【学习】numpy、self-supervised learning自监督学习
李宏毅机器学习和numpy基础
- 一、numpy
-
- 1、NumPy Ndarray 对象
- 2、NumPy 数据类型
- 3、NumPy 数组属性
- 4、NumPy 创建数组
-
- numpy.empty
- numpy.zeros
- numpy.ones
- 5、NumPy 从已有的数组创建数组
-
- numpy.asarray
- numpy.frombuffer
- numpy.fromiter
- 6、NumPy 从数值范围创建数组
-
- numpy.arange
- numpy.linspace
- numpy.logspace
- NumPy 切片和索引
- 二、self-supervised learning 自监督学习
-
- 1、self-supervised learning
-
- supervised
- self-supervised
- (1)输入掩码(masking input)
- (2)next sentence prediction
- BERT怎么用呢?
- GLUE
- 使用BERT
- 预训练一个seq2seq的模型
- why does BERT work?
- multi-lingual BERT
一、numpy
1、NumPy Ndarray 对象
ndarray 的内部结构:
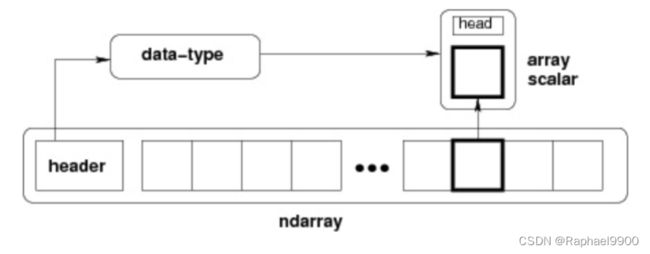
跨度可以是负数,这样会使数组在内存中后向移动,切片中 obj[::-1] 或 obj[:,::-1] 就是如此。
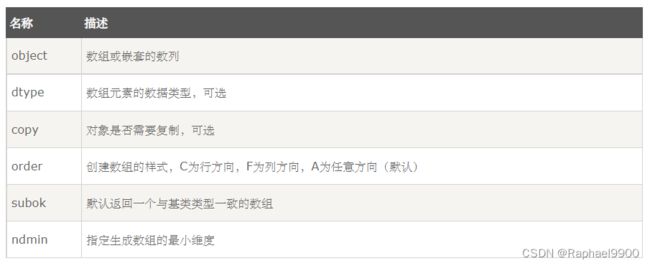
创建一个 ndarray 只需调用 NumPy 的 array 函数即可:
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
import numpy as np
a = np.array([1, 2, 3], dtype = complex)
print (a)
输出:[1.+0.j 2.+0.j 3.+0.j]
2、NumPy 数据类型
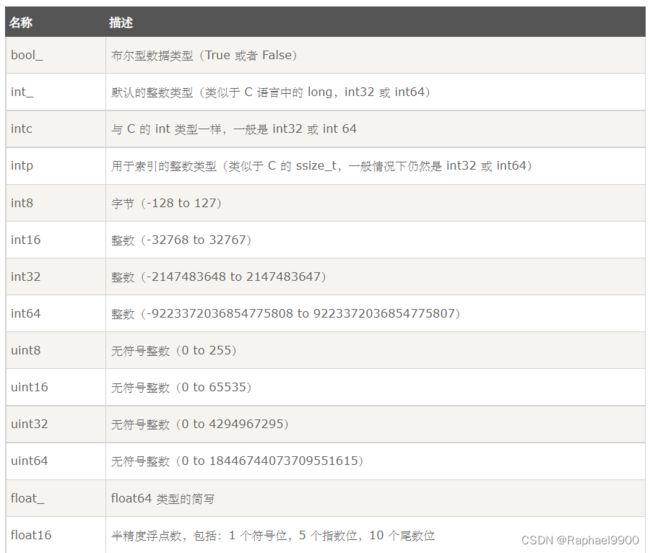


数据类型对象 (dtype)
dtype 对象是使用以下语法构造的:
numpy.dtype(object, align, copy)
object - 要转换为的数据类型对象
align - 如果为 true,填充字段使其类似 C 的结构体。
copy - 复制 dtype 对象 ,如果为 false,则是对内置数据类型对象的引用
3、NumPy 数组属性
axis=0,表示沿着第 0 轴进行操作,即对每一列进行操作;axis=1,表示沿着第1轴进行操作,即对每一行进行操作。NumPy 数组的维数称为秩(rank)。在 NumPy中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)。
NumPy 的数组中比较重要 ndarray 对象属性有:
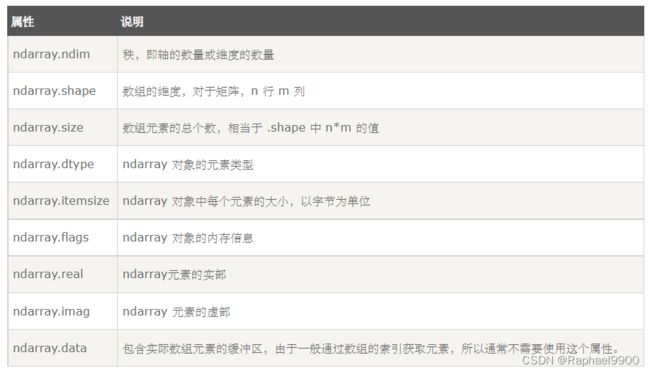
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
a.shape = (3,2) 或者是b = a.reshape(3,2)
print (a) 或者是print(b)
输出:
[[1 2]
[3 4]
[5 6]]
ndarray.itemsize
以字节的形式返回数组中每一个元素的大小。
例如,一个元素类型为 float64 的数组 itemsize 属性值为 8(float64 占用 64 个 bits,每个字节长度为 8,所以 64/8,占用 8 个字节),又如,一个元素类型为 complex32 的数组 item 属性为 4(32/8)。
ndarray.flags

