Graphviz绘制模型树2——XGBoost模型的可解释性
从二分类模型中的树重新理解XGBoost算法
- 一.对绘制的树简单解释
-
- 1.1类别判断
- 1.2树的最大层级
- 1.3效果较差情况
- 二.从数据来解释一棵树
-
- 2.1EXCEL构建第1颗树
- 2.2第1棵树的数据解释
- 2.3效果较差的节点解释
- 三.N颗树如何预测样本
-
- 3.1样本22数据
- 3.2样本22落入叶子情况
- 3.3样本22的总结
- 四.Excel构建可用于预测的模型
-
- 4.1EXCEL构建模型
- 4.2验证数据带入模型
- 4.3树的叶子节点分值为什么能相加
- 五.总结
背景介绍:
本文是 XGBoost模型调参、训练、评估、保存和预测文章的后续。接文章 XGraphviz绘制模型树1——软件配置与XGBoost树的绘制仍以二分类问题为例,从绘制的模型树着手重新理解XGBoost模型。
百度网盘提取本文数据和完整脚本(提取码:54ul)
一.对绘制的树简单解释
本文树的绘制接Graphviz绘制模型树1——软件配置与XGBoost树的绘制,这里共绘制了10颗树,树的最大深度为5。
1.1类别判断
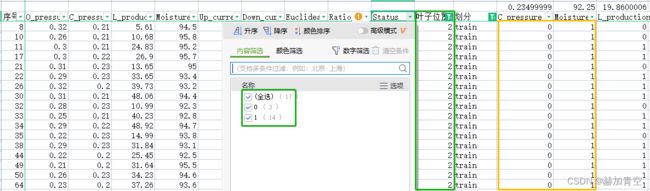
图1-1和图1-2所示,蓝色圆边为条件节点,棕色方边为叶子节点。二分类问题中,一个最底层的条件节点的两个叶子节点权值总是一正一负出现的,正的一方判断为1,负的一方判断为0。
图1-1:num_trees=0即第1颗树,默认绘制第1颗树

1.2树的最大层级
图1-2蓝色条件节点的最大层数由树的最大深度max_depth决定,本文模型采用max_depth=5。
图1-2:num_trees=8即第5颗树,树的深度为3

