patch 卷积神经网络_语义分割经典网络:全卷积神经网络(FCN)&U-net
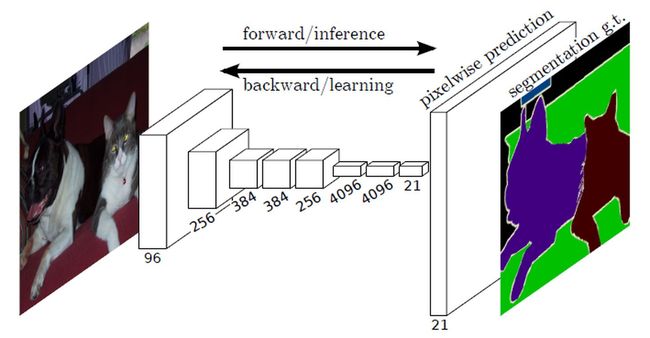
图像分类和检测任务,一般包含图像分类、目标检测、语义分割。其中语义分割相对较难,因为要预测的是每一个像素的类别。
FCN
全卷积神经网络(Fully Convolutional Network)是目前很多语义分割方法的基础。
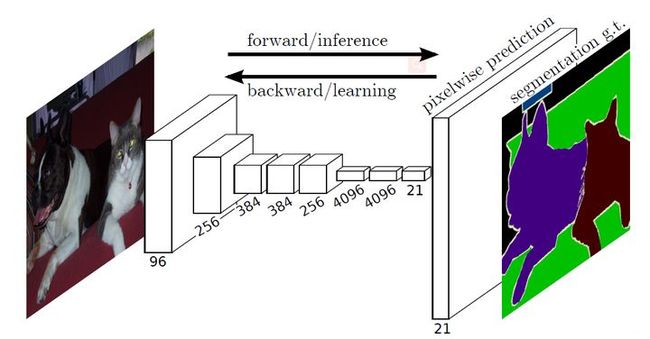
从图中可看出,神经网络结构只有卷积模块,在网络的尾端并没有全连接层。然后通过逐像素预测得到原图像中每个像素的预测结果。后面这一步是如何实现,后面会说到。
解决问题
1.DCNN对于WHAT(分类问题)很好,但丢失了WHERE(位置信息)。 2.一些目标检测任务不是端到端,比如RCNN需使用selective search得到proposal,再送到图像分类算法中检测。
将全连接层替换为卷积层:
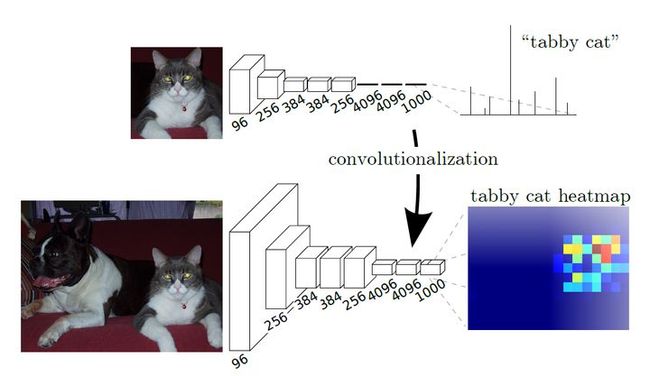
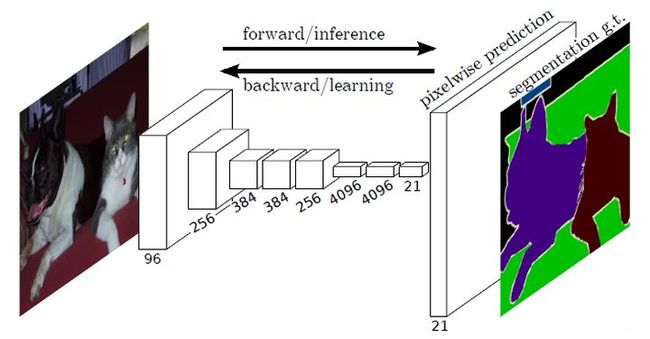
如图所示,上图上半部分显示的是一个猫经过LeNet5神经网络,最终得到这整张图像的分类结果,这是一种粗糙的图像检测/分类任务,在一张图像中的一个patch(下半部分得知,上半部分的猫实际上是原图的一部分)得到一个分类。全连接层1000个神经元,意味着有1000类。
要将全连接层换成卷积层很简单,例如原先网络最后一个卷积层是7×7×channal,将原本1×1×4096的全连接层,转换成4096个7×7×channal卷积核即可,然后再接下来的两个全连接层替换成4096个1×1×4096的卷积核、1000个1×1×4096的卷积核。
但是这样做的意义不大,同样地丢失了WHERE信息。要得到像素级别的分类,为了得到一个heatmap(有一定的长和宽!),所以不需要这么大的kernal(比如上段的7×7×channal卷积核),只需要在需要输出分辨率的特征中添加1000个1×1×channal的卷积核即可。(假设1000为分类类别数量)。
再解释一下,我们知道CNN在浅层得到的是一些基础特征,如点、线等,越往深层得到的特征越高级,越完整,比如浅层网络得到的特征为一个鸟的头、脚、翅膀,深层网络得到鸟的整个形状。但由于部分卷积和pooling层有下采样的作用,所以输出的图层分辨率小于原图,注意到最后的output有1000个channals,意味着在output的每一个像素都有对应类别的概率。
