【人脸识别】基于PCA+SVM人脸识别(准确率)matlab源码含GUI
一、简介
1 PCA\ PCA(Principal Component Analysis)是常用的数据分析方法。PCA是通过线性变换,将原始数据变换为一组各维度线性无关的数据表示方法,可用于提取数据的主要特征分量,常用于高维数据的降维。
1.1 降维问题\ 数据挖掘和机器学习中,数据以向量表示。例如某个淘宝店2012年全年的流量及交易情况可以看成一组记录的集合,其中每一天的数据是一条记录,格式如下:\ (日期, 浏览量, 访客数, 下单数, 成交数, 成交金额)\ 其中“日期”是一个记录标志而非度量值,而数据挖掘关心的大多是度量值,因此如果我们忽略日期这个字段后,我们得到一组记录,每条记录可以被表示为一个五维向量,其中一条样本如下所示:\  \ 一般习惯上使用列向量表示一条记录,本文后面也会遵循这个准则。\ 机器学习的很多算法复杂度和数据的维数有着密切关系,甚至与维数呈指数级关联。这里区区5维的数据,也许无所谓,但是实际机器学习中处理成千上万甚至几十万维的数据也并不罕见,在这种情况下,机器学习的资源消耗是不可接受的,因此就会对数据采取降维的操作。降维就意味着信息的丢失,不过鉴于实际数据本身常常存在相关性,所以在降维时想办法降低信息的损失。\ 例如上面淘宝店铺的数据,从经验可知,“浏览量”和“访客数”往往具有较强的相关性,而“下单数”和“成交数”也具有较强的相关性。可以直观理解为“当某一天这个店铺的浏览量较高(或较低)时,我们应该很大程度上认为这天的访客数也较高(或较低)”。因此,如果删除浏览量或访客数,最终并不会丢失太多信息,从而降低数据的维度,也就是所谓的降维操作。如果把数据降维用数学来分析讨论,用专业名词表示就是PCA,这是一种具有严格数学基础并且已被广泛采用的降维方法。
\ 一般习惯上使用列向量表示一条记录,本文后面也会遵循这个准则。\ 机器学习的很多算法复杂度和数据的维数有着密切关系,甚至与维数呈指数级关联。这里区区5维的数据,也许无所谓,但是实际机器学习中处理成千上万甚至几十万维的数据也并不罕见,在这种情况下,机器学习的资源消耗是不可接受的,因此就会对数据采取降维的操作。降维就意味着信息的丢失,不过鉴于实际数据本身常常存在相关性,所以在降维时想办法降低信息的损失。\ 例如上面淘宝店铺的数据,从经验可知,“浏览量”和“访客数”往往具有较强的相关性,而“下单数”和“成交数”也具有较强的相关性。可以直观理解为“当某一天这个店铺的浏览量较高(或较低)时,我们应该很大程度上认为这天的访客数也较高(或较低)”。因此,如果删除浏览量或访客数,最终并不会丢失太多信息,从而降低数据的维度,也就是所谓的降维操作。如果把数据降维用数学来分析讨论,用专业名词表示就是PCA,这是一种具有严格数学基础并且已被广泛采用的降维方法。
1.2 向量与基变换\ 1.2.1 内积与投影\ 两个大小相同向量的内积被定义如下:\  \
\ 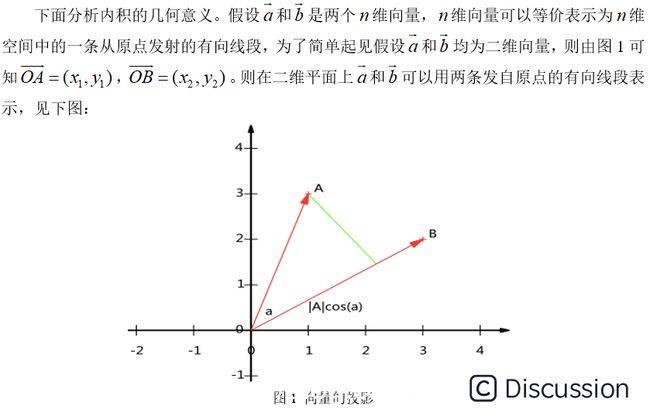 \
\  \ 1.2.2 基\ 在代数中,经常用线段终点的点坐标表示向量。假设某个向量的坐标为(3,2),这里的3实际表示的是向量在x轴上的投影值是3,在y轴上的投影值是2。也就是说隐式引入了一个定义:以x轴和y轴上正方向长度为1的向量为标准。那么一个向量(3,2)实际是在x轴投影为3而y轴的投影为2。注意投影是一个矢量,可以为负。向量(x, y)实际上表示线性组合:\
