中文自动文本摘要生成指标计算,Rouge/Bleu/BertScore/QA代码实现
本部分讲述下如何计算生成摘要与参考摘要的指标,指标方面分为两类,一类基于n-grams计算,如Rouge-1,Rouge-2,Rouge-L,BLEU,主要衡量摘要的句法的连贯性,不能衡量生成摘要的真实性与忠诚程度,另一类基于蕴含或者QA等辅助手段,这种方式能够更好的衡量生成摘要的忠诚度,如FEQA,QuestEval,最后就是简单地BertScore。代码中均为transformers库中计算代码,放置位置参考之前的bart等文章。
至于摘要生成过程中存在的幻觉问题,如内在的无中生有,外在的无中生有,有一篇很好的综述:Survey of Hallucination in Natural Language Generation:https://arxiv.org/pdf/2202.03629.pdf
1 ROUGE、BLEU计算
1.1 分词还是不分词?
计算指标前需要一个统一的标准,不同与英文,中文指标再计算的时候各家有各家的计算方法,有的分词有的部分词,有的jieba分词有的hanlp分词。
1.2 词表是以字为基础还是词为基础?统一标准
不同的模型词表也不同,生成摘要的时候要统一标准!
例如,以字为词表的模型(典型的就是中文BART)在transformers中生成的摘要的这种形式的:['我 是 生 成 的 摘 要']
而以词为词表的模型(典型的就是中文T5 Pegasus)生成的摘要是这种形式的:['我 是 生成 的 摘要']
那么在这种情况下,就要统一标准:将摘要首先去除空格,全部变成['我是生成的摘要']这种形式,即:
decoded_preds = ["".join(pred.replace(" ", "")) for pred in decoded_preds]
decoded_labels = ["".join(label.replace(" ", "")) for label in decoded_labels]
但这样会存在一个问题,对于数字英文等多的中文摘要指标计算会偏高。若是字的生成,不建议去除空格,transformers生成的原始摘要设置空格分开就行了。
比如:1234举起手啊--->分字就是1 2 3 4 举 起 手 啊;按此表就是1234 举 起 手 啊
1.3 计算指标
计算指标此时就可以分为两种,一种是分词后计算,一种是不分词计算。
(1)分词后计算,以jieba分词为例:
decoded_preds = [" ".join(jieba.cut(pred.replace(" ", ""))) for pred in decoded_preds]
decoded_labels = [" ".join(jieba.cut(label.replace(" ", ""))) for label in decoded_labels]
此时结果为:
['我 是 生成 的 摘要']
['我 是 参考 的 摘要']
二者格式相同,直接计算即可:result = rouge.get_scores(decoded_preds, decoded_labels, avg=True)
(2)如果不分词的话,则直接按字符级计算:
decoded_preds = [" ".join(pred.replace(" ", "")) for pred in decoded_preds]
decoded_labels = [" ".join(label.replace(" ", "")) for label in decoded_labels]
result = rouge.get_scores(decoded_preds, decoded_labels, avg=True)
此时结果为:
['我 是 生 成 的 摘 要']
['我 是 参 考 的 摘 要']
有空格是因为rouge库计算需要空格隔开,如果你用lawrouge库就不用了,直接调用result = rouge.get_scores(decoded_preds, decoded_labels, avg=True)
1.4 计算差异
一般来说,二者之间有着巨大的差异,分词后计算指标通常比字符级小很多,5-10个点不等
from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction
from rouge import Rouge
def compute_metrics(eval_pred):
predictions, labels = eval_pred
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# 字符级别
decoded_preds = [" ".join((pred.replace(" ", ""))) for pred in decoded_preds]
decoded_labels = [" ".join((label.replace(" ", ""))) for label in decoded_labels]
# 词级别,分词
# decoded_preds = [" ".join(jieba.cut(pred.replace(" ", ""))) for pred in decoded_preds]
# decoded_labels = [" ".join(jieba.cut(label.replace(" ", ""))) for label in decoded_labels]
rouge = Rouge()
labels_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in labels]
total = 0
rouge_1, rouge_2, rouge_l, bleu = 0, 0, 0, 0
for decoded_label, decoded_pred in zip(decoded_labels, decoded_preds):
total += 1
scores = rouge.get_scores(hyps=decoded_pred, refs=decoded_label)