简单地将全连接层转化成卷积层,得到了一个“heapmap”,即一个分辨率比较小的map的每个像素的分类概率。这与我们后面需要得到与原图分辨率大小一样的map(同时需知道每个像素的分类概率)还有一定的差距。
上采样output使其恢复到原图分辨率
作者介绍了三种方法,一种是OverFeat中提出的Shift-and-stitch,另一种是简单的双线性插值,还有一种是称为deconvolution反卷积的方法。
Shift-and-stitch方法不在此处阐述。
双线性插值根据插值像素x轴与y轴相邻的像素值权重来确定。
本文采用了第三种方法,反卷积(deconvolution)。图像卷积由于stride和padding不同,有可能会对图像进行下采样,同时pooling层也会使分辨率下降。只要我们知道卷积的参数,进行反操作,就可以使下采样的图像恢复到原图像的大小。
举一个简单的例子。下图是一个传统的CNN过程。
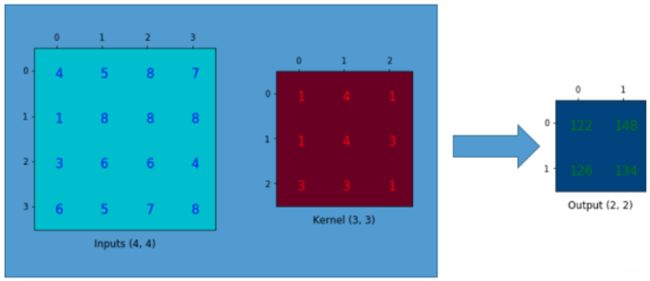
计算过程如下,使卷积核从左到右、从上而下与图像进行内积和操作,得到卷积后的结果。
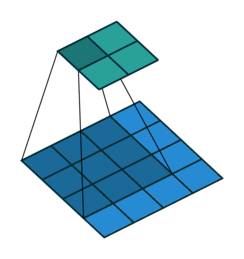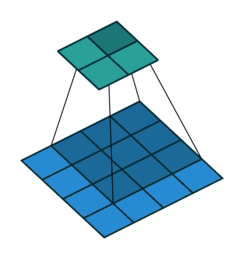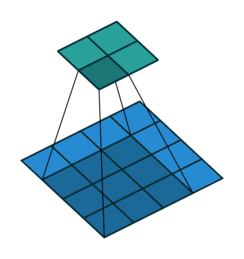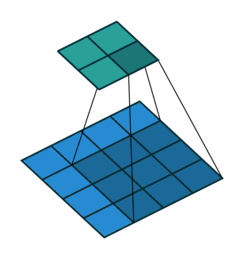
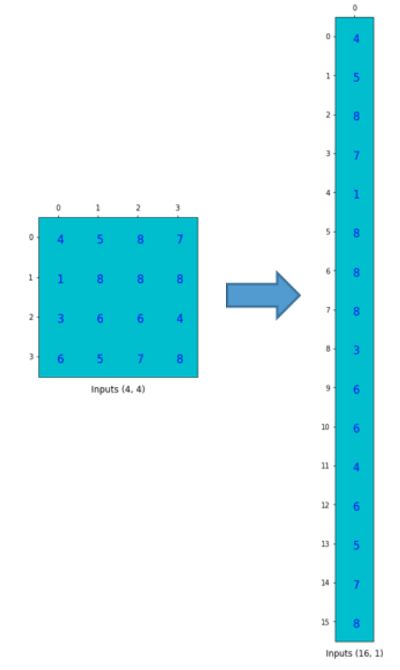
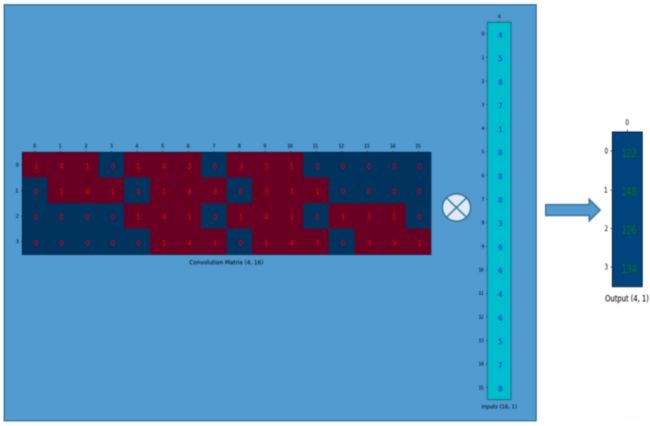
实际上在实现方法上,用的是矩阵乘法,kernal可以写成矩阵形式(卷积矩阵),图像也可以写成一维向量的形式。 如下图表示,kernal写成矩阵形式(卷积矩阵),图像也写成一维向量的形式。
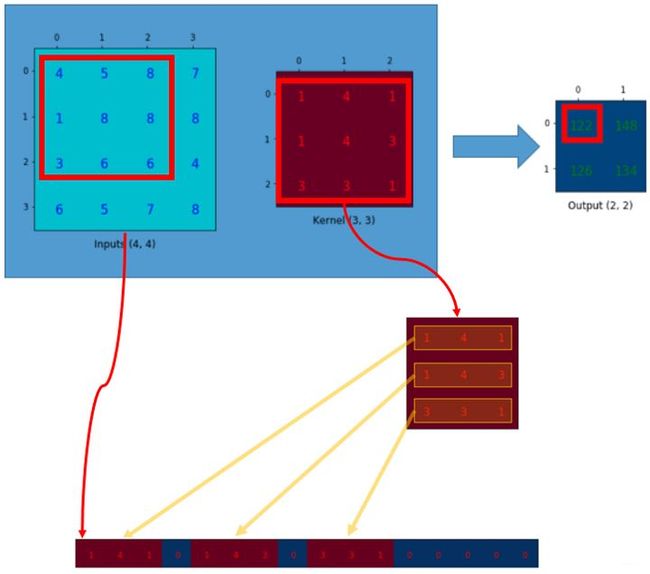
于是kernal可写成:

图像可写为:
卷积的过程可以表示为:
那deconvolution呢?已知卷积核与卷积后的output,恢复图像。

