ABSTRACT:
抽象:
I am creating a Data Analysis Project on Heart Disease Prediction. The project uses raw data in form of a .csv file and transforms into Data Analysis. This project is an attempt of data analyzing Heart Disease Prediction with the help of data science and data analytics in python code. Heart disease is one of the biggest causes of morbidity and mortality among the population of the world. Prediction of cardiovascular disease is regarded as one of the most important subjects in the section of clinical data analysis. The amount of data in the healthcare industry is huge. Data mining turns the large collection of raw healthcare data into information that can help to make informed decisions and predictions.
我正在创建有关心脏病预测的数据分析项目。 该项目使用.csv文件形式的原始数据,然后转换为数据分析。 该项目是在数据科学和python代码中的数据分析的帮助下对心脏病预测进行数据分析的尝试。 心脏病是世界人口发病率和死亡率的最大原因之一。 在临床数据分析部分,心血管疾病的预测被认为是最重要的主题之一。 医疗保健行业中的数据量巨大。 数据挖掘将大量原始医疗保健数据收集转变为有助于做出明智决策和预测的信息。
Coronary Heart Disease (CHD) is the most common type of heart disease, killing over 370,000 people annually. Every year about 735,000 Americans has a heart attack. Of these, 525,000 are a first heart attack and 210,000 happen in people who have already had a heart attack. This makes heart disease a major concern to be dealt with. But it is difficult to identify heart disease because of several risk factors such as diabetes, high blood pressure, high cholesterol, abnormal pulse rate, and many other factors. Because of these factors, scientists have turned towards modern approaches like Data Mining and Machine Learning for predicting the disease.
冠心病(CHD)是最常见的心脏病,每年造成370,000多人死亡。 每年约有735,000美国人患有心脏病。 其中,有525,000例是首次心脏病发作,而210,000例是已经患有心脏病的人。 这使心脏病成为需要处理的主要问题。 但是由于多种危险因素(例如糖尿病,高血压,高胆固醇,脉搏异常)和许多其他因素,很难识别出心脏病。 由于这些因素,科学家们已转向数据挖掘和机器学习等现代方法来预测疾病。
In this article, I will be applying Data analytics as well as one Machine Learning approach for classifying whether a person is suffering from heart disease or not, using one of the most used dataset — the Cleveland Heart Disease dataset from the UCI Repository.
在本文中,我将使用数据分析以及一种机器学习方法,使用最常用的数据集之一(来自UCI存储库的克利夫兰心脏病数据集)对人是否患有心脏病进行分类。
导入库: (Importing Libraries:)
import numpy as np:
将numpy导入为np:
NumPy is a python library used for working with arrays. It also has functions for working in the domain of linear algebra, Fourier transform, and matrices. It was created in 2005 by Travis Oliphant. It is an open-source project and you can use it freely. NumPy stands for Numerical Python. In Python, we have lists that serve the purpose of arrays, but they are slow to process. NumPy aims to provide an array object that is up to 50x faster than traditional Python lists. Arrays are very frequently used in data science, where speed and resources are very important.
NumPy是用于处理数组的python库。 它还具有用于线性代数,傅立叶变换和矩阵领域的功能。 它由Travis Oliphant于2005年创建。 这是一个开源项目,您可以自由使用它。 NumPy代表数值Python。 在Python中,我们有满足数组目的的列表,但是处理起来很慢。 NumPy旨在提供一个比传统Python列表快50倍的数组对象。 阵列在数据科学中非常常用,因为速度和资源非常重要。
import pandas as pd
将熊猫作为pd导入
Pandas is an open-source, BSD-licensed Python library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language. Python with Pandas is used in a wide range of fields including academic and commercial domains including finance, economics, statistics, analytics, etc. Python was majorly used for data munging and preparation. It had very little contribution to data analysis. Pandas solved this problem. Using Pandas, we can accomplish five typical steps in the processing and analysis of data, regardless of the origin of data — load, prepare, manipulate, model, and analyze.
Pandas是经过BSD许可的开源Python库,为Python编程语言提供了高性能,易于使用的数据结构和数据分析工具。 带有Pandas的Python被广泛用于包括学术,商业领域在内的众多领域,包括金融,经济学,统计学,分析等。Python主要用于数据处理和准备。 它对数据分析的贡献很小。 熊猫解决了这个问题。 使用Pandas,无论数据的来源如何,我们都可以完成五个典型的数据处理和分析步骤-加载,准备,操作,建模和分析。
import matplotlib.pyplot as plt
导入matplotlib.pyplot作为plt
Matplotlib is a plotting library for the Python programming language and its numerical mathematics extension NumPy. Pyplot is a Matplotlib module which provides a MATLAB-like interface. Matplotlib is designed to be as usable as MATLAB, with the ability to use Python and the advantage of being free and open-source. Matplotlib is designed to be as usable as MATLAB, with the ability to use Python and the advantage of being free and open-source. It provides an object-oriented API for embedding plots into applications using general-purpose GUI toolkits like Tkinter, wxPython, Qt, or GTK+.
