Softmax 函数的特点和作用是什么
Softmax 函数的特点和作用是什么?
27 个回答

----------
因为这里不太方便编辑公式,所以很多公式推导的细节都已经略去了,如果对相关数学表述感兴趣的话,请戳这里的链接Softmax的理解与应用 - superCally的专栏 - 博客频道 - http://CSDN.NET
----------
Softmax在机器学习中有非常广泛的应用,但是刚刚接触机器学习的人可能对Softmax的特点以及好处并不理解,其实你了解了以后就会发现,Softmax计算简单,效果显著,非常好用。
我们先来直观看一下,Softmax究竟是什么意思
我们知道max,假如说我有两个数,a和b,并且a>b,如果取max,那么就直接取a,没有第二种可能
但有的时候我不想这样,因为这样会造成分值小的那个饥饿。所以我希望分值大的那一项经常取到,分值小的那一项也偶尔可以取到,那么我用softmax就可以了 现在还是a和b,a>b,如果我们取按照softmax来计算取a和b的概率,那a的softmax值大于b的,所以a会经常取到,而b也会偶尔取到,概率跟它们本来的大小有关。所以说不是max,而是 Soft max 那各自的概率究竟是多少呢,我们下面就来具体看一下
定义
假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的Softmax值就是
也就是说,是该元素的指数,与所有元素指数和的比值
这个定义可以说非常的直观,当然除了直观朴素好理解以外,它还有更多的优点
1.计算与标注样本的差距
在神经网络的计算当中,我们经常需要计算按照神经网络的正向传播计算的分数S1,和按照正确标注计算的分数S2,之间的差距,计算Loss,才能应用反向传播。Loss定义为交叉熵
取log里面的值就是这组数据正确分类的Softmax值,它占的比重越大,这个样本的Loss也就越小,这种定义符合我们的要求
2.计算上非常非常的方便
当我们对分类的Loss进行改进的时候,我们要通过梯度下降,每次优化一个step大小的梯度
我们定义选到yi的概率是
然后我们求Loss对每个权重矩阵的偏导,应用链式法则(中间推导省略)。
最后结果的形式非常的简单,只要将算出来的概率的向量对应的真正结果的那一维减1,就可以了
举个例子,通过若干层的计算,最后得到的某个训练样本的向量的分数是[ 1, 5, 3 ], 那么概率分别就是[0.015,0.866,0.117],如果这个样本正确的分类是第二个的话,那么计算出来的偏导就是[0.015,0.866−1,0.117]=[0.015,−0.134,0.117],是不是很简单!!然后再根据这个进行back propagation就可以了



答案来自专栏:机器学习算法与自然语言处理
详解softmax函数以及相关求导过程
这几天学习了一下softmax激活函数,以及它的梯度求导过程,整理一下便于分享和交流。
softmax函数
softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类!
假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的softmax值就是
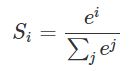

更形象的如下图表示:

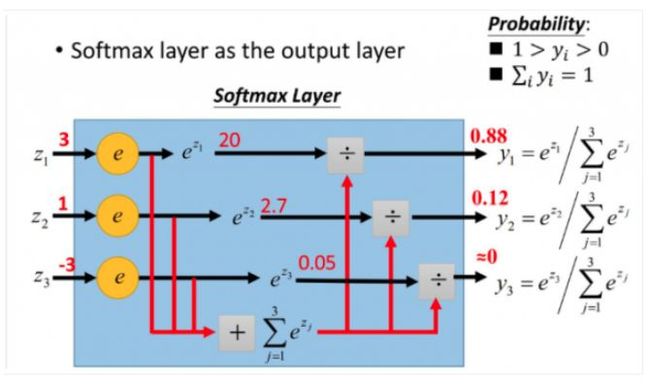
softmax直白来说就是将原来输出是3,1,-3通过softmax函数一作用,就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们就可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为我们的预测目标!
举一个我最近碰到利用softmax的例子:我现在要实现基于神经网络的句法分析器。用到是基于转移系统来做,那么神经网络的用途就是帮我预测我这一个状态将要进行的动作是什么?比如有10个输出神经元,那么就有10个动作,1动作,2动作,3动作...一直到10动作。(这里涉及到nlp的知识,大家不用管,只要知道我现在根据每个状态(输入),来预测动作(得到概率最大的输出),最终得到的一系列动作序列就可以完成我的任务即可)
原理图如下图所示:

