基于大数据spark+hadoop的图书可视化分析系统
作者主页:计算机毕设老哥
精彩专栏推荐订阅:在 下方专栏Java实战项目专栏
Python实战项目专栏
安卓实战项目专栏
微信小程序实战项目专栏
文章目录
-
- Java实战项目专栏
- Python实战项目专栏
- 安卓实战项目专栏
- 微信小程序实战项目专栏
- 一、开发介绍
-
- 1.1 开发环境
- 二、系统介绍
-
- 2.1图片展示
- 三、部分代码设计
- 总结
- 有问题评论区交流
-
- Java实战项目专栏
- Python实战项目专栏
- 安卓实战项目专栏
- 微信小程序实战项目专栏
一、开发介绍
1.1 开发环境
-
技术栈:spark+hadoop+hive
-
离线ETL+在线数据分析 (OLAP)+流计算+机器学习+图计算
二、系统介绍
2.1图片展示
注册登录页面: 大数据可视化分析模块:
大数据可视化分析模块: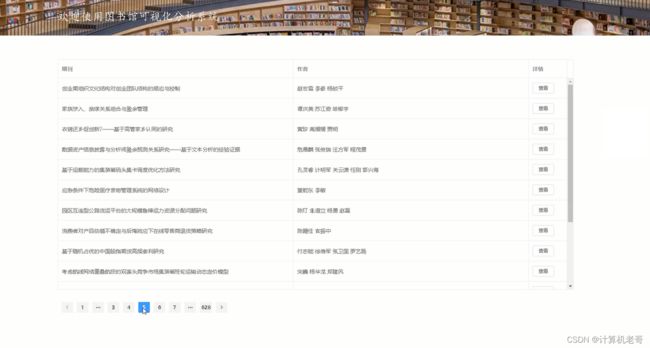
 管理员后面模块:
管理员后面模块:
三、部分代码设计
package org.pact518
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.recommendation._
import org.apache.spark.rdd.RDD
import scala.math.sqrt
import org.jblas.DoubleMatrix
object alsBatchRecommender {
private val minSimilarity = 0.6
def cosineSimilarity(vector1: DoubleMatrix, vector2: DoubleMatrix): Double = vector1.dot(vector2) / (vector1.norm2() * vector2.norm2())
def calculateAllCosineSimilarity(model: MatrixFactorizationModel, dataDir: String, dateStr: String): Unit = {
//calculate all the similarity and store the stuff whose sim > 0.5 to Redis.
val productsVectorRdd = model.productFeatures
.map{case (movieId, factor) =>
val factorVector = new DoubleMatrix(factor)
(movieId, factorVector)
}
val productsSimilarity = productsVectorRdd.cartesian(productsVectorRdd)
.filter{ case ((movieId1, vector1), (movieId2, vector2)) => movieId1 != movieId2 }
.map{case ((movieId1, vector1), (movieId2, vector2)) =>
val sim = cosineSimilarity(vector1, vector2)
(movieId1, movieId2, sim)
}.filter(_._3 >= minSimilarity)
productsSimilarity.map{ case (movieId1, movieId2, sim) =>
movieId1.toString + "," + movieId2.toString + "," + sim.toString
}.saveAsTextFile(dataDir + "allSimilarity_" + dateStr)
productsVectorRdd.unpersist()
productsSimilarity.unpersist()
}
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("alsBatchRecommender").set("spark.executor.memory", "2g")
val sc = new SparkContext(conf)
if (args.length < 1) {
println("USAGE:")
println("spark-submit ... xxx.jar Date_String [Iteration]")
println("spark-submit ... xxx.jar 20160424 10")
sys.exit()
}
val dateStr = args(0)
val iterations = if (args.length > 1) args(1).toInt else 5
val dataDir = "hdfs://master:9001/leechanx/netflix/"
val trainData = sc.textFile(dataDir + "trainingData.txt").map{ line =>
val lineAttrs = line.trim.split(",")
Rating(lineAttrs(1).toInt, lineAttrs(0).toInt, lineAttrs(2).toDouble)
}.cache()
val (rank, lambda) = (50, 0.01)
val model = ALS.train(trainData, rank, iterations, lambda)
trainData.unpersist()
calculateAllCosineSimilarity(model, dataDir, dateStr) //save cos sim.
model.save(sc, dataDir + "ALSmodel_" + dateStr) //save model.
