Python+Pandas+Pymsql爬取全国各省市疫情数据并写入MySQL数据库
许久鸽着没有更新了,想弄一部matlab的教程合集,这段时间除了搞其他的,也是拿了一部分精力到我的公众号建设上来....
这个想法确实是我一时发生的灵感,所以说干就干,经过[艰苦努力]之后,写好了这个程序的脚本
这一篇的话虽然其实也没有太大难度,不过涉及到一些正则表达式utf8转换和数据库写入的问题。
一、相关配置
1. MySQL+ Navicat for MySQL:Mysql是一款Oracle旗下的,非常通用的数据库。而Navicat可以将指令化的数据库操作直接以用户图形的界面给用户操纵,大大方便了数据库的操作和读取
2. python扩展库:
urllib 扩展库(爬虫库)
pandas 扩展库(是一个可以真正利用python创建向量和矩阵的扩展库,也是一个数学和数据分析库)
pymsql 扩展库(进行python和mysql的对接)
sqlalchemy 扩展库(由于pymysql写入数据库会不成功,使用这个库来进行写入)3.首先你要使用navicat在localhost下创建一个名为epidemic的数据库,如图

二、 我们来梳理一下整个程序的全过程
首先,通过urllib爬取疫情界面的代码,用正则表达式re将其中的数据匹配后提取出,由于是以utf-8编码的,所以我们还需要将其中中文utf8编码的部分转换为中文,然后将其写入字典,利用Pandas将字典转化为DataFrame类型,然后将其写入mysql数据库。
下面是一些注意事项:
(1) 在爬取Url之前,有的网站应当伪造浏览器的头部,假装是浏览器内部正常访问,(在这个里面14行演示伪造浏览器的头部(虽然对于这个百度网址根本不需要伪造))
(2)下来就是三个pattern(很长的正则表达式),为了爬取完整的省疫情信息我修改了三次:
一般省的疫情信息如下(这里以山东省的为例):
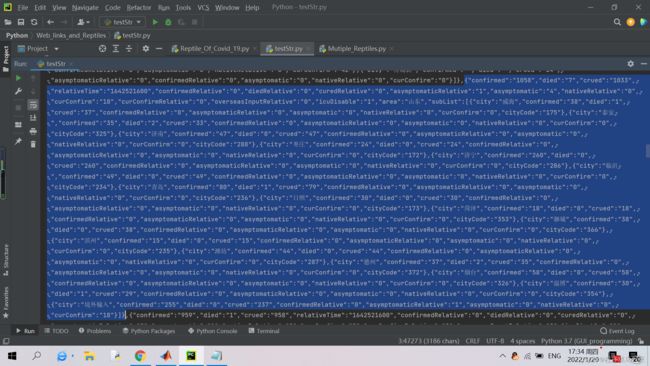
因为我们分开爬取省和市的信息(由于市可以由关键字“city”来确定,但爬取市后确定其所在的省还是比较难的,最便捷的方法是直接建个省市对应字典,然后加上前缀,这里就分开爬取了,不加前缀)
一般的省的数据格式都是:
{"confirmed":"12880","died":"213","crued":"12474","relativeTime":"1642521600","confirmedRelative":"7","diedRelative":"0","curedRelative":"28","asymptomaticRelative":"0","asymptomatic":"0","nativeRelative":"0","curConfirm":"193","curConfirmRelative":"-21","overseasInputRelative":"","icuDisable":"1","area":"广西" #这是数据形式 但是通过这样的数据形式只能匹配到23个省,后来我又进行了三方面的正则表达式修复:
# 1 有的省含有"cityCode":"2912"这一项
通过修改正则表达式("cityCode":"(\d*?)",)*?的一段,保证这一段可加可不加
# 2 部分省"curConfirmRelative"有的省的数据为负数
# 正则表达式中,匹配数字的字符无法匹配复数,所以要有一个可加可不加的负号放在"curConfirmRelative"后面
# 3 单独对于北京市:多了"confirmInter":"1"的一项,通过修正了以上三个内容后,可完整地爬取34个省的内容
另外我也附上我专门复制的处理前的数据
链接:https://pan.baidu.com/s/1tuJIpu4qoYZ9TFc_AekfRw
提取码:cheu
(3)如何将字符串中的'\uabcd'转换为中文的问题:
一般使用decode等方法是肯定不行的,方法是使用eval来将字符串嵌入到代码中,比如A.append('\u7058\u8a34')时,计算机会自动使用utf8转义。
(4)使用create_enging和to_sql写入数据库的问题
这里主要是注意一下格式吧,确实我因为这个没少掉坑,这个会在那里有详细注释
三、程序代码
(注意:其中数据库连接时,host = "127.0.0.1"一般是不用动的,但你需要设定两个密码,这里假定我的密码为password)
# 使用python爬取全国各省市疫情数据并且写入MySQL数据库
# import requests as Req
import urllib.request as ureq
from urllib.request import Request,urlopen
import re
# import numpy as np # 使用numpy和pandas是两种性能优越的数据处理库,这一篇用不上numpy
import pandas as pd
import pymysql as sql
from sqlalchemy import create_engine
url = r'https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_aladin_banner#tab4';
# 这是设置需要打开的url
# ----接下来伪造浏览器的头部,假装是使用浏览器从网页内部正常访问----------------
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36',
'Referer':url}
#(其实这一块对于这个网站可以不加,但有的设置反爬机制的网站不加这个会有防盗链)----