那么比如在一次的输出过程中输出结点的值是如下:
[0.2,0.1,0.05,0.1,0.2,0.02,0.08,0.01,0.01,0.23]
那么我们就知道这次我选取的动作是动作10,因为0.23是这次概率最大的,那么怎么理解多分类呢?很容易,如果你想选取俩个动作,那么就找概率最大的俩个值即可~(这里只是简单的告诉大家softmax在实际问题中一般怎么应用)
softmax相关求导
当我们对分类的Loss进行改进的时候,我们要通过梯度下降,每次优化一个step大小的梯度,这个时候我们就要求Loss对每个权重矩阵的偏导,然后应用链式法则。那么这个过程的第一步,就是对softmax求导传回去,不用着急,我后面会举例子非常详细的说明。在这个过程中,你会发现用了softmax函数之后,梯度求导过程非常非常方便!
下面我们举出一个简单例子,原理一样,目的是为了帮助大家容易理解!

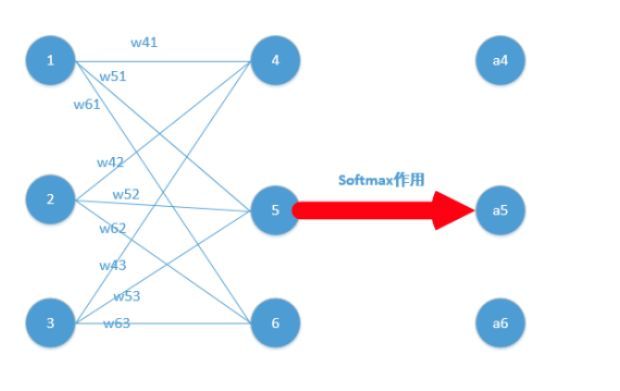
我们能得到下面公式:
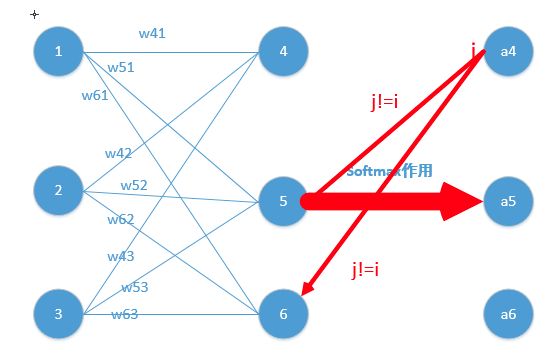
z4 = w41*o1+w42*o2+w43*o3
z5 = w51*o1+w52*o2+w53*o3
z6 = w61*o1+w62*o2+w63*o3
z4,z5,z6分别代表结点4,5,6的输出,01,02,03代表是结点1,2,3往后传的输入.
那么我们可以经过softmax函数得到
好了,我们的重头戏来了,怎么根据求梯度,然后利用梯度下降方法更新梯度!
要使用梯度下降,肯定需要一个损失函数,这里我们使用交叉熵作为我们的损失函数,为什么使用交叉熵损失函数,不是这篇文章重点,后面有时间会单独写一下为什么要用到交叉熵函数(这里我们默认选取它作为损失函数)
交叉熵函数形式如下:
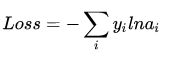
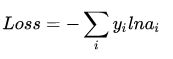
其中y代表我们的真实值,a代表我们softmax求出的值。i代表的是输出结点的标号!在上面例子,i就可以取值为4,5,6三个结点(当然我这里只是为了简单,真实应用中可能有很多结点)
现在看起来是不是感觉复杂了,居然还有累和,然后还要求导,每一个a都是softmax之后的形式!
但是实际上不是这样的,我们往往在真实中,如果只预测一个结果,那么在目标中只有一个结点的值为1,比如我认为在该状态下,我想要输出的是第四个动作(第四个结点),那么训练数据的输出就是a4 = 1,a5=0,a6=0,哎呀,这太好了,除了一个为1,其它都是0,那么所谓的求和符合,就是一个幌子,我可以去掉啦!
为了形式化说明,我这里认为训练数据的真实输出为第j个为1,其它均为0!
那么Loss就变成了,累和已经去掉了,太好了。现在我们要开始求导数了!
我们在整理一下上面公式,为了更加明白的看出相关变量的关系:
其中,那么形式变为
那么形式越来越简单了,求导分析如下:
参数的形式在该例子中,总共分为w41,w42,w43,w51,w52,w53,w61,w62,w63.这些,那么比如我要求出w41,w42,w43的偏导,就需要将Loss函数求偏导传到结点4,然后再利用链式法则继续求导即可,举个例子此时求w41的偏导为:
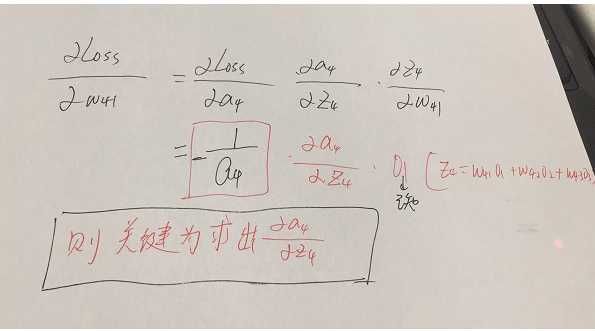