4、NumPy 创建数组
ndarray 数组除了可以使用底层 ndarray 构造器来创建外,也可以通过以下几种方式来创建。
numpy.empty
numpy.empty 方法用来创建一个指定形状(shape)、数据类型(dtype)且未初始化的数组:
numpy.empty(shape, dtype = float, order = ‘C’)

import numpy as np
x = np.empty([3,2], dtype = int)
print (x)
输出:
[[ 6917529027641081856 5764616291768666155]
[ 6917529027641081859 -5764598754299804209]
[ 4497473538 844429428932120]]
#数组元素为随机值,因为它们未初始化。
numpy.zeros
创建指定大小的数组,数组元素以 0 来填充:
numpy.zeros(shape, dtype = float, order = ‘C’)

import numpy as np
#默认为浮点数
x = np.zeros(5)
print(x)
#设置类型为整数
y = np.zeros((5,), dtype = int)
print(y)
#自定义类型
z = np.zeros((2,2), dtype = [(‘x’, ‘i4’), (‘y’, ‘i4’)])
print(z)
输出:
[0. 0. 0. 0. 0.]
[0 0 0 0 0]
[[(0, 0) (0, 0)]
[(0, 0) (0, 0)]]
numpy.ones
创建指定形状的数组,数组元素以 1 来填充:
numpy.ones(shape, dtype = None, order = ‘C’)
5、NumPy 从已有的数组创建数组
numpy.asarray
numpy.asarray 类似 numpy.array
numpy.asarray(a, dtype = None, order = None)

x = [1,2,3] #列表
x = (1,2,3) #元祖
x = [(1,2,3),(4,5)] #元祖列表
numpy.frombuffer
numpy.frombuffer 用于实现动态数组。
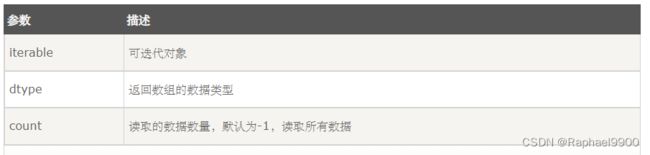
numpy.frombuffer 接受 buffer 输入参数,以流的形式读入转化成 ndarray 对象。
numpy.frombuffer(buffer, dtype = float, count = -1, offset = 0)

numpy.fromiter
numpy.fromiter 方法从可迭代对象中建立 ndarray 对象,返回一维数组。
numpy.fromiter(iterable, dtype, count=-1)
import numpy as np
#使用 range 函数创建列表对象
list=range(5)
it=iter(list)
#使用迭代器创建 ndarray
x=np.fromiter(it, dtype=float)
print(x)
輸出:[0. 1. 2. 3. 4.]
6、NumPy 从数值范围创建数组
numpy.arange
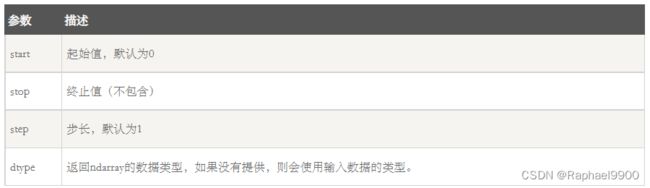
numpy 包中的使用 arange 函数创建数值范围并返回 ndarray 对象,函数格式如下:
numpy.arange(start, stop, step, dtype)
import numpy as np
x = np.arange(5)
print (x)
输出:
[0 1 2 3 4]
import numpy as np
x = np.arange(10,20,2)
print (x)
输出:[10 12 14 16 18]
numpy.linspace
numpy.linspace 函数用于创建一个一维数组,数组是一个等差数列构成的,格式如下:
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)