Matplotlib是Python编程语言及其数字数学扩展NumPy的绘图库。 Pyplot是Matplotlib模块,提供类似于MATLAB的界面。 Matplotlib设计为与MATLAB一样可用,具有使用Python的能力以及免费和开源的优势。 Matplotlib设计为与MATLAB一样可用,具有使用Python的能力以及免费和开源的优势。 它提供了一个面向对象的API,可使用Tkinter,wxPython,Qt或GTK +等通用GUI工具包将绘图嵌入到应用程序中。
import seaborn as sns
将seaborn导入为sns
Seaborn is a library for making statistical graphics in Python. It is built on top of matplotlib and closely integrated with pandas data structures. Seaborn aims to make visualization a central part of exploring and understanding data. Its dataset-oriented plotting functions operate on data frames and arrays containing whole datasets and internally perform the necessary semantic mapping and statistical aggregation to produce informative plots.
Seaborn是一个使用Python制作统计图形的库。 它建立在matplotlib之上,并与pandas数据结构紧密集成。 Seaborn旨在使可视化成为探索和理解数据的中心部分。 其面向数据集的绘图功能在包含整个数据集的数据框和数组上运行,并在内部执行必要的语义映射和统计汇总以生成信息图。
import os
导入操作系统
It is possible to automatically perform many operating system tasks. The OS module in Python provides functions for creating and removing a directory (folder), fetching its contents, changing and identifying the current directory, etc.
可以自动执行许多操作系统任务。 Python中的OS模块提供了用于创建和删除目录(文件夹),获取其内容,更改和标识当前目录等功能。
import warnings
进口警告
Warning messages are typically issued in situations where it is useful to alert the user of some condition in a program, where that condition (normally) doesn’t warrant raising an exception and terminating the program. For example, one might want to issue a warning when a program uses an obsolete module. Warning messages are normally written to sys.stderr, but their disposition can be changed flexibly, from ignoring all warnings to turning them into exceptions. The disposition of warnings can vary based on the warning category, the text of the warning message, and the source location where it is issued. Repetitions of a particular warning for the same source location are typically suppressed.
警告消息通常是在警告用户程序中某些情况的情况下发出的,该情况(通常)不保证引发异常并终止程序。 例如,当程序使用过时的模块时,可能要发出警告。 警告消息通常被写入sys.stderr,但是可以灵活地更改它们的处理方式,从忽略所有警告到将其转变为异常。 警告的处理方式可能会根据警告类别,警告消息的文本以及发出警告的源位置而有所不同。 通常会禁止针对同一源位置重复特定警告。
from sklearn.model_selection import train_test_split
从sklearn.model_selection导入train_test_split
Model_selection is a method for setting a blueprint to analyze data and then using it to measure new data. Selecting a proper model allows you to generate accurate results when making a prediction. To do that, you need to train your model by using a specific dataset. Then, you test the model against another dataset. If you have one dataset, you’ll need to split it by using the Sklearn train_test_split function first.
Model_selection是一种用于设置蓝图以分析数据,然后使用它来测量新数据的方法。 选择合适的模型可以使您在进行预测时生成准确的结果。 为此,您需要培训 使用特定的数据集来建立模型。 然后,针对另一个数据集测试模型。 如果您有一个数据集,则需要先使用Sklearn train_test_split函数对其进行拆分。
train_test_split is a function in Sklearn model selection for splitting data arrays into two subsets: for training data and for testing data. With this function, you don’t need to divide the dataset manually. By default, Sklearn train_test_split will make random partitions for the two subsets. However, you can also specify a random state for the operation.
train_test_split是Sklearn模型选择中的一个功能,用于将数据数组分为两个子集:用于训练数据和用于测试数据。 使用此功能,您无需手动划分数据集。 默认情况下,Sklearn train_test_split将对这两个子集进行随机分区。 但是,您也可以为操作指定一个随机状态。
from sklearn.metrics import accuracy_score
从sklearn.metrics导入precision_score
Accuracy classification score. In multilabel classification, this function computes subset accuracy: the set of labels predicted for a sample must exactly match the corresponding set of labels in y_true.
