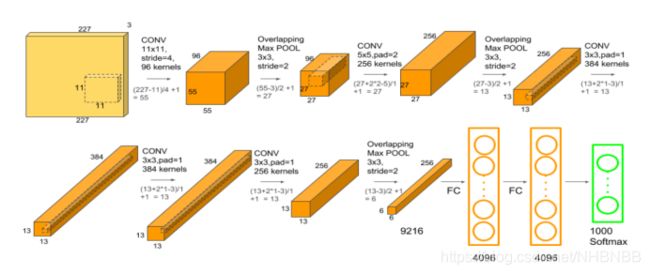

2.3卷积层
卷积(Convolution)是一种数学运算,它采用某种方式将一个函数“应用”到另一个函数,结果可以理解为两个函数的“混合体”。事实证明,卷积非常擅长检测图像中的简单结构,然后结合这些简单特征来构造更复杂的特征。在卷积网络中,会在一系列的层上发生此过程,每层对前一层的输出执行一次卷积。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。
权值全局共享机制是卷积神经网络的特点。图像是一种二阶或三阶字节数组,二阶数组包含宽度和高度2个维度,三阶数组有3个维度,包括宽度、高度和通道,所以灰度图是二阶的,而 RGB图是三阶的(包含3个通道)。字节的值被简单解释为整数值,描述了必须在相应像素上使用的特定通道数量[6]。所以在处理计算机视觉时,可以将一个图像想象为一个 2D 数字数组(对于RGB或RGBA图像,可以将它们想象为3个或4个2D数字数组的相互重叠),计算过程如下图2-6所示。
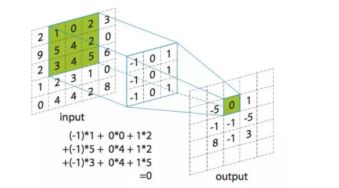
如果使用卷积核进行运算后,所得到的结果受到多个超参数因素影响:卷积核(kernel)或者叫过滤器(filter)的大小、步长(stride)以及Padding操作。对于CNN网络,一般来说,假设输入形状是 NhNw,卷积核窗口形状是 KhKw,那么输出形状将会是Nh-Kh+1Nw-Kw+1。所以卷积层的输出形状由输入形状和卷积核窗口形状决定。卷积层还有两个超参数,即填充和步长,它们可以对给定形状的输入和卷积核改变输出形状。
填充(padding)是指在输入高和宽的两侧填充元素(通常是0),具体的操作如下式2-1所示。

一般来说,如果在高的两侧一共填充Ph行,在宽的两侧一共填充 Pw列,那么输出形状将会是Nh-Kh+Ph+1Nw-Kw+Pw+1。这种操作称为Same,当没有填充时,称为Valid,Valid操作会丢弃图像边缘的所有剩余值,而且会使图像越来越小,在更深层的网络中不足以提取特征,这些特征叫做Feature Map。
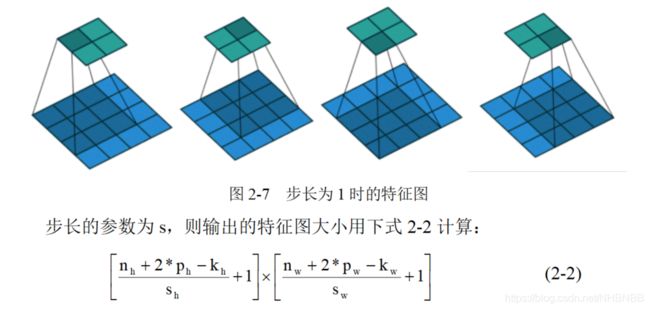
另一个超参数是步长(stride),代表同一个卷积窗口从输入数组的最左上方开始,按从左往右、从上往下的顺序,依次在输入数组上滑动。我们将每次滑动的行数和列数称为步长,当stride = 1时如下图2-7所示。
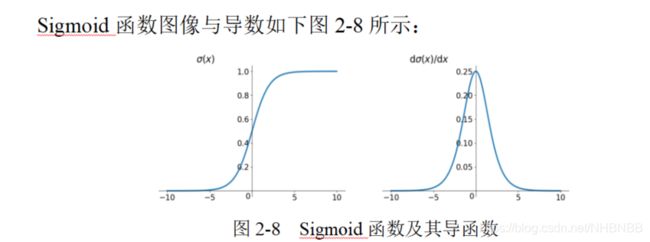
在神经网络中,当输入激励达到一定强度,神经元就会被激活,产生输出信号。模拟这一细胞激活过程的函数,就叫激活函数。卷积运算是线性操作,而神经网络要拟合的是非线性的函数,所以我们使用激活函数来进行非线性拟合。在AlexNet之前,神经网络(包括LeNet)一般都把激活函数选为Sigmoid或tanh。