import numpy as np
a = np.linspace(1,10,10)
print(a)
输出:[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
import numpy as np
a = np.linspace(1,1,10)
print(a)
输出:[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
numpy.logspace
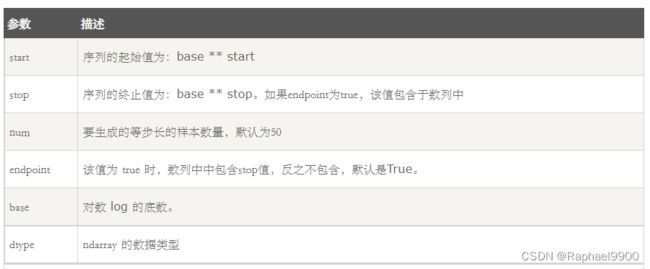
numpy.logspace 函数用于创建一个于等比数列。格式如下:
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
import numpy as np
a = np.logspace(0,9,10,base=2)
print (a)
输出:[ 1. 2. 4. 8. 16. 32. 64. 128. 256. 512.]
NumPy 切片和索引
ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。
ndarray 数组可以基于 0 - n 的下标进行索引,切片对象可以通过内置的 slice 函数,并设置 start, stop 及 step 参数进行,从原数组中切割出一个新数组。
import numpy as np
a = np.arange(10)
s = slice(2,7,2) # 从索引 2 开始到索引 7 停止,间隔为2
print (a[s])
輸出:[2 4 6]
也可以通过冒号分隔切片参数 start:stop:step 来进行切片操作:
import numpy as np
a = np.arange(10)
b = a[2:7:2] # 从索引 2 开始到索引 7 停止,间隔为 2
print(b)
输出:[2 4 6]
冒号 : 的解释:如果只放置一个参数,如 [2],将返回与该索引相对应的单个元素。如果为 [2:],表示从该索引开始以后的所有项都将被提取。如果使用了两个参数,如 [2:7],那么则提取两个索引(不包括停止索引)之间的项。
import numpy as np
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print(a)
#从某个索引处开始切割
print(‘从数组索引 a[1:] 处开始切割’)
print(a[1:])
输出:
[[1 2 3]
[3 4 5]
[4 5 6]]
从数组索引 a[1:] 处开始切割
[[3 4 5]
[4 5 6]]
切片还可以包括省略号 …,来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它将返回包含行中元素的 ndarray。
import numpy as np
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print (a[…,1]) # 第2列元素
print (a[1,…]) # 第2行元素
print (a[…,1:]) # 第2列及剩下的所有元素
输出:
[2 4 5]
[3 4 5]
[[2 3]
[4 5]
[5 6]]
二、self-supervised learning 自监督学习
自监督学习的一个很大的模型是BERT,有340M 的参数。除此之外还有下面的模型,都比BERT大。

GPT-3有175B的参数。

1、self-supervised learning
supervised
假如我们要输入一篇文章x训练我们的模型,模型输出y。我们有标注label y^和y进行对比,这种方法就是有监督的。
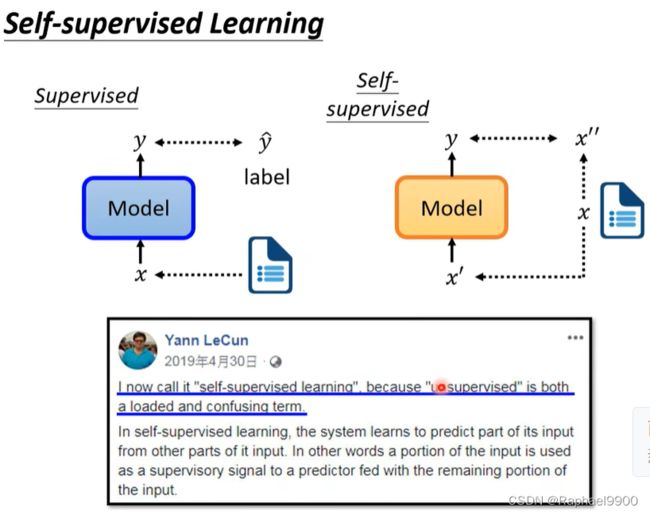
self-supervised
假如我们有一篇无标注的文章x,我们让x分成两部分(x’‘和x’),一部分x’作为模型的输入,另外一部分x’‘作为模型的标注。模型根据输入x’输出y,我们希望y和label x’'越接近越好。这种没有label的学习就是无监督的自监督学习。
BERT做的事情是以下两个:
(1)输入掩码(masking input)
其实bert模型是一个transformer encoder,在这里用在自然语言处理作为例子。BERT的输入是“台湾大学”,之后我们随机对一个输入(“湾”)进行掩码(Randomly masking some tokens)。Token是我们处理一段文字的单位。在这里我们把中文的一个字当成一个token。我们这里进行掩码的操作有两种方法。第一种方法是换成mask(一种特殊的符号,是一种新的字,在字典里面没有出现过)。另外一种方法是随机找一个字代替。在bert模型里面,他随机选择决定用哪一个字进行掩码,以上的两种掩码方式都可以用。在里面输入之后会输出向量序列。对于掩码之后产生的向量,会进行linear的操作(与一个矩阵相乘),然后经过softmax得到输出分布(这个分布是一个非常长的向量,里面有所有的字,每个字都对应一个分数)。

我在接下来你要怎么训练这个BERT呢?BERT不知道被盖起来的是什么字,所以学习的目标就是:输出跟ground truth(真实数据,1-of-hot 向量)越接近越好(最小化交叉熵)。

BERT与Linear一起训练,以确定输出是什么字。除了masking,BERT还做另外的事情:
(2)next sentence prediction
从资料库里面的拿两个句子出来,然后在这两个句子中间加入一个特殊的符号([SEP])代表分隔(区分两个句子)。还会在最前面,整个sequence的最前面,加入一个特别的符号([CLS])。把这个处理完的序列输入BERT里面,看[CLS]对应的输出。他要做的是一个类似二元分类问题,要预测的就是yes or no。这个意思指的是什么呢?就是要预测说这两个句子是不是相接的,如果这两个句子是相接的,他就要训练成看到两个相接的句子就输出yes,看到两个不是相接的句子就输出no。就这样但是后来的研究发现说next sentence prediction对于接下来的事情其实帮助不大。在一篇叫做robustly optimized BERT approach 的论文里面,它的缩写是RoBERTa,就是明确是指是说他尝试了做next sentence prediction这个方法,但是没有什么特别的帮助。接下来会有更多文章说没有用,。他没有用的一个可能是next sentence prediction这个任务可能太简单了,要知道两个句子该不该被接在一起,也许是不是一个特别难的任务。做法就是你先随机选择,接下来选接在他后面的句子,或者是从整个资料库里面随便选一句,那通常随便选一句,跟你一开始选的这一句一定很不像。所以BERT没有借由这一个任务学到太多有用的东西。那后来还有另外一个方法,跟next sentence prediction有点像,大家在文件上看起来是比较有用的,叫做SOP。这个方法是说:我们找出来的句子可能本来就是接在一起的,只是你可能会把本来放在前面的那个句子当和放在后面的那个句子顺序弄反了。可能这个问题比较难,所以 sop目在文件上看起来是有用的。那他被用在一个叫做albert,就是BERT进阶的版本。