精度分类得分。 在多标签分类中,此函数计算子集准确性:为样本预测的标签集必须与y_true中的相应标签集完全匹配。
from sklearn.linear_model import LogisticRegression
从sklearn.linear_model导入LogisticRegression
Logistic Regression is a Machine Learning classification algorithm that is used to predict the probability of a categorical dependent variable. In logistic regression, the dependent variable is a binary variable that contains data coded as 1 (yes, success, etc.) or 0 (no, failure, etc.). In other words, the logistic regression model predicts P(Y=1) as a function of X.
Logistic回归是一种机器学习分类算法,用于预测分类因变量的概率。 在逻辑回归中,因变量是一个二进制变量,其中包含编码为1(是,成功等)或0(否,失败等)的数据。 换句话说,逻辑回归模型预测P(Y = 1)作为X的函数。
The above information is about all the libraries that were imported and some basic things what are they used for.
上面的信息是有关所有导入的库的,以及它们的基本用途。
现在,当我们导入所需的库时,让我们深入研究有趣的东西。 (Now as we have imported the required Libraries, let us dive deep into the fun stuff.)
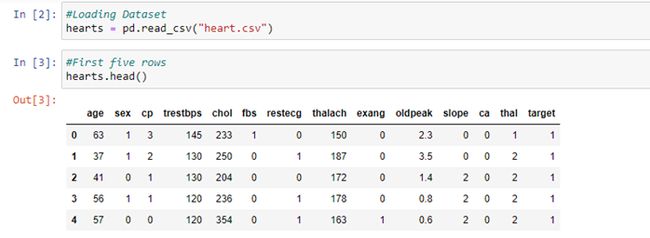
hearts = pd.read_csv(“hearts.csv”)
心= pd.read_csv(“ hearts.csv”)
read_csv is an inbuilt function of Pandas library which allows us to read .csv files and here I initialized it to hearts variable.
read_csv是Pandas库的内置函数,它使我们可以读取.csv文件,在这里我将其初始化为hearts变量。
hearts.head()
hearts.head()
The head() function is used to get the first n rows. This function returns the first n rows for the object based on position. It is useful for quickly testing if your object has the right type of data in it. By default, n=5.
head()函数用于获取前n行。 此函数根据位置返回对象的前n行。 这对于快速测试对象中的数据类型是否正确非常有用。 默认情况下,n = 5。
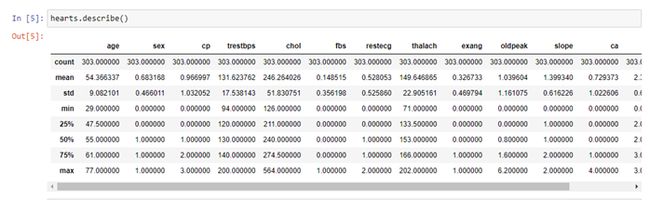
hearts.describe()
hearts.describe()
The describe() function computes a summary of statistics pertaining to the Data Frame columns. This function gives the mean, std, and IQR values. And, function excludes the character columns and given a summary about numeric columns.
describe()函数计算与“数据帧”列有关的统计信息摘要。 此函数提供平均值,std和IQR值。 并且,函数排除字符列,并给出有关数字列的摘要。
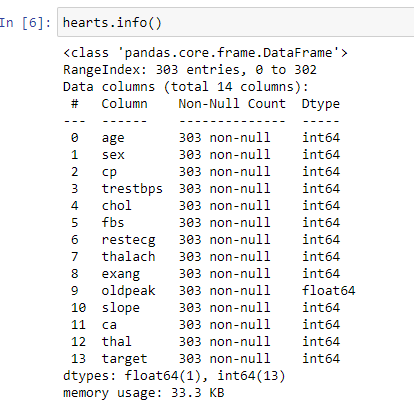
hearts.info()
hearts.info()
The info() function is used to print a concise summary of a Data Frame. This method prints information about a Data Frame including the index dtype and column dtypes, non-null values, and memory usage. The above output clearly shows that there are no values missing.
info()函数用于打印数据框的简要摘要。 此方法显示有关数据帧的信息,包括索引dtype和列dtype,非空值和内存使用情况。 以上输出清楚地表明没有缺失的值。
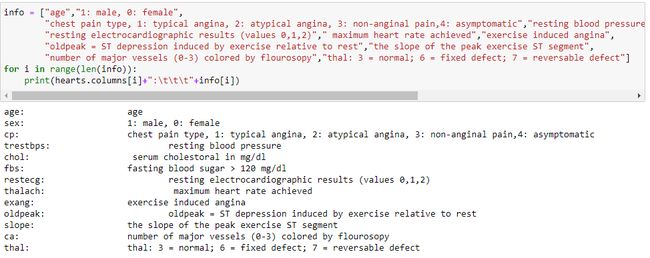
The above code helps us in analyzing the columns in a better way.
