Python学习(三)之Numpy与Pandas的使用
文章目录
- 1 Numpy简单使用
-
- 1.1 Numpy介绍
- 1.2 基本使用
- 2 Pandas数据分析
-
- 2.1 Pandas介绍
- Pandas基本使用
1 Numpy简单使用
1.1 Numpy介绍
1 Numpy 是一个专门用于矩阵化运算、科学计算的开源Python
2 NumPy将Python相当于变成一种免费的更强大的Matlab系统:
- 强大的 ndarray 多维数组结构
- 成熟的函数库
- 用于整合C/C++和Fortran代码的工具包
- 实用的线性代数、傅里叶变换和随机数模块
- Numpy 和稀疏矩阵运算包scipy 配合使用非常方便
1.2 基本使用
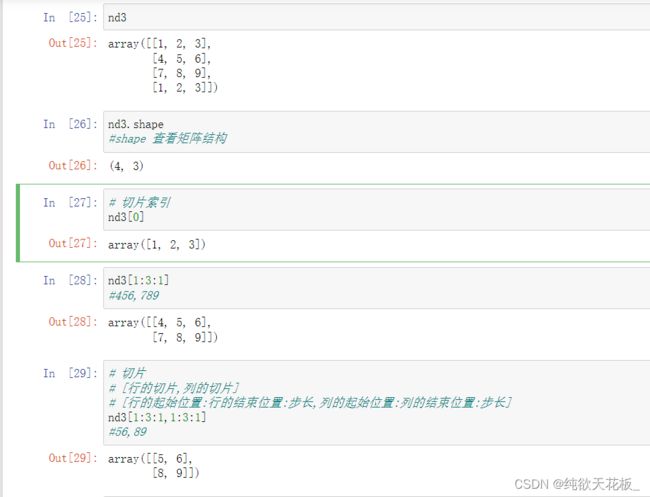
矩阵表示:使用Numpy,易得到二维矩阵

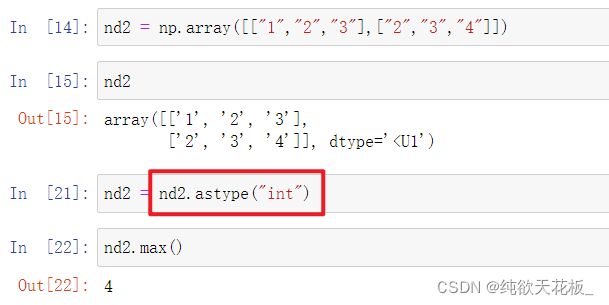
作为ndarray对象里的数据有时并不是所需要的,那么可以使用ndarray对象的astype() 方法转为指定的数据类型
将数据转为ndarray对象后,会需要按某种方式来抽取数据,ndarray对象提供了两种索引方式:
- 切片索引:切片索引和对列表list的切片索引相似,不过由原本 的一维切片变为多维。
nd4 = np.array([
[0,1,2,3,4,5],
[10,11,12,13,14,15],
[20,21,22,23,24,25],
[30,31,32,33,34,35],
[40,41,42,43,44,45],
[50,51,52,53,54,55],
])

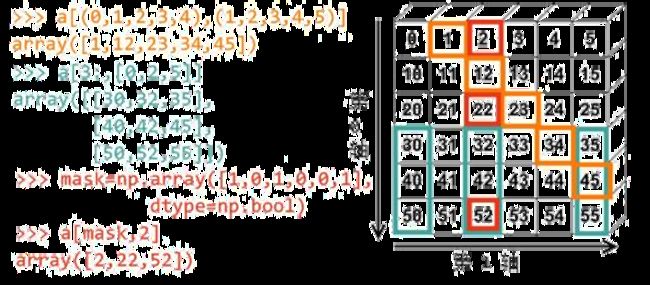
- 布尔值索引:通过添加条件判断数组中每个值的真/假转为布尔值再对原数组进行索 引,为真 True 时会被抽取出来

源码地址:https://gitee.com/GentleXiaoMing/python-learn/blob/master/numpylearn/Numpydemo.ipynb
2 Pandas数据分析
2.1 Pandas介绍
pandas提供了使我们能够快速便捷地处理结构化数据的大量数据结构和函数
pandas兼具NumPy高性能的数组计算功能以及电子表格和关系型数据库灵活的数据处理功能
对于金融行业的用户,pandas提供了大量适合于金融数据的高性能时间序列功能和工具
学统计的人会对R语言比较熟悉,R提供的data.frame对象功能仅仅是pandas的DataFrame所提供的功能的一个子集
Pandas基本使用
源码地址:https://gitee.com/GentleXiaoMing/python-learn/blob/master/numpylearn/Pandasdemo.ipynb