这就完成了反卷积deconvolution的过程。
直观上看,deconvolution就是以下动画:
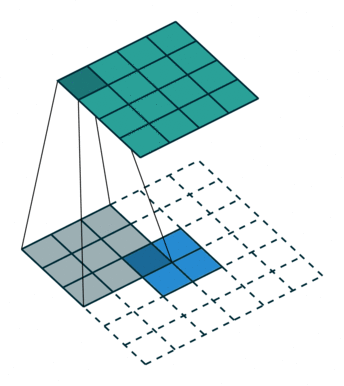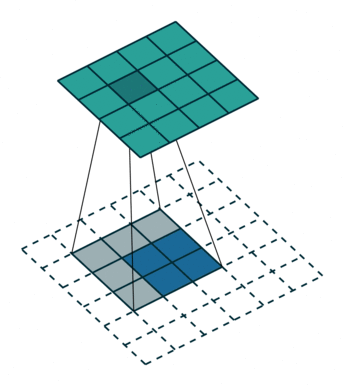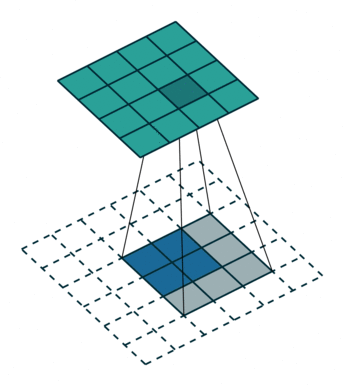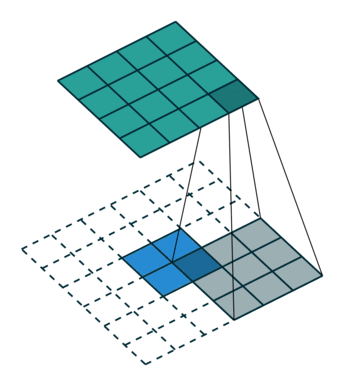
注意,这个kernal参数是可学习的。
还有一种上采样的方式,为unpooling,这是不可学习的,在进行maxpooling时记录max值的位置,在进行unpooling时将值填进原位置,并在其余位置补零。
使用FCNs网络来进行像素级别的图像分类
通过deconvolution的过程,就可以将原本较小的图像恢复到input大小,也即得到了每一个像素的分类概率。
已知通过网络,最终输出output大小为原图的1/32,放大32倍得到原输入大小,会出现一个问题,就是分类不够细腻,为了更加细腻,一个简单的想法就是,融合了多个不同卷积层的output,也就是使用多层output叠加。
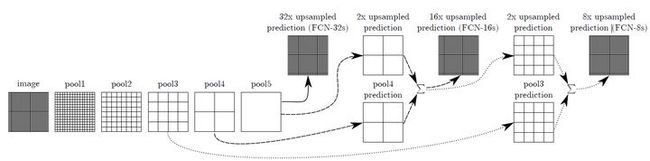
由图可知,FCN-32s即是最后的output放大32倍的结果,FCN-16s指的是倒数第二层pooling层的output放大16倍与最后的output放大32倍相加的结果,同理可知FCF-8s。
最后的效果可以由下图所示,可以看到FCN-8s被细化过,像素分类更加精确。

U-Net也是如FCN一般中语义分割任务的经典之作,一开始是用于生物图像的语义分割。
U-net
背景
在医学图像中,很多情况的输出需要定位,故需要使用语义分割的方法。
在之前的方法中,是使用sliding-windows方法预测每一个像素的label class,即通过提供一个局部区域(patch)作为输入。首先,这个network可以定位,其次,patch的训练数据远大于训练图像集。
显然,这个策略有两个缺点。 一是这个网络很慢,因为网络为每个patch分开运行,同时因为patch的重叠有大量的冗余。 二是这是一个在定位精度和图像内容使用的权衡,大patches需要更多maxpooling操作可减少定位精度,小patches又只能看到少的内容。