w51.....w63等参数的偏导同理可以求出,那么我们的关键就在于Loss函数对于结点4,5,6的偏导怎么求,如下:
这里分为俩种情况:


j=i对应例子里就是如下图所示:
比如我选定了j为4,那么就是说我现在求导传到4结点这!


那么由上面求导结果再乘以交叉熵损失函数求导
,它的导数为,与上面相乘为(形式非常简单,这说明我只要正向求一次得出结果,然后反向传梯度的时候,只需要将它结果减1即可,后面还会举例子!)那么我们可以得到Loss对于4结点的偏导就求出了了(这里假定4是我们的预计输出)
第二种情况为:
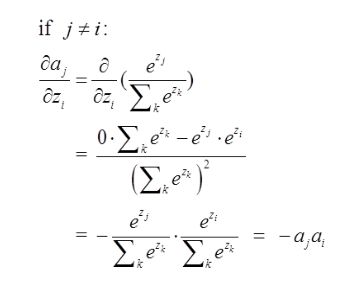
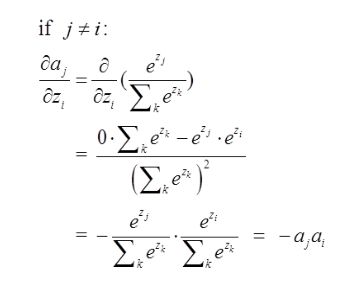
这里对应我的例子图如下,我这时对的是j不等于i,往前传:

那么由上面求导结果再乘以交叉熵损失函数求导
,它的导数为,与上面相乘为(形式非常简单,这说明我只要正向求一次得出结果,然后反向传梯度的时候,只需要将它结果保存即可,后续例子会讲到)这里就求出了除4之外的其它所有结点的偏导,然后利用链式法则继续传递过去即可!我们的问题也就解决了!
下面我举个例子来说明为什么计算会比较方便,给大家一个直观的理解
举个例子,通过若干层的计算,最后得到的某个训练样本的向量的分数是[ 2, 3, 4 ],
那么经过softmax函数作用后概率分别就是=[
,,] = [0.0903,0.2447,0.665],如果这个样本正确的分类是第二个的话,那么计算出来的偏导就是[0.0903,0.2447-1,0.665]=[0.0903,-0.7553,0.665],是不是非常简单!!然后再根据这个进行back propagation就可以了
到这里,这篇文章的内容就讲完了,我希望根据自己的理解,通过列出大量例子,直白的给大家讲解softmax的相关内容,让大家少走弯路,真心希望对大家的理解有帮助!欢迎交流指错!画图整理不易,觉得有帮助的给个赞呗,哈哈!
参考:
softmax的log似然代价函数(公式求导)
交叉熵代价函数(作用及公式推导)
Softmax回归 - Ufldl
部分图片来自于网络!


