3DCNN,3D卷积神经网络,动作识别
为了学习3d卷积,看了一篇相关的论文,参考博客论文复现将论文和代码理解一遍。源代码没有注释,在这篇文章中我按照自己的理解写好重要地方的注释,数据集请进入博客中获取,博主贴了数据的百度网盘
一、在这份代码中首先处理视频数据。
1、
videoto3d.py
import matplotlib.pyplot as plt
import numpy as np
import cv2
class Videoto3D:
def __init__(self, width, height, depth):
self.width = width
self.height = height
self.depth = depth
def video3d(self, filename, color=False, skip=True):
cap = cv2.VideoCapture(filename)#捕获视频
nframe = cap.get(cv2.CAP_PROP_FRAME_COUNT)#获取视频的帧数
if skip:
#从第0帧开始,每隔总帧数的1/15取出一帧,即每个视频取出16帧
frames = [x * nframe / self.depth for x in range(self.depth)]
else:
frames = [x for x in range(self.depth)]
framearray = []#用于存储经过后面处理的16帧图像
for i in range(self.depth):
cap.set(cv2.CAP_PROP_POS_FRAMES, frames[i])#设置截取的下一帧的索引
ret, frame = cap.read()
frame = cv2.resize(frame, (self.height, self.width))#resize后每张从视频中截取的图像变成32x32x3
if color:#如果color是True(即RGB图像)则直接合并到framearray,否则先转化为灰度图再合并
framearray.append(frame)
else:
framearray.append(cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY))
cap.release()
return np.array(framearray)#返回包含所有处理后的图像的framearray
# 输入视频,由于数据集名称类似于v_ApplyEyeMakeup_g01_c01.avi前两个下划线“_”之间是这类视频的类名,所以用这个函数提取出类名
def get_UCF_classname(self, filename):
return filename[filename.find('_') + 1:filename.find('_', 2)]
2、
在def loaddata(video_dir, vid3d, nclass, result_dir, color=False, skip=True):函数中,video_dir是传入的数据文件夹地址
vid3d是定义的一个对象,定义这个对象时用构造函数传入的参数是对应视频需要的图像的行数和列数以及每个视频要提取多少帧。
这个定义在main()函数里面
![]()
nclass是要分的类别数量,result_dir是分类结果存储的地址,color表示RGB图还是灰度图,skip为True表示在视频中隔一段时间取帧,若为False则从视频开头连续取所需数量的帧。
3、
#os.listdir()用于返回指定文件夹中的文件或文件夹名字列表,在这是dataset文件夹
#里面存放的是视频数据
files = os.listdir(video_dir)
# X存放的是五维数组,各个维数代表(视频编号,帧高,帧宽,通道数,一个视频提取的帧数),
# 例如(402,32,32,3,16)是总共402个视频,每个视频提取16帧,每个帧是32x32x3的图像
X = []
#labels是每个视频对应的标签,402个视频就有402个标签
labels = []
#labellist是标签的种类,402个视频,但是只有3个种类,那么labellist的shape就是3
labellist = []
pbar = tqdm(total=len(files))#进度条
如果是5类那么labellist就是如下图,
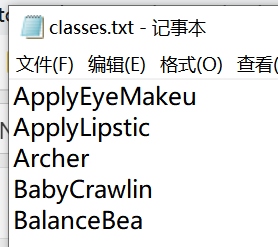
只选择前5个文件夹的视频

4、处理每个视频文件得到X和标签
for filename in files:#files有101个不同类别的视频文件夹,对这101个文件夹遍历
print(filename)
pbar.update(1)#更新进度条
if filename == '.DS_Store':
continue
namelist = os.path.join(video_dir, filename)
files2 = os.listdir(namelist)#files2是一个文件夹中的视频
for files3 in files2:#对一个类别的文件夹中所有视频遍历
name = os.path.join(namelist,files3)
print("dir is ",name)
label = vid3d.get_UCF_classname(files3)#取得视频对应的类别名
if label not in labellist:#将新的类别名放入labellist中
if len(labellist) >= nclass:
continue
labellist.append(label)#每一个视频对应的类别都要放入label中
labels.append(label)
# 将每个视频处理后得到的四维数组合并,形成五维的X。
X.append(vid3d.video3d(name, color=color, skip=skip))
pbar.close()#关闭进度条
5、将类别种类写入classes.txt
with open(os.path.join(result_dir, 'classes.txt'), 'w') as fp:
for i in range(len(labellist)):
fp.write('{}\n'.format(labellist[i]))
6、将所有视频类别名分别转换为从0开始的数字
for num, label in enumerate(labellist):
for i in range(len(labels)):
if label == labels[i]:
labels[i] = num#如果只分三类,那么labels只有三种0,1,2
7、返回X和已经转换为数字的labels
因为Conv3d的input_shape格式要求,对X的五个维度换一下位置。
if color:
return np.array(X).transpose((0, 2, 3, 4, 1)), labels#将X的1轴放在最后,这一维表示每个视频的15帧
else:
return np.array(X).transpose((0, 2, 3, 1)), labels
8、