Sigmoid函数是深度学习领域开始时使用频率最高的activation function。它是便于求导的平滑函数,其导数为,这是优点。然而,Sigmoid有三大缺点:
1.容易出现梯度消失gradient vanishing;
2.函数输出并不是零中心zero-centered;(虽然双边Sigmoid是零中心)
3.幂运算相对来讲比较耗时。
tanh读作Hyperbolic Tangent(双曲正切函数),如下图2-9所示,它虽然解决了zero-centered的输出问题,然而,gradient vanishing的问题和幂运算的问题仍然存在。

为了解决这些问题,Alex提出了另一种新的激活函数—ReLU(Rectified Linear Unit,线性修正单元)。

ReLU函数在现如今比较常用,它有以下特点:
1.解决了gradient vanishing问题;在(0—+∞)区间
2.计算速度非常快,只需要判断输入是否大于0;
3.收敛速度远快于sigmoid和tanh。
3.收敛速度远快于sigmoid和tanh。
Sigmoid 的导数只有在 0 的附近时有较好的激活性,而在正负饱和区域的梯度趋向于0, 从而产生梯度弥散的现象,而ReLU在大于0的部分梯度为常数,所以不会有梯度弥散现象。ReLU的导数计算的更快。ReLU在负半区的导数为0, 所以神经元激活值为负时,梯度为0, 此神经元不参与训练,具有稀疏性。ReLU是一种非饱和函数,在训练时间上比饱和函数更快。梯度消失现象相对较弱,有助于训练更深的网络[8]。
池化操作是对数据进行计算的过程,主要包括最大池化、平均池化。传统的池化窗口是没有重叠的,不同窗口的池化过程分别独立计算。如果设置 s
池化层也叫下采样层(subsampled),它具有以下特点:
1.降维,缩减模型大小,提高计算速度;
2.降低过拟合概率,提升特征提取鲁棒性;
3.对平移和旋转不敏感;
局部归一化(Local Response Normalization,简称LRN),为了改善卷积神经网络的性能,AlexNet还对某些层进行了局部响应归一化处理,在神经生物学有一个概念叫做“侧抑制”(lateral inhibitio),指的是被激活的神经元抑制相邻神经元。归一化(normalization)的目的是“抑制”,局部归一化就是借鉴了“侧抑制”的思想来实现局部抑制,尤其当使用 ReLU 时这种“侧抑制”很管用,因为 ReLU 的响应结果是无界的(可以非常大),所以需要归一化。使用局部归一化的方法有助于增加泛化能力,计算公式如式2-6所示。
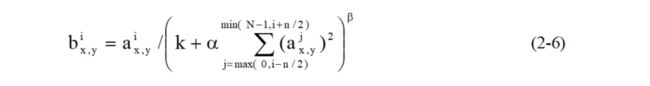
其中,N是卷积面(或池化面)的总数,n是相邻面的个数,k、α、β 是可调参数。当选用k = 2,n = 5,α = e-4 ,β = 0.75时,AlexNet利用局部响应归一化的技巧,可以将在ImageNet中top-1和top-5错误率分别降低了1.4%和1.2%[7]。