现在有一些方法提出了一个观点,输出要考虑多层特征。全局定位和内容使用是有可能同时兼顾的。
U-Net架构
本文提出一种架构,也称为“fully convolutional network”。没有使用到全连接层。
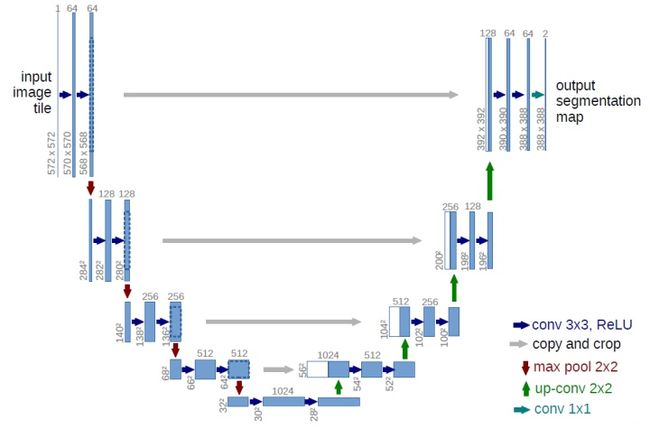
网络经过了四次下采样,再经过四次上采样。在每一个下采样都采用了double数量的feature channels。
将下采样的output与上采样的output叠加。由于下采样output分辨率会比上采样output的分辨率大,故需要进行裁剪,得到上采样对应outpurt的尺寸后,再进行叠加。这里与FCN的skip connect有些不同,FCN里是直接把数值相加,而U-Net里是进行特征叠加,使channal翻倍。最后使用类别总数的1×1卷积核进行卷积,得到最后的output,这里和FCN是一致的。
overlap-tile 策略
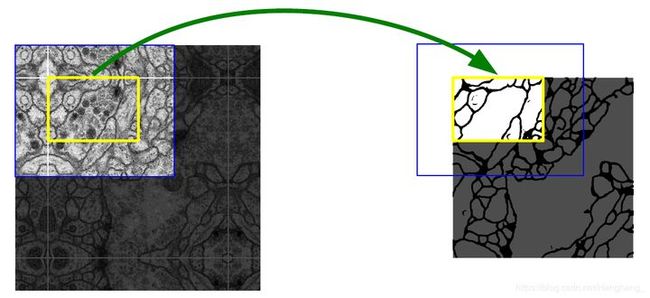
个人理解是由于图像分辨率太大难以学习,故采取了剪切的方法,但是由于剪切之后边缘部分难以进行分类,于是采用了overlap-tile策略。
根据图中显示,由于图像太大,可先裁剪一个patches(黄色框)来进行语义分割,但是黄框的边缘被剪切,特征被破坏。 于是在实际的分割任务中,选取黄框周围更大分辨率的图像来进行语义分割,再将结果进行裁剪。最后再将这些patches进行拼接,得到一整张图的语义分割结果。
这样做的目的是为了更好地检测每一个patches的边缘信息,拼接后更加准确。
对于两种网络而言,一个比较明显的区别就在于FCN是把信息相加,而U-Net是拼接。
看完两经典网络之后,感觉语义分割大概就是这么一个套路:
1. 提取图片特征;
2. 将输出的全连接层换成全卷积层;
3. 使用上采样+多层叠加方式得到分类结果。
参考文献:
《Fully Convolutional Networks for Semantic Segmentation》
《U-Net: Convolutional Networks for Biomedical Image Segmentation》
https://medium.com/activating-robotic-minds/up-sampling-with-transposed-convolution-9ae4f2df52d0