python爬取网站图片(尽力在讲解)
1.首先,先导入两个库(一个就是常用的reques库,另一个就是BeautiSoup库)
import requests
from bs4 import BeautifulSoup2.确定你要爬取的网页
本例子中爬取的网页是
https://www.dpm.org.cn/lights/royal.html(来自夜曲编程,写这篇博客是来复习的,也希望获得启发,毕竟有人在网上说过,爬虫也只是能爬取教过的网页。感觉爬虫好难啊。)
3.设置反爬虫
通过设置headers(当然设置发爬虫还可以限制爬取频率来限制,让服务器认为你是一个人类,哈哈!(time.sleep(2)))
打开网页后,按f12,查看网络的第一个文件,无论第一个文件叫什么,都是打开第一个文件,然后查看他的user-agent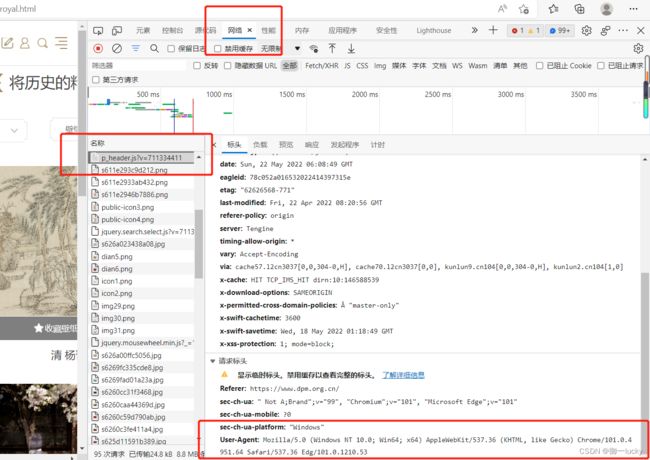
4.查看网页的页数规律
也就是查看第一页的图片是什么链接,第二页是什么,第三页,第四页,他们之间有什么规律和差别。
可以把鼠标放在页码序号哪里,右侧就会出现图中右侧序号的页面。(把鼠标轻触右侧的红框里的链接,就会出现完整的网页链接。)
第一页的网页链接就是:
https://www.dpm.org.cn/lights/royal/p/1.html
第二页:
https://www.dpm.org.cn/lights/royal/p/2.html
第三页:
https://www.dpm.org.cn/lights/royal/p/3.html
5.用requests库请求网页
response=requests.get(url,headers=headers)
headers=headers是把你的爬虫伪装成用户去读取数据
6.将读取的内容转换成文本
html=response.text7.解析
soup=BeautifulSoup(html,"lxml")8.寻找节点
content_all=soup.find_all(class_="pic")个人觉得这是一个十分难的工作,过几天会出一个本网页的节点寻找方法,我是不会找的。
9.寻找每一个图片的节点
imgContent=content.find(name="img")图片节点
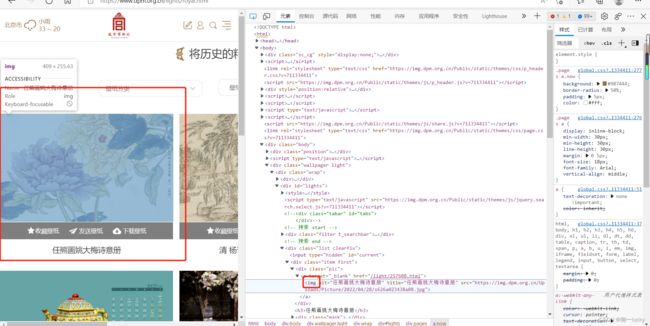
10.找每一个图片的链接并请求
imgUrl=imgContent.attrs["src"]#一页网页中每个图片的链接
imgResponse=requests.get(imgUrl)
img=imgResponse.content11.写入文件
with open(f"E:/bc/pythonProject/lianxi/{imgName}.jpg","wb")as f:
f.write(img)建议将文件路径写的越全越好
以下是全部代码
import requests
from bs4 import BeautifulSoup
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36 Edg/101.0.1210.53"}
#url="https://www.dpm.org.cn/lights/royal.html"
imgName=0
for page in range(1,4):
url=f"https://www.dpm.org.cn/lights/royal/p/{page}.html"
response=requests.get(url,headers=headers)
html=response.text
soup=BeautifulSoup(html,"lxml")
content_all=soup.find_all(class_="pic")
for content in content_all:
imgContent=content.find(name="img")
imgName=imgName+1
imgUrl=imgContent.attrs["src"]#一页网页中每个图片的链接
imgResponse=requests.get(imgUrl)
img=imgResponse.content
#print(imgUrl)
with open(f"E:/bc/pythonProject/lianxi/{imgName}.jpg","wb")as f:
f.write(img)
写在最后,我感觉找节点还是很难,呜呜,希望哪个大佬能指点我一下。本博客仅代表我的个人看法,本人初学者一枚,有问题还请不吝赐教。