7. 确保分布式系统的可靠性
系统故障是不符合其规范的系统行为。失败的后果可能会有所不同。
系统故障可能是由其某些组件(处理器、内存、输入/输出设备、通信线路或软件)的故障(故障)引起的。
组件故障可能由设计、制造或编程错误引起。它也可能由物理损坏、设备磨损、无效输入、操作员错误和许多其他原因引起。
故障可以是随机的、间歇的或永久性的。
重复操作时,随机故障(故障)消失。
例如,此类故障的原因可能是来自经过的有轨电车的电磁干扰。另一个例子是从不同任务访问操作系统的顺序中的罕见情况。
周期性故障在一段时间内频繁重复,然后可能很长一段时间都不会发生。示例 - 接触不良,处理异常完成任务后操作系统的错误操作。
永久性(持久性)故障在其原因消除之前不会停止 - 磁盘损坏、微电路故障或程序错误。
故障根据其表现的性质分为拜占庭式(系统是活跃的,并且可以以不同的方式表现出来,甚至是恶意的)和生命迹象的丧失(部分或全部)。前者比后者更难识别。他们的名字来源于拜占庭帝国(330-1453)的名字,那里阴谋、阴谋和欺骗盛行。
为了确保在系统故障情况下可靠地解决问题,使用了两种根本不同的方法——在系统(或其组件)发生故障后恢复解决方案和防止系统故障(容错)。
7.1。失败后恢复。
恢复可以是直接的(不返回之前的状态)和可返回的。
前向恢复基于及时检测故障并通过将系统的错误状态恢复到正确状态来消除其后果。这种恢复只有在特定的一组预定故障时才有可能。
在回滚恢复中,进程(或系统)从不正确的状态返回到之前的某些正确状态。这引发了以下问题。
(1) 记忆状态、恢复记忆状态和重复先前执行的工作所导致的性能开销可能过高。
(2) 不保证故障恢复后不会再次发生。
(3) 对于某些系统组件,可能无法恢复到以前的状态(自动售货机)。
但是,这种方法更通用,并且比第一种更常用。进一步的考虑将仅限于这种方法。
为了恢复传统计算机中的状态,使用了两种方法(及其组合),基于中间状态固定或执行操作的记录。它们存储的信息量和恢复所需的时间不同。
在分布式系统中使用这种方法会遇到以下困难。
7.1.1. 孤儿消息和多米诺骨牌效应。

该图显示了通过消息交互的三个进程(X、Y、Z)。垂直虚线在时间轴上显示存储过程状态以在发生故障时恢复的时刻。箭头对应于消息并显示它们发送和接收的时刻。
如果进程 X 中断,那么它可以从状态 x3 恢复,而不会对其他进程产生任何影响。
假设进程 Y 在发送消息 m 后中断并返回状态 y2。在这种情况下,消息 m 的接收固定在 x3,但它的发送没有标记在 y2。由于全局状态不一致,不应容忍这种情况(例如 - 一条消息包含从一个帐户转移到另一个帐户的金额)。在这种情况下,消息 m 称为孤立消息。进程 X 必须返回到其先前的状态 x2 并且冲突将得到解决。
现在假设进程 Z 发生故障并恢复到状态 z2。这会将进程 Y 回滚到 y1,然后将 X 和 Z 处理到它们的初始状态 x1 和 y1。这种效应被称为多米诺骨牌效应。
7.1.2. 消息丢失。

假设检查点 x1 和 y1 分别被提交以恢复进程 X 和 Y。
如果进程 Y 在收到消息 m 后发生故障,并且两个进程都恢复了 (x1,y1),则消息 m 将丢失(其丢失与通道中的丢失无法区分)。
- 无限恢复的问题。
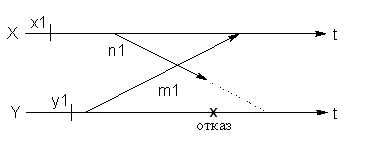
进程 Y 在从 X 接收到消息 n1 之前中断。当 Y
返回状态 y1,不包含发送消息 m1 的记录。所以 X 必须回到状态 x1。

回滚后,Y 发送 m2 并接收 n1(幽灵消息)。进程 X 回退到 x1 后,发送 n2 并接收 m2。但是,回滚后的 X 不再有发送 n1 的记录。因此,Y 必须重新回滚到 y1。现在 X 必须回退到 x1,因为它已经收到了 m2,没有记录要发送给 Y。这种情况将无限期地重复。
7.1.4。一致的控制点集。
上述困难表明,由任意一组本地检查点组成的全局检查点不能确保交互进程的恢复。