req = Request(url=url,headers = headers)
with ureq.urlopen(req) as WebPage:
content = WebPage.read().decode(encoding ='utf8')
pattern_1 = r'{"confirmed":"(\d*?)","died":"(\d*?)","crued":"(\d*?)","relativeTime":"(\d*?)","confirmedRelative":"(\d*?)","diedRelative":"(\d*?)","curedRelative":"(\d*?)","asymptomaticRelative":"(\d*?)",("confirmInter":"(\d*?)",)*?"asymptomatic":"(\d*?)","nativeRelative":"(\d*?)","curConfirm":"(\d*?)","curConfirmRelative":"((-?)\d*?)",("cityCode":"(\d*?)",)*?"overseasInputRelative":"(\d*?)","icuDisable":"(\d*?)';
pattern_2 = r'"area":"(.+?)"'
pattern_3 = r'{"city":"([\\a-z0-9]+?)","confirmed":"(\d*?)","died":"(\d*?)","crued":"(\d*?)","confirmedRelative":"(\d*?)","asymptomaticRelative":"(\d*?)","asymptomatic":"(\d*?)","nativeRelative":"(\d*?)","curConfirm":"(\d*?)","cityCode":"(\d*?)"}'
# 注意pattern_3中最后一个使用+,不用+?
# 如果pattern过长可能会出现错误导致匹配不了了
# 非常注意是city的哪一项需要加上+?
# 对于方括号,为了避免匹配内部的字符,需要在第一个括号前加上\
#-------------正则表达式修复过程------------------------
# 第一次:(修复4个城市有"cityCode":"(\d*?)"项的问题)
# 第二次修复香港等6城市格式:
# {"confirmed":"12880","died":"213","crued":"12474","relativeTime":"1642521600","confirmedRelative":"7","diedRelative":"0","curedRelative":"28","asymptomaticRelative":"0","asymptomatic":"0","nativeRelative":"0","curConfirm":"193","curConfirmRelative":"-21","cityCode":"2912","overseasInputRelative":"","icuDisable":"1","area":"香港"
# "curConfirmRelative":"((\-?)\d*?)"修复该项可为负数的问题
# 第三次:修复北京格式有"confirmInter":"1"项的问题
# {"confirmed":"1240","died":"9","crued":"1203","relativeTime":"1642521600","confirmedRelative":"4","diedRelative":"0","curedRelative":"0","asymptomaticRelative":"2","confirmInter":"1","asymptomatic":"49","nativeRelative":"3","curConfirm":"28","curConfirmRelative":"4","cityCode":"131","overseasInputRelative":"1","icuDisable":"1","area":"北京"
#-----------------数据处理部分--------------------
ZoneData = re.findall(pattern_1,content,re.M) # 最后一项实际上是re.match
# ZoneData得到的数据是省的部分
ZoneName = re.findall(pattern_2,content,re.M)
# 省名集合
CityData = re.findall(pattern_3,content,re.M)
ZoneResult =[];
Confirmed =[]; #累计确诊
Died = []; #累计死亡
Cured =[]; #累计治愈
ConfirmedRelative =[]; # 新增确诊
DiedRelative = []; # 新增死亡
CuredRelative = []; # 新增治愈
AsymptomaticRelative = []; # 新增无症状感染者
# 这里是建立字典存储数据
for i in range(len(ZoneData)): # 共有34个省
Zone_Name=re.sub('\\\\u',r'\\u',ZoneName[i])
eval('ZoneResult.append("'+Zone_Name+'")')
# 通过eval函数,利用这种样子的方式,将带有一个反斜杠的字符串转化为转义中文字符
Confirmed.append(ZoneData[i][0])
Died.append(ZoneData[i][1])
Cured.append(ZoneData[i][2])
