Hive数据仓库工具基本架构和入门部署详解
文章目录
- 概述
-
- 定义
- 本质
- 特点
- Hive与Hadoop关系
- Hive与关系型数据库区别
- 优缺点
- 其他说明
- 架构
-
- 组成部分
- 数据模型(Hive数据组织形式)
- Metastore(元数据)
- Compiler(编译器)
- Optimizer(优化器)
- 安装
-
- 内嵌模式
- 本地 MetaStore
- 远程 MetaStore
-
- hiveserver2
- metastore
概述
定义
Hive 官网 https://hive.apache.org/
Hive 官网Wiki文档 https://cwiki.apache.org/confluence/display/Hive/
Hive GitHub源码地址 https://github.com/apache/hive
Apache Hive™数据仓库软件使用SQL对分布式存储中的大型数据集进行读写和管理,结构可以映射到已存储的数据上,也提供命令行工具和JDBC驱动连接用户到Hive。目前最新版本为3.1.3
Hive由Facebook开源用于解决海量结构化日志的数据统计,基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成一张表,并且提供类SQL的查询功能,这套Hive SQL简称HQL。Hive仅仅是一个工具,本身不存储数据只提供一种管理方式,同时也不涉及分布式概念;Hive不是为在线事务处理(OLTP)工作负载而设计的,它最适合用于对数据仓库进行统计分析。
本质
Hive本质就是MapReduce,将类SQL(HQL)转换成MapReduce程序,减少编写MapReduce的复杂度,MapReduce对用户来说虽然灵活,但需要用户自己实现功能接口,不像Spark高层级应用提供各种算子操作。hive支持了三种底层计算引擎包括mr、tez、spark,默认计算引擎mr,用户可以指定具体使用哪个底层计算引擎(set hive.execution.engine=mr/tez/spark),当前前提得先完成Spark整合或安装tez。
特点
- Hive提供了标准的SQL功能,通过SQL轻松访问数据的工具,从而支持数据仓库任务,如提取/转换/加载(ETL)、报告和数据分析。
- 一种将结构强加于各种数据格式的机制。
- 访问直接存储在Apache HDFS™或其他数据存储系统(如Apache HBase™)中的文件。
- 通过Apache Tez™、Apache Spark™或MapReduce执行查询。
- 使用HPL-SQL的过程语言。
- 通过Hive LLAP, Apache YARN和Apache Slider实现亚秒查询检索。
Hive与Hadoop关系
- Hive是基于Hadoop的。
- Hive本身其实没有多少功能,hive就相当于在Hadoop上⾯加了⼀个外壳,就是对hadoop进⾏了⼀次封装。
- Hive的存储是基于HDFS的,hive的计算是基于MapReduce。
Hive与关系型数据库区别
- Hive和关系型数据库存储文件的系统不同, Hive使用的是HDFS(Hadoop的分布式文件系统),关系型数据则是服务器本地的文件系统。
- Hive使用的计算模型是MapReduce,而关系型数据库则是自己设计的计算模型。
- 关系型数据库都是为实时查询业务设计的,而Hive则是为海量数据做挖掘而设计的,实时性差;实时性的区别导致Hive的应用场景和关系型数据库有很大区别。
