SVC案例:预测明天是否会下雨 (一)
概述:
此数据来源于Kaggle上的一份数据,我们的目的是在这个数据集上来预测明天是否会下雨。在这个15W行数据的数据集上,随机抽样5000个样本来为大家演示一些数据预处理和特征工程的思路。欢迎大家交流和指正:)
数据预处理
1.导库导数据,探索特征
- 导入需要的库
// An highlighted block
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
- 导入数据,探索数据
// An highlighted block
df = pd.read_csv('weather.csv',index_col=0)
df.shape # 查询数据形状 查看数据是几行几列 -(142193, 22)
因为数据比较大,有142193行,所以我们抽取5000条样本进行分析建模
// An highlighted block
weather = df.sample(n=5000,random_state=0)
首先看一下数据情况:
// An highlighted block
df.head() #查看数据的前几行

由此可以看出由于抽样的原因, 数据的索引需要我们重新设置
// An highlighted block
weather.index = range(weather.shape[0]) #重置索引
weather.head()

// An highlighted block
weather.columns #提取所有的特征名

以下是所有特征的含义,最后一个变量RainTomorrow 就是我们的目标变量,我们的标签:明天下雨了吗?
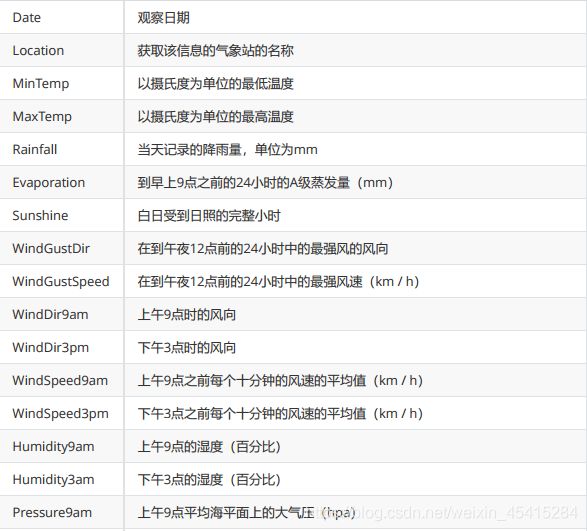
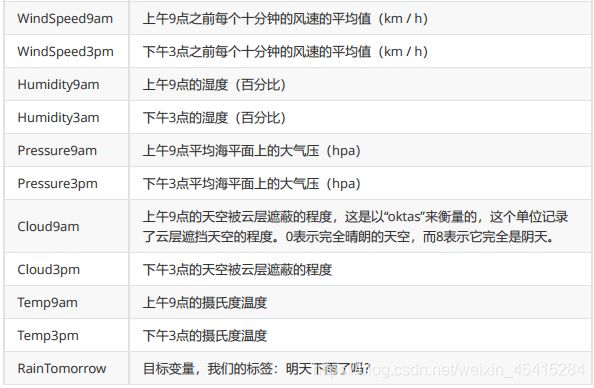
分别提取特征矩阵和标签:
// An highlighted block
X=weather.iloc[:,:-1]
Y=weather.iloc[:,-1]
// An highlighted block
X.info()
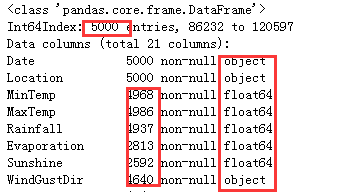
// An highlighted block
#查看标签类别
np.unique(Y)
#查看缺失值的比例(各个特征的缺失值比例)
X.isnull().mean()
查看特征矩阵整体情况:可以分析得出此特征矩阵里存在缺失值, 粗略观察可以发现,这个特征矩阵由一部分分类变量和一部分连续变量组成,其中云层遮蔽程度虽然是以数字表示,但是本质却是分类变量。大多数特征都是采集的自然数据,比如蒸发量,日照时间,湿度等等,而少部分特征是人为构成的。还有一些是单纯表示样本信息的变量,比如采集信息的地点,以及采集的时间。
标签是包含’No’和’Yes’的二分类问题。
2. 分数据集,探索标签
- 切分训练集和测试集
在现实中,我们会先分训练集和测试集,再开始进行数据预处理。这是由于,测试集在现实中往往是不可获得的,或者被假设为是不可获得的,我们不希望我们建模的任何过程受到测试集数据的影响,否
则的话,就相当于提前告诉了模型一部分预测的答案。在这里,为了让案例尽量接近真实的样貌,所以采取了现实中所使用的这种方式:先分训练集和测试集,再一步步进行预处理。这样导致的结果是,我
们对训练集执行的所有操作,都必须对测试集执行一次,工作量是翻倍的。
// An highlighted block
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,Y,test_size=0.3,random_state=420)
Xtrain.shape #训练集特征数据形状
Xtest.shape #测试集特征数据形状
新切分数据后,索引需要重新设置:
// An highlighted block
#恢复索引
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0])