ConfirmedRelative.append(ZoneData[i][4])
DiedRelative.append(ZoneData[i][5])
CuredRelative.append(ZoneData[i][6])
AsymptomaticRelative.append(ZoneData[i][7])
dic = {"地区":ZoneResult,"累计确诊":Confirmed,"累计死亡":Died,"累计治愈":Cured,
"新增确诊":ConfirmedRelative,"新增死亡":DiedRelative,"新增治愈":CuredRelative,
'新增无症状感染':AsymptomaticRelative}
DB = pd.DataFrame(dic)
print(DB)
CityName = [];
CityConfirmed = [];
CityDied = [];
CityCured = [];
CityConfirmedRelative = [];
CityAsymptomaticRelative =[];
CityCode = []; # 城市号
for i in range(len(CityData)):
eval("CityName.append("+"\""+CityData[i][0]+"\")")
CityConfirmed.append(CityData[i][1])
CityDied.append(CityData[i][2])
CityCured.append(CityData[i][3])
CityConfirmedRelative.append(CityData[i][4])
CityAsymptomaticRelative.append(CityData[i][5])
CityCode.append(CityData[i][9])
dic2 = {"城市号":CityCode,"城市名":CityName,"累计确诊":CityConfirmed,"累计死亡":CityDied,
"累计治愈":CityCured,"新增确诊":CityConfirmedRelative,"新增无症状感染者":CityAsymptomaticRelative}
DB_2 = pd.DataFrame(dic2)
print(DB_2)
# r'{"city":"([\\a-z0-9]+?)","confirmed":"(\d*?)","died":"(\d*?)","crued":"(\d*?)","confirmedRelative":"(\d*?)",
# "asymptomaticRelative":"(\d*?)","asymptomatic":"(\d*?)","nativeRelative":"(\d*?)","curConfirm":"(\d*?)","cityCode":"(\d*?)"}'
#---------------写入区块---------------------------
def connect():
conn = sql.connect(host="127.0.0.1",
port=3306, #设置端口号
user='root',
password='password',
db='epidemic',
charset='utf8'
) # 连接MySQL数据库
return conn
# 注意参数db在这里是连接localhost下的数据库名称,也可以使用database=...,
# 这里连接的是我在localhost下建的库epidemic
# 使用数据库创建一个游标对象cursor
# 选中数据库epidemic
# cursor.execute()可以执行sql语句
try:
conn = connect()
cursor = conn.cursor();
DB.to_sql("province_data",conn,if_exists='append',index=False)
DB_2.to_sql("City_Data",conn,if_exists='append',index=False)
# ------ 这个基本上不管用----------------
except:
# 基本格式:
engine = create_engine('mysql+pymysql://root:[email protected]:3306/epidemic?charset=utf8')
# 注意一般格式: engine = create_engine("mysql+pymysql://user:密码@host:port/数据库名称?charset=utf8")
con = engine.connect() # connect一定要加
DB.to_sql(name="province_data",con=engine,if_exists='replace',index=False);
# 第一个参数是表名,第三个参数是replace时,会自动新建表格,是append时,不会新建
DB_2.to_sql(name="city_data",con=engine,if_exists='replace',index=False);
# 注意if_exists参数,参数为replace时,如果表已经存在则报错,不存在创建表
# 参数为append时,将数据写在表后方
print("写入数据库成功");
conn.close() # 关闭连接
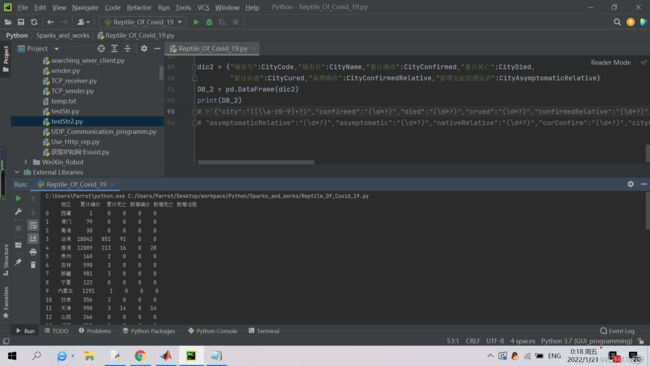
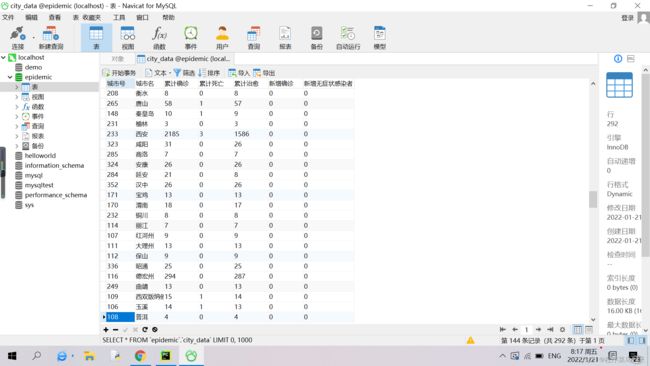
四、运行结果:

五、声明
本文同步至微信公众号“FPRSP的小屋”以及CSDN"程序菜鸟一只",转载请附上原文链接