2.4全连接层
全连接层(Full Connected )的输入是一维向量,需要将Pooling 层的输出向量压平(Flatten)成一个一维的向量,然后输入到全连接层中,最后送到Softmax层进行分类。卷积神经网络为什么用卷积而不用全连接的原因之一就是:全连接计算量太大。全连接层就是一个线性特征映射的过程,将多维的特征输入映射为二维的特征输出,高维表示样本批次,低维常常对应任务目标(例如分类就对应每一个类别的概率)[8]。全连接层主要对特征进行重新拟合,减少特征信息的丢失;输出层主要准备做好最后目标结果的输出,全连接层的结构如下图2-12所示。

目前由于全连接层参数冗余(仅全连接层参数就可占整个网络参数80%左右),近期一些性能优异的网络模型如ResNet和GoogLeNet等均用全局平均池化(global average pooling,GAP)取代FC来融合学到的深度特征,最后仍用Softmax等损失函数作为网络目标函数来指导学习过程。需要指出的是,用GAP替代FC的网络通常有较好的预测性能[9]。
2.5减少过拟合
AlexNet约有6000万个参数,远远多于LeNet的参数。为了减少过拟合,AlexNet还使用了数据扩充和Dropout丢失数据的训练技巧。数据扩充(Data Augmentation)有两种方法:一是图像的平移和翻转,二是基于PCA的RGB强度调整。数据扩充可以使AlexNet的top-1误差率至少减少了1.0%。早期最常见的针对图像数据减少过拟合的方法就是人工地增大数据集[10],AlexNet中使用了两种增大数据量的方法:

在训练神经网络时,如果训练样本过少,一般就需要考虑采用某些正则化技巧来防止过拟合。Dropout(丢失输出),是一种简单有效的正则化技巧,其基本思想就是通过阻止特征检测器的共同作用来提高神经网络的泛化能力。
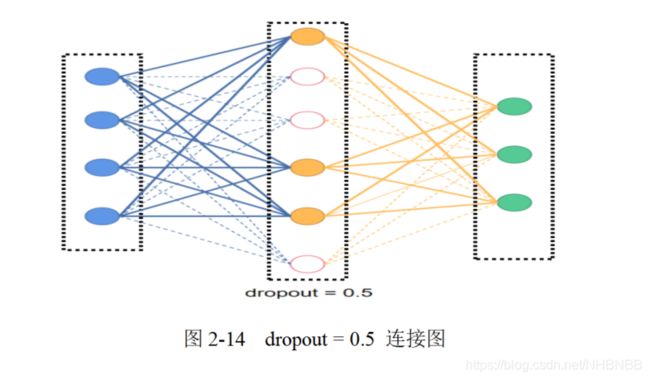
Dropout丢失输出是指在神经网络的训练过程中随机得让网络中的一些节点(包括输入和隐含层节点)不工作。那些不工作的网络节点可以暂时认为不是网络结构的一部分。引入Dropout主要是为了防止过拟合。在神经网络中Dropout通过修改神经网络本身结构来实现,对于某一层的神经元,通过定义的概率将神经元置为0,这个神经元就不参与前向和后向传播,就如同在网络中被删除了一样,同时保持输入层与输出层神经元的个数不变,然后按照神经网络的学习方法进行参数更新。在下一次迭代中,又重新随机删除一些神经元(置为0),直至训练结束。
Dropout是AlexNet中一个很大的创新,现在神经网络中的必备结构之一。Dropout也可以看成是一种模型组合,每次生成的网络结构都不一样,通过组合多个模型的方式能够有效地减少过拟合,Dropout只需要两倍的训练时间即可实现模型组合(类似取平均)的效果,非常高效[11],具体操作入下图2-14所示。