- 查看是否有样本不均衡问题
通过查看标签每一类的数量和,来比较一下样本是否不均衡
// An highlighted block
Ytrain.value_counts()
Ytest.value_counts()
对标签进行编码,这样标签就由原来的’No’, 'Yes’转换成‘0’,‘1’了:
// An highlighted block
from sklearn.preprocessing import LabelEncoder #标签专用编码包
from sklearn.preprocessing import OrdinalEncoder #特征专用包
encorder = LabelEncoder().fit(Ytrain)
Ytrain = pd.DataFrame(encorder.transform(Ytrain))
Ytest = pd.DataFrame(encorder.transform(Ytest))
补充个知识点:
关于fit/transform/fit_transform:
fit完之后得到模型,如果想要把模型运用到不同的对象上,那就fit 和 transform分开
如果想要把fit之后的模型运用到同一个对象上,可以直接写fit_transform
3. 探索特征,处理特征矩阵
(1)描述性统计和异常值
// An highlighted block
#描述性统计
Xtrain.describe([0.01,0.05,0.1,0.25,0.5,0.75,0.9,0.99]).T
Xtest.describe([0.01,0.05,0.1,0.25,0.5,0.75,0.9,0.99]).T
#提取出所有的数值型特征的列名
col = Xtrain.mean().index
len(col) #16个数值型的特征
(np.abs((Xtrain.loc[:,col] - Xtrain.mean())/Xtrain.std())>3).sum()/Xtrain.shape[0]#查看训练集各列异常值的比例
如果异常值是少数存在,于是采取删除的策略(注意如果删除特征矩阵,则必须连对应的标签一起删除,特征矩阵的行和标签的行必须要一一对应)
- 提取出所有训练集所有异常值的索引
// An highlighted block
deltrain = []
for i in col:
bool_ = np.abs((Xtrain.loc[:,i] -
Xtrain.loc[:,i].mean())/Xtrain.loc[:,i].std())>3
ind = Xtrain[bool_].index
deltrain.extend(list(ind))
deltrain1 = list(set(deltrain)) #去重之后异常值的索引
- 提取出所有测试集所有异常值的索引
// An highlighted block
deltest = []
for i in col:
bool_ = np.abs((Xtest.loc[:,i] -
Xtrain.loc[:,i].mean())/Xtrain.loc[:,i].std())>3
ind = Xtest[bool_].index
deltest.extend(list(ind))
#去重之后有异常值的行索引
deltest1 = list(set(deltest))
- 删除异常值(特征和标签都要删除)
// An highlighted block
Xtrain = Xtrain.drop(index=deltrain1)
Ytrain = Ytrain.drop(index=deltrain1)
Xtest = Xtest.drop(index=deltest1)
Ytest = Ytest.drop(index=deltest1)
(2)处理困难特征:日期变量
// An highlighted block
Xtrain.Date.value_counts()