\ 1.2.2 基\ 在代数中,经常用线段终点的点坐标表示向量。假设某个向量的坐标为(3,2),这里的3实际表示的是向量在x轴上的投影值是3,在y轴上的投影值是2。也就是说隐式引入了一个定义:以x轴和y轴上正方向长度为1的向量为标准。那么一个向量(3,2)实际是在x轴投影为3而y轴的投影为2。注意投影是一个矢量,可以为负。向量(x, y)实际上表示线性组合:\ 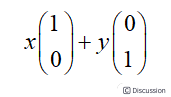 \ 由上面的表示,可以得到所有二维向量都可以表示为这样的线性组合。此处(1,0)和(0,1)叫做二维空间中的一组基。\
\ 由上面的表示,可以得到所有二维向量都可以表示为这样的线性组合。此处(1,0)和(0,1)叫做二维空间中的一组基。\ 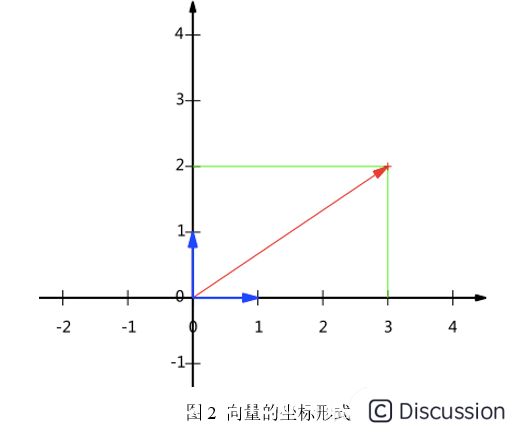 \ 之所以默认选择(1,0)和(0,1)为基,当然是为了方便,因为它们分别是x和y轴正方向上的单位向量,因此就使得二维平面上点坐标和向量一一对应。但实际上任何两个线性无关的二维向量都可以成为一组基,所谓线性无关在二维平面内,从直观上就是两个不在一条直线的向量。\
\ 之所以默认选择(1,0)和(0,1)为基,当然是为了方便,因为它们分别是x和y轴正方向上的单位向量,因此就使得二维平面上点坐标和向量一一对应。但实际上任何两个线性无关的二维向量都可以成为一组基,所谓线性无关在二维平面内,从直观上就是两个不在一条直线的向量。\ 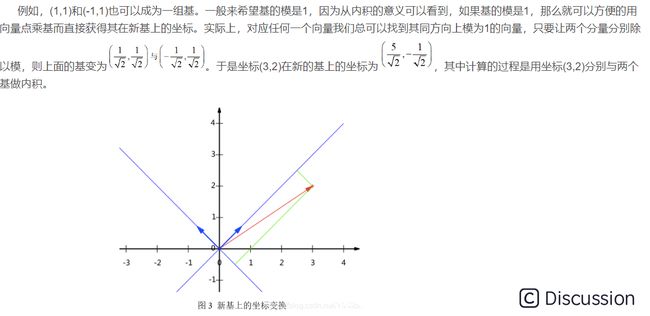 \ 另外这里的基是正交的(即内积为0,或直观说相互垂直),可以成为一组基的唯一要求就是线性无关,非正交的基也是可以的。不过因为正交基有较好的性质,所以一般使用的基都是正交的。\ 1.2.3 基变换的矩阵\ 上述例子中的基变换,可以采用矩阵的乘法来表示,即\
\ 另外这里的基是正交的(即内积为0,或直观说相互垂直),可以成为一组基的唯一要求就是线性无关,非正交的基也是可以的。不过因为正交基有较好的性质,所以一般使用的基都是正交的。\ 1.2.3 基变换的矩阵\ 上述例子中的基变换,可以采用矩阵的乘法来表示,即\ 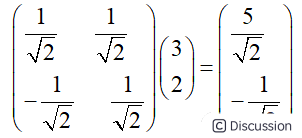 \ 如果推广一下,假设有M个N维向量,想将其变换为由R个N维向量表示的新空间中,那么首先将R个基按行组成矩阵A,然后将向量按列组成矩阵B,那么两矩阵的乘积AB就是变换结果,其中AB的第m列为A中第m列变换后的结果,通过矩阵相乘表示为:\
\ 如果推广一下,假设有M个N维向量,想将其变换为由R个N维向量表示的新空间中,那么首先将R个基按行组成矩阵A,然后将向量按列组成矩阵B,那么两矩阵的乘积AB就是变换结果,其中AB的第m列为A中第m列变换后的结果,通过矩阵相乘表示为:\ 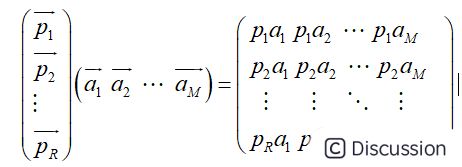 \
\  \ 1.3 协方差矩阵及优化目标\ 在进行数据降维的时候,关键的问题是如何判定选择的基是最优。也就是选择最优基是最大程度的保证原始数据的特征。这里假设有5条数据为\
\ 1.3 协方差矩阵及优化目标\ 在进行数据降维的时候,关键的问题是如何判定选择的基是最优。也就是选择最优基是最大程度的保证原始数据的特征。这里假设有5条数据为\ 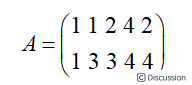 \ 计算每一行的平均值,然后再让每一行减去得到的平均值,得到\