- Hive很容易扩展自己的存储能力和计算能力,这也是其寄托在Hadoop本身的优势,而关系型数据库在这方面要比Hive差很多。
优缺点
- 优点
- 学习成本低:提供了类SQL查询语⾔HQL,使得熟悉SQL语⾔的开发⼈员⽆需关⼼细节,可以快速上⼿。
- 海量数据分析:底层是基于海量计算到MapReduce实现。
- 可扩展性:为超⼤数据集设计了计算/扩展能⼒(MR作为计算引擎,HDFS作为存储系统),Hive可以⾃由的扩展集群的规模,⼀般情况下不需要重启服务。
- 延展性:Hive⽀持⽤户⾃定义函数,⽤户可以根据⾃⼰的需求来实现⾃⼰的函数。包括用户定义函数(udf,一行输入对应一行输出,类似map)、用户定义聚合(UDAFs,多行输入对应一行输出类似sum聚合函数)和用户定义表函数(udtf,一行输入对应多行输出,类似explore)来扩展用户代码。
- 良好的容错性:某个数据节点出现问题HQL仍可完成执⾏。
- 统计管理:提供了统⼀的元数据管理。
- 缺点
- Hive的HQL表达能⼒有限 。
- 迭代式算法⽆法表达。
- Hive的效率⽐较低。
- Hive⾃动⽣成的MapReduce作业,通常情况下不够智能化。
- Hive调优⽐较困难,粒度较粗。
其他说明
-
Hive数据存储没有单一的“Hive格式”。Hive内置了逗号和制表符分隔值(CSV/TSV)文本文件、Apache Parquet™、Apache ORC™和其他格式的连接器。用户可以为Hive扩展其他格式的连接器。
-
Hive支持文件格式和压缩:RCFile、Avro、ORC、Parquet、Compression、 LZO。
-
Hive的组件包括HCatalog和WebHCat
- HCatalog是Hadoop的一个表和存储管理层,它允许用户使用不同的数据处理工具(包括Pig和MapReduce)更容易地读写网格上的数据。
- WebHCat提供了一个服务,您可以使用它来运行Hadoop MapReduce(或YARN)、Pig、Hive任务。也可以通过HTTP (REST风格)接口对Hive元数据进行操作。
架构
组成部分
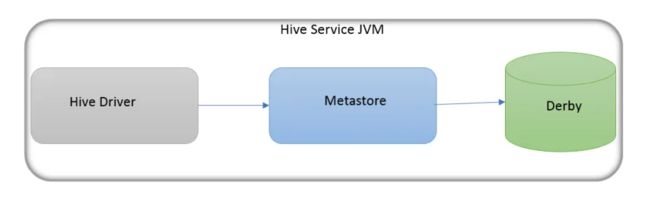
下图包含了Hive的主要组件及其与Hadoop的交互。Hive的主要组件有:
- UI(用户界面):用户向系统提交查询和其他操作的用户界面。包括Shell命令⾏ JDBC/ODBC:是指Hive的JAVA实现,与传统数据库JDBC类似。 WebUI:是指可通过浏览器访问Hive。
- DRIVER(驱动):接收查询的组件,该组件实现了会话连接管理,并提供了以JDBC/ODBC接口为模型的执行和获取api。
- Compiler(编译器):解析查询对不同的查询块和查询表达式进行语义分析,并最终在metastore中查找的表和分区元数据的帮助下生成执行计划。
- Metastore(元数据):存储仓库中各种表和分区的所有结构信息的组件,包括列和列类型信息,读写数据所需的序列化器和反序列化器,以及存储数据的对应HDFS文件。Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括(表名、表所属的数据库名、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在⽬录等),如果规模大还可以存储TiDB分布式关系型数据库。