2.6使用双GPU训练
随着数据集越来越大,机器学习对图像处理的计算力需求逐步超越了CPU的性能水平,这导致图形处理器(Graphics Processing Unit ,GPU)得到了迅猛的发展。与CPU不同,GPU是专门执行复杂的数学和和几何计算而设计的。现在,GPU已经超越了3D图形处理的局限,被广泛用于浮点运算和并行运算,可以提供数十倍乃至上百倍的CPU的性能。早期的LeNet并没有使用GPU,而AlexNet使用了两个GPU来提升训练速度,分别放置一半卷积核(或神经元),并限制在某些层之间的GPU通信,如下图2-15所示。
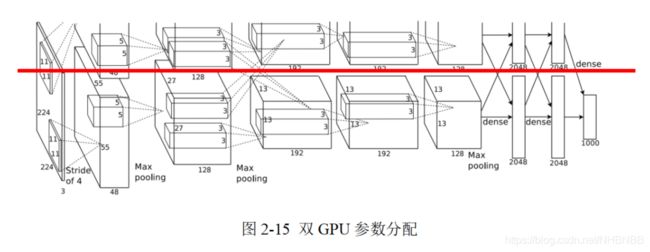
因为AlexNet训练时使用了两块GPU,因此这个结构图中不少组件都被拆成了两部分。现在我们GPU的显存可以放下全部模型数据,因此只考虑一块GPU的情况即可。
2.7块归一化(Batch Normalization)
块归一化(Batch Normalization),又称为批量归一化。对神经网络的训练过程进行块归一化,不仅可以提高网络的训练速度,还可以提高网络的泛化能力。块归一化可以理解为把对输入数据的归一化扩展到对其它层的输入数据进行归一化,以减小内部数据分布偏移(internal covariate shift)的影响。经过块归一化后,一方面可以通过选择比较大的初始学习率极大提升训练速度,另一方面还可以不用太关心初始化方法和正则化技巧的选择,从而减少对网络训练过程的人工干预[9]。
2.8参数初始化
AlexNet使用了mini-batch SGD,batch的大小为128,梯度下降的算法选择了momentum,动量衰减参数设置为0.9,加入了L2正则化,或者说权重衰减参数为0.0005。论文中提到这么小的权重衰减参数几乎可以说没有正则化效果,但对模型的学习非常重要,这里的权重衰减不仅仅是一个正规化器,同时它减少了模型的训练误差[10]。对于所有层都使用了相等的学习率,这是在整个训练过程中手动调整的。当验证误差率在当前学习率下不再降低时,就将学习率除以10[11]。学习率初始化为0.01,在训练结束前共减小3次。Alex训练该网络时大致将这120万张图像的训练集循环了90次,在两个NVIDIA GTX 580 3GB GPU上花了五到六天。另外,在AlexNet中所有层的权重初始化为服从0均值,标准差为0.001的高斯分布,第2、4、5卷积层以及全连接层的偏置量初始化为1,这样做的好处是它通过给ReLU函数一个正激励从而加速早期学习的速度,其他层的偏置量初始化为0[12]。
3.基于AlexNet的CIFAR-10识别模型搭建
3.1环境准备
本次模型搭建使用的是Windows10操作系统,10代i7酷睿8核处理器,GTX 1650Ti 16G显卡,Python 3.7.6语言环境,Anaconda 包管理系统,Spyder 编译器,安装了Tensorflow 2.0 深度学习开发框架,配合Keras 2.3.1搭建整个神经网络。