\ 计算每一行的平均值,然后再让每一行减去得到的平均值,得到\  \ 通过坐标的形式表现矩阵,得到的图如下:\
\ 通过坐标的形式表现矩阵,得到的图如下:\ 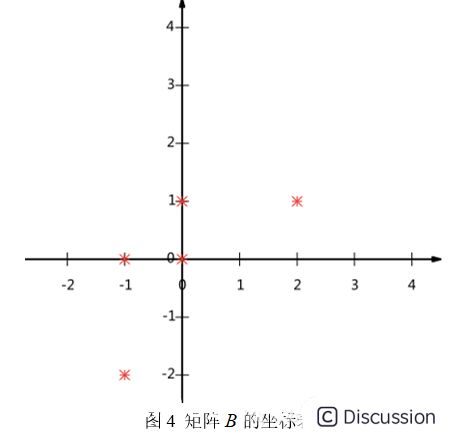 \ 那么现在的问题是:用一维向量来表示这些数据,又希望尽量保留原有的信息,该如何选择呢?这个问题实际上是要在二维平面中选择一个方向的向量,将所有数据点都投影到这条直线上,用投影的值表示原始记录,即二维降到一维的问题。那么如何选择这个方向(或者说基)才能尽量保留最多的原始信息呢?一种直观的看法是:希望投影后的投影值尽可能分散。
\ 那么现在的问题是:用一维向量来表示这些数据,又希望尽量保留原有的信息,该如何选择呢?这个问题实际上是要在二维平面中选择一个方向的向量,将所有数据点都投影到这条直线上,用投影的值表示原始记录,即二维降到一维的问题。那么如何选择这个方向(或者说基)才能尽量保留最多的原始信息呢?一种直观的看法是:希望投影后的投影值尽可能分散。
1.3.1 方差\ 上述问题是希望投影后投影的值尽可能在一个方向上分散,而这种分散程度,可以采用数学上的方差来表述,即:\ 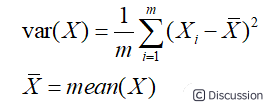 \ 于是上面的问题被形式化表述为:寻找一个一维基,使得所有数据变换为这个基上的坐标后,方差值最大。
\ 于是上面的问题被形式化表述为:寻找一个一维基,使得所有数据变换为这个基上的坐标后,方差值最大。
2.3.2 协方差\ 数学上可以用两个特征的协方差表示其相关性,即:\  \ 当协方差为0时,表示两个特征完全独立。为了让协方差为0,选择第二个基时只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。
\ 当协方差为0时,表示两个特征完全独立。为了让协方差为0,选择第二个基时只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。
至此获得降维问题的优化目标:将一组N维向量降为K维(K\
2.3.3 协方差矩阵\ 假设只有x和y两个字段,将它们按行组成矩阵,其中是通过中心化的矩阵,也就是每条字段减去每条字段的平均值得到的矩阵:\ 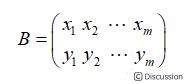 \
\  \ 3.4 协方差矩阵对角化\
\ 3.4 协方差矩阵对角化\  \
\  \ 1.4 算法与实例\ 1.4.1 PCA算法\
\ 1.4 算法与实例\ 1.4.1 PCA算法\  \ 1.4.2 实例\
\ 1.4.2 实例\  \
\  \ 1.5. 讨论\ 根据上面对PCA的数学原理的解释,可以了解到一些PCA的能力和限制。PCA本质上是将方差最大的方向作为主要特征,并且在各个正交方向上将数据“离相关”,也就是让它们在不同正交方向上没有相关性。
\ 1.5. 讨论\ 根据上面对PCA的数学原理的解释,可以了解到一些PCA的能力和限制。PCA本质上是将方差最大的方向作为主要特征,并且在各个正交方向上将数据“离相关”,也就是让它们在不同正交方向上没有相关性。