rouge_1 += scores[0]['rouge-1']['f']
rouge_2 += scores[0]['rouge-2']['f']
rouge_l += scores[0]['rouge-l']['f']
bleu += sentence_bleu(
references=[decoded_label.split(' ')],
hypothesis=decoded_pred.split(' '),
smoothing_function=SmoothingFunction().method1
)
bleu /= len(decoded_labels)
rouge_1 /= total
rouge_2 /= total
rouge_l /= total
result = {'rouge-1': rouge_1, 'rouge-2': rouge_2, 'rouge-l': rouge_l}
print(result)
# 测试平均与分别计算是否一致
result2 = rouge.get_scores(decoded_preds, decoded_labels, avg=True)
print(result2)
print(bleu)
# result = {'rouge-1': result['rouge-1']['f'], 'rouge-2': result['rouge-2']['f'], 'rouge-l': result['rouge-l']['f']}
result = {key: value * 100 for key, value in result.items()}
result["gen_len"] = np.mean(labels_lens)
result["bleu"] = bleu * 100
return result2 QA&QG
流程比较复杂,例如基于QA的,需要分别训练Question generation与Answer generation模型,模型的训练好坏直接影响效果。先简单介绍QA与QG的训练,其中QA基于BERT,QG基于BART,这里是用的是英文的SQuAD-1.1,中文方法是一样的,使用CMRC2018的SQuAD格式数据,模型换成中文模型就好了。不同论文的实现方式不一样,我只说一个最最简单的方法。
2.1目录结构

2.2 数据加载
squad.py,我这里cmrc2018.py与squad.py一样,只是数据集地址不一样
重要的是这个地方,加载的是数据集的位置
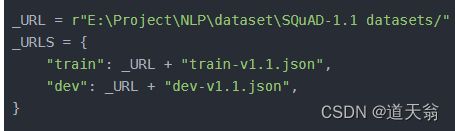
# coding=utf-8
# Copyright 2020 The TensorFlow Datasets Authors and the HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Lint as: python3
"""SQUAD: The Stanford Question Answering Dataset."""
import json
import datasets
from datasets.tasks import QuestionAnsweringExtractive
logger = datasets.logging.get_logger(__name__)
_CITATION = """\
@article{2016arXiv160605250R,
author = {{Rajpurkar}, Pranav and {Zhang}, Jian and {Lopyrev},
Konstantin and {Liang}, Percy},
title = "{SQuAD: 100,000+ Questions for Machine Comprehension of Text}",
journal = {arXiv e-prints},
year = 2016,
eid = {arXiv:1606.05250},
pages = {arXiv:1606.05250},
archivePrefix = {arXiv},
eprint = {1606.05250},
}
"""
_DESCRIPTION = """\
Stanford Question Answering Dataset (SQuAD) is a reading comprehension \
dataset, consisting of questions posed by crowdworkers on a set of Wikipedia \
articles, where the answer to every question is a segment of text, or span, \
from the corresponding reading passage, or the question might be unanswerable.
"""
_URL = r"E:\Project\NLP\dataset\SQuAD-1.1 datasets/"
_URLS = {
"train": _URL + "train-v1.1.json",
"dev": _URL + "dev-v1.1.json",
}
class SquadConfig(datasets.BuilderConfig):
"""BuilderConfig for SQUAD."""
def __init__(self, **kwargs):
"""BuilderConfig for SQUAD.
Args:
**kwargs: keyword arguments forwarded to super.
"""
super(SquadConfig, self).__init__(**kwargs)
class Squad(datasets.GeneratorBasedBuilder):
"""SQUAD: The Stanford Question Answering Dataset. Version 1.1."""