上面的代码可以帮助我们更好地分析列。
探索性数据分析(EDA) (EXPLORATORY DATA ANALYSIS (EDA))
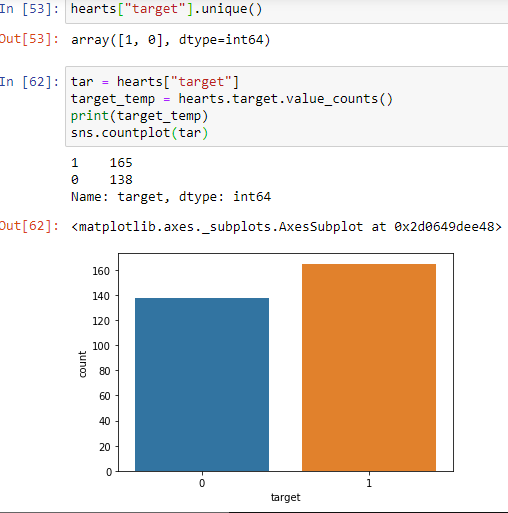
tar = hearts[“target”]
tar = hearts [“目标”]
Here tar variable is assigned to targets columns
此处将tar变量分配给目标列
hearts[“target”].unique()
心[“目标”] .unique()
Here we use the unique function which prints out all the unique values in the given variable of the dataset.
在这里,我们使用唯一函数,该函数在数据集的给定变量中打印出所有唯一值。
target_temp = hearts.target.value_counts()
target_temp = hearts.target.value_counts()
The above code calculates the total values in the target variable.
上面的代码计算目标变量中的总值。
print(target_temp)
打印(target_temp)
And this code prints the values.
并且此代码打印值。
Here “1” is the number of people suffering from heart disease and “0” is the number of people who are not suffering from heart disease. Hence the number of people suffering from heart disease is “165” and the number of people not suffering from heart disease is “138”.
这里的“ 1”是患有心脏病的人数,而“ 0”是未患有心脏病的人数。 因此,患有心脏病的人数为“ 165”,而未患有心脏病的人数为“ 138”。
Clearly, from this, we can assume that this is a classification problem with target variables having values “0” and “1”.
显然,由此可以假定这是目标值分别为“ 0”和“ 1”的分类问题。
sns.countplot(tar)
sns.countplot(tar)
Countplot shows the counts of observations in each categorical bin using bars.
计数图使用条形图显示每个分类箱中的观测值。
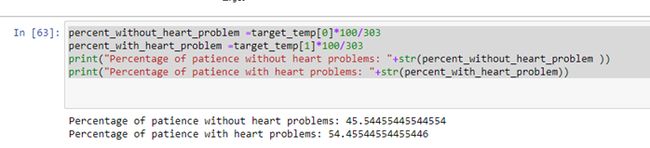
Here we find the percentage of people that are suffering and the people who are not suffering from heart disease and they are 45.54% and 54.45% respectively.
在这里,我们找到了患心脏病的人和没有患心脏病的人的百分比,分别是45.54%和54.45% 。
hearts[“sex”].unique()
心[“性别”] .unique()
Here we use the unique function which prints out all the unique values in the given variable of the dataset.
在这里,我们使用唯一函数,该函数在数据集的给定变量中打印出所有唯一值。
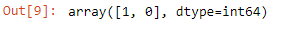
We have two features
我们有两个特点
Here “1” is denoted for the number of males and “0” is for the number of females.
在此,“ 1”表示男性数,“ 0”表示女性数。
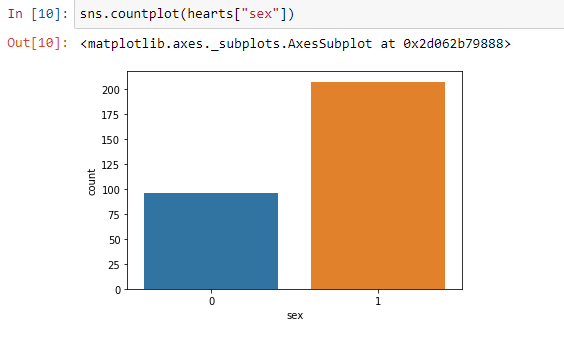
sns.countplot(hearts[“sex”])
sns.countplot(hearts [“ sex”])
Countplot shows the counts of observations in each categorical bin using bars. Here, by this count plot, we can see that number of females is less as compared to the number of males.