因此,PCA也存在一些限制,例如它可以很好的解除线性相关,但是对于高阶相关性就没有办法了,对于存在高阶相关性的数据,可以考虑Kernel PCA,通过Kernel函数将非线性相关转为线性相关。另外,PCA假设数据各主特征是分布在正交方向上,如果在非正交方向上存在几个方差较大的方向,PCA的效果就大打折扣了。
最后需要说明的是,PCA是一种无参数技术,也就是说面对同样的数据,如果不考虑清洗,谁来做结果都一样,没有主观参数的介入,所以PCA便于通用实现,但是本身无法个性化的优化。
2 SVM基本概念\ 支持向量机(Support Vector Machine, SVM)的基本模型是在特征空间上找到最佳的分离超平面使得训练集上正负样本间隔最大。SVM是用来解决二分类问题的有监督学习算法,在引入了核方法之后SVM也可以用来解决非线性问题。\ 一般SVM有下面三种:
硬间隔支持向量机(线性可分支持向量机):当训练数据线性可分时,可通过硬间隔最大化学得一个线性可分支持向量机。\ 软间隔支持向量机:当训练数据近似线性可分时,可通过软间隔最大化学得一个线性支持向量机。\ 非线性支持向量机:当训练数据线性不可分时,可通过核方法以及软间隔最大化学得一个非线性支持向量机。
2.2 硬间隔支持向量机\  \
\ 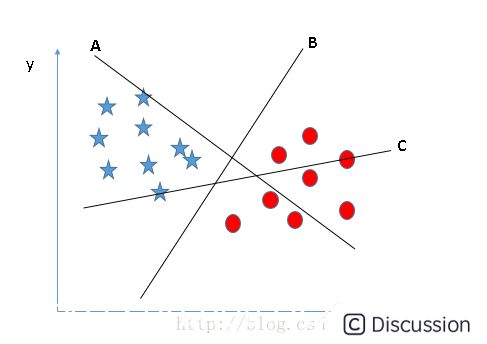 \ 对于图2的A、B、C三个超平面,应该选择超平面C,因为使用超平面C进行划分对训练样本局部扰动的“容忍”度最好,分类的鲁棒性最强。例如,由于训练集的局限性或噪声的干扰,训练集外的样本可能比图2中的训练样本更接近两个类目前的分隔界,在分类决策的时候就会出现错误,而超平面C受影响最小,也就是说超平面C所产生的分类结果是最鲁棒性的、是最可信的,对未见样本的泛化能力最强。\
\ 对于图2的A、B、C三个超平面,应该选择超平面C,因为使用超平面C进行划分对训练样本局部扰动的“容忍”度最好,分类的鲁棒性最强。例如,由于训练集的局限性或噪声的干扰,训练集外的样本可能比图2中的训练样本更接近两个类目前的分隔界,在分类决策的时候就会出现错误,而超平面C受影响最小,也就是说超平面C所产生的分类结果是最鲁棒性的、是最可信的,对未见样本的泛化能力最强。\ 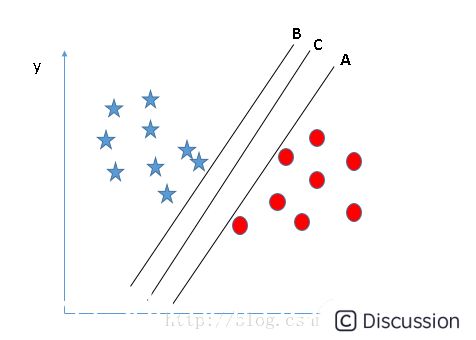 \ 下面以下图中示例进行推导得出最佳超平面。\
\ 下面以下图中示例进行推导得出最佳超平面。\  \
\  \
\  \ 这就是SVM的基本型。
\ 这就是SVM的基本型。
2.2.1 拉格朗日对偶问题\  \
\  \ 2.2.2 SVM问题的KKT条件\
\ 2.2.2 SVM问题的KKT条件\  \ 2.3 软间隔支持向量机\
\ 2.3 软间隔支持向量机\  \
\  \
\  \
\  \ 2.4 非线性支持向量机\
\ 2.4 非线性支持向量机\ 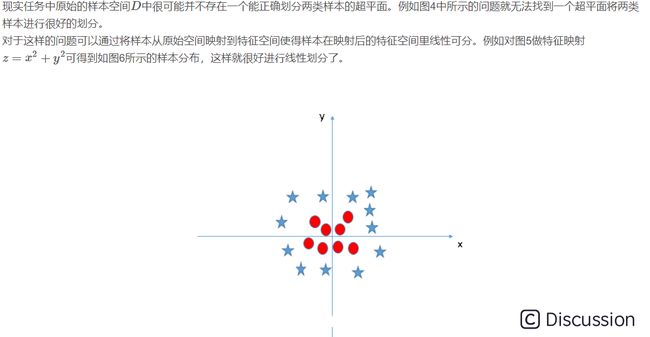 \
\ 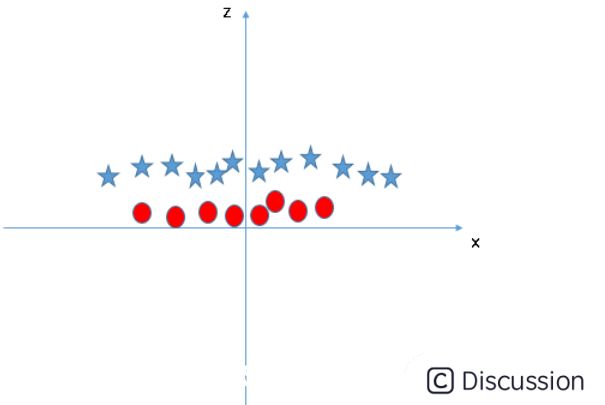 \
\  \
\  \ 2.4.1 支持向量回归\
\ 2.4.1 支持向量回归\  \
\  \
\ 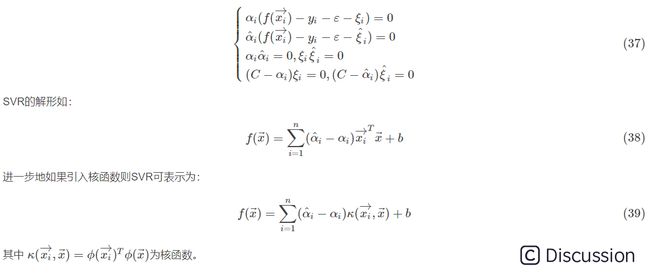 \ 2.4.2 常用核函数\
\ 2.4.2 常用核函数\ 