BUILDER_CONFIGS = [
SquadConfig(
name="plain_text",
version=datasets.Version("1.0.0", ""),
description="Plain text",
),
]
def _info(self):
return datasets.DatasetInfo(
description=_DESCRIPTION,
features=datasets.Features(
{
"id": datasets.Value("string"),
"title": datasets.Value("string"),
"context": datasets.Value("string"),
"question": datasets.Value("string"),
"answers": datasets.features.Sequence(
{
"text": datasets.Value("string"),
"answer_start": datasets.Value("int32"),
}
),
}
),
# No default supervised_keys (as we have to pass both question
# and context as input).
supervised_keys=None,
homepage="https://rajpurkar.github.io/SQuAD-explorer/",
citation=_CITATION,
task_templates=[
QuestionAnsweringExtractive(
question_column="question", context_column="context", answers_column="answers"
)
],
)
def _split_generators(self, dl_manager):
downloaded_files = dl_manager.download_and_extract(_URLS)
return [
datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"filepath": downloaded_files["train"]}),
datasets.SplitGenerator(name=datasets.Split.VALIDATION, gen_kwargs={"filepath": downloaded_files["dev"]}),
]
def _generate_examples(self, filepath):
"""This function returns the examples in the raw (text) form."""
logger.info("generating examples from = %s", filepath)
key = 0
with open(filepath, encoding="utf-8") as f:
squad = json.load(f)
for article in squad["data"]:
title = article.get("title", "")
for paragraph in article["paragraphs"]:
context = paragraph["context"] # do not strip leading blank spaces GH-2585
for qa in paragraph["qas"]:
answer_starts = [answer["answer_start"] for answer in qa["answers"]]
answers = [answer["text"] for answer in qa["answers"]]
# Features currently used are "context", "question", and "answers".
# Others are extracted here for the ease of future expansions.
yield key, {
"title": title,
"context": context,
"question": qa["question"],
"id": qa["id"],
"answers": {
"answer_start": answer_starts,
"text": answers,
},
}
key += 1
2.3 QA训练
QA_finetune.py
# coding=utf-8
import json
import numpy as np
import torch
from datasets import Dataset,load_dataset
from transformers.data.metrics.squad_metrics import compute_exact, compute_f1
squad = load_dataset('./squad.py')
squad2 = squad["validation"][0]
# 获取验证数据集
# valid_datasets = squad["validation"].flatten().data
# # 获取验证数据集中的content
# valid_contents = valid_datasets[2]
# # 获取验证数据集中的gold answer
# valid_answers = valid_datasets[4]
# # 获取验证数据集中的gold answer start
# valid_answers_start = valid_datasets[5]
xx = compute_f1("left Graz and severed all relations with his family","left Graz and severed")
print(squad)
from transformers import AutoTokenizer, default_data_collator, BertForQuestionAnswering, TrainingArguments, Trainer, \
BertTokenizer
tokenizer = AutoTokenizer.from_pretrained(r"E:\Project\NLP\bert-base-uncased")
def preprocess_function(examples):
'''
用于处理训练集,因为训练集每个问题只有一个参考答案回答
'''
questions = [q.strip() for q in examples["question"]]
inputs = tokenizer(
questions,
examples["context"],
max_length=512,
truncation="only_second",
return_offsets_mapping=True,
padding="max_length",
)
offset_mapping = inputs.pop("offset_mapping")
answers = examples["answers"]
start_positions = []
end_positions = []
for i, offset in enumerate(offset_mapping):
answer = answers[i]
start_char = answer["answer_start"][0]
end_char = answer["answer_start"][0] + len(answer["text"][0])
sequence_ids = inputs.sequence_ids(i)
# Find the start and end of the context
idx = 0
while sequence_ids[idx] != 1:
idx += 1
context_start = idx
while sequence_ids[idx] == 1:
idx += 1
context_end = idx - 1
# If the answer is not fully inside the context, label it (0, 0)
if offset[context_start][0] > end_char or offset[context_end][1] < start_char:
start_positions.append(0)
end_positions.append(0)
else:
# Otherwise it's the start and end token positions
idx = context_start
while idx <= context_end and offset[idx][0] <= start_char:
idx += 1
start_positions.append(idx - 1)
idx = context_end
while idx >= context_start and offset[idx][1] >= end_char:
idx -= 1