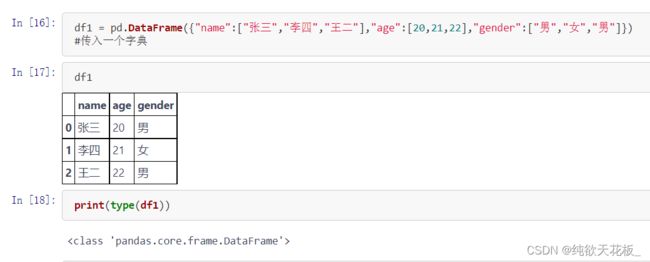


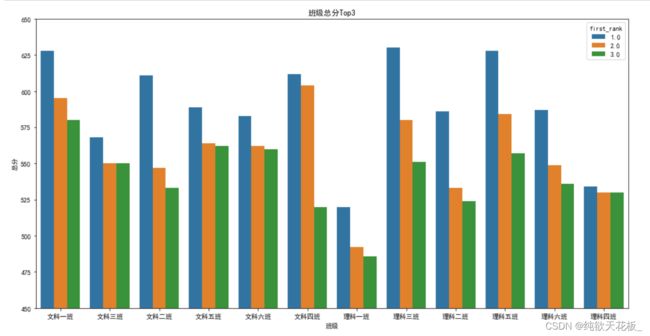
上述是简单的使用,接下来利用pandas对学生表、成绩表进行联表数据分析,分别求出总分排名、班级前三名以及TopN结构化展示柱状图和班级性别占比扇形图还有随机产生RGB颜色和使用pandas与数据库进行连接,导出数据。
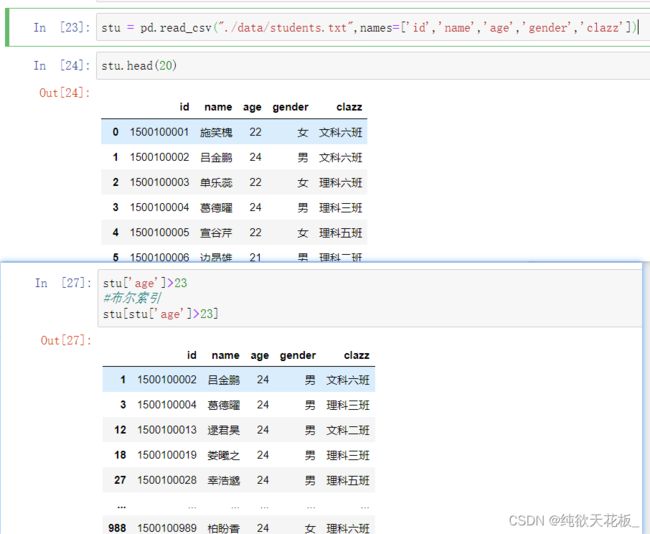
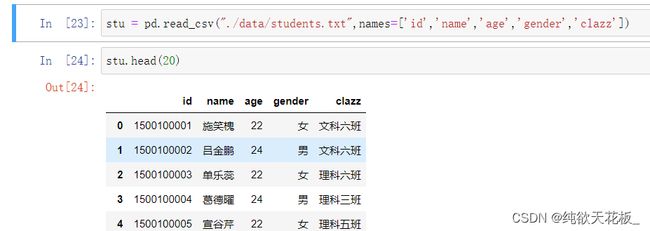
1 获取学生表和分数表:
stu = pd.read_csv("./data/students.txt",names=['id','name','age','gender','clazz'])
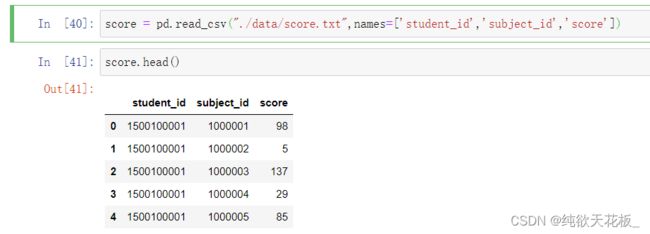
score = pd.read_csv("./data/score.txt",names=['student_id','subject_id','score'])
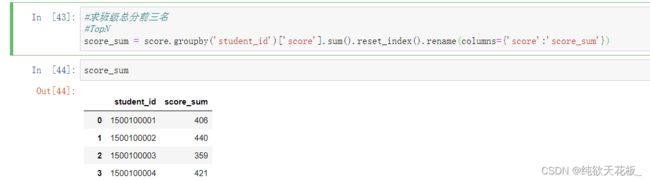
2 求出班级总分前三名,关联两张表(merge())