在main函数中运行完loaddata函数后,对返回的X数组reshape,交换后两个维度。然后对标签独热码处理
X = x.reshape((x.shape[0], img_rows, img_cols, frames, channel))
Y = np_utils.to_categorical(y, nb_classes)
二、开始搭建网络
1、最重要的是这一步,搭建网络。
以下是网络图,
搭建代码
model = Sequential()
model.add(Conv3D(32, kernel_size=(3, 3, 3), input_shape=(
X.shape[1:]), padding='SAME'))
model.add(Activation('relu'))
model.add(Conv3D(32, kernel_size=(3, 3, 3), padding='SAME'))
model.add(Activation('softmax'))
model.add(MaxPooling3D(pool_size=(3, 3, 3), padding='SAME'))
model.add(Dropout(0.25))
model.add(Conv3D(64, kernel_size=(3, 3, 3), padding='SAME'))
model.add(Activation('relu'))
model.add(Conv3D(64, kernel_size=(3, 3, 3), padding='SAME'))
model.add(Activation('softmax'))
model.add(MaxPooling3D(pool_size=(3, 3, 3), padding='SAME'))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='sigmoid'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes, activation='softmax'))
其中X.shape为
![]()
X.shape[1:]为(32,32,15,3)
2、用categorical_crossentropy的loss函数,Adam优化器
model.compile(loss=categorical_crossentropy,
optimizer=adam_v2.Adam(), metrics=['accuracy'])
model.summary()
plot_model(model, show_shapes=True,
to_file=os.path.join(args.output, 'model.png'))#画出模型架构图
3、将数据分为训练集和测试集
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size=0.2, random_state=43)
最后测试的loss和accuracy

总代码
videoto3d.py
import matplotlib.pyplot as plt
import numpy as np
import cv2
class Videoto3D:
def __init__(self, width, height, depth):
self.width = width
self.height = height
self.depth = depth
def video3d(self, filename, color=False, skip=True):
cap = cv2.VideoCapture(filename)#捕获视频
nframe = cap.get(cv2.CAP_PROP_FRAME_COUNT)#获取视频的帧数
if skip:
#从第0帧开始,每隔总帧数的1/15取出一帧,即每个视频取出16帧
frames = [x * nframe / self.depth for x in range(self.depth)]
else:
frames = [x for x in range(self.depth)]
framearray = []#用于存储经过后面处理的16帧图像
for i in range(self.depth):
cap.set(cv2.CAP_PROP_POS_FRAMES, frames[i])#设置截取的下一帧的索引
ret, frame = cap.read()
frame = cv2.resize(frame, (self.height, self.width))#resize后每张从视频中截取的图像变成32x32x3
if color:#如果color是True(即RGB图像)则直接合并到framearray,否则先转化为灰度图再合并
framearray.append(frame)
else:
framearray.append(cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY))
cap.release()
return np.array(framearray)#返回包含所有处理后的图像的framearray
# 输入视频,由于数据集名称类似于v_ApplyEyeMakeup_g01_c01.avi前两个下划线“_”之间是这类视频的类名,所以用这个函数提取出类名
def get_UCF_classname(self, filename):
return filename[filename.find('_') + 1:filename.find('_', 2)]
3dcnn.py
import argparse
import os
import matplotlib
matplotlib.use('AGG')
import matplotlib.pyplot as plt
import numpy as np
from keras.datasets import cifar10
from keras.layers import (Activation, Conv3D, Dense, Dropout, Flatten,
MaxPooling3D)
from keras.layers.advanced_activations import LeakyReLU
from keras.losses import categorical_crossentropy
from keras.models import Sequential
from keras.optimizers import adam_v2
from keras.utils import np_utils
from keras.utils.vis_utils import plot_model
from sklearn.model_selection import train_test_split
import videoto3d
from tqdm import tqdm
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
def plot_history(history, result_dir):
plt.plot(history.history['accuracy'], marker='.')