对于分布式系统,记住一致的全局状态是一个主要的理论问题。
如果一组检查点在其固定期间没有进程之间的交换,则称为严格一致的。它对应于严格一致的全局状态的概念,即接收到所有发送的消息并且通信通道中没有消息。如果对于任何接收消息的固定操作,相应的发送操作也是固定的(不存在孤立消息),则 一组检查点称为一致的。
修复一组一致的检查点的简单方法是在每次消息发送操作后修复一个本地检查点。在这种情况下,发送消息和修复应该是一个不可分割的操作(事务)。最后一个局部控制点的集合是一致的(但不是严格一致的)。
为了避免在使用一组一致的检查点进行恢复期间丢失消息,您必须重新发送那些由于回滚而收据变得无效的消息。使用消息时间戳,您可以识别幽灵消息并避免无休止的恢复。
7.1.5。同步检查点和恢复
下面描述了用于创建一组一致的检查点并使用它们进行恢复而没有无限循环危险的算法。
创建一组一致的控制点的算法。
该算法对分布式系统提出以下要求。
(1) 进程通过通信通道发送消息进行通信。
(2) 通道按照先进先出算法工作。点对点通信协议确保消息不会因通信错误或回滚到检查点而丢失。(确保这一点的另一种方法是使用稳定的内存来记录发送的消息并修复通道上收到的最后一条消息的 ID。)
该算法在稳定内存中创建两种类型的检查点——永久和试用。
永久检查点是本地检查点,它是一致的全局检查点的一部分。试验检查点是一个临时检查点,仅当算法成功时才会变为永久性检查点。该算法假设只有一个进程发起了许多检查点的创建,并且在算法运行过程中没有一个参与者会中断。
该算法分两个阶段执行。
第一阶段。
提交发起者(Pi 进程)创建一个试验检查点并要求所有其他进程执行相同的操作。这可以防止进程在创建检查点检查点后发送非服务消息。每个进程都会通知 Pi 它是否已经做了一个检查点检查点。如果所有进程都设置了试验检查点,那么 Pi 决定永久设置试验点。如果任何进程无法做出测试点,则决定取消所有测试点。
第二阶段。
Pi 将其决定通知所有进程。结果,要么所有进程都将具有新的永久检查点,要么没有进程将创建新的永久检查点。只有在 Pi 进程做出的决定被执行后,所有进程才能发送消息。
该算法的正确性是显而易见的,因为每个人创建的永久检查点集合不能包含不固定的消息发送操作。
优化:如果一个进程在提交上一个永久检查点后没有发送消息,它可能不会创建一个新的。
回滚(恢复)算法。
该算法假定它由单个进程启动,并且不会与提交算法并行运行。
它分两个阶段进行。
第一阶段。
回滚发起者询问其他人是否准备好回滚。当每个人都准备好回滚时,他决定回滚。
第二阶段。
Pi 将决定通知所有人。收到此消息后,每个过程都按指示进行。从响应就绪轮询的那一刻起,进程不得发送消息,直到做出决定(您不能向可能已经回滚的进程发送消息)。
优化:如果一个进程在提交上一个永久检查点后没有交换消息,那么它不需要回滚到它。
7.1.6。异步检查点和恢复。
同步提交简化了恢复,但会带来很多开销:
- 用于实现算法的附加服务消息。
- 同步延迟 - 您不能在算法运行时发送非官方消息。
如果失败很少见,那么这些损失根本不合理。
提交可以异步完成。在这种情况下,控制点的集合可能不一致。在回滚期间,通过将每个进程依次回滚到记录其发送和其他人接收的所有消息的点来搜索合适的一致集(以消除孤儿消息)。该算法依赖于每个进程在稳定内存中的存在,该日志跟踪它发送和接收的消息数量,以及关于消除多米诺效应所必需的进程之间交互组织的一些假设(例如,根据消息-反应-响应方案组织应用程序)。
7.2. 容错性。
上述故障后恢复方法因中断正常运行而不适用于某些系统(控制系统、在线模式的事务)。
为避免这些麻烦,请创建能够抵抗故障的系统。此类系统要么掩盖故障,要么在发生故障时以预定方式运行(例如,事务对数据库所做的更改在故障时变得不可见)。
两种机制被广泛用于提供容错——投票协议和集体决策协议。
投票协议用于掩盖失败(选择正确的结果,由所有可服务的执行者获得)。