val realRatings = sc.textFile(dataDir + "realRatings.txt").map{ line =>
val lineAttrs = line.trim.split(",")
Rating(lineAttrs(1).toInt, lineAttrs(0).toInt, lineAttrs(2).toDouble)
}
val rmse = computeRmse(model, realRatings)
println("the Rmse = " + rmse)
sc.stop()
}
def parameterAdjust(trainData: RDD[Rating], realRatings: RDD[Rating]): (Int, Double, Double) = {
val evaluations =
for (rank <- Array(10, 50);
lambda <- Array(1.0, 0.0001);
alpha <- Array(1.0, 40.0))
yield {
val model = ALS.trainImplicit(trainData, rank, 10, lambda, alpha)
val rmse = computeRmse(model, realRatings)
unpersist(model)
((rank, lambda, alpha), rmse)
}
val ((rank, lambda, alpha), rmse) = evaluations.sortBy(_._2).head
println("After parameter adjust, the best rmse = " + rmse)
(rank, lambda, alpha)
}
def computeRmse(model: MatrixFactorizationModel, realRatings: RDD[Rating]): Double = {
val testingData = realRatings.map{ case Rating(user, product, rate) =>
(user, product)
}
val prediction = model.predict(testingData).map{ case Rating(user, product, rate) =>
((user, product), rate)
}
val realPredict = realRatings.map{case Rating(user, product, rate) =>
((user, product), rate)
}.join(prediction)
sqrt(realPredict.map{ case ((user, product), (rate1, rate2)) =>
val err = rate1 - rate2
err * err
}.mean())//mean = sum(list) / len(list)
}
def unpersist(model: MatrixFactorizationModel): Unit = {
// At the moment, it's necessary to manually unpersist the RDDs inside the model
// when done with it in order to make sure they are promptly uncached
model.userFeatures.unpersist()
model.productFeatures.unpersist()
}
}
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.github.hellowzk</groupId>
<artifactId>light-spark</artifactId>
<version>1.0.4-release</version>
<packaging>pom</packaging>
<!--<parent>
<groupId>org.sonatype.oss</groupId>
<artifactId>oss-parent</artifactId>
<version>7</version>
</parent>-->
<modules>
<module>light-spark-core</module>
<module>assembly</module>
<module>example</module>
</modules>
<properties>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.encoding>${project.build.sourceEncoding}</java.encoding>
<java.version>1.8</java.version>
<scala.encoding>${project.build.sourceEncoding}</scala.encoding>
<scala.version.major>2.11</scala.version.major>
<scala.version>${scala.version.major}.12</scala.version>
<spark.version.pre>2.2</spark.version.pre>
<spark.version>${spark.version.pre}.3</spark.version>
<hbase.version>1.4.3</hbase.version>
<hadoop.version>2.6.0-cdh5.13.0</hadoop.version>
<spark.deploy.mode>cluster</spark.deploy.mode>
<app.build.profile.id></app.build.profile.id>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<version>3.0.2</version>
<configuration>
<nonFilteredFileExtensions>
<nonFilteredFileExtension>sh</nonFilteredFileExtension>
<nonFilteredFileExtension>conf</nonFilteredFileExtension>
<nonFilteredFileExtension>json</nonFilteredFileExtension>
<nonFilteredFileExtension>txt</nonFilteredFileExtension>
<nonFilteredFileExtension>xlsx</nonFilteredFileExtension>
</nonFilteredFileExtensions>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.7.0</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.1</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<jvmArgs>
<jvmArg>-Xms64m</jvmArg>
<!--可以在测试环境修改为1024m,提交时为2048m-->
<!--<jvmArg>-Xmx1024m</jvmArg>-->
<jvmArg>-Xmx2048m</jvmArg>
</jvmArgs>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-${java.version}</arg>
</args>
</configuration>
</plugin>
<!--生成javadoc包的插件-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-javadoc-plugin</artifactId>
<version>2.9.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>jar</goal>
</goals>
</execution>
</executions>
</plugin>
<!--生成java源码包插件(仅对java有用,对scala不管用) source-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-source-plugin</artifactId>
<version>3.0.1</version>
<executions>
<execution>
<id>attach-sources</id>
<goals>
<goal>jar-no-fork</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
<profiles>
<profile>
<id>dev</id>
<properties>
<app.build.profile.id>dev</app.build.profile.id>
</properties>
</profile>
<profile>
<id>spark2.2</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<properties>
<spark.version.pre>2.2</spark.version.pre>
</properties>
</profile>
<profile>
<id>spark2.3</id>
<properties>
<spark.version.pre>2.3</spark.version.pre>
</properties>
</profile>
<profile>
<id>spark2.4</id>
<properties>
<spark.version.pre>2.4</spark.version.pre>
</properties>
</profile>
</profiles>
<distributionManagement>
<snapshotRepository>
<id>ossrh</id>
<url>https://oss.sonatype.org/content/repositories/snapshots/</url>
</snapshotRepository>
<repository>
<id>ossrh</id>
<url>https://oss.sonatype.org/service/local/staging/deploy/maven2/</url>
</repository>
</distributionManagement>
</project>
总结
大家可以帮忙点赞、收藏、关注、评论啦
有问题评论区交流
精彩专栏推荐订阅:在 下方专栏
Java实战项目专栏
Python实战项目专栏
安卓实战项目专栏
微信小程序实战项目专栏