BERT怎么用呢?
BERT会做的事情是什么?我们训练的时候就会叫BERT学两个任务,一个是盖住一些词汇,他可以把盖住的部分补回来,知道怎么做填空题。另外一个是它可以预测两个句子是不是应该被接在一起,但这招好像没有什么用,那所以整体而言不能真正学到是什么。他就是学到怎么做填空那好像是不够的!如果我要解的任务不是填空题的话,BERT有什么用呢?我们可以去教会一个模型做填空题以后,然后BERT可以被用在其他的任务上,即使这些任务跟填空题不一定要有关,甚至是根本就没有什么关系,但是可以被用在这些任务上。BERT真正被使用的任务叫做downstream tasks(实际上真正在意的任务)。BERT学会做这些任务的时候,还是需要有一些标准的资料(labeled data)。BERT学到之后就可以分化成各式各样的任务,这叫做微调(fine-tune)。在产生BERT之前的就叫预训练(pre-train)。

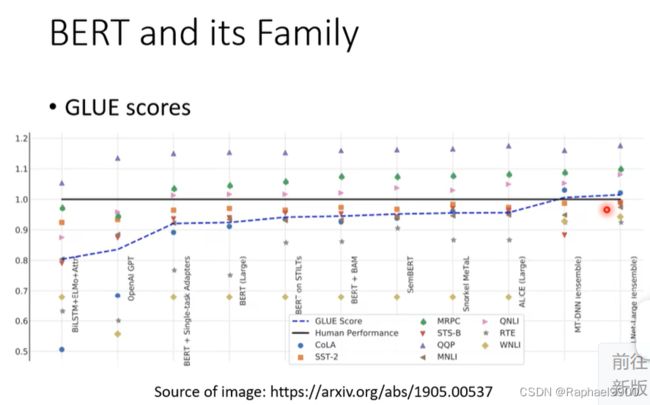
GLUE
要测试一个自监督学习模型的能力,通常会把它测试在多个任务上BERT可以经过微调处理各式各样的任务,所以我们通常不只会测试他在一个任务上的能力。在一个任务集合里面,最知名的一个标杆就叫做GLUE,它是general language understanding的缩写。GLUE里面总共有九个任务。我们让BERT经过微调后去做多个不同的任务,看看他在每个任务上得到的正确率是多少,再取一个平均值,得到一个分数,这个分数代表了这个自监督学习模型的好坏。

在这个图上,横轴是不同的模型,很多都是BERT的变种。黑色的线代表的是人类在这个任务上得到正确率(1)。本来九个任务里面只有一个是机器做的比人好,后来随着越来越多技术被提出来,就有另外三个任务可以做的很好。当然这只是在这一个资料集上面的结果,并不代表说机器超越了人类,他是在这个资料集上超越了人类。这显示的是什么呢?机器对这个资料集玩坏了。接下来有人做了进阶版的资料集。
使用BERT
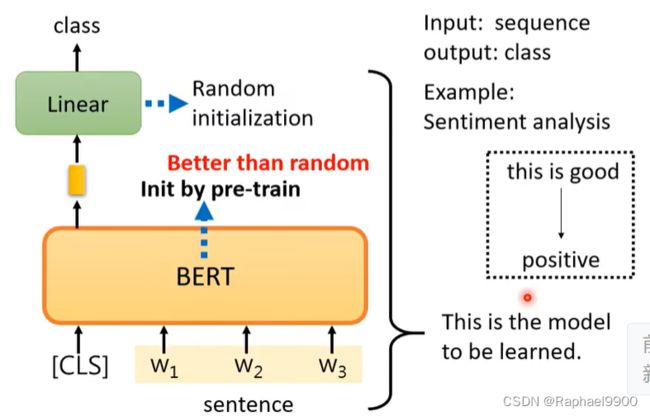
第一个情况
假设我们的下游任务是输入一个序列,输出一个类别,这是一个分类的问题。比如说给机器的句子,要去判断说这个句子是正面的还是负面。那对于BERT而言,他怎么解sentiment analysis的问题呢?
给他一个句子,就是你要拿来sentiment analysis的那一个,然后把这个句子前面一个[CLS]的token,把这个序列输入到BERT里面,去看【CLS】的部分,然后通过linear决定新出类别是什么?正面还是负面。做的时候需要有下游任务的标注,也就是说BERT并没有办法凭空去解一个问题,你仍然需要提供的一些标注的资料给他。比如大量的句子和每一个句子是正面的还是负面的标注,才能够去训练BERT。linear的部分跟都会用radiant decent做。在训练模型的时候,不是会随机初始化一个参数吗?然后用great descent去调那个参数。linear的参数是随机初始化的。但是BERT的参数不再是完全随机初始化,我们是直接把那个学会了做填空题的BERT的参数拿来初始化BERT,事实上这样做的结果会比较好。