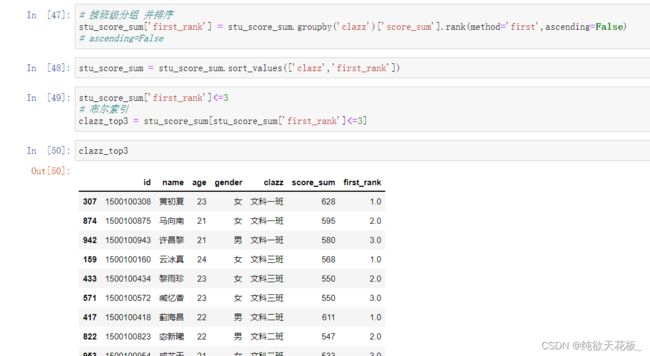
3 按班级分组并排序 取前三名
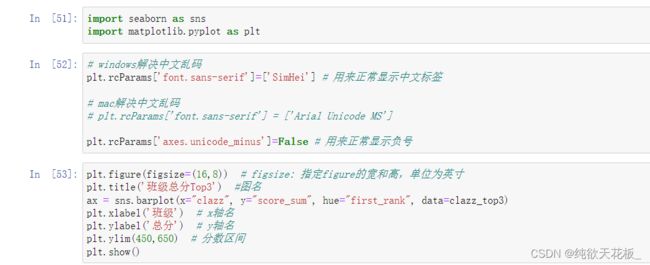
4 这里使用seaborn
Seaborn 是基于 matplotlib 开发的高阶Python 数据可视图库,用于绘制优雅、美观的统计图形。
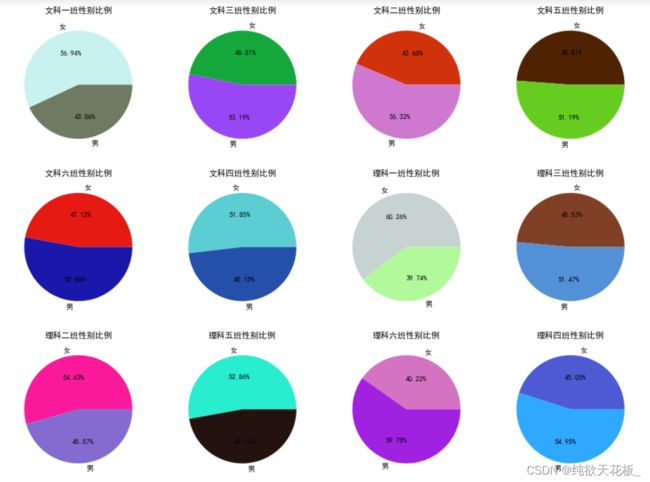
5 各班级男女比例占比扇形图



6 绘制子图,每个班级单独的男女比例图
#绘制子图
plt.figure(figsize=(16,12))
i = 1
for clazz in clazz_gender.clazz.unique():
plt.subplot(3,4,i) #三行四列
plt.title('%s性别比例' %clazz)
clazz1 = clazz_gender[clazz_gender['clazz']==clazz]
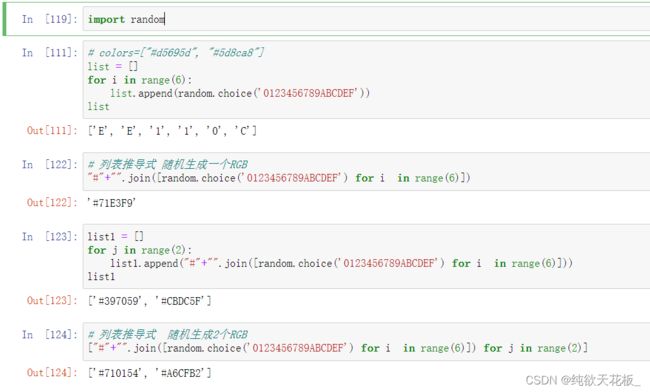
plt.pie(clazz1['cnt'],labels=clazz1['gender'],autopct='%.2f%%',colors=["#"+"".join([random.choice('0123456789ABCDEF') for i in range(6)]) for j in range(2)])
i+=1
plt.show()