计数图使用条形图显示每个分类箱中的观测值。 在此,通过此计数图,我们可以看到女性人数少于男性人数。
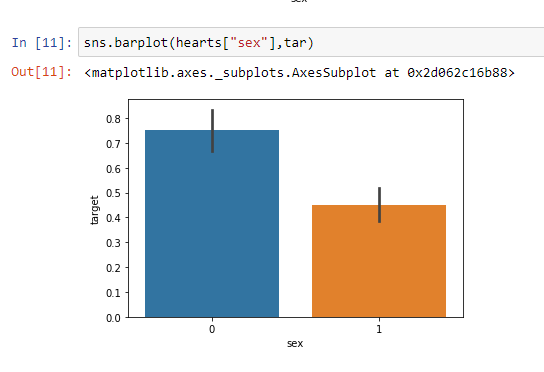
sns.barplot(hearts[“sex”],tar)
sns.barplot(hearts [“ sex”],tar)
A bar plot represents an estimate of central tendency for a numeric variable with the height of each rectangle and provides some indication of the uncertainty around that estimate using error bars.
条形图表示对每个矩形高度的数字变量的集中趋势的估计,并使用误差条提供了一些围绕该估计的不确定性的指示。
From the above barplot, we can easily see that the proportion of females suffering from heart disease is more than that of males.
从上面的图表中,我们可以很容易地看出,患有心脏病的女性比例要高于男性。
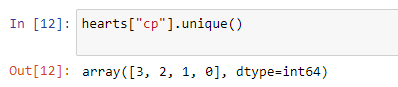
hearts[“cp”].unique()
心[“ cp”]。unique()
We have four features
我们有四个特点
Here type “0” is for typical anginal, type “1” is for atypical anginal, type “3” is for non-anginal, and type “4” is for asymptotic.
在这里,“ 0”代表典型的心绞痛,“ 1”代表非典型心绞痛,“ 3”代表非心绞痛,“ 4”代表渐近。
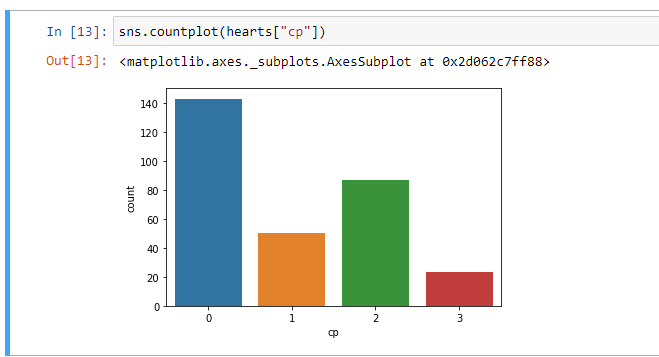
sns.countplot(hearts[“cp”])
sns.countplot(hearts [“ cp”])
Countplot shows the counts of observations in each categorical bin using bars. Here, by this count plot, we can see that most of the patients have typical anginal chest pain whereas very few patients suffer from an asymptotic type of chest pain.
计数图使用条形图显示每个分类箱中的观测值。 在此,通过此计数图,我们可以看到大多数患者患有典型的心绞痛性胸痛,而极少数患者患有渐进型胸痛。
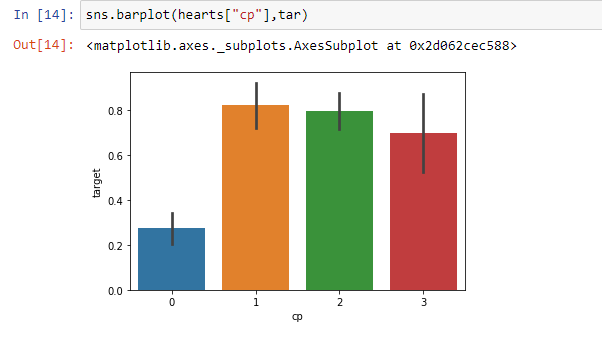
From the above barplot, we can easily see that people having typical anginal pain are much less likely to have heart problems as compared to the rest of the three.
从上面的小图中,我们可以很容易地看到,与其他三个人相比,患有典型心绞痛的人患心脏病的可能性要小得多。

The above code gives us the two features regarding persons who have fasting blood sugar for 1 it is >120 mg/dl and for 0 it is <120 mg/dl.