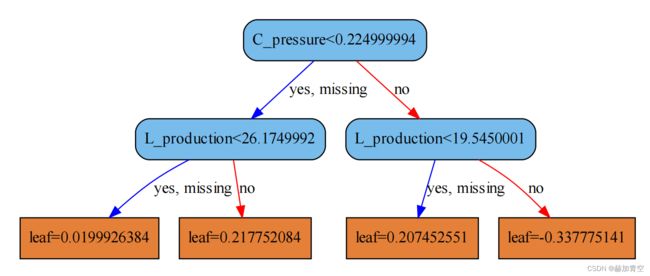
1.3效果较差情况
图1-3特殊情况也有两个叶子节点方向相同的情况出现,此时必有leaf绝对值较小的叶子样本分类分不开。
图1-3:num_trees=1即第2颗树,叶子节点1效果差
不明白可以先继续往下看,看数据一目了然。
二.从数据来解释一棵树
这里是在模拟XGBooxt模型训练的过程中数据落入树节点的情况,所以仅用训练集数据来验证节点结论。
# 打印训练数据和验证数据的索引
print('训练集数据index:', list(X_train.index))
print('验证集数据index:', list(X_test.index))
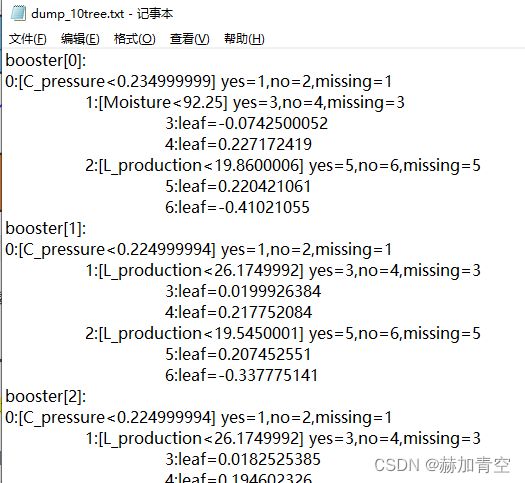
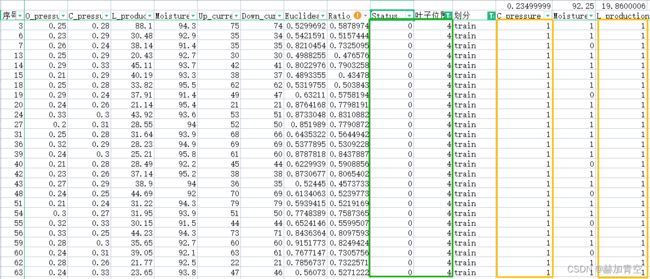
运行完脚本后,各节点信息可以从dump.txt文件中获取(将模型保存为了文本格式),下图展示部分树:第1颗树为例 编号booster[0],根据最顶端根节点0的条件划分为1和2两个条件节点,再根据两个条件节点分别划分了编号为3,4,5,6的叶子节点,叶子节点带有结果权值(其中missing是对缺失值的划分标准)。第1颗树为例 编号booster[1]…理解方式均相同,不再赘述。
2.1EXCEL构建第1颗树
下图为EXCEL构建第1颗树的部分内容:
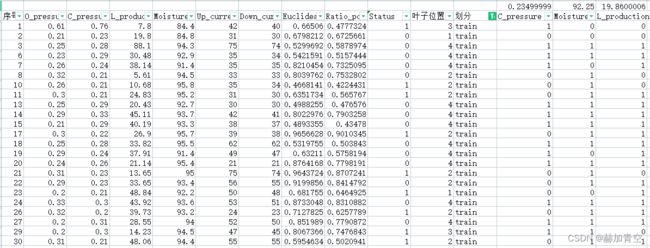
- 首先,需要区分出训练集和验证集,两个数据集构建时一起构建、验证时分开验证;
- 然后,已序号1的样本为例
=IF(C4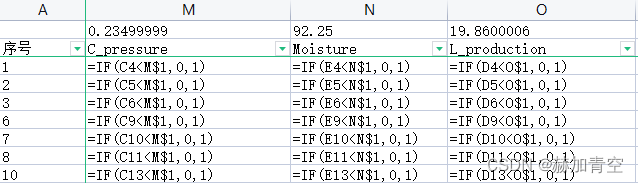
- 最后,根据树的条件,将每个样本划分到对应的叶子节点

这个过程可能稍麻烦了些,关于EXCEL构建的10颗树、整体模型和树的图片内容在XGBoost模型调参、训练、评估、保存和预测的百度网盘链接,这里建议先按我的文章思路走,能减少弯路。
2.2第1棵树的数据解释
图1-1为例:
叶子节点1:leaf=-0.0742500052
条件:C_pressure<0.234999999 and Moisture<92.25
结果:{0:3,1:1},叶子节点1预测为0,样本序号23判断错误

叶子节点2:leaf=0.227172419
条件:C_pressure<0.234999999 and Moisture>=92.25
结果:{0:3,1:14},叶子节点2预测为1,3个样本判断错误
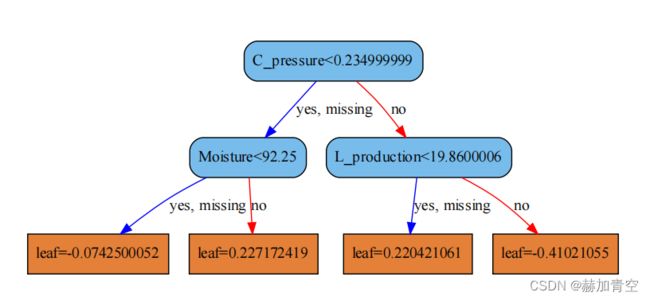
叶子节点3:leaf=0.220421061
条件:C_pressure>=0.234999999 and L_production<19.8600006
结果:{1:7},叶子节点3预测为1,0个样本判断错误