经查看,日期不是独一无二的,日期有重复;在我们分训练集和测试集之后,日期也不是连续的,而是分散的;如果我们把它当作连续型变量处理,那算法会人为它是一系列1~3000左右的数字,不会意识到这是日期;如果我们把它当作分类型变量处理,类别太多,有2025类,如果换成数值型,会被直接当成连续型变量,如果做成哑变量,我们特征的维度会爆炸。
其实我们可以想到,日期必然是和我们的结果有关的,我们可以想到,昨天的天气可能会影响今天的天气,而今天的天气又可能会影响明天的天气。但是对于算法来说,普通的算法是无法捕捉到样本与样本之间的联系的(行与行的联系),我们的算法捕捉的是样本的每个特征与标签之间的联系(即列与列之间的联系)。
因此我们可以把”今天的天气会影响明天的天气“这个指标转换成一个特征,我们观察到,我们的特征中有一列叫做“Rainfall",这是表示当前日期当前地区下的降雨量,我们可以把其中大于1的认为是下雨(“yes”),小于1的认为是不下雨(“no”)。
// An highlighted block
Xtrain.Rainfall.value_counts()
#查看Rainfall列是否存在缺失值
Xtrain.Rainfall.isnull().sum()

// An highlighted block
Xtrain.loc[Xtrain["Rainfall"] >= 1,"RainToday"] = "Yes"
Xtrain.loc[Xtrain["Rainfall"] < 1,"RainToday"] = "No"
Xtrain.loc[Xtrain["Rainfall"] == np.nan,"RainToday"] = np.nan
Xtest.loc[Xtest["Rainfall"] >= 1,"RainToday"] = "Yes"
Xtest.loc[Xtest["Rainfall"] < 1,"RainToday"] = "No"
Xtest.loc[Xtest["Rainfall"] == np.nan,"RainToday"] = np.nan
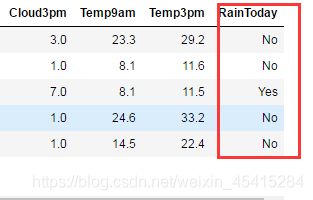
其次,我们也可以对不同月份进行分组,算法可以通过训练感受到,“这个月或者这个季节更容易下雨”。因此,我们可以将月份或者季节从日期变量中提取出来,作为一个特征使用,而舍弃掉具体的日期。如此,我们又可以创造第二个特征,月份"Month"。
// An highlighted block
Xtrain["Date"] = Xtrain["Date"].apply(lambda x:int(x.split("-")[1]))
Xtrain.rename(columns={"Date":"Month"},inplace=True)
Xtest["Date"] = Xtest["Date"].apply(lambda x:int(x.split("-")[1]))
Xtest = Xtest.rename(columns={"Date":"Month"})
_第7张图片](http://img.e-com-net.com/image/info8/0e52e641fd3943acaa9c251649d635b7.png)
通过时间,我们处理出两个新特征,“今天是否下雨”和“月份”
(3)处理分类型变量:缺失值
由于我们的特征矩阵由两种类型的数据组成:分类型和连续型,因此我们必须对两种数据采用不同的填补缺失值策略。传统地,如果是分类型特征,我们则采用众数进行填补。如果是连续型特征,我们则采用均值来填补(具体根据实际业务情况)。
// An highlighted block
#查看缺失值的缺失情况
Xtrain.isnull().mean()
Xtrain.dtypes #提取每一列的数据类型
#首先找出,分类型特征都有哪些
cate = Xtrain.columns[Xtrain.dtypes == "object"].tolist()
#除了特征类型为"object"的特征们,还有虽然用数字表示,但是本质为分类型特征的云层遮蔽程度
cloud = ["Cloud9am","Cloud3pm"]
cate = cate + cloud
cate
#对于分类型特征,我们使用众数来进行填补
from sklearn.impute import SimpleImputer
si = SimpleImputer(missing_values=np.nan,strategy="most_frequent")
#注意,我们使用训练集数据来训练我们的填补器,本质是在生成训练集中的众数
si.fit(Xtrain.loc[:,cate])
#然后我们用训练集中的众数来同时填补训练集和测试集
Xtrain.loc[:,cate] = si.transform(Xtrain.loc[:,cate])
Xtest.loc[:,cate] = si.transform(Xtest.loc[:,cate])
Xtrain.head()
Xtest.head()
#查看分类型特征是否依然存在缺失值
Xtrain.loc[:,cate].isnull().mean()
Xtest.loc[:,cate].isnull().mean()
(4)处理分类型变量:将分类型变量编码
在编码中,和我们的填补缺失值一样,我们也是需要先用训练集fit模型,本质是将训练集中已经存在的类别转换成是数字,然后我们再使用接口transform分别在测试集和训练集上来编码我们的特征矩阵。
// An highlighted block
#将所有的分类型变量编码为数字,一个类别是一个数字
from sklearn.preprocessing import OrdinalEncoder
oe = OrdinalEncoder()
#利用训练集进行fit
oe = oe.fit(Xtrain.loc[:,cate])
#用训练集的编码结果来编码训练和测试特征矩阵
#在这里如果测试特征矩阵报错,就说明测试集中出现了训练集中从未见过的类别
Xtrain.loc[:,cate] = oe.transform(Xtrain.loc[:,cate])
Xtest.loc[:,cate] = oe.transform(Xtest.loc[:,cate])
Xtrain.loc[:,cate].head()
Xtest.loc[:,cate].head()

(5)处理连续性变量:填补缺失值
连续型变量的缺失值由均值来进行填补。连续型变量往往已经是数字,无需进行编码转换。与分类型变量中一样,我们也是使用训练集上的均值对测试集进行填补。
// An highlighted block
col = Xtrain.columns.tolist()
for i in cate:
col.remove(i)
col
#实例化模型,填补策略为"mean"表示均值
impmean = SimpleImputer(missing_values=np.nan,strategy = "mean")
#用训练集来fit模型
impmean = impmean.fit(Xtrain.loc[:,col])
#分别在训练集和测试集上进行均值填补
Xtrain.loc[:,col] = impmean.transform(Xtrain.loc[:,col])
Xtest.loc[:,col] = impmean.transform(Xtest.loc[:,col])
Xtrain.head()
Xtest.head()
(6)处理连续性变量:无量纲化
数据的无量纲化是SVM执行前的重要步骤,因此我们需要对数据进行无量纲化。但注意,这个操作我们不对分类型变量进行。
// An highlighted block
col.remove("Month")
col
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss = ss.fit(Xtrain.loc[:,col])
Xtrain.loc[:,col] = ss.transform(Xtrain.loc[:,col])
Xtest.loc[:,col] = ss.transform(Xtest.loc[:,col])
Xtrain.head()
Xtest.head()
特征工程到这里就全部结束了。由于时间原因,建模的过程稍后会更新。
未完,待续------