有趣的地方是,这个图上有各式各样的任务,随着epoch的增加,训练的loss会降低。在图中,我们有已经进行预训练的模型(fine-tune微调)和随机初始化参数(scratch)的模型。随机初始化参数的模型用虚线,而预训练的模型用实线。在图中可以看出来,进行过预训练的模型的loss下降的比较快,大约在2 epochs就可以下降到零附近。而随机初始化参数的模型会花比较多的时间才能练到较低的loss,而且有些模型即使到了20 epochs也不能训练到跟有预训练模型的相同的水平。

像bert这种模型,它是不是semi-supervised或者unsupervised的模型呢?都是。因为要把BERT应用到下游任务上,下游任务需要有标注的资料。在做预训练的时候用了大量没有标注的资料,但下游任务有少量有标注的资料,所以合起来是semi-supervised半监督学习。
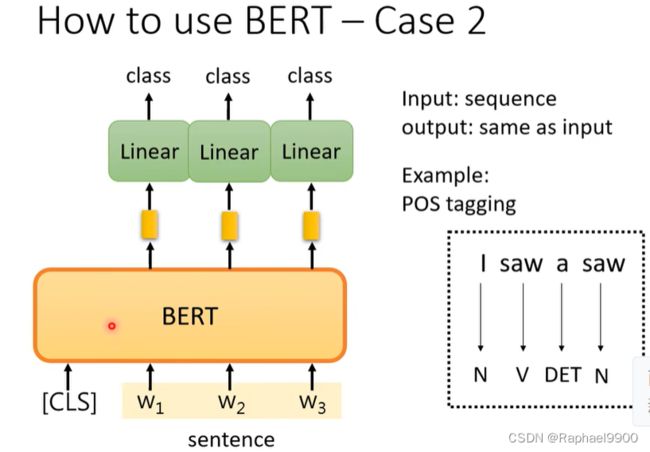
第二个情况
第二个情况是输入一个序列,输出另外一个相同长度的序列。什么样的任务是输入跟输出长度一样的呢?比如说词性标注(POS tagging),你给机器一个句子,机器输出每一个词汇对应的词性。BERT怎么处理这种问题呢?你就给输入一个句子,这个句子里面的每一个token(每个字)有一个对应的向量。经过BERT和linear之后输出每一个词汇属于哪一个类别。这里跟跟一般的分类问题不同的是,我们的BERT不是经过随机选取参数的,而是通过预训练来选取参数的。
第三个情况
输入两个句子,输出一个类别。这边举的都是自然语言处理的例子,也可以把这些例子改成语音的例子或影像的例子。不管是语音还是文字,都可以看作是一排向量。最常见的是natural language inference的例子,缩写是NLI。什么是natural language inference做的事情呢?他要做的是:给机器两个句子,一个句子叫做promise(前提),另外一个句子叫做hypothesis(假设)。机器要做的事情就是,从这个前提能不能够得到这个假设,这个前提是否跟这个假设矛盾。在这个例子里面,我们的前提是有一个人他骑着一个马,然后他跳过了一个坏掉的飞机。这个句子是从一个基础语言库里面拿出来的。假设是这个人在一个小餐馆里面。是吗?不是,这个是矛盾(contradiction)的。所以机器要做的事情就是输入句子,得出这两个句子之间的关系(contradiction、entailment、neutral)。像这样子的任务啊其实很常见,可以用在立场分析里面。

bert怎么解决这个问题呢?
输入两个句子,两个句子中间放一个特殊的符号[SEP],最前面再放[CLS]这个符号,经过BERT输出也会给我们另外一个序列。但是我们只取[CLS]这个部分送到linear里面,然后决定输出什么样的类别。这跟之前是一样的,需要一些标注的资料才有办法训练这个模型,BERT部分不再是随机初始化的而是用预训练模型的参数初始化的。
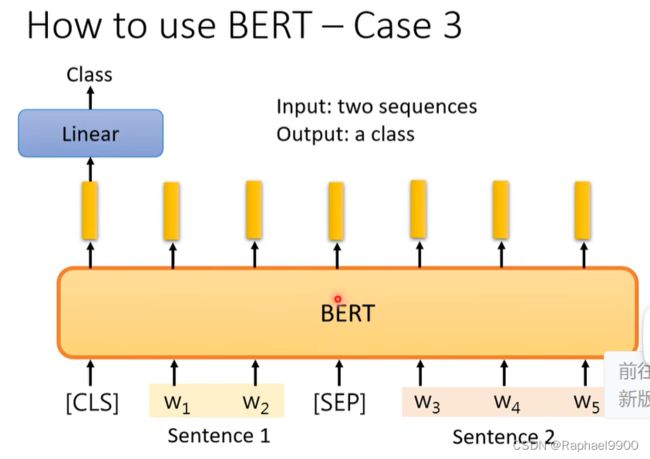
第四个情况
输入一个问题,输出答案。BERT也可以应用在QA问题上。但是这边这个问答不是一般的问答,它是稍微有点限制的问答,这种问答是extraction-base QA,也就是说答案一定出现在文章里面。在这个任务里面,我们的输入有文章(document)和问题(query),不管是文章还是问题,他都是一个序列。如果是中文的话,每一个d就代表了一个中文的字,每一个q也代表了一个中文文字。把Q和D输入到QA模型里面,输出两个正整数s和e。根据这两个正整数直接从文章里面截一个段落出来就是答案。意思就是说从这个文章里面的第s个字到第e个字,串起来就是正确答案。这个其实是今天非常标准的做法,就是我第一次听到说做这个五六年前第一次听到说做QA的时候居然是读一篇文章,给一个问题输出两个正整数就是答案。现在有一篇文章有一个问题,那机器怎么输出问题的正确答案的?看下图