叶子节点4:leaf=-0.41021055
条件:C_pressure>=0.234999999 and L_production>=19.8600006
结果:{0:26},叶子节点4预测为0,0个样本判断错误
综上,图1-1这个XGBoost模型的第1棵树(共n_estimators棵树)已用训练样本数据解释清楚,树1分类的效果还不错。
2.3效果较差的节点解释
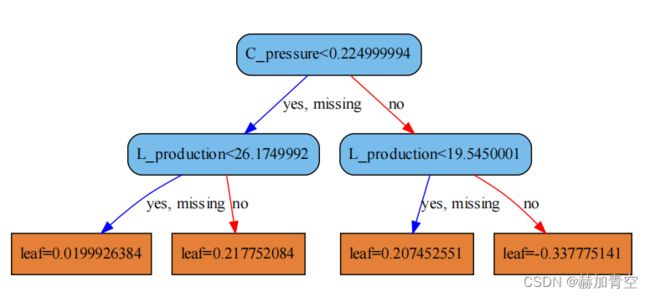
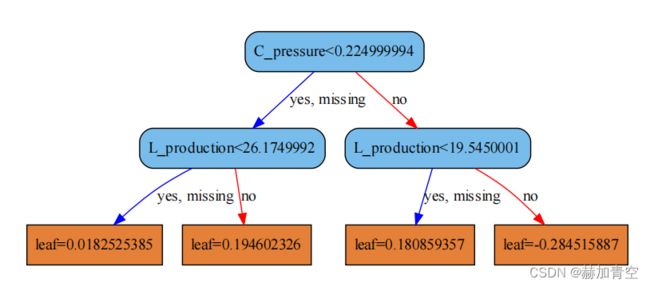
图1-3所示第2颗树,叶子节点1和2方向相同特殊情况说明:
叶子节点1:leaf=0.0199926384
条件:C_pressure<0.224999994 and L_production<26.1749992
结果:{0:2,1:3},叶子节点1预测为1,2个样本判断错误

叶子节点2:leaf=0.217752084
条件:C_pressure<0.224999994 and L_production>=26.1749992
结果:{1:8},叶子节点1预测为1,0个样本判断错误

综上,图1-3这个XGBoost模型的第2棵树叶子节点1未分开两个类的数据。第2棵树叶子节点1分值leaf=0.0199926384较小,在10颗中最终的贡献也就较小。
三.N颗树如何预测样本
众所周知,XGBoost属于Boosting模型,即同质集成算法的加法模型。
3.1样本22数据
这里以样本22为例解释XGBoost模型整合10颗树的过程,样本22实际类别为0。
序号 22
划分 train
O_pressure 0.29
C_pressure 0.23
L_production 33.65
Moisture 93.4
Up_current 56
Down_current 55
Euclidean_distance 0.919985631
Ratio_power_reference 0.841479165
Status 0
3.2样本22落入叶子情况
第1颗树判断样本22落入叶子节点2,leaf=0.227172419,树1的判断为:0.227172419>0,预测为1
第2颗树判断样本22落入叶子节点4,leaf=-0.337775141,树1+树2的判断为:0.227172419+(-0.337775141)=-0.110602722<0,预测为0
第3颗树判断样本22落入叶子节点4,leaf=-0.284515887,树1~树3的判断为:0.227172419+(-0.337775141)+(-0.284515887)=-0.395118609<0,预测为0
…依次类推,此处省去树4~9
第10颗树判断样本22落入叶子节点3,leaf=-0.15735659,树1~树10的判断为:0.227172419+(-0.337775141)+(-0.284515887)+(-0.640970677)+(-0.856471181)+(-1.061422601)+(-0.89972618)+(-1.071646152)+(-1.135751551)+(-0.15735659)=-1.293108141<0,预测为0