plt.plot(history.history['val_accuracy'], marker='.')
plt.title('model accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.grid()#生成网格
plt.legend(['acc', 'val_acc'], loc='lower right')
plt.savefig(os.path.join(result_dir, 'model_accuracy.png'))
plt.close()
plt.plot(history.history['loss'], marker='.')
plt.plot(history.history['val_loss'], marker='.')
plt.title('model loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.grid()
plt.legend(['loss', 'val_loss'], loc='upper right')
plt.savefig(os.path.join(result_dir, 'model_loss.png'))
plt.close()
def save_history(history, result_dir):
loss = history.history['loss']
acc = history.history['accuracy']
val_loss = history.history['val_loss']
val_acc = history.history['val_accuracy']
nb_epoch = len(acc)
with open(os.path.join(result_dir, 'result.txt'), 'w') as fp:
fp.write('epoch\tloss\tacc\tval_loss\tval_acc\n')
for i in range(nb_epoch):
fp.write('{}\t{}\t{}\t{}\t{}\n'.format(
i, loss[i], acc[i], val_loss[i], val_acc[i]))
def loaddata(video_dir, vid3d, nclass, result_dir, color=False, skip=True):
#os.listdir()用于返回指定文件夹中的文件或文件夹名字列表,在这是dataset文件夹
#里面存放的是视频数据
files = os.listdir(video_dir)
# X存放的是五维数组,各个维数代表(视频编号,帧高,帧宽,通道数,一个视频提取的帧数),
# 例如(402,32,32,3,16)是总共402个视频,每个视频提取16帧,每个帧是32x32x3的图像
X = []
#labels是每个视频对应的标签,402个视频就有402个标签
labels = []
#labellist是标签的种类,402个视频,但是只有3个种类,那么labellist的shape就是3
labellist = []
pbar = tqdm(total=len(files))#进度条
for filename in files:#files有101个不同类别的视频文件夹,对这101个文件夹遍历
print(filename)
pbar.update(1)#更新进度条
if filename == '.DS_Store':
continue
namelist = os.path.join(video_dir, filename)
files2 = os.listdir(namelist)#files2是一个文件夹中的视频
for files3 in files2:#对一个类别的文件夹中所有视频遍历
name = os.path.join(namelist,files3)
print("dir is ",name)
label = vid3d.get_UCF_classname(files3)#取得视频对应的类别名
if label not in labellist:#将新的类别名放入labellist中
if len(labellist) >= nclass:
continue
labellist.append(label)#每一个视频对应的类别都要放入label中
labels.append(label)
# 将每个视频处理后得到的四维数组合并,形成五维的X。
X.append(vid3d.video3d(name, color=color, skip=skip))
pbar.close()#关闭进度条
with open(os.path.join(result_dir, 'classes.txt'), 'w') as fp:
for i in range(len(labellist)):
fp.write('{}\n'.format(labellist[i]))
for num, label in enumerate(labellist):
for i in range(len(labels)):
if label == labels[i]:
labels[i] = num#如果只分三类,那么labels只有三种0,1,2
if color:
return np.array(X).transpose((0, 2, 3, 4, 1)), labels#将X的1轴放在最后,这一维表示每个视频的15帧
else:
return np.array(X).transpose((0, 2, 3, 1)), labels
def main():
parser = argparse.ArgumentParser(
description='simple 3D convolution for action recognition')
parser.add_argument('--batch', type=int, default=128)
parser.add_argument('--epoch', type=int, default=100)
parser.add_argument('--videos', type=str, default='UCF101',
help='directory where videos are stored')