BERT也是取经过预训练的模型的参数的。怎么用BERT解QA的问题呢?这个解法是这个样子的,文章跟问题中间有一个特殊的符号[SEP],前面有个[CLS],把这个序列放到BERT输入。那在这整个任务里面,唯一需要使用随机初始化参数的只有两个向量,这边用橙色的向量跟蓝色的向量来表示,这两个向量长度跟BERT的输出长度是一样的。那接下来呢怎么使用这两个向量呢?先把橙色的拿出来,分别跟对应到文章这个部分所输出的向量。文章那边输入三个token,这边就输出三个向量,把这三个向量都跟橙色的这个向量做一个内积算出三个数字。接下来我得到三个数字,接下来看哪里分数最高。中间的向量得到分数最高吗?那s=2表示文章的起始的位置为2的就是输出了。蓝色的向量也做一模一样的事情,输出代表结束的位置。

理论上BERT的模型的输入没有长度限制,因为BERT的模型是一个transfomer encoder。但是实际上不能输入很长的序列,因为需要做self-attention(计算量很大)。最长可能就在512了。

我们能不能做一个BERT来处理“填空题”的问题呢?这个真的是没办法做,自己训练不起来。当初最早设计BERT的Google用的资料量也已经非常精准,他的资料量有三个billion的词汇。实验室有个助教试图自己训练ALBERT-base(BERT的升级版),所以在这个图上面,纵轴代表的是GLUE的分数,横轴就是训练的过程。助教用TPU训练了1M十万次用了八天。

为什么要自己把它做出来,为什么我们要自己训练一个BERT呢?这些模型都是公开的,我们自己训练一个,而且结果跟谷歌的BERT差不多,到底有什么意义呢?这边想要做的事情,其实是想要建立bert的胚胎学。是什么意思呢?我知道BERT的训练过程,需要耗费非常大的运算资源。所以我们想要知道有没有什么可能去节省这个运算资源,想要知道怎么让他训练更快一点,也许我们可以从观察他的训练过程开始。过去从来没有人观察过BERT的训练过程,因为谷歌直接告诉你他在各个任务上都做的很好,那实际上在训练的过程中到底学到了什么事情?这个过程中他什么时候学会填动词,什么时候学会填名词,什么时候学会填代名词,没有人去研究过这件事情。我们自己训练了一个BERT以后,我们就可以观察BERT在什么时候学会填什么样的词汇,知道它的填空的能力是怎么增进的。得到的结论跟我们想象的是不太一样的。
预训练一个seq2seq的模型
刚才讲的那些任务都没有包括seq2seq model,那如果我们今天要做的任务是seq2seq model怎么办呢?Bert其实也可以预训练decoder。有一个seq2seq model,输入一串句子,输出是一串句子,中间cross attention连接在一起。我们给encoder的输入增加干扰噪声,使得输出的结果不是原来的结果。然后decoder希望输出的句子跟干扰前是一模一样的,看到弄坏的结果,然后要输出还原弄坏前的结果。
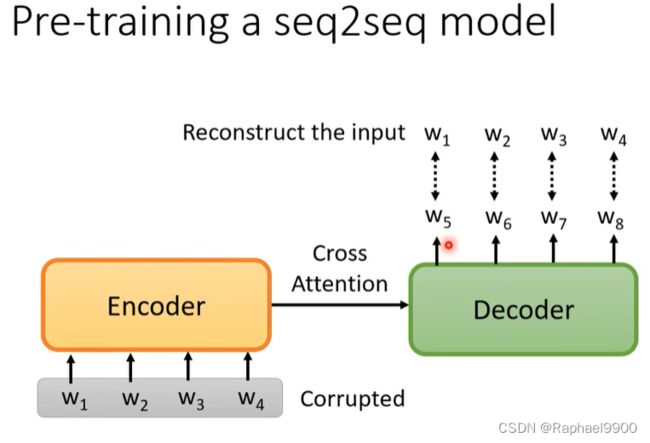
那怎么干扰呢?就有各种不同的方法,有一个方法叫做MASS,里面就说这个弄坏的方法就跟BERT一样,把一些地方盖起来。那后来还有各式各样弄坏的方法,比如说把一些词汇删掉,把输入的数据弄乱,词汇的顺序做一个旋转,然后还有同时盖住和删掉的方法,然后再请seq2seq model把它还原回来。有一篇论文r叫做BART,他就是把这些方法一股脑的都用上去,发现都用所有的方法可能结果是更好。