3.3样本22的总结
综上,在10颗最大深度为5的树组成的XGBoost模型中,复现了序号为22的样本的预测过程,最终预测结果为落入10颗树叶子节点对应的分值的总和-1.293108141,最终值小于0即,预测为0。第1课树判断错误,从第2颗树开始即判断正确,经过10颗树的不断修正,最终确定了样本22的预测结果为0,符合真实情况。
四.Excel构建可用于预测的模型
EXCEL构建的模型、树的全部图片内容都在百度网盘提取本文数据和完整脚本(提取码:54ul) 的百度网盘链接。树结构的缩略图如下:

4.1EXCEL构建模型
-
首先,需要针对样本建立单颗树的模型,这里参考 2.1EXCEL构建第1颗树 的内容,已经非常清晰,不再赘述。
-
其次,需要确定每棵树的叶子节点对应分值,整理如下

-
然后,汇总每颗样本对应的叶子节点
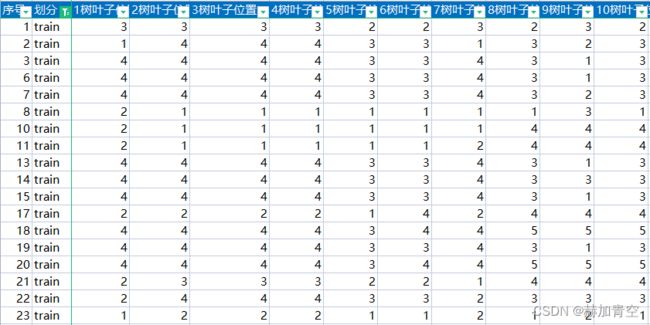
-
最后,匹配出每个样本对应叶子节点的分值,分值求和即可预测结果。

任何一个样本都会分别带入到绘制的10棵树中,获取样本落入每颗树的叶子节点及其叶子节点分值,10颗树的分值相加即为对样本的预测结果,二分类问题中,预测结果大于0则预测为1,小于0则预测为0;预测结果越大于0则预测为1的概率越大,预测结果越小于0则预测为0的概率越大。EXCEL构建的模型训练集样本分值和预测结果如上图,这里只是部分结论图,更细致内容见网盘 EXCEL构建的XGBoost模型.xlsx 文件。
4.2验证数据带入模型
这里首先展示出Python构建的XGBoost模型在验证集上的预测效果,其中索引为46和65的样本预测错误。
# 打印训练数据和验证数据的索引
print('训练集数据index:', list(X_train.index))
print('验证集数据index:', list(X_test.index))