上面的代码为我们提供了两个有关空腹血糖的人的两个特征,空腹血糖为1时> 120 mg / dl,0时为<120 mg / dl。
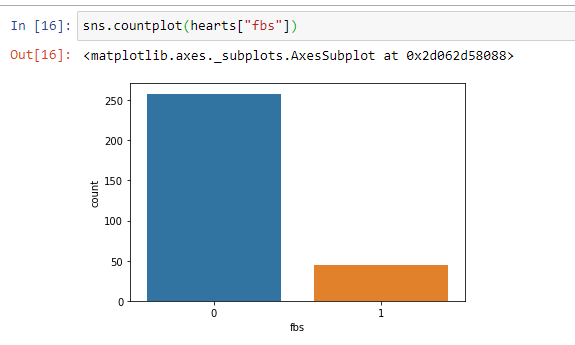
sns.countplot(hearts[“fbs”])
sns.countplot(hearts [“ fbs”])
Here we see people having fbs >120mg/dl i.e. “0” is very high as compared to people who are having fbs<120 mg/dl.
在这里我们看到fbs> 120mg / dl的人,即与fbs <120 mg / dl的人相比,“ 0”很高。
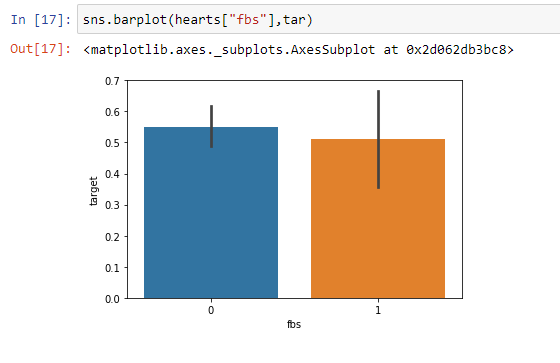
From the above barplot, we can clearly see that fbs does not have much effect on heart problem.
从上面的小节中,我们可以清楚地看到fbs对心脏问题影响不大。
We have three features,
我们具有三个功能,
They are type “0”, type “1” and type “2”.
它们是“ 0”类型,“ 1”类型和“ 2”类型。
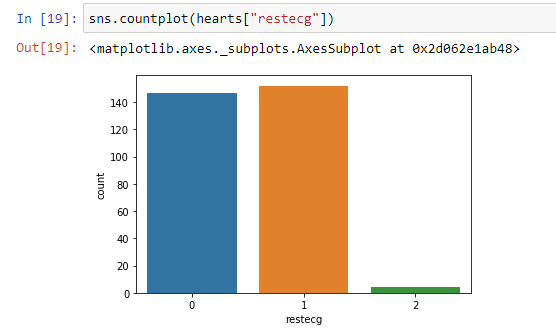
sns.countplot(hearts[“restecg”])
sns.countplot(hearts [“ restecg”])
Here we can clearly see people having type “0” and type “1” is almost the same whereas people having type “2” is extremely low as compared to type “0” and type “1”.
在这里,我们可以清楚地看到类型为“ 0”和类型“ 1”的人几乎相同,而类型为“ 2”的人们与类型“ 0”和类型“ 1”相比则极低。
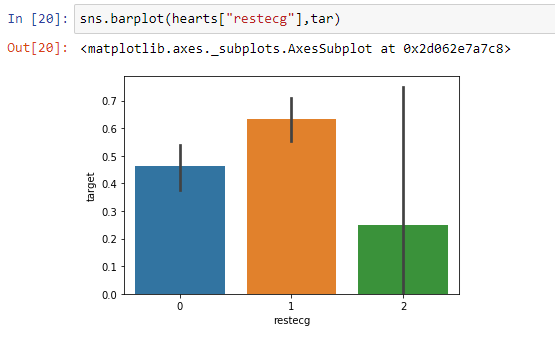
From the above barplot, we can easily see that people having type “2” are much less likely to have heart problems as compared to type “0” and type “1”.
从上面的小图中,我们可以轻松地看到,与“ 0”和“ 1”型相比,“ 2”型人患心脏病的可能性要小得多。

exang is Exercise-induced angina we have two features here. “0” if for people not having exang and “1” is for people having exang.
exang是运动引起的心绞痛,我们在这里有两个特点。 对于没有exang的人为“ 0”,对于有exang的人为“ 1”。
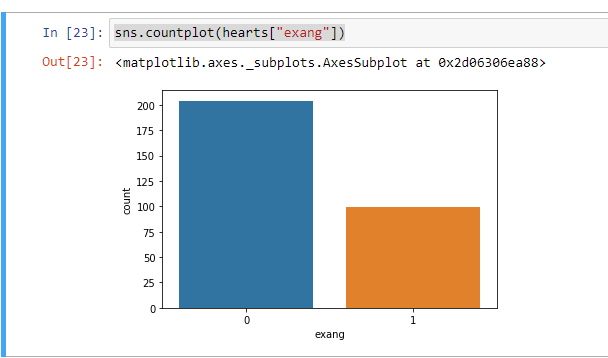
Here we can clearly see people having type “0” is more than type “1”.