2.5 SVM的优缺点\ 优点:\ SVM在中小量样本规模的时候容易得到数据和特征之间的非线性关系,可以避免使用神经网络结构选择和局部极小值问题,可解释性强,可以解决高维问题。\ 缺点:\ SVM对缺失数据敏感,对非线性问题没有通用的解决方案,核函数的正确选择不容易,计算复杂度高,主流的算法可以达到O(n2)O(n2)的复杂度,这对大规模的数据是吃不消的。
二、源代码
``` function varargout = test(varargin) guiSingleton = 1; guiState = struct('guiName', mfilename, ... 'guiSingleton', guiSingleton, ... 'guiOpeningFcn', @testOpeningFcn, ... 'guiOutputFcn', @testOutputFcn, ... 'guiLayoutFcn', [] , ... 'guiCallback', []); if nargin && ischar(varargin{1}) guiState.gui_Callback = str2func(varargin{1}); end
if nargout [varargout{1:nargout}] = guimainfcn(guiState, varargin{:}); else guimainfcn(guiState, varargin{:}); end
function testOpeningFcn(hObject, eventdata, handles, varargin) global imgrow imgcol V pcaface accuracy imgrow=112; imgcol=92;%读取的图像为112*92 npersons=41;%选取41个人的脸 disp('读取训练数据...'); fmatrix=ReadFace(npersons,0);%读取训练数据 nfaces=size(f_matrix,1);%样本人脸的数量
%低维空间的图像是(npersons5)k的矩阵,每行代表一个主成分脸,每个脸20维特征 disp('训练数据PCA特征提取...'); mA=mean(fmatrix);%求每个属性的均值 k=20;%降维至20维 [pcaface,V]=fastPCA(fmatrix,k,mA);%主成分分析法特征提取 %pcaface是200*20 disp('训练特征数据规范化....') lowvec=min(pcaface); upvec=max(pcaface); scaledface=scaling(pcaface,lowvec,upvec);
disp('SVM样本训练...') gamma=0.0078; c=128; multiSVMstruct=multiSVMtrain(scaledface,npersons,gamma,c); save('recognize.mat','multiSVMstruct','npersons','k','mA','V','lowvec','upvec');
disp('读取测试数据...') [testface,realclass]=ReadFace(npersons,1);