有这么多干扰的方法,哪种方法比较好呢?谷歌都帮你做完了,有一篇论文叫做T5(transfer text-to-text transformer),T5做了各式各样的尝试,长达67页。T5训练在一个叫C4(colossal clean crawled corpus)的数据集上,C4是非常大的。

why does BERT work?
为什么BERT会有用呢?
常见的解释方法:输入一串文字,每一个文字都有个对应的向量,这个向量叫做embedding(代表了每个字的意思)。比如说输入台湾大学,输出四个向量,这四个向量分别就代表台湾大学。相似意思的token会有相似的embedding。更具体而言是假设你把这些字对应的向量把它画出来,发现意思越相近的字他们的向量就越接近。比如草跟果是植物,他们的向量就比较接近。但是中文有一字多义的问题,Bert它可以考虑上下文,所以同一个字,比如说都是果这个字,它的上下文不同,它的向量是不会样。可以吃的苹果的果跟苹果手机的果这两个果统统都是果,但是根据上下文它的意思不同,所以它的向量对应的分布就非常不一样。
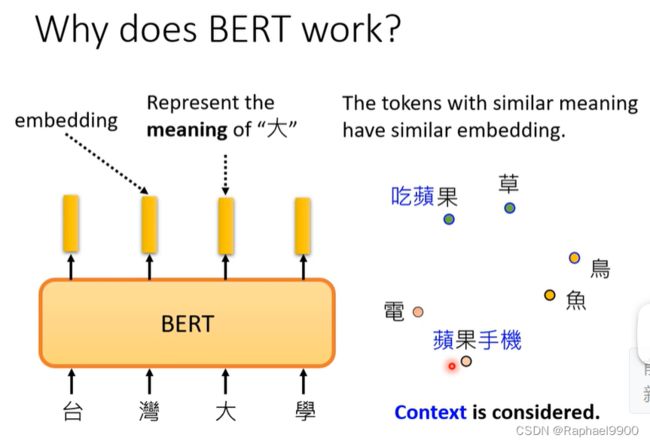
接下来就看真实的例子。
假设我们现在就考虑果这个字,那我们就收集很多有提到果这个字的句子,比如说喝苹果汁,苹果电脑等等。那我们把这些句子都丢到BERT里面,再去计算每一个果所对应的embedding。下面的两个果不一样,因为这是一个encoder(里面含有self-attention),所以根据我上下文的不同,得到向量会不一样。接下来我们计算这些果之间的余弦相似度(cosine)得到的结果。
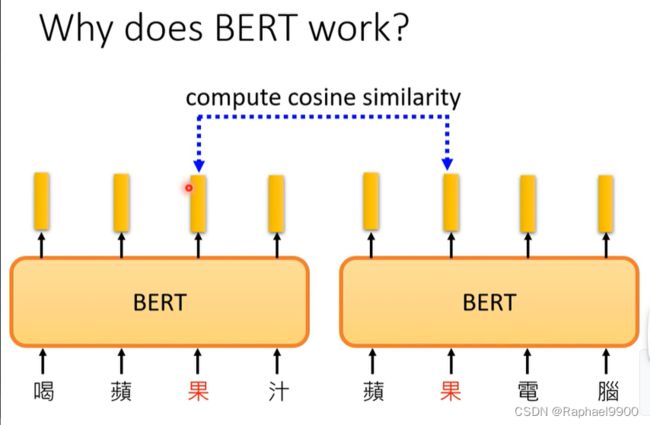
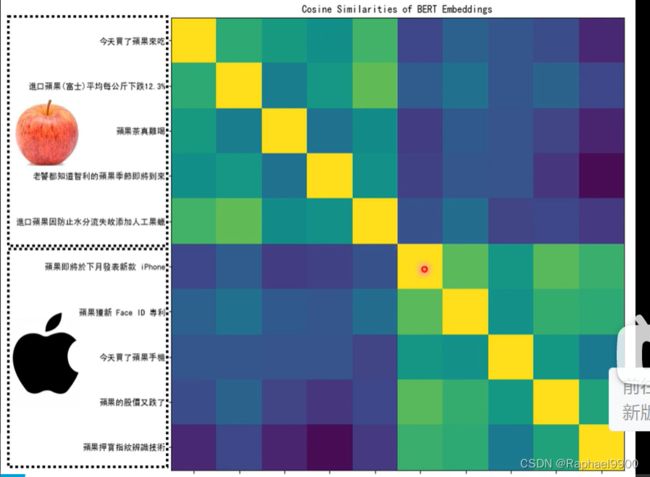
这边选了十个句子,观察得到的结果。前五个句子里面的果都代表了可以吃的苹果,后五个句子代表苹果手机的果。这边有十个组,两两之间。会得到embedding的余弦相似度。偏黄色代表相似度大,前五个组上相似度比较高,后五个组之间的相似度也比较高,但是他们分别求相似度就低。 也就是说BERT能够分辨这两种果的语义。
输出来的向量,每个向量代表了那个词的意思。所以说bert在训练做填空题的过程中,他学会了每一个中文字有什么样的意思,Bert也许真的了解了中文的意思。对他来说,每个中文的符号不再是没有关系的,他了解了中文的意思,所以他可以在接下来的任务做的更好。为什么我们说这些向量可以代表那个字的意思呢?我们是基于一个科学的假设。也就是1960年代的一个语言学家提出来的,我们需要看一段文字的上下文,才能知道这个词汇的意思。BERT在做的事情就是在学会做填空题的过程中去查看上下文来抽取信息,最后得到输出。在下面的例子中,我们从w1w3w4中抽取信息分析w2是什么,然后bert就能预测w2。过去有一个技术跟bert很像,叫word embedding,可以根据上下文得到中间。但是它是只有两层transformer。为什么不用更多的transformer或者用CNN呢?因为那时候的计算量比较小。但是bert能做到很高的计算量。他就能理解出上下文的意思得到这个词的embedding,能区分一个相同的词在具有不同的上下文的时候有不一样的意思,这种叫contextualized word embedding。