在这里我们可以清楚地看到类型为“ 0”的人比类型为“ 1”的人更多。
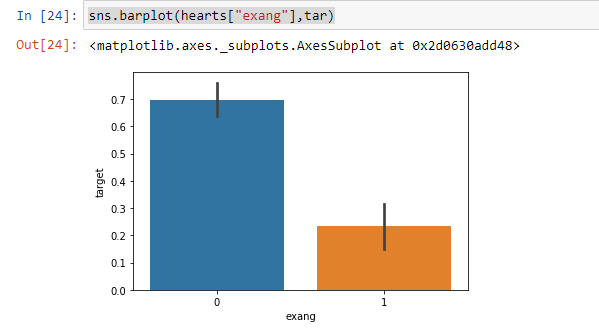
From the above barplot, we can easily see that people having type “1” are much less likely to have heart problems as compared to type “0”.
从上面的小图中,我们可以轻松地看到,与“ 0”型相比,“ 1”型的人患心脏病的可能性要小得多。
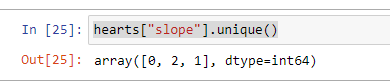
We have three features
我们有三个特点
They are slope “0”, slope “1” and slope “2”.
它们是斜率“ 0”,斜率“ 1”和斜率“ 2”。
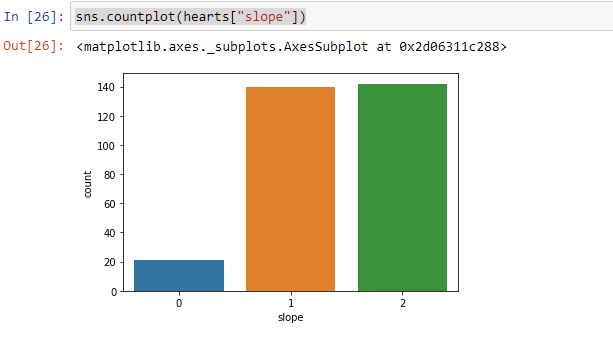
Here we can clearly see people having slope “1” and slope “2” is much more than slope “0”.
在这里,我们可以清楚地看到具有“ 1”斜率和“ 2”斜率的人远大于“ 0”。
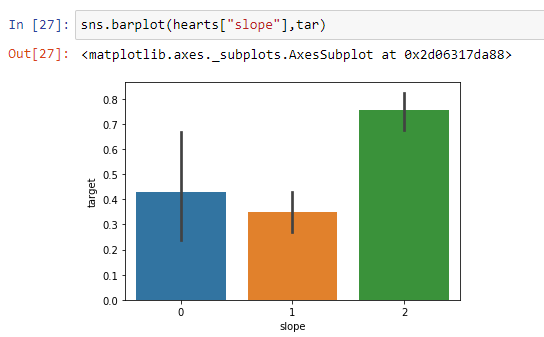
From the above barplot, we can easily see that people having slope “2” have much more heart problems as compared to slope “0” and slope “1”.
从上面的小图中,我们可以很容易地看到,与“ 0”和“ 1”相比,“ 2”的人的心脏问题要多得多。

We have five features
我们有五个功能
They are type “0”, type “1”, type “2”, type “3”, and type “4”.
它们是“ 0”类型,“ 1”类型,“ 2”类型,“ 3”类型和“ 4”类型。
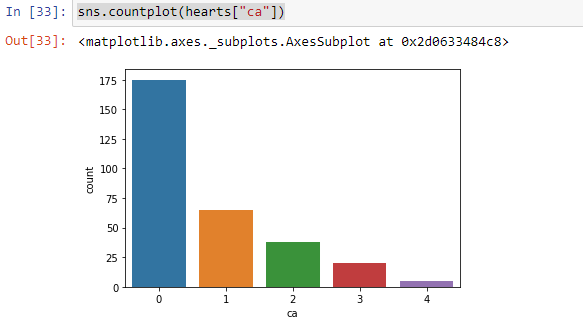
From the above countplot we can see that people having ca=0 are extremely high in number as compared to the rest of the ca’s.