- Execution Engine(执行引擎):执行编译器创建的执行计划的组件。这个计划是一个分阶段的DAG。执行引擎管理计划的这些不同阶段之间的依赖关系,并在适当的系统组件上执行这些阶段。例如将优化后的执⾏计划提交给hadoop的yarn上执⾏提交job。

- UI调用驱动程序的执行接口(图1中的步骤1)。
- 驱动程序为查询创建会话句柄,并将查询发送到编译器以生成执行计划(步骤2)。
- 编译器从元存储中获取必要的元数据(步骤3和4)。
- 该元数据用于对查询树中的表达式进行类型检查,并根据查询谓词修剪分区。编译器生成的计划(步骤5)是阶段的DAG,每个阶段都是映射/还原作业、元数据操作或HDFS操作。对于map/reduce阶段,计划包含map操作符树(在映射器上执行的操作符树)和reduce操作符树(用于需要reducer的操作)。
- 执行引擎将这些阶段提交给适当的组件(步骤6、6.1、6.2和6.3)。在每个任务(映射器/还原器)中,与表或中间输出关联的解串器用于从HDFS文件中读取行,这些行通过关联的运算符树传递。生成输出后,通过序列化程序将其写入临时HDFS文件(如果操作不需要reduce,则会在映射器中发生)。临时文件用于向计划的后续映射/还原阶段提供数据。对于DML操作,最终的临时文件将移动到表的位置。该方案用于确保不读取脏数据(文件重命名是HDFS中的原子操作)。
- 对于查询,执行引擎直接从HDFS读取临时文件的内容,作为来自驱动程序的提取调用的一部分(步骤7、8和9)。
数据模型(Hive数据组织形式)
- Table(表):这些类似于关系数据库中的表。可以对表进行筛选、投影、联接和联合。另外,一个表的所有数据都存储在HDFS的一个目录中。Hive还支持外部表的概念,通过为表创建DDL提供适当的位置,可以在HDFS中预先存在的文件或目录上创建表。表中的行被组织成类似于关系型数据库的类型化列
- Partition(分区):每个表可以有一个或多个分区键来决定数据的存储方式,例如一个带有日期分区列ds的表T有一些特定日期的文件存储在HDFS的< Table location>/ds=目录中。进一步加快数据检索效率。
- Buckets(桶):每个分区中的数据可以根据表中某个列的哈希值依次划分为Buckets。每个桶以文件的形式存储在分区目录中。bucket可以高效地评估依赖于数据样本的查询(如使用表上的sample子句查询)。
Metastore(元数据)
- Metastore是一个具有数据库或文件支持存储的对象存储,数据库支持的存储利用对象关系映射(ORM)实现,将其存储在关系数据库中的主要是用于元数据的查询。MetaSore 是 Hive 元数据存储的地方。Hive 数据库、表、函数等的定义都存储在 MetaStore 中。根据系统配置方式,统计信息和授权记录也可以存储在这。Hive 或者其他执行引擎在运行时可以使用这些数据来确定如何解析,授权以及有效执行用户的查询。MetaStore 分为两个部分:服务和后台数据的存储。
- Metastore提供了一个可选组件Thrift接口来操作和查询配置单元元数据,Thrift提供了许多流行语言包括Java、C++、Ruby的绑定,可以通过编程的⽅式远程访问Hive;第三方工具可以使用此接口将配置单元元数据集成到其他业务元数据存储库中。
Compiler(编译器)
编译器对hql语句进⾏词法、语法、语义的编译(需要跟元数据关联),编译完成后会⽣成⼀个执⾏计划。hive上就是编译成mapreduce的job
- 解析器:将查询字符串转换为解析树表示。将HQL字符串转换成抽象语法树AST,这⼀步⼀般都⽤第三⽅⼯具库完成,⽐如 antlr;对AST进⾏语法 分析,⽐如表是否存在、字段是否存在、SQL语义是否有误。
- 语义分析器:将解析树转换为内部查询表示,它仍然是基于块的,而不是运算符树。作为该步骤的一部分,将验证列名并执行类似*的扩展。在此阶段还执行类型检查和任何隐式类型转换。例如分区表则会收集该表的所有表达式,以便以后可以使用它们来修剪不需要的分区。如果查询指定了采样,则也会收集该采样以供后续使用。