end_positions.append(idx + 1)
inputs["start_positions"] = start_positions
inputs["end_positions"] = end_positions
return inputs
tokenized_squad = squad.map(preprocess_function, batched=True, remove_columns=squad["train"].column_names)
# train_x = squad["train"].map(preprocess_function, batched=True, remove_columns=squad["train"].column_names)
# valid_x = squad["validation"].map(preprocess_function, batched=True, remove_columns=squad["validation"].column_names)
data_collator = default_data_collator
model = BertForQuestionAnswering.from_pretrained(r"E:\Project\NLP\long-document\bert-base-uncased")
training_args = TrainingArguments(
# fp16 = True,
output_dir="./QA_results",
do_train=True,
do_eval=True,
evaluation_strategy="epoch",
# eval_steps=2,
learning_rate=1e-4,
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
logging_dir="logs",
logging_strategy="steps",
save_total_limit=3,
logging_steps=1,
num_train_epochs=4,
weight_decay=0.01,
gradient_accumulation_steps=8,
)
def compute_metrics(eval_pred):
predictions,label_ids = eval_pred
start = predictions[0]
end = predictions[1]
answer_start = np.argmax(predictions[0],axis = 1)
answer_end = np.argmax(predictions[1],axis = 1)
label_start = label_ids[0] # 这个是token过后的开始与结束为止 不是一个一个字符数的 是一个一个单词数的
label_end = label_ids[1]
data = tokenized_squad["validation"]
gold_answers=[]
pred_answers=[]
# 遍历每一个验证数据
for idx,example in enumerate(data):
input_ids = example["input_ids"]# 取出文本
label_start = example["start_positions"]# 取出开始
label_end = example["end_positions"]# 取出结束
gold_answer=""
pred_answer=""
for i in range(label_end-label_start+1):
gold_answer+=str(input_ids[label_start+i])+" "
if answer_start[idx] < answer_end[idx]:
answer_end[idx] = answer_start[idx]
for i in range(answer_end[idx]-answer_start[idx]+1):
pred_answer+=str(input_ids[label_start+i])+" "
gold_answers.append(gold_answer.strip())
pred_answers.append(pred_answer.strip())
# 计算f1 score与exact score
f1_score=0
exact_score=0
for gold_answer,pred_answer in zip(gold_answers,pred_answers):
f1_score+=compute_f1(gold_answer,pred_answer)
exact_score+=compute_exact(gold_answer,pred_answer)
f1_score/=len(gold_answers)
exact_score/=len(gold_answers)
f1_score*=100
exact_score*=100
result = {'f1_score': f1_score, 'exact_score': exact_score}
return result
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_squad["train"],
eval_dataset=tokenized_squad["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
2.4 QG训练
QG_finetune.py
import json
import numpy as np
from datasets import Dataset
from transformers import AutoTokenizer, BartTokenizer, Seq2SeqTrainingArguments, DataCollatorForSeq2Seq, \
BartForConditionalGeneration, Seq2SeqTrainer
from transformers.data.metrics.squad_metrics import compute_f1
# x = ['Which NFL team represented the AFC at Super Bowl 50?', 'Which NFL team represented the NFC at Super Bowl 50?', 'Where did Super Bowl 50 take place?', 'Which NFL team won Super Bowl 50?', 'What color was used to emphasize the 50th anniversary of the Super Bowl?', 'What was the theme of Super Bowl 50?', 'What day was the game played on?', 'What is the AFC short for?', 'What was the theme of Super Bowl 50?', 'What does AFC stand for?', 'What day was the Super Bowl played on?', 'Who won Super Bowl 50?', 'What venue did Super Bowl 50 take place in?', 'What city did Super Bowl 50 take place in?', 'If Roman numerals were used, what would Super Bowl 50 have been called?', 'Super Bowl 50 decided the NFL champion for what season?', 'What year did the Denver Broncos secure a Super Bowl title for the third time?', 'What city did Super Bowl 50 take place in?', 'What stadium did Super Bowl 50 take place in?', 'What was the final score of Super Bowl 50? ']
# xx = ['Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League', 'Super Bowl 50 was an American football game to determine the champion of the National Football League']
max_input_length=512
max_target_length=128
train_path = r'E:\Project\NLP\dataset\SQuAD-1.1 datasets\train-v1.1.json'
dev_path = r'E:\Project\NLP\dataset\SQuAD-1.1 datasets\dev-v1.1.json'