disp('测试数据降维...') m=size(testface,1); for i=1:m testface(i,:)=testface(i,:)-mA; end pcatestface=testface*V; disp('测试特征数据规范化...') scaledtestface=scaling(pcatestface,lowvec,upvec); disp('样本分类...') class=multiSVM(scaledtestface,multiSVMstruct,npersons);
disp('测试完成!') accuracy=sum(class==realclass)/length(class); set(handles.changefont,'string','请先选择照片......') handles.output = hObject; guidata(hObject, handles); function [fmatrix,realclass]=ReadFace(npersons,flag) %读取ORL人脸库照片里的数据到矩阵 %输入: % npersons-需要读入的人数,每个人的前五幅图为训练样本,后五幅为验证样本 % imgrow-图像的行像素为全局变量 % imgcol-图像的列像素为全局变量 % flag-标志,0表示读入训练样本,1表示读入测试样本 %输出: %已知全局变量:imgrow=112;imgcol=92; global imgrow; global imgcol; realclass=zeros(npersons5,1);%zeros 创建全零数组 矩阵创建了一个2001的零矩阵 fmatrix=zeros(npersons*5,imgrow*imgcol);%创建了一个200*(112*92)的零矩阵,把训练集中所有的人脸都放在这个fmatrix中 for i=1:npersons facepath='./orl_faces/s';%训练样本集的路径 facepath=strcat(facepath,num2str(i));%strcat 字符串拼接 num2str()把数字转为字符串 facepath=strcat(facepath,'/'); cachepath=facepath;%得到图片的路径 for j=1:5 unction [ scaledface] = scaling( faceMat,lowvec,upvec ) %特征数据规范化 %输入??faceMat需要进行规范化的图像数据, % lowvec原来的最小值 % upvec原来的最大值 upnew=1; lownew=-1; [m,n]=size(faceMat); scaledface=zeros(m,n); for i=1:m scaledface(i,:)=lownew+(faceMat(i,:)-lowvec)./(upvec-lowvec)*(upnew-lownew); end end voting=zeros(m,nclass); for i=1:nclass-1 for j=i+1:nclass class=svmclassify(multiSVMstruct{i}{j},testface); voting(:,i)=voting(:,i)+(class==1); voting(:,j)=voting(:,j)+(class==0); end end [~,class]=max(voting,[],2); end ```
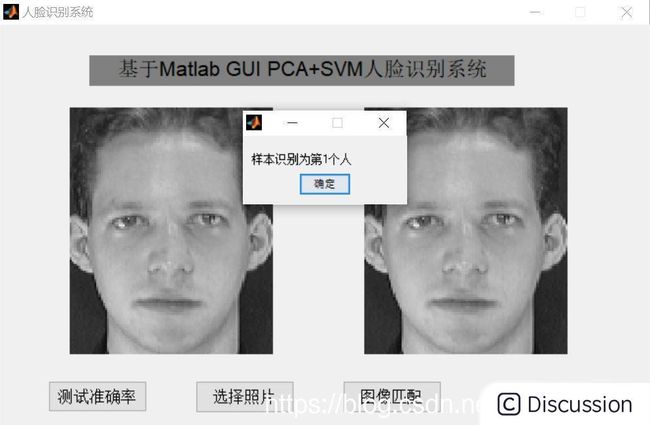
三、运行结果
 \
\