- 逻辑计划生成器:将内部查询表示转换为逻辑计划,该计划由运算符树组成。一些运算符是关系代数运算符,如“filter”、“join”等。但一些运算符是特定于配置单元的,稍后将用于将此计划转换为一系列映射还原作业。一个这样的算子是发生在映射-还原边界处的还原链接算子。这一步还包括优化器转换计划以提高性能——其中一些转换包括:将一系列连接转换为单个多路连接,对分组依据执行映射端部分聚合,分两个阶段执行分组依据,以避免在分组密钥存在倾斜数据时,单个缩减器可能成为瓶颈的情况。每个运算符包括一个描述符,该描述符是可序列化对象。
- 查询计划生成器(物理计划):将逻辑计划转换为一系列映射缩减任务。操作符树被递归遍历,被分解为一系列map-reduce可序列化任务,这些任务可以稍后提交给Hadoop分布式文件系统的map-reduce框架。ReduceLink操作符是映射-还原边界,其描述符包含还原键。ReduceLink描述符中的缩减键用作映射缩减边界中的缩减密钥。如果查询指定,则计划包含所需的样本/分区。计划被序列化并写入文件。
Optimizer(优化器)
将执⾏计划进⾏优化,减少不必要的列、使⽤分区、使⽤索引等,优化job。
- 优化器将执行更多的计划转换。优化器是一个不断发展的组件。列修剪和谓词下推、mapjoin。
- 优化器可以增强为基于CBO(Cost-based optimization in Hive)。输出表的排序性质也可以保留,查询可以在小样本数据上执行以猜测数据分布,可以用于生成更好的执行计划。
安装
Hive的安装方式或者说是MetaStore安装 分为三种部署模式:内嵌模式、本地模式以及远程模式。Hive自动监测是否有Hadoop的环境变量。
# 下载hive最新版本3.1.3
wget --no-check-certificate https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
# 解压
tar -xvf apache-hive-3.1.3-bin.tar.gz
# 进入目录
cd apache-hive-3.1.3-bin
内嵌模式
默认情况下,MetaStore 服务和 Hive 服务运行在同一个 JVM 中,包含一个内嵌的以本地磁盘作为存储的 Derby 数据库实例。使用内嵌的 MetaStore 是 Hive 入门最简单的方法。但是每次只有一个内嵌的 Derby 数据库可以访问某个磁盘上的数据库文件,这就意味着一次只能为每个 MetaStore 打开一个 Hive 会话。如果试着启动第二个会话,在它试图连接 MetaStore 时,会得到错误信息。因此它并不是一个实际的解决方案,并不适合在生产环境使用,常用于测试。
- 优点:使用简单,不用进行配置。
- 缺点:只支持单Session。Session可以简单的理解为同一路径下不允许开两个hive。
# 配置环境变量
vi /etc/profile
export HIVE_HOME=/home/commons/apache-hive-3.1.3-bin
export PATH=$HIVE_HOME/bin:$PATH
# 生效环境变量
source /etc/profile
# 配置hive-env环境变量
cp conf/hive-env.sh.template conf/hive-env.sh
vi conf/hive-env.sh
export HADOOP_HOME=/home/commons/hadoop
export HIVE_CONF_DIR=/home/commons/apache-hive-3.1.3-bin/conf
export HIVE_AUX_JARS_PATH=/home/commons/apache-hive-3.1.3-bin/lib
# 复制hive-default.xml
cp conf/hive-default.xml.template conf/hive-site.xml
# 替换{system:java.io.tmpdir}
vi conf/hive-site.xml
# 在vi里替换,一共替换4处地方,4 substitutions on 4 lines
:%s#${system:java.io.tmpdir}#/home/commons/apache-hive-3.1.3-bin/iotmp#g
# 在vi里替换,一共替换3处地方,3 substitutions on 3 lines
:%s#${system:user.name}#root#g
# 初始化derby元数据
schematool -initSchema -dbType derby