output_dir=r'E:\Project\NLP\dataset\SQuAD-1.1 datasets\QG_results'
tokenizer_path=r'E:\Project\NLP\bart-base-english'
model_path=r'E:\Project\NLP\bart-base-english'
def data_preprocess(path):
with open(path, 'r', encoding='utf-8') as f_train:
train_set = json.load(f_train)
datas = train_set
# convert
new_data = []
for data in datas["data"]:
for d in data['paragraphs']:
context = d['context']
for qa in d['qas']:
new_data.append({
'context': context,
'answers': qa['answers'],
'question': qa['question']
})
contexts=[]
labels=[]
for data in new_data:
answer_text = data['answers'][0]['text']
answer_len = len(answer_text)
answer_start = data['answers'][0]['answer_start']
hl_context = data['context'][:answer_start] +'' + answer_text + '' + data['context'][answer_start + answer_len:]
label=data['question'] #+ ''
contexts.append(hl_context)
labels.append(label)
return contexts, labels
train_contexts,train_labels=data_preprocess(train_path)
dev_contexts,dev_labels=data_preprocess(dev_path)
train={}
dev={}
train["contexts"]=train_contexts#[0:50]
train["labels"]=train_labels#[0:50]
dev["contexts"]=dev_contexts#[0:20]
dev["labels"]=dev_labels#[0:20]
train_dataset=Dataset.from_dict(train)
train_dataset=train_dataset.shuffle(seed=42)
dev_dataset=Dataset.from_dict(dev)
dev_dataset=dev_dataset.shuffle(seed=42)
tokenizer = BartTokenizer.from_pretrained(tokenizer_path)
special_tokens_dict = {'additional_special_tokens': ['']}
tokenizer.add_special_tokens(special_tokens_dict)
def preprocess_function(examples):
inputs = [doc for doc in examples["contexts"]]
model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True)
# Setup the tokenizer for targets
with tokenizer.as_target_tokenizer():
labels = tokenizer(examples["labels"], max_length=max_target_length, truncation=True)
# title_len_1 = tokenizer(examples["len_title_1"], max_length=max_target_length, truncation=True)
# title_len_all = tokenizer(examples["len_title_all"], max_length=max_target_length, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
tokenized_train_dataset = train_dataset.map(preprocess_function, batched=True, remove_columns=train_dataset.column_names)
tokenized_dev_dataset = dev_dataset.map(preprocess_function, batched=True, remove_columns=dev_dataset.column_names)
batch_size = 1
args = Seq2SeqTrainingArguments(
fp16 = True,
output_dir=output_dir,
num_train_epochs=5, # demo
do_train=True,
do_eval=True,
per_device_train_batch_size=1, # demo
per_device_eval_batch_size=1,
learning_rate=1e-04,
warmup_steps=100,
weight_decay=0.01,
label_smoothing_factor=0.1,
predict_with_generate=True,
logging_dir="logs",
logging_strategy="steps",
logging_steps=1,
save_total_limit=3,
evaluation_strategy="epoch",
generation_max_length=max_target_length,
generation_num_beams=4,
# remove_unused_columns=False,
)
model = BartForConditionalGeneration.from_pretrained(model_path)
model.resize_token_embeddings(len(tokenizer))
# model, list_en, list_de = create_student_by_copying_alternating_layers(model, 'trian.pth', 12, 3)
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
def compute_metrics(eval_pred):
predictions, labels = eval_pred
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
f1_score = 0
for label, pred in zip(decoded_labels, decoded_preds):
f1_score += compute_f1(label, pred)
f1_score /= len(decoded_preds)
f1_score *= 100
result = {'f1_score': f1_score}
return result
trainer = Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_train_dataset,
# train_dataset=dataset_train,
eval_dataset=tokenized_dev_dataset,
# eval_dataset=dataset_valid,
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
train_result = trainer.train()
2.5 使用
中文是一样的,不过数据集换一下,注意格式!训练好之后就可以通过QG对源文本生成问题与答案,将问题输入AG模型生成回答,比较源文本的回答与生成摘要的回答结果来比较,这样做不需要参考摘要!!!
3 BERTScore
这是一个介于rouge与QA之间的指标,通过将参考摘要与生成摘要输入bert模型,获得句向量,比较句向量之间的cosin相似度来获得指标,使用很简单,只需要调用库函数就行。
from bert_score import score
# data
cands = ['天天干家务烦死了','难受死了啊']
refs = ['这也完全不相干啊','真的难受死了啊']
P, R, F1 = score(cands, refs, lang="zh", verbose=True)
print(f"System level F1 score: {F1.mean():.3f}")