我们把训练在文字上的BERT拿来做蛋白质的分类,DNA的分类或者是音乐的分类。我们就拿DNA的分类做例子吧,dna就是一连串去氧核糖核酸,去氧核糖核酸有四种分别用C\T\A\G来表示。我们要做DNA分类的问题,就是给一串DNA,要决定这个DNA属于什么类型。一个分类的问题,label资料训练下去就结束了。

把组成DNA序列的四个基本脱氧核糖核酸用ATCG表示。然后我们把atcg分别赋予不同的含义,如下,然后在句子前面加上[CLS]输入到bert里面,经过linear输出一个class。在这里我们的bert是经过预训练的,而linear是随机参数初始化的。

然后一下做了一个实验,蛋白质、DNA和音乐分别用词汇来表示。有四个模型一起做实验,可以发现在BERT里面,我们的结果是非常好的。

虽然不知道为什么,但是BERT确实是很好的。就算给他是乱七八糟的东西,他也能训练的很好。
multi-lingual BERT
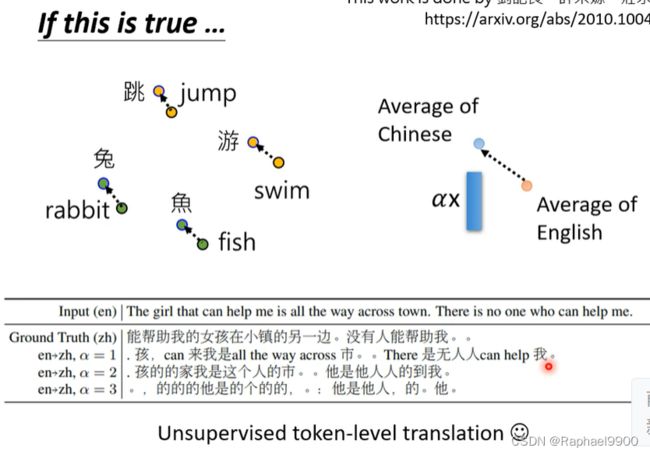
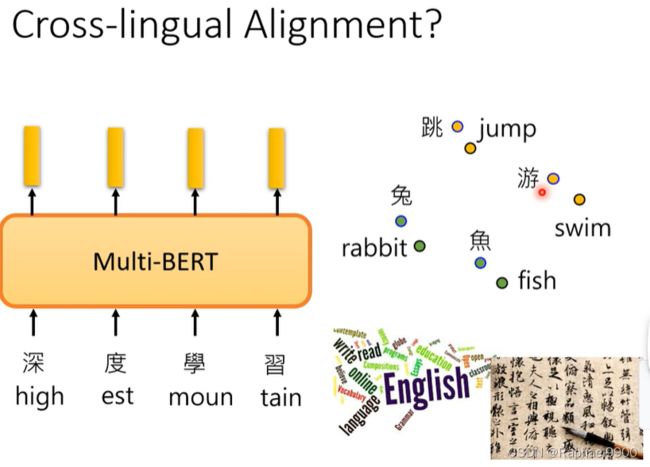
接下来有一个multi-lingual bert,我们可以用不同国家的语言去训练这个模型。

这个模型用104种语言来训练。如果我们用英语做问答训练的例子来训练这个模型的话,它就能自动用中文的问答测试(预训练是104中语言参与的,但是它只会做填空,然后做了微调之后只用一种语言训练就能做另外一种语言的QA测试)。人类也只能到93.3%。

也许在看过大量语言过程中学会了同样意思不同语言之间embedding的关系。
MRR越高越好。

自己训练是数据量是不是太多了?增加数据之后:前面没有变化,但是后面会下降!资料量是需要的!

虽然他会用不同的语言测试,但是实际上BERT还是知道不同语言的符号的。
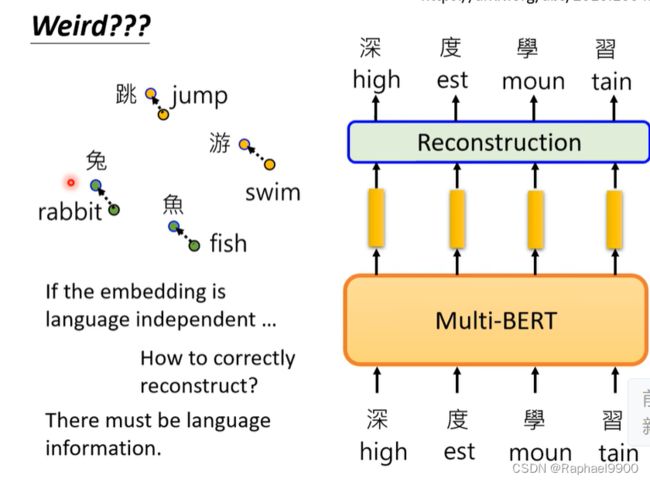
不同语言之间确实有一个差异,这里是举例中文和英文的:如果输入中文,如果我们假设这个差异,就能得到中文的意思。

虽然翻译的不是很准确,但是不同语言之间的信息还是藏在多语言BERT里面的。