从上面的计数图中可以看出,与ca的其余部分相比,ca = 0的人数非常多。
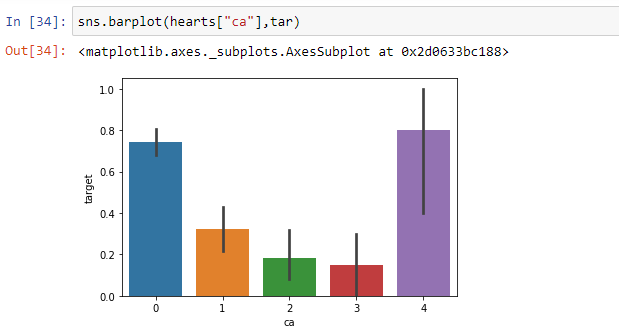
Here we see that people having ca=4 have a very high number of heart problems. As compared to the rest of the people.
在这里,我们看到ca = 4的人患有很多心脏病。 与其他人相比。

We have four features
我们有四个特点
They are type “0”, type “1”, type “2”, and type “3”.
它们是类型“ 0”,类型“ 1”,类型“ 2”和类型“ 3”。
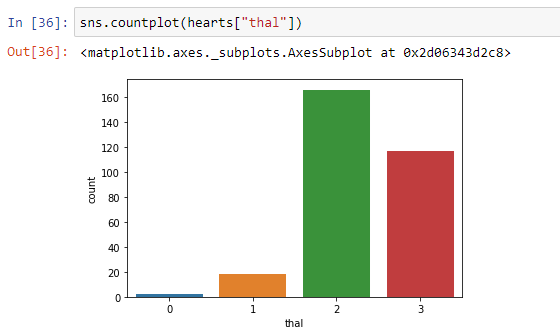
From the above count plot, we can see that people having thal as type “2” is very as compared to the rest of the group.
从上面的计数图中,我们可以看出,与其他人相比,泰尔人为“ 2”型的人非常多。
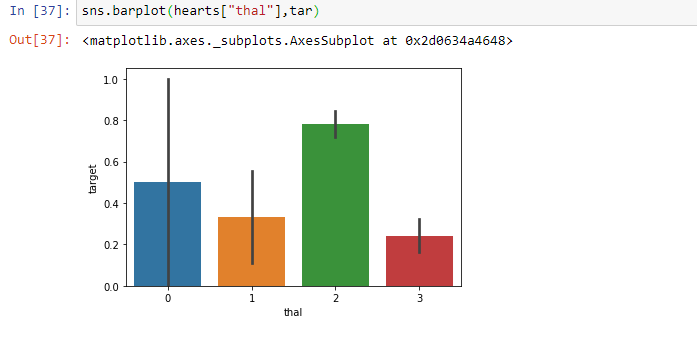
From the above barplot, we can clearly see that type “0” has a high chance of having a heart problem.
从上面的小图可以清楚地看到,“ 0”型患心脏病的可能性很高。
Here we have completed EDA now its time to move on prediction using machine learning models.
在这里,我们已经完成了EDA,现在是时候使用机器学习模型进行预测了。

Now the above code is used for Machine Learning purposes. We split the data into train and test set keeping in mind that the approach should not overfit or underfit on the given data. 20% of the data is taken for testing while 80% is being used for training the model.
现在,以上代码用于机器学习目的。 我们将数据分为训练集和测试集,请记住,该方法不应过度拟合或不足以满足给定数据。 20%的数据用于测试,而80%的数据用于训练模型。
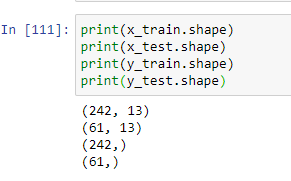
Here we print the shape of the train and test set i.e. the dimension of train and test set.
在这里,我们打印火车和测试仪的形状,即火车和测试仪的尺寸。

Here we apply Logistic regression to the first training set and from that using the .predict method we calculate y_pred i.e. the prediction of y using x_test.
在这里,我们将Logistic回归应用于第一个训练集,然后使用.predict方法从中得出Logistic回归,从而计算y_pred,即使用x_test对y的预测。

Finally comparing the results of y_pred with y_test we get that accuracy of the Logistic Regression is about 85.25%.
最后,将y_pred与y_test的结果进行比较,我们得出逻辑回归的准确性约为85.25%。
结论 (CONCLUSION)
Heart diseases are one of the major concerns of society and the number of people affected by these diseases is increasing day by day and it is important to find a solution to this problem.
心脏病是社会关注的主要问题之一,受这些疾病影响的人数每天都在增加,找到解决该问题的方法很重要。
It is difficult to manually determine the odds of getting heart disease based on risk factors. But with the help of data analytics and machine learning models, we can determine these diseases and have a better chance of treating it.
很难根据风险因素手动确定患心脏病的几率。 但是借助数据分析和机器学习模型,我们可以确定这些疾病,并有更好的机会进行治疗。
翻译自: https://medium.com/@cabhinav764/heart-disease-prediction-2247b3ff99dd