parser.add_argument('--nclass', type=int, default=101)
parser.add_argument('--output', type=str, required=True)
parser.add_argument('--color', type=bool, default=False)
parser.add_argument('--skip', type=bool, default=True)
parser.add_argument('--depth', type=int, default=10)
args = parser.parse_args()
img_rows, img_cols, frames = 32, 32, args.depth
channel = 3 if args.color else 1
fname_npz = 'dataset_{}_{}_{}.npz'.format(
args.nclass, args.depth, args.skip)
vid3d = videoto3d.Videoto3D(img_rows, img_cols, frames)
nb_classes = args.nclass
if os.path.exists(fname_npz):
loadeddata = np.load(fname_npz)
X, Y = loadeddata["X"], loadeddata["Y"]
else:
x, y = loaddata(args.videos, vid3d, args.nclass,
args.output, args.color, args.skip)
X = x.reshape((x.shape[0], img_rows, img_cols, frames, channel))
Y = np_utils.to_categorical(y, nb_classes)
X = X.astype('float32')
np.savez(fname_npz, X=X, Y=Y)
print('Saved dataset to dataset.npz.')
print('X_shape:{}\nY_shape:{}'.format(X.shape, Y.shape))
# Define model
model = Sequential()
model.add(Conv3D(32, kernel_size=(3, 3, 3), input_shape=(
X.shape[1:]), padding='SAME'))
model.add(Activation('relu'))
model.add(Conv3D(32, kernel_size=(3, 3, 3), padding='SAME'))
model.add(Activation('softmax'))
model.add(MaxPooling3D(pool_size=(3, 3, 3), padding='SAME'))
model.add(Dropout(0.25))
model.add(Conv3D(64, kernel_size=(3, 3, 3), padding='SAME'))
model.add(Activation('relu'))
model.add(Conv3D(64, kernel_size=(3, 3, 3), padding='SAME'))
model.add(Activation('softmax'))
model.add(MaxPooling3D(pool_size=(3, 3, 3), padding='SAME'))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='sigmoid'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes, activation='softmax'))
model.compile(loss=categorical_crossentropy,
optimizer=adam_v2.Adam(), metrics=['accuracy'])
model.summary()
plot_model(model, show_shapes=True,
to_file=os.path.join(args.output, 'model.png'))#画出模型架构图
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size=0.2, random_state=43)
history = model.fit(X_train, Y_train, validation_data=(X_test, Y_test), batch_size=args.batch,
epochs=args.epoch, verbose=1, shuffle=True)#verbose=1表示输出进度条信息, shuffle=True训练过程打乱输入样本顺序
model.evaluate(X_test, Y_test, verbose=0)#verbose=0表示不输出日志信息
model_json = model.to_json()
if not os.path.isdir(args.output):
os.makedirs(args.output)
with open(os.path.join(args.output, 'ucf101_3dcnnmodel.json'), 'w') as json_file:
json_file.write(model_json)
model.save_weights(os.path.join(args.output, 'ucf101_3dcnnmodel.hd5'))
loss, acc = model.evaluate(X_test, Y_test, verbose=0)
print('Test loss:', loss)
print('Test accuracy:', acc)
print(history.history.keys())
plot_history(history, args.output)
save_history(history, args.output)
if __name__ == '__main__':
main()