这里讲解一下Softmax函数用于sotfmax分类器时的解释。
一、什么是Softmax分类器?
Softmax分类器可以理解为逻辑回归分类器面对多分类问题的一般化归纳。
现在我们假设存在一个多分类器
ps:如果想简化一点,那可以直接认为 是个线性分类器
输出多分类问题的评分时,除了Softmax外还有SVM,不过SVM不存在直观解释,我们只能认为它是个越高越好的分数。
而Softmax的输出则可以更加直观地解释为归一化概率,并可由此引出一系列解释,这一点后文会讨论。
在Softmax分类器中,函数映射 代表着某种“评分”这个概念保持不变,但将这些评分值视为每个分类的未归一化的对数概率,并且将折叶损失(hinge loss)替换为交叉熵损失(cross-entropy loss)。公式如下:
或等价的
在上式中,使用 来表示分类评分向量 中的第 j 个元素。
数据集的损失值是数据集中所有样本数据的损失值 的均值与正则化损失 之和。
函数 被称作softmax 函数,它的:
- 输入一个向量,向量中元素为任意实数的评分值( 中的),函数对其进行缩放.
- 输出一个向量,其中每个元素值在0到1之间,且所有元素之和为1。
所以,包含softmax函数的完整交叉熵损失看起唬人,实际上还是比较容易理解的。
二、多视角下的softmax函数
1. 信息论视角:
在机器学习中,有一个经常和softmax捆绑在一起的名词“交叉熵”损失
在“真实”分布 和估计分布之间的 交叉熵 定义如下:
因此,Softmax就是最小化在估计分类概率 和“真实”分布之间的交叉熵。
证明/解释
“假设真实”分布就是所有概率密度都分布在正确的类别上(比如:假设输入属于第 类,则 在 的位置就有一个单独的1)。
还有,既然交叉熵可以写成熵和相对熵(Kullback-Leibler divergence,另一个名字叫KL散度)
且delta函数 的信息熵是0(若不了解请学习信息论/通信原理等课程的内容,了解信息熵的定义) ;
那么,就能训练一个sotfmax分类器,就等价于对两个分布之间的相对熵做最小化操作。
换句话说,交叉熵损失函数“想要”预测分布的所有概率密度都在正确分类上。
注:Kullback-Leibler散度(Kullback-Leibler Divergence)也叫做相对熵(Relative Entropy),它衡量的是相同事件空间里的两个概率分布的差异情况。
2. 概率论解释
可解释为给定输入特征 ,以 为参数,分配给正确分类标签 的归一化概率。
Softmax分类器将输出向量 的评分解释为没归一化的对数概率。那么,做指数函数的幂就得到了没有归一化的概率,而除法操作则对数据进行了归一化处理,使得这些概率的和为1。
从概率论的角度来理解,是在最小化正确分类的负对数概率,这可以看做是最大似然估计(MLE)。
该解释的另一个好处是,损失函数中的正则化部分 可以被看做是权重矩阵 的高斯先验,进行最大后验估计(MAP),而不是最大似然估计。
三、彩蛋:令人迷惑的命名规则
SVM分类器使用的是折叶损失(hinge loss),又被称为最大边界损失(max-margin loss)。
Softmax分类器使用的是交叉熵损失(corss-entropy loss)。
Softmax分类器的命名是从 softmax函数 那里得来的,softmax函数将原始分类评分变成正的归一化数值,所有数值和为1,这样处理后交叉熵损失才能应用。
注意,“softmax损失(softmax loss)”是没有意义的,因为softmax只是一个压缩数值的函数。(这个说法常用来做简称)
四、SVM和Softmax的比较
下图有助于区分这 Softmax和SVM这两种分类器:
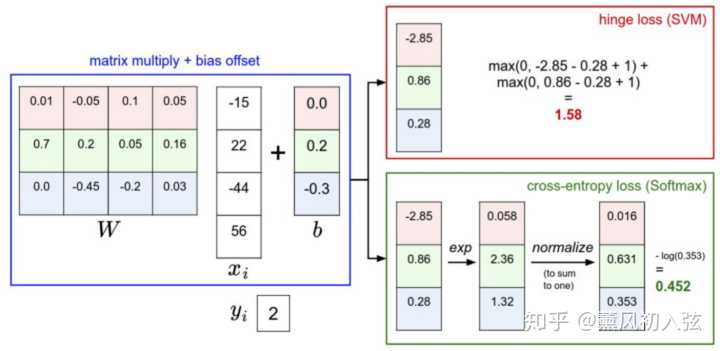