验证数据放入利用EXCEL构建的模型中,模型预测结果如下,索引为46和65的样本预测错误,与python构建的XGBoost模型结果一致。即可以证明我们利用EXCEL构建的模型和Python构建的XGBoost模型是一致的。
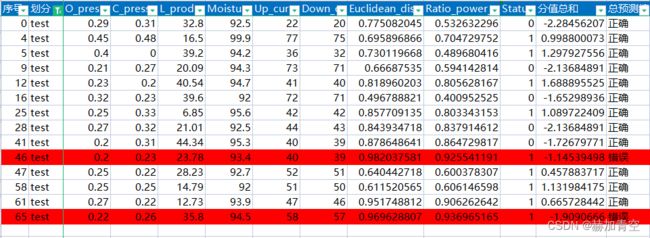
4.3树的叶子节点分值为什么能相加
敲黑板、划重点:XGBoost算法原理及基础知识 3.6如何生成一个XGBoost模型,在这里有XGBoost生成的简单过程,更便于理解。
XGBoost模型属于Boosting模型,Boosting的基本思想是不断纠正弱学习器所犯的错误,进而将弱学习器提升为强学习器。Boosting方法串行的训练一系列分类器,使得先前基分类器做错的样本在后续受到更多关注,并将这些分类器进行结合,以便获得性能完美的强分类器。
- Boosting的两种实现方式如下:
1)AdaBoost继承了Boosting的思想,为每个弱学习器赋予不同权值,将所有弱分类器权重和作为预测的结果,达到强学习器的效果。通俗理解,先训练了第1颗树并对样本进行了预测,第2棵树训练时基于第1颗树的判断结果,第2棵树的训练更加关注第1颗树判断错误的样本,而第1颗树判断正确的样本则关注减少,同样第3棵树训练时,会更加关注第1颗树和第2棵树综合判断后仍然判断错误的样本,而减少对正确样本的关注,以此类推直至达到结束条件。AdaBoost不是本文重点,这里不再展开。
2)Gradient Boosting是Boosting思想的另一种实现方法,它将损失函数梯度下降的方向作为优化的目标,新的学习器建立在之前学习器损失函数梯度下降的方向,在梯度下降的方向不断优化,使损失函数持续下降,从而提高模型的拟合程度,代表算法有GBDT、XGBoost、LightGBM。通俗理解,先训练了第1颗树并对样本进行了预测,第2颗树的学习目标是第1颗树预测值与真实值之间的残差,第3颗树的学习目标是第1颗和第2棵树的预测值之和与真实值的残差,以此类推直至达到结束条件。
简单拓展:GBDT基学习器是CART回归树,XGBoost基模型为树模型时也是回归树,返回结果是连续值。

上图为陈天齐博士XGBoost论文内容,利用加法模型判断样本使用电脑的例子,两棵树tree1和tree2分别有自己的叶子节点权值,权值相加便是模型对样本的预测结果。 - 综上论述,应该已经可以理解权值为什么能相加和什么是加法模型了。本文所解释数据为例,会出现以下两种情况:
1)第1颗树判断为错误的样本经过模型的不断纠正,有3个样本最终判断正确了

2)经过迭代多颗树后,反而把原有的两个判断正确的样本 判断错误了,但整体依然是更好了

- 另外多说几句:
1)样本分值是样本落入每棵树的叶子节点分值之和。这里的“之和”的加法,可以理解为软投票——不同权值的相加。不同之处在于Bagging的软投票是各基模型之间没有直接关系,而Boosting模型采用前向分布算法,后面的基模型是基于前面模型预测值之和与真实值的残差来继续拟合的。
2)下面结论不止对最终结果适用,对每颗树的预测结果同样适用。结论:预测结果大于0则预测为1,小于0则预测为0;预测结果越大于0则预测为1的概率越大,预测结果越小于0则预测为0的概率越大。
3)每棵树都有对样本结果的判断,每颗树对自己判断的结果的话语权由对应节点分值决定,所以可以相加。
4)树的个数并不是越多越好的,树的个数其实就是模型的迭代次数,10颗树就是模型会迭代10次。针对不同的特征数据会有不同的合适的迭代次数,这也是调参的必要性。
五.总结
至此,已经完成了从结果树对XGBoost模型的解释,可以看出XGBoost模型可解释性还是不错的,相较于决策树模型是复杂了些,但与神经网络相比,可解释性已经非常强了。结合下面这4片文章,已经解释清楚了XGBoost模型的实战使用
XGBoost模型调参、训练、评估、保存和预测
XGBoost算法原理及基础知识
分类任务评估1——推导sklearn分类任务评估指标
分类任务评估2——推导ROC曲线、P-R曲线和K-S曲线
Graphviz绘制模型树1——软件配置与XGBoost树的绘制
声明:本文所载信息不保证准确性和完整性。文中所述内容和意见仅供参考,不构成实际商业建议,可收藏可转发但请勿转载,如有雷同纯属巧合。