# 找到3215行的位置,将description整行内容删除保存
vi conf/hive-site.xml

重新执行初始化后显示完成

初始化完后会在执行初始化脚本当前路径生成metastore_db的目录,hive内嵌模式启动就是读当前路径下这个目录,这也意味着在其他目录执行hive就没法共享内嵌Derby元数据信息。
本地 MetaStore
如果要支持多会话(以及多租户),需要使用一个独立的数据库。这种配置方式成为本地配置,因为 MetaStore 服务仍然和 Hive 服务运行在同一个进程中,但连接的却是另一个进程中运行的数据库,在同一台机器上或者远程机器上。对于本地模式来说客户端和服务端在同一个节点上,启动hive后自动启动元数据服务并连接。
- 优点:支持多Session。
- 缺点:需要配置,还需要关系数据库如MySQL。

在本地模式下不需要配置 hive.metastore.uris,默认为空表示是本地模式。如果选择 MySQL 作为 MetaStore 存储数据库,需要提前将 MySQL 的驱动包拷贝到 $HIVE_HOME/lib目录下。JDBC 连接驱动类视情况决定选择 com.mysql.cj.jdbc.Driver 还是 com.mysql.jdbc.Driver。
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.50.95:3308/hive_meta?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
然后执行初始化操作,初始化成功后查看hive_meta数据库自动创建且有相关表

show databases;后显示数据有default默认数据库了

远程 MetaStore
hiveserver2
将hive中的相关进程比如hiveserver2或者metastore这样的进程单独开启,使用客户端工具或者命令进行远程连接这样的服务。即远程模式。客户端可以在任何机器上,只要连接到这个server,就可以操作,客户端可以不需要密码。

修改hadoop的core-site.xml
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
# 启动hiveserver2
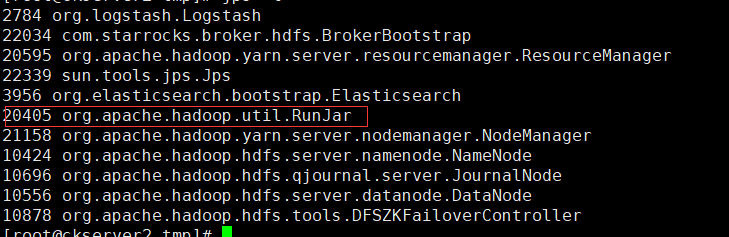
hive --service hiveserver2 &
查看进程和上面执行hive可执行文件的进程都是org.apache.hadoop.util.RunJar
# 将hive目录发送其他机器上
scp -r ../apache-hive-3.1.3-bin hadoop1:/home/commons
# 修改hive-site.xml内容
vi hive-site.xml
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop2</value>
<description>Bind host on which to run the HiveServer2 Thrift service.</description>
</property>
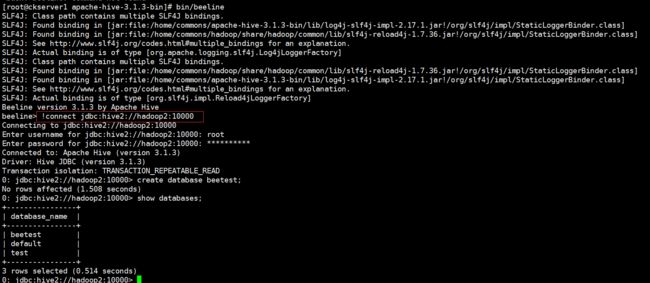
# 启动beeline客户端
bin/beeline
# 连接jdbc,用户名和密码就是你启动hiveserver2机器用户名密码
!connect jdbc:hive2://hadoop2:10000
metastore
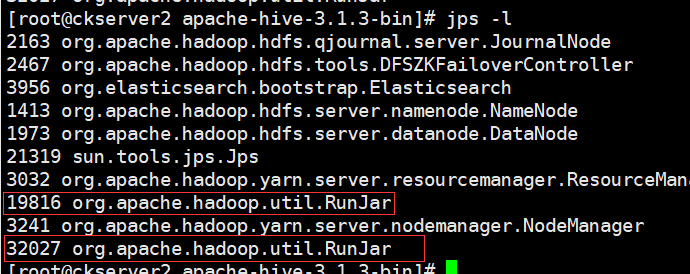
# 启动metastore
hive --service metastore &
启动后查看进程可以看到比刚才增多一个RunJar进程
修改hive-site.xml内容
vi hive-site.xml hive.metastore.uris thrift://hadoop2:9083 Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.
# 执行hive就可以连接到远程9083的元数据服务bin/hive
**本人博客网站 **IT小神 www.itxiaoshen.com