做出集体决策的协议分为两类。首先,用于做出单一决定的协议,其中所有表演者都可以使用并且必须接受一切,或者每个人都不会做出预先确定的决定。这种决策的示例是在达到所有要求的准确性时结束迭代周期的决定,对失败做出响应的决定(我们已经熟悉该协议 - 它用于决定将所有进程回滚到检查点)。其次,用于根据彼此接收的数据做出商定决策的协议。在这种情况下,所有可服务的执行器都需要从其他可服务的执行器接收可靠的数据,而忽略来自故障执行器的数据。
确保容错的关键方法是冗余(硬件、流程、数据)。
- 使用热备模式(副驾驶、备份软件)。
切换到备用工作人员的问题。
7.2.2. 使用主动繁殖。
一个很好的例子是车载计算机中设备的三重复制和决策时的投票。
其他示例是分布式文件系统中的 DSM 页面传播和文件传播。同时,非常重要的一点是存在一种不可分割的消息广播机制(它们必须以相同的顺序到达每个人)。
投票算法。
在文件复制中使用投票的一般方案可以表示如下。
一个文件只能被不同的进程按顺序修改,并被所有进程同时读取(写-读协议)。文件的所有修改都有编号,文件的每个副本都以版本号 √ 修改次数为特征。每个副本都被分配了一定数量的投票Vi。让分配给所有副本的总票数等于 V。 写入仲裁 V w和读取仲裁 V r被确定为
V w > V/2 和 V w + V r > V
记录需要向所有服务器请求许可,并从拥有当前版本副本的服务器中获得适当数量 (V w ) 的投票(当收到许可时,该过程会收到其版本号以及归属于该副本的投票数量)副本)。如果其副本已过时(版本号低于接收到的最大值),则必须在修改副本之前对其进行更新。
选择写入仲裁,使两个进程不能同时获得写入权限。
完成修改后,该过程将其发送给文件当前版本的所有所有者。
要阅读,从任何服务器获得所需的票数(V r )就足够了。选择读取仲裁使得至少从中获得许可的服务器之一是文件当前副本的所有者。需要注意的是,当多个进程同时请求写权限时,有可能会出现投票权被瓜分而没有一个进程获得仲裁的情况。为了摆脱这种情况,进程应该在超时后放弃他们的请求(通知所有向他们发送权限的服务器),然后重复请求。
所描述的方案是基于投票的静态分布。分配给不同服务器的投票差异使得考虑它们的特性(可靠性、效率)成为可能。动态重新分配选票的方法提供了更大的灵活性。
为了保证部分服务器的故障不会导致无法获得法定人数的情况,使用了改变投票者组成的机制。
做出单一决定的协议
应该注意的是,在没有可靠通信的情况下(具有有限的延迟时间),不可能有实现单一解决方案的算法。考虑一下众所周知的两军问题。
5000名勇士组成的绿军位于山谷之中。
三千名武者的两支蓝色大军在山谷周围的群山中相距甚远。如果两支蓝军同时攻击果岭,他们将获胜。如果只有一支蓝军参战,那么它就会被彻底击败。
假设第 1 蓝军司令亚历山大将军(通过信使)向第 2 蓝军司令米哈伊尔将军发送消息,我有一个计划——明天黎明时分进攻。信使带着米哈伊尔的回信回到亚历山大——好主意,萨沙。明天黎明见。亚历山大命令士兵在黎明时分准备进攻。
然而,过了一会儿,亚历山大突然意识到米哈伊尔并不知道信使回来了,因此可能不敢攻击。然后他向米哈伊尔发送了一个信使,以确认亚历山大已经收到了他(迈克尔的)信息,并且攻击必须发生。
信使到达了米哈伊尔,但现在他害怕,不知道信使的到来,亚历山大可能不敢进攻。等等。很明显,将军们永远不会达成协议。
假设存在这样一个消息数量有限的共识协议。去除多余的最近消息,我们得到了最小协议。最近的消息很重要(因为协议是最小的)。如果这条消息没有到达它的目的地,那么就不会有战争。但是发送此消息的人不知道它是否通过了。因此,它不能认为协议已经完成,也不能决定攻击。即使使用可靠的处理器(将军),在通信不可靠的情况下也无法做出单一决定。
现在假设通信是可靠的,但处理器不可靠。
共识决策协议 的一个典型例子是拜占庭将军的任务。