3.2导入库
在编程之前需要导入需要的库和模块。由于Keras已经被集成在Tensorflow中,我们直接导入Tensorflow下的keras模块包。CIFAR数据集也被Keras收录,就直接导入。数据集共有60000张图片,我们将随即取出50000张作为训练集,10000张作为测试集。
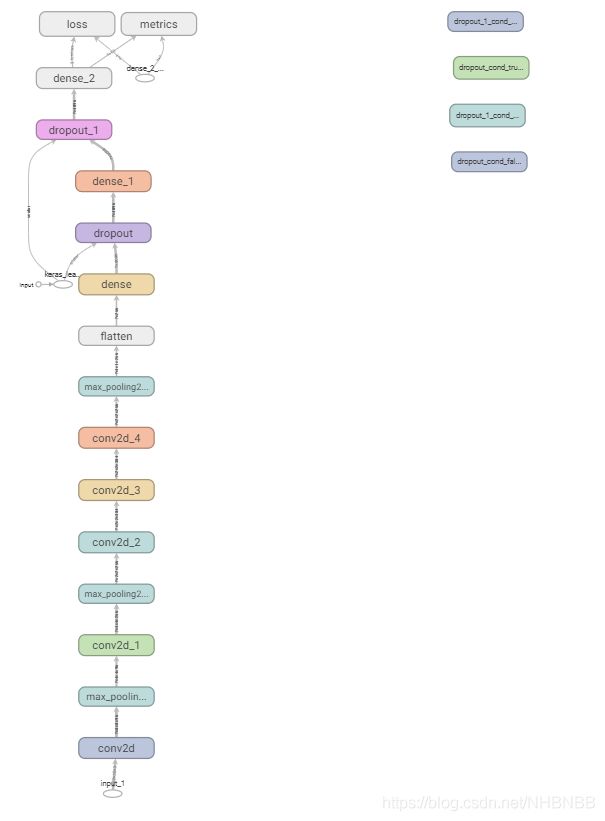
3.3模型搭建
通过借鉴AlexNet网络,我们搭建了模型如下图3-1所示。
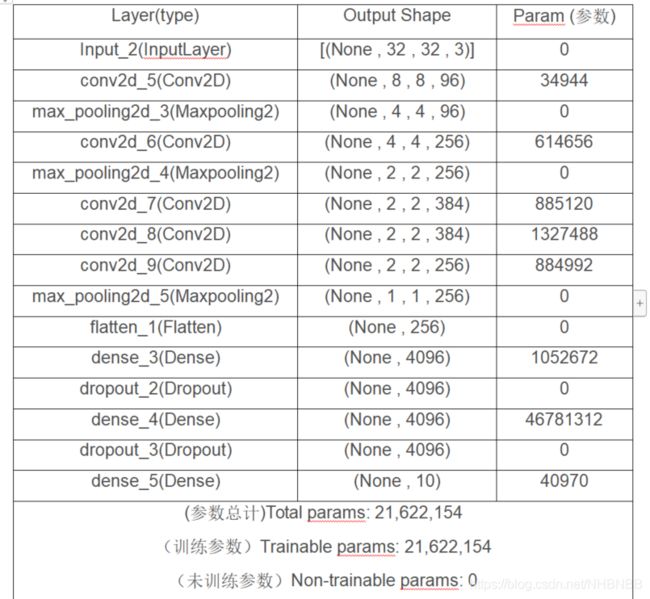
共有21622154个参数进行训练,经过6个小时的训练,模型就可以训练好了。
4.结论
本文主要讲解了AlexNet的模型结构与功能创新,并利用Tensorflow 搭建了Alex模型,在CIFAR数据集上进行了训练,具体的模型保存在model中,在训练集中的准确率达到了99.64%,loss减小到0.012;在测试集中的准确率达到了75.86%,loss减小到1.5897。使用TensorBoard对训练过程进行可视化。
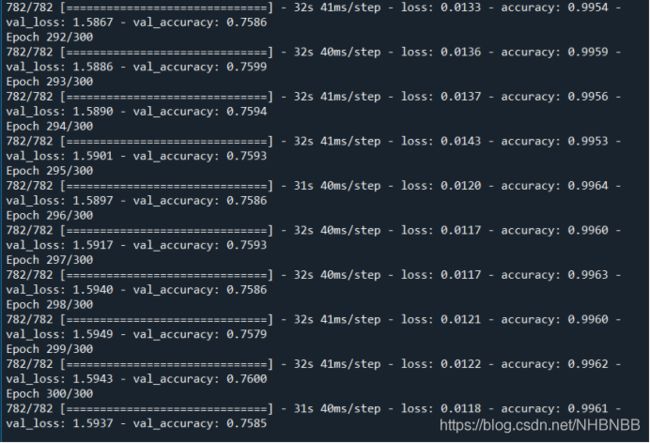
经过300次epoch的准确率
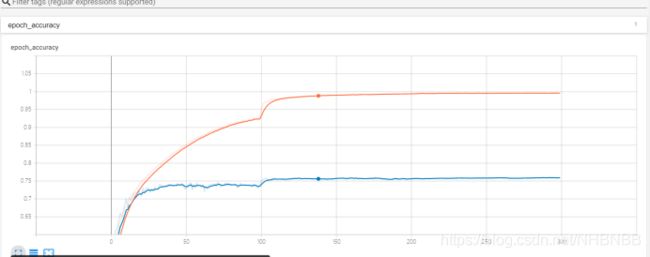
训练集与测试集的准确率变化
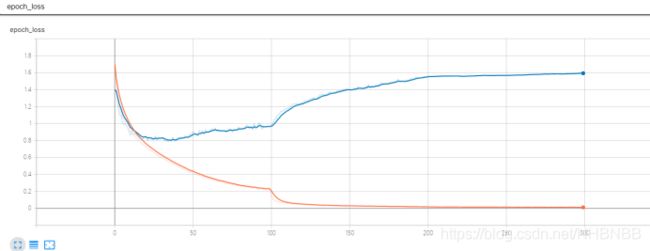
训练集与测试集的loss损失变化
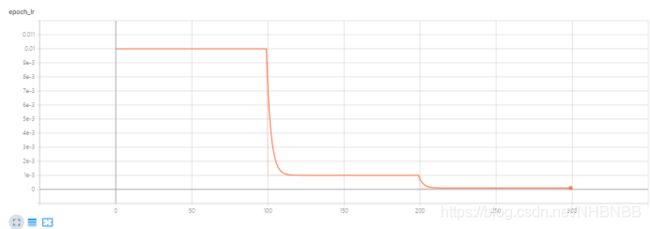
学习率变化
AlexNet结构图
参考文献
[1]Alex Krizhevsky,Ilya Sutskever,Geoffrey E. Hinton. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM,2017,60(6).
[2]Ian Goodfellow,Yoshua Bengio ,Aaron Courville. Deep learning [M]. MIT press, 2016.
[3]LeCun, Yoshua Bengio, Boser, B., Denker, J.S., Henderson, D., Howard, R.E., Hubbard, W. and Jackel, L.D., 1989. Backpropagation applied to handwritten zip code recognition. Neural computation, 1(4), pp.541-551.
[4]Francois Chollet. Deep Learning With Python [M].MIT press, 2017.