两个分类器都计算了同样的分值向量 f(本节中是通过矩阵乘来实现)
不同之处在于对 f 中分值的解释:
- SVM分类器将它们看做是分类评分,它的损失函数鼓励正确的分类(本例中是蓝色的类别2)的分值比其他分类的分值高出至少一个边界值。
- Softmax分类器将这些数值看做是每个分类没有归一化的对数概率,鼓励正确分类的归一化的对数概率变高,其余的变低。
上图的两个分类器损失函数值没有可比性。只在给定同样数据,在同样的分类器的损失值计算中,它们才有意义。
Softmax分类器为每个分类提供了“可能性”
SVM的计算是无标定的,而且难以对评分值给出直观解释。
Softmax分类器则计算出对于所有分类标签的可能性。
举个例子,SVM分类器是[12.5, 0.6, -23.0]对应分类“猫”,“狗”,“船”。
而softmax分类器可以计算出三个标签的”可能性“是[0.9, 0.09, 0.01],这就让你能看出对于不同分类准确性的把握。
为什么我们要在”可能性“上面打引号呢?
因为可能性分布的集中或离散程度是由正则化参数λ直接决定的,λ是你能直接控制的一个输入参数。如果正则化参数 λ 更大,那么权重 W 就会被惩罚的更多,然后他的权重数值就会更小,算出来的分数也会更小,概率的分布就更加分散了。随着正则化参数 λ 不断增强,输出的概率会趋于均匀分布。
softmax分类器算出来的概率最好是看成一种对于分类正确性的自信(贝叶斯学派的观点)。
看起来很不一样对吧,但实际上……
在实际使用中,SVM和Softmax经常是相似的:
两种分类器的表现差别很小。
相对于Softmax分类器,SVM更加“局部目标化(local objective)”,这既可以看做是一个特性,也可以看做是一个劣势。
考虑一个评分是[10, -2, 3]的数据,其中第一个分类是正确的。那么一个SVM( )会看到正确分类相较于不正确分类,已经得到了比边界值还要高的分数,它就会认为损失值是0。
SVM对于数字个体的细节是不关心的:如果分数是[10, -100, -100]或者[10, 9, 9],对于SVM来说没设么不同,只要满足超过边界值等于1,那么损失值就等于0。
softmax分类器则不同。对于[10, 9, 9]来说,计算出的损失值就远远高于[10, -100, -100]的。
换句话来说,softmax分类器对于分数是永远不会满意的:正确分类总能得到更高的可能性,错误分类总能得到更低的可能性,损失值总是能够更小。
但SVM只要边界值被满足了就满意了,不会超过限制去细微地操作具体分数。

经典softmax的推导过程
关于softmax是什么,可以看以前李宏毅老师的一个PPT,如图1,softmax将多个输出限定在之间,并且满足概率之和为1,通过softmax可以将信号呈指数的加大或者减少,突出想要增强的信息,


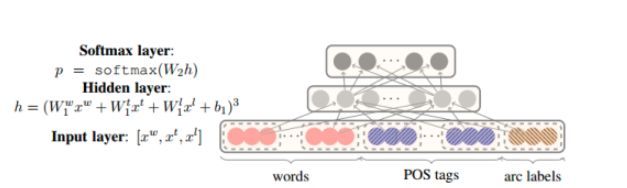
因此在多分类输出层经常加入softmax,完成多分类的目的,在损失函数上采样交叉熵损失去评估真实标签与预测值之间分布的差异,如图2所示,是预测值,是真实值,在多分类中其取值往往为onehot的编码方式,而如果直接将softmax应用在多标签分类中(即取值不是onehot, 是multihot),有可能存在问题,后面将通过softmax的推导来说明这个问题。


为了与论文公式符号保持一致(避免与上述截图中的符号搞混),本文将应用到的符号先提前定义声明,
- : 表示类别,或者标签的总数
- : 表示样本的真实的标签(在本文的语境中是bounding box的标签)
- 交叉熵损失函数表示为:, 其中
- 对于 相关的全连接参数定义为, bias项为
由于模型的参数为, 根据链式法则,可以得到如下公式:
显然,根据softmax的计算过程,以及交叉熵损失函数,
可以快速得到, 因为我们的主要目标是计算得到 , 由于计算公式中,包含了, 而各个中又包含了, 根据链式法则,可以画出求变量之间的依赖关系图如下,以及求导过程:
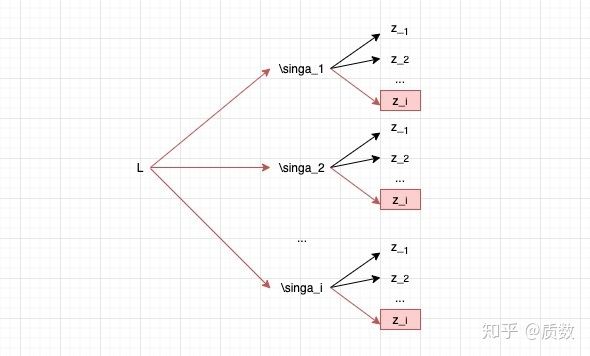

对于上述求导公式,首先根据交叉熵损失函数的公式:, 将其看做是关于的函数,因此可以得到:
对于, 需要分两种情况来考虑
当 时, (将看做是常数), 求导过程如下
当 时(不能将看做是常数), 求导过程如下
综合上述的求导过程,可以得到:
在多分类问题中,表示的是样本标签属于类别, ,整个向量为onehot编码,因此上式中, 因此,