在这个问题中,绿军在山谷中,n 个蓝军将领他们的军队在山区。通信是通过电话进行的,并且是可靠的,但在n 个将军中,有m个是叛徒。叛徒们正积极地试图阻止忠诚的将军们的同意。
本案中的约定如下。每个将军都知道他手下有多少勇士。目标是让所有忠诚的将领都知道所有忠诚军队的数量,即 他们每个人都收到长度为n的相同向量,其中第 i 个元素包含第 i 个军队的规模(如果其指挥官是忠诚的)或未定义(如果指挥官是叛徒)。
1982年提出了相应的递归算法(Lampport)。
让我们对n =4 和m =1 的情况进行说明。在这种情况下,算法分 4 步执行。
1步。每个将军都会向其他人发送一条信息,其中他指出了他的军队的规模。忠诚的将领报告真实数字,而叛徒可能会在不同的消息中报告不同的数字。将军1表示1(一千名士兵),将军2表示2,将军3表示其他三位将军分别为x,y,z,将军4表示4。
第 2 步。每个都从可用信息中形成自己的向量。
事实证明:
vect1(1,2,x,4)
vect2(1,2,y,4)
vect3(1,2,3,4)
vect4(1,2,z,4)
第三步。每个人都将他的向量发送给其他人(general-3 再次发送任意值)。
将军收到以下向量:
| g1 |
g2 |
g3 |
g4 |
| (1,2,y,4) |
(1,2,x,4) |
(1,2,x,4) |
(1,2,x,4) |
| (A B C D) |
(e,f,g,h) |
(1,2,y,4) |
(1,2,y,4) |
| (1,2,z.4) |
(1,2,z.4) |
(1,2,z.4) |
(i,j,kl) |
第 4 步。每个将军检查所有接收到的向量中的每个元素。如果某个值在至少两个向量中匹配,则将其放入结果向量中,否则结果向量的对应元素被标记为未知。
所有忠诚的将军得到一个向量 (1,2,unknown,4) - 达成一致。
如果我们考虑 n=3 和 m=1 的情况,则不会达成一致。
Lamport 证明,在一个有 m 个不正确工作的处理器的系统中,只有当有 2m + 1 个正确工作的处理器(超过 2/3)时才能达成一致。
其他作者已经表明,在具有异步处理器和无限通信延迟的分布式系统中,即使有一个空闲处理器(即使它没有显示生命迹象)也无法达成一致。
算法的应用——可靠的时钟同步。
可靠的不可分割广播消息的算法。
该算法分两个阶段执行,并假设每个处理器都有队列来存储传入消息。它的初始优先级被用作消息的唯一标识符——发送的逻辑时间,其值在不同的处理器上是不同的。
第一阶段。
发送进程向一组进程发送消息(进程 ID 列表包含在消息中)。
当收到此消息时,处理:
- 给消息一个优先级,将消息标记为无法投递,并缓冲它。时间戳(当前逻辑时间)用作优先级。
- 发送者被告知分配给消息的优先级。
第二阶段。
当收到所有收件人的回复时,发件人:
- 选择分配给消息的最高优先级并将其设置为消息的最终优先级。
- 将此优先级发送给所有收件人。
收到最终优先级后,收件人:
- 将此优先级分配给消息。
- 将邮件标记为已送达。
- 按分配的优先级升序排列所有缓冲的消息。
- 如果队列中的第一条消息被标记为已送达,那么它将被视为最终收到。
如果接收方发现自己有一条标记为不可投递的消息,而其发送方已损坏,那么它作为协调者采取以下两个步骤来完成协议。
1. 轮询所有收件人有关此邮件的状态。
收件人可以通过以下三种方式之一进行回复:
- 该消息被标记为无法投递并被赋予一定的优先级。
- 该消息被标记为已传递并具有这样那样的最终优先级。
- 他没有收到这条消息。
2. 收到所有答复后,协调员执行以下操作:
- 如果消息被标记为由收件人发送,则其最终优先级将发送给每个人。(收到此消息后,每个进程执行阶段 2 的步骤)。
- 否则,协调器从阶段 1 重新启动整个协议。(重新发送具有相同优先级的消息不能导致冲突)。
应该注意的是,该算法需要存储初始和最终优先级,即使对于已接